生成音频的方法、设备和存储介质与流程
本技术涉及音频,特别涉及一种生成音频的方法、设备和存储介质。
背景技术:
1、在音频技术领域,vc(voice conversion,声音转换)技术是指将一段源音频转换为具有指定说话人音色的目标音频,并且目标音频中还保留有源音频的发音节奏特征,其中,发音节奏特征用于表示发音过程的每个音素和对应的发音时长。例如,在儿童朗读的应用程序中,为了同时保留父亲或母亲的音色以及朗读音频的发音节奏特征,父亲或母亲可以在应用程序中选择某个童话故事的朗读音频。另外,父亲或母亲还需要录制一段自己讲话的音频,点击转换控件后,就可以得到具有自己音色以及朗读音频的发音节奏特征的音频。
2、相关应用程序中可以有声音转换模型,该模型包括ppg(phoneme posteriorgram,音素后验概率)提取器、声学模型和声码器。具体使用过程如下:将朗读音频输入到ppg提取器,得到ppg矩阵。ppg矩阵是朗读音频的每个帧对应各音素的概率,是一种发音节奏特征。将ppg矩阵和目标人物的音色特征输入到声音转换模型中,就可以得到具有目标人物音色和朗读音频的发音节奏特征的音频。
3、在相关技术中,如果朗读音频有较大的噪声,那么会影响ppg提取器提取出的发音节奏特征(ppg矩阵)的准确性,进一步影响转换音频的质量。
技术实现思路
1、本技术实施例提供了一种生成音频的方法、装置、设备和存储介质,能够解决相关技术的问题。技术方案如下:
2、第一方面,提供了一种生成音频的方法,所述方法包括:
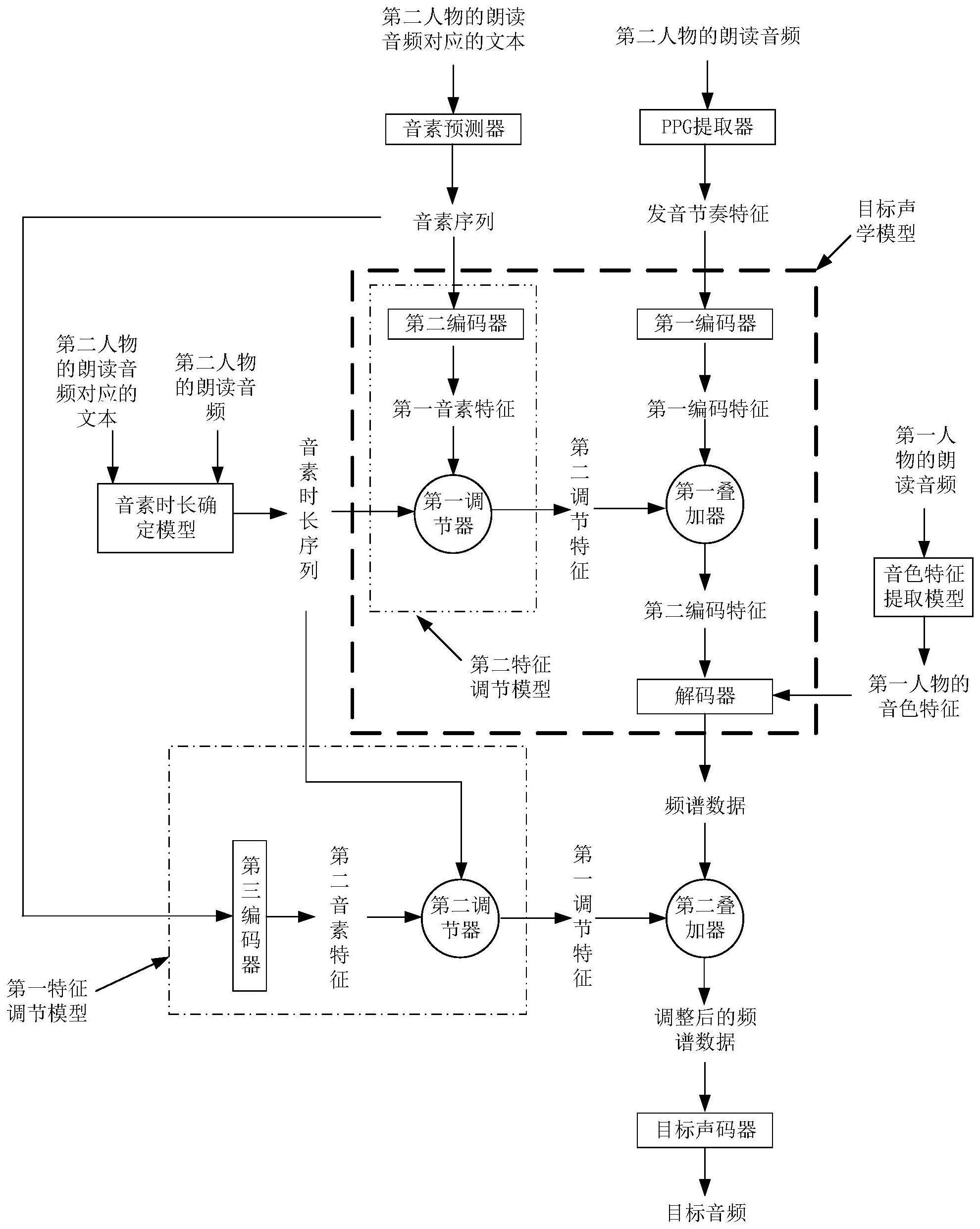
3、获取第一人物的音色特征,获取第二人物的朗读音频对应的发音节奏特征、音素序列和音素时长序列;
4、将所述第一人物的音色特征以及所述第二人物对应的发音节奏特征、所述音素序列和所述音素时长序列输入预先训练完成的目标声学模型,得到所述目标声学模型输出的频谱数据;
5、将所述音素序列和所述音素时长序列输入预先训练完成的第一特征调节模型,由所述第一特征调节模型使用所述音素时长序列对所述音素序列进行长度调整后输出第一调节特征,其中所述第一调节特征的长度与所述频谱数据的长度相同;
6、使用所述第一调节特征对所述频谱数据进行调整,得到调整后的频谱数据;
7、将所述调整后的频谱数据输入预先训练完成的目标声码器,得到所述目标声码器输出的目标音频。
8、在一种可能的实现方式中,所述目标声学模型包括第一编码器、解码器、第二特征调节模型和第一叠加器;
9、所述将所述第一人物的音色特征以及所述第二人物对应的发音节奏特征、所述音素序列和所述音素时长序列输入预先训练完成的目标声学模型,得到所述目标声学模型输出的频谱数据,包括:
10、将所述第二人物对应的发音节奏特征输入预先训练完成的所述第一编码器,得到所述第一编码器输出的第一编码特征;
11、将所述第二人物对应的音素序列和所述第二人物对应的音素时长序列输入预先训练完成的所述第二特征调节模型,由所述第二特征调节模型使用所述第二人物对应的音素时长序列对所述第二人物对应的音素序列进行长度调整后输出第二调节特征,其中所述第二调节特征与所述第一编码特征的长度相同;
