一种结合听损补偿和语音降噪的语音增强方法
本发明属于语音增强,具体涉及一种结合听损补偿和语音降噪的语音增强方法。
背景技术:
1、听力康复已成为世界范围内人们面临的严峻挑战。据估计,全世界大约有5亿人患有听力损伤问题。助听器是现阶段行之有效的听力康复手段。然而,现有的助听技术在面对带噪环境下的听损补偿仍困难重重。目前,针对助听器的降噪方法主要分为空间选择方法以及非空间降噪方法。空间选择方法(比如波束形成)基于目标语音和干扰源在空间上的差异设计,保持目标语音方向更敏感。但是现实中的噪声可能来自不同方向,而且目标语音和干扰源的方位也可能随时间变化。单麦克风降噪技术主要利用目标语音和干扰源的时频差异对噪声进行抑制,但对于语音的清晰度改善有限。因此,如何有效提高听损患者在噪声环境下的言语理解度,是目前助听器设计的重要方向。
2、近年来,基于深度神经网络的语音降噪技术取得了突破性的进展。相比于传统算法,基于深度学习的方法在非平稳低信噪比环境下的优势更加明显。基于深度学习的降噪技术也开始应用于助听器领域。比如,听觉激励特征被提取以馈送至神经网络并估计浮值掩蔽,从而进行针对人工耳蜗的噪声抑制;通过语音可懂度引导神经架构搜索以优化神经网络进行用于助听器的降噪;使用针对宽带频谱图的深度滤波以进行助听器的降噪。然而,这些方法没有合理地将噪声抑制与听损补偿结合起来。事实上,不同的听损患者对特定频率的增益需求不同,在对噪声进行抑制的同时也应考虑针对特定患者的听损补偿效果。
3、从目前的研究情况看,基于助听器的语音处理算法通常将语音增强和听损补偿当做两个算法来处理,而将听损补偿和语音增强进行分开处理会带来计算量上的冗余,增加了系统时延;此外,脱离声学环境的情况下来讨论听损补偿,可能导致对环境噪声的放大,从而影响补偿效果。
技术实现思路
1、发明目的:针对现有技术中存在的问题,本发明公开了一种结合听损补偿和语音降噪的语音增强方法,能够稳定有效地提升带噪环境下听损补偿的效果,方法巧妙新颖,具有良好的应用前景。
