一种面向音频注入的叠加声烦恼度建模方法
本发明涉及声品质,具体涉及一种面向音频注入系统的噪声烦恼度建模方法。
背景技术:
1、通过在原始噪声中注入调控声以降低其烦恼感的方法被称为音频注入法(audioinjection),原始噪声也称为目标声(target sound,ts),所加入的声音称为调控声(controllable sound,cs),混合后的声音称为叠加声(combined noise,cn)。较之传统的减法噪声控制策略,音频注入法具有实施简单、成本低、易于工程实现等优点,逐渐成为噪声控制领域的前沿课题,受到研究人员和工业界的广泛关注和重视。
2、音频注入法的基础在于建立混合噪声烦恼度模型对叠加声烦恼度进行评价与预测。国内外学者对多种相似混合噪声烦恼度建模进行了大量研究,提出了多种模型,其中最具代表性的有:能量叠加模型(energy summation model)、独立效应模型(independenteffect model)、最强组分模型(strongest component or dominant source model)、矢量叠加模型(vector summation model)等。以上几种混合噪声烦恼度模型均是基于能量角度对总烦恼度进行建模计算,忽略了听觉效应的影响;简单能量叠加模型默认组成混合噪声的各单一噪声成分剂量与烦恼度之间的关系是一致的,然而对不同特定噪声烦恼度的研究结果证明这一结论是不成立的,特别当各单一噪声为不相似噪声时,其烦恼度预测误差会进一步增大;独立效用模型考虑到不同噪声之间噪声剂量与烦恼度的关系各有差别,但该模型认为各噪声烦恼度的作用是独立、互不相干的,噪声的相消与相长效应已经否认了这一观点。最强组分模型虽然在应用中的模型预测效果好于上述两种模型,但不适用于音频注入的叠加声烦恼预测,音频注入的叠加声主成分为目标噪声,等价于使用该模型对目标噪声的烦恼度进行预测,并不能体现不同调控声所产生的调控效果与烦恼度改善程度;矢量叠加模型引用常量线性修正单一噪声烦恼度与总烦恼度之间的关系,但不同调控声与目标声组合产生的烦恼抑制结果不同,仅凭单一参量无法解释不同组合之间的烦恼度关系。