12、将所述第二调节特征和所述第一编码特征输入所述第一叠加器,由所述第一叠加器对所述第二调节特征和所述第一编码特征进行对位相加后得到并输出第二编码特征;
13、将所述第二编码特征和所述第一人物的音色特征输入预先训练完成的所述解码器,得到所述解码器输出的所述频谱数据。
14、在一种可能的实现方式中,所述第二特征调节模型包括第二编码器和第一调节器;
15、所述将所述第二人物对应的音素序列和所述第二人物对应的音素时长序列输入预先训练完成的所述第二特征调节模型,由所述第二特征调节模型使用所述第二人物对应的音素时长序列对所述第二人物对应的音素序列进行长度调整后输出第二调节特征,包括:
16、将所述第二人物对应的音素序列输入预先训练完成的所述第二编码器,得到所述第二编码器输出的第一音素特征;
17、将所述第一音素特征和所述音素时长序列输入所述第一调节器,由所述第一调节器使用所述第二人物对应的音素时长序列对所述第一音素特征进行长度调整后输出所述第二调节特征。
18、在一种可能的实现方式中,所述第一特征调节模型包括第三编码器和第二调节器;
19、所述将所述音素序列和所述音素时长序列输入预先训练完成的第一特征调节模型,由所述第一特征调节模型使用所述音素时长序列对所述音素序列进行长度调整后输出第一调节特征,包括:
20、将所述音素序列输入预先训练完成的所述第三编码器,得到所述第三编码器输出的第二音素特征;
21、将所述第二音素特征和所述音素时长序列输入所述第二调节器,由所述第二调节器使用所述音素时长序列对所述第二音素特征进行长度调整后输出所述第一调节特征。
22、在一种可能的实现方式中,所述使用所述第一调节特征,对所述频谱数据进行调整,得到调整后的频谱数据,包括:
23、将所述第一调节特征和所述频谱数据输入第二叠加器,由所述第二叠加器对所述第一调节特征和所述频谱数据进行对位相加后得到并输出所述调整后的频谱数据。
24、在一种可能的实现方式中,获取第二人物的朗读音频对应的音素时长序列,包括:
25、将所述第二人物的朗读音频和所述朗读音频对应的文本输入音素时长确定模型,得到所述第二人物对应的音素时长序列。
26、在一种可能的实现方式中,所述方法还包括:
27、获取第一样本音频对应的音色特征、发音节奏特征、音素序列、音素时长序列和频谱数据;
28、将所述第一样本音频对应的音色特征、所述发音节奏特征、所述音素序列和所述音素时长序列输入待训练的声学模型,得到所述待训练的声学模型输出的频谱数据;
29、以最小化所述第一样本音频对应的频谱数据和所述待训练的声学模型输出的频谱数据之间的差异为训练目的,对所述待训练的声学模型进行训练;
30、若训练后的声学模型满足训练结束条件,则将所述训练后的声学模型确定为所述目标声学模型。
31、在一种可能的实现方式中,所述方法还包括:
32、获取第二样本音频对应的音素序列、音素时长序列和频谱数据;
33、将所述第二样本音频对应的音素序列和所述音素时长序列输入所述经过训练的第一特征调节模型,得到所述第一特征调节模型输出的第三调节特征;