3、这些模型对于相似混合噪声烦恼度预测有一定帮助,但在音频注入法中,相当部分的叠加噪声属于不相似混合噪声,该混合噪声的组成较为复杂,各成分之间的声压级和频谱差异较大,作用机理不单纯为声能量叠加与掩蔽,还包括时频补偿与信息掩蔽,已有混合噪声烦恼度模型的预测误差较大,不适用于音频注入应用的具体工程环境。
4、不同于交通噪声与其他混合噪声烦恼度研究,音频注入中的混合噪声(即叠加声),是人为合成的,我们可以得到混合噪声各组成成分的具体参数。基于此,针对音频注入法可以通过叠加声烦恼度建模来评价某一类噪声的烦恼度。
5、音频注入法是一种通过改善噪声声品质从而降低烦恼度达到降噪效果的“加法控制”。烦恼度是基于心理声学的概念,描述了人对声音的烦恼感。烦恼度评测主要分为主观评测和客观评测,现阶段主要以主观评测为主,主观评测虽然可以直观反映听音者对声音的实际心理感受,但受限于具体的噪声环境,只能对某一特定噪声的烦恼度进行评测,工作量和成本都比较大。因此烦恼度的客观评测是目前研究的重点,通过心理声学领域的客观参数:响度、尖锐度、粗糙度、波动强度、主观持续时长等,建立噪声烦恼度模型,评价某一类噪声的烦恼度。不同于单一噪声烦恼度评价,音频注入法的烦恼度评价是对目标声与调控声的混合噪声(叠加声)烦恼度进行评价。如表1所示,以某音频注入研究实验数据为例。
6、表1目标声、调控声与叠加声参数对比
7、
8、但实验发现,由于调控声和目标声的声压级相差较大,普遍在10db以上,混合以后的叠加声以目标声成分为主,声学参数基本上与目标声相同,因而不同调控声所形成叠加声的声学参数差异较小,平均声压级相差0.8%以内,平均响度相差8.5%以内,平均尖锐度相差5.5%以内。对混合噪声进行评价时使用叠加声的响度、尖锐度、粗糙度和波动强度等参量作为自变量建立的多元线性回归模型误差较大,且各自变量与应变量的线性回归关系不密切,即自变量参数与应变量之间的相关性不强。
技术实现思路
1、为解决现有方法对混合噪声进行评价时使用叠加声的响度、尖锐度、粗糙度和波动强度等参量作为自变量建立的多元线性回归模型误差较大,且各自变量与应变量的线性回归关系不密切的问题,本发明提出一种面向音频注入的误差更小的叠加声烦恼度建模方法,运用调控声与目标声响度差、尖锐度差、粗糙度差、波动强度差为自变量建立多元线性回归模型,提高模型的精度和参数相关性,进一步完善音频注入叠加声烦恼度客观评价。
2、本发明的技术方案为:
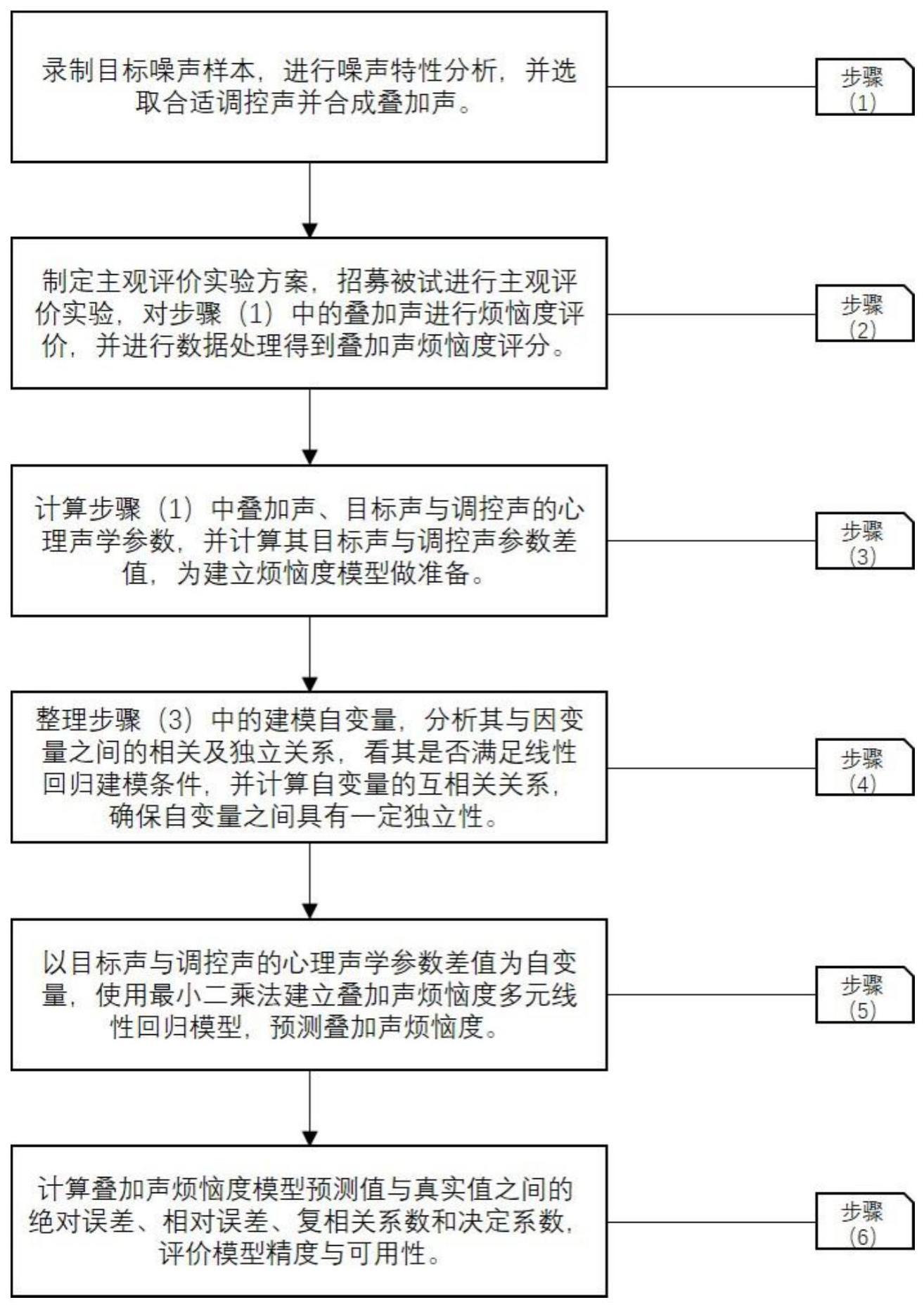
3、一种面向音频注入的叠加声烦恼度建模方法,包括以下步骤:
4、步骤1:根据目标声,选择相应的调控声进行时域叠加,得到若干叠加声样本;
5、步骤2:对步骤1得到的叠加声样本进行烦恼度主观评价实验及数据处理;
6、步骤3:计算目标声、调控声和叠加声的心理声学参数,并计算目标声与调控声对应心理声学参数差值;
7、步骤4:以步骤3计算的目标声与调控声心理声学参数差值作为自变量,对应的叠加声烦恼度评分值为因变量,计算自变量与因变量之间的相关关系,以及自变量之间的相关关系及共线性关系,根据计算结果,确定建模自变量;
8、步骤5:利用步骤4确定建模自变量,叠加声烦恼度评分值为因变量,采用多元线性回归,实现音频注入叠加声烦恼度建模。
9、进一步的,步骤1中,先采集目标声样本,然后利用声分析软件绘制目标声样本的时域图、频谱图及时频图,分析目标声的时域及频域特性,根据目标声的时域及频域特性,挑选相应的调控声与目标声进行时域叠加,得到叠加声样本。
10、进一步的,步骤2中,对叠加声样本进行烦恼度主观评价实验后,对实验数据进行有效性检验:分析被试评分范围,剔除前后评分相差过大数据;对被试数据进行误判分析,判断同一被试若干次评价结果的一致性;进行相关分析,判断同一被试若干次评价结果之间的相关性;最后对实验数据进行聚类分析,剔除评分标准相差过大的被试数据;剔除无效数据后计算每个叠加声对应的平均烦恼度,得到最终烦恼度评分结果。
11、进一步的,步骤3中,心理声学参数包括响度、尖锐度、粗糙度、波动强度。
12、进一步的,步骤3中,采用zwicker模型计算响度。
13、进一步的,步骤4中,确定的建模自变量为目标声与调控声的响度差值δn、尖锐度差值δs、粗糙度差值δr、波动强度差值δfl。
14、有益效果
15、本发明为音频注入法中叠加声烦恼度建模提供新方法。从调控声与叠加声参数差值入手,更能直观反映二者相对关系对音频注入叠加声烦恼度的影响,提高模型精度。
16、此外,本发明推动音频注入法的理论研究。直观得到调控声与目标声参数差值与烦恼度的数值关系,有助于音频注入的调控机理研究,从而指导调控声选取及音频注入系统优化。
17、本发明的附加方面和优点将在下面的描述中部分给出,部分将从下面的描述中变得明显,或通过本发明的实践了解到。
- 还没有人留言评论。精彩留言会获得点赞!