34、使用所述第三调节特征对所述第二样本音频对应的频谱数据进行调整,得到所述第二样本音频对应的调整后的频谱数据;
35、将所述第二样本音频对应的调整后的频谱数据输入所述待训练的声码器,得到所述待训练的声码器输出的预测音频;
36、以最小化所述预测音频和所述样本音频之间的差异,对所述待训练的声码器进行训练;若训练后的声码器满足训练结束条件,则将所述训练后的声码器确定为所述目标声码器。
37、第二方面,提供了一种生成音频的装置,所述装置包括:
38、获取模块,用于获取第一人物的音色特征,获取第二人物的朗读音频对应的发音节奏特征、音素序列和音素时长序列;
39、生成模块,用于:
40、将所述第一人物的音色特征以及所述第二人物对应的发音节奏特征、所述音素序列和所述音素时长序列输入预先训练完成的目标声学模型,得到所述目标声学模型输出的频谱数据;
41、将所述音素序列和所述音素时长序列输入预先训练完成的第一特征调节模型,由所述第一特征调节模型使用所述音素时长序列对所述音素序列进行长度调整后输出第一调节特征,其中所述第一调节特征的长度与所述频谱数据的长度相同;
42、使用所述第一调节特征对所述频谱数据进行调整,得到调整后的频谱数据;
43、将所述调整后的频谱数据输入预先训练完成的目标声码器,得到所述目标声码器输出的目标音频。
44、在一种可能的实现方式中,所述目标声学模型包括第一编码器、解码器、第二特征调节模型和第一叠加器;
45、所述生成模块,用于:
46、将所述第二人物对应的发音节奏特征输入预先训练完成的所述第一编码器,得到所述第一编码器输出的第一编码特征;
47、将所述第二人物对应的音素序列和所述第二人物对应的音素时长序列输入所述第二特征调节模型,由所述第二特征调节模型使用所述第二人物对应的音素时长序列对所述第二人物对应的音素序列进行长度调整后输出第二调节特征,其中所述第二调节特征与所述第一编码特征的长度相同;
48、将所述第二调节特征和所述第一编码特征输入所述第一叠加器,得到所述第一叠加器输出的第二编码特征;
49、将所述第二编码特征和所述第一人物的音色特征输入预先训练完成的所述解码器,得到所述解码器输出的所述频谱数据。
50、在一种可能的实现方式中,所述第二特征调节模型包括第二编码器和第一调节器;
51、所述生成模块,用于:
52、将所述第二人物对应的音素序列输入预先训练完成的所述第二编码器,得到所述第二编码器输出的第一音素特征;
53、将所述第一音素特征和所述音素时长序列输入所述第一调节器,由所述第一调节器使用所述第二人物对应的音素时长序列对所述第一音素特征进行长度调整后输出所述第二调节特征。
54、在一种可能的实现方式中,所述第一特征调节模型包括第三编码器和第二调节器;
55、所述生成模块,用于:
56、将所述音素序列输入预先训练完成的所述第三编码器,得到所述第三编码器输出的第二音素特征;
57、将所述第二音素特征和所述音素时长序列输入所述第二调节器,由所述第二调节器使用所述音素时长序列对所述第二音素特征进行长度调整后输出所述第一调节特征。
58、在一种可能的实现方式中,所述生成模块,用于:
59、将所述第一调节特征和所述频谱数据输入第二叠加器,由所述第二叠加器对所述第一调节特征和所述频谱数据进行对位相加后得到并输出所述调整后的频谱数据。
60、在一种可能的实现方式中,所述获取模块,用于:
61、将所述第二人物的朗读音频和所述朗读音频对应的文本输入音素时长确定模型,得到所述第二人物对应的音素时长序列。
62、在一种可能的实现方式中,所述装置还包括训练模块:
63、所述获取模块,用于获取第一样本音频对应的音色特征、发音节奏特征、音素序列、音素时长序列和频谱数据;
64、所述生成模块,用于将所述第一样本音频对应的音色特征、所述发音节奏特征、所述音素序列和所述音素时长序列输入待训练的声学模型,得到所述待训练的声学模型输出的频谱数据;
65、所述训练模块,用于:
66、以最小化所述第一样本音频对应的频谱数据和所述待训练的声学模型输出的频谱数据之间的差异为训练目的,对所述待训练的声学模型进行训练;
67、若训练后的声学模型满足训练结束条件,则将所述训练后的声学模型确定为所述目标声学模型。
68、在一种可能的实现方式中,所述获取模块,还用于:
69、获取第二样本音频对应的音素序列、音素时长序列和频谱数据;
70、所述生成模块,用于:
71、将所述第二样本音频对应的音素序列和所述音素时长序列输入经过训练的第一特征调节模型,得到所述第一特征调节模型输出的第三调节特征;
72、使用所述第三调节特征对所述第二样本音频对应的频谱数据进行调整,得到所述第二样本音频对应的调整后的频谱数据;
73、将所述第二样本音频对应的调整后的频谱数据输入所述待训练的声码器,得到所述待训练的声码器输出的预测音频;
74、所述训练模块,用于:
75、以最小化所述预测音频和所述样本音频之间的差异,对所述待训练的声码器进行训练;若训练后的声码器满足训练结束条件,则将所述训练后的声码器确定为所述目标声码器。
76、第三方面,提供了一种计算机设备,计算机设备包括存储器和处理器,存储器用于存储计算机指令;处理器执行存储器存储的计算机指令,以使计算机设备执行第一方面及其可能的实现方式的方法。
77、第四方面,提供了一种计算机可读存储介质,计算机可读存储介质存储有计算机程序代码,响应于计算机程序代码被计算机设备执行,计算机设备执行第一方面及其可能的实现方式的方法。
78、第五方面,提供了一种计算机程序产品,计算机程序产品包括计算机程序代码,响应于计算机程序代码被计算机设备执行,计算机设备执行第一方面及其可能的实现方式的方法。
79、本技术的实施例提供的技术方案可以包括以下有益效果:
80、通过本技术实施例提供的方法,采用音素序列和音素时长序列,音素序列一般是从音频对应的文本中获取的,完全不受音频中噪声的影响,音素时长序列一般是基于音频和音频对应的文本得到的,受音频中噪声的影响很小。另外,音素序列可以提供音频的发音信息,音素时长序列可以提供音频的节奏信息。因此,除了将发音节奏特征和音色特征作为模型的输入之外,将音素序列和音素时长序列同时作为模型的输入,以生成音频,可以降低噪声对生成音频的影响。进一步,可以提高生成音频的质量。
- 还没有人留言评论。精彩留言会获得点赞!