2、技术方案:为实现上述发明目的,本发明采用如下技术方案:
3、一种结合听损补偿和语音降噪的语音增强方法,包括如下步骤:
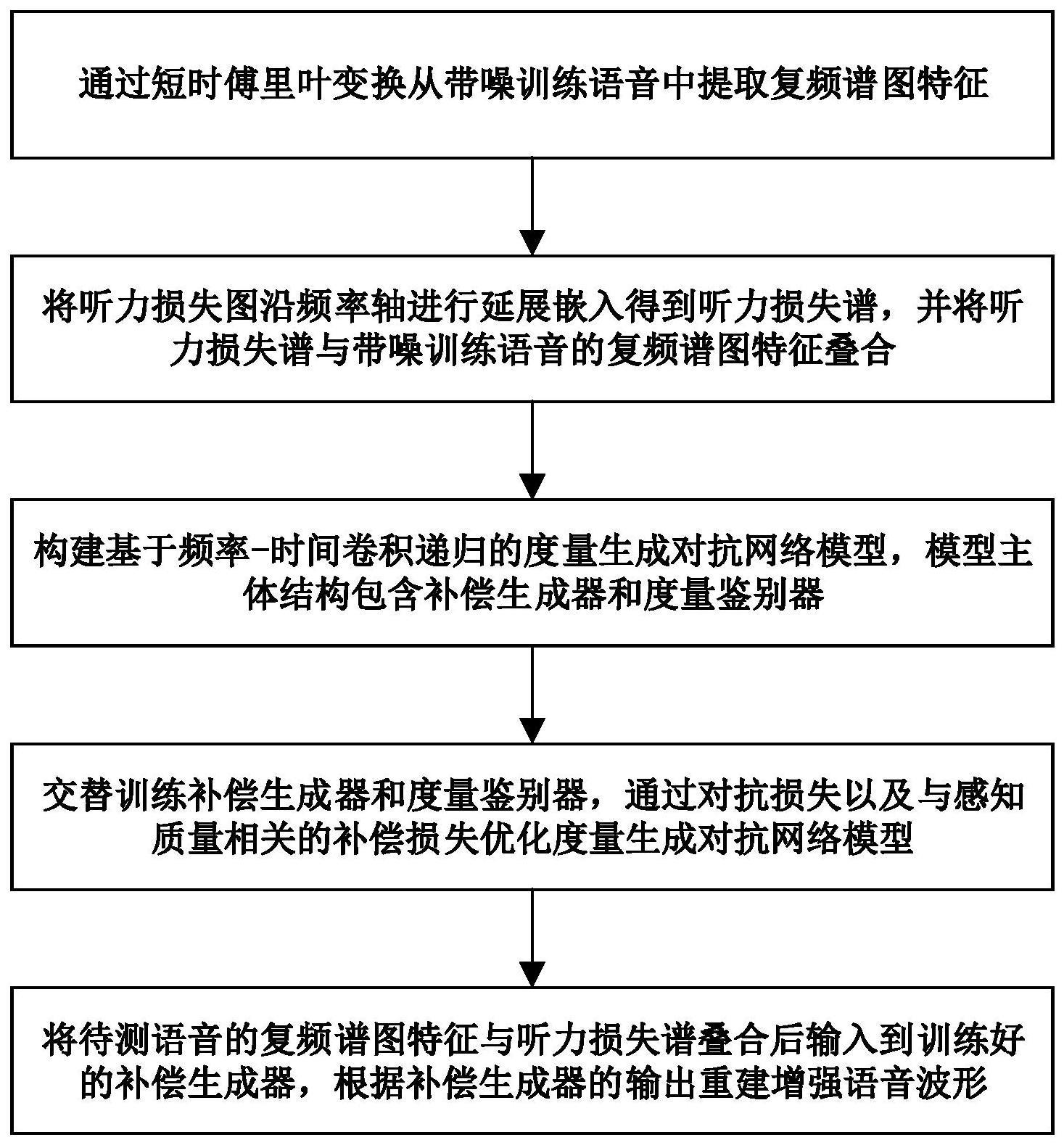
4、s1:通过短时傅里叶变换从带噪训练语音中提取复频谱图特征;
5、s2:将听力损失图沿频率轴进行延展嵌入得到听力损失谱,并将听力损失谱与步骤s1中得到的带噪训练语音的复频谱图特征叠合;
6、s3:构建基于频率-时间卷积递归的度量生成对抗网络模型,模型主体结构包含补偿生成器和度量鉴别器;
7、s4:交替训练补偿生成器与度量鉴别器,通过对抗损失以及与感知质量相关的补偿损失优化度量生成对抗网络模型;
8、s5:将待测语音的复频谱图特征与听力损失谱叠合后输入到训练好的补偿生成器,根据补偿生成器的输出重建待测语音的增强语音波形。
9、优选的,所述步骤s2包括:
10、首先对听力损失图进行傅里叶变换,之后分别在[250,500,1000,2000,4000,8000]hz频率上采样得到6维听力损失图增益,对于每一维听力损失图增益,将其归一化后作为每一个频率区间的增益值,最后形成听力损失谱;
11、听力损失谱再与带噪训练语音的复频谱图特征叠合以取得频率区间上的对齐。
12、优选的,补偿生成器中包括卷积编码器、频率-时间递归处理模块和卷积解码器;
13、所述步骤s3包括:
14、s31:构建补偿生成器的卷积编码器,卷积编码器使用5个卷积块来沿频率轴对其输入特征提取局部模式并降低特征分辨率,每个卷积块包括一个二维卷积层以及卷积层后依次设置的批归一化处理和prelu激活函数,其中起始两个卷积块的卷积层设置卷积步长为2;
15、卷积编码器的输入即为补偿生成器的输入;
16、s32:构建补偿生成器的频率-时间递归处理模块,频率-时间递归处理模块包括具有相同结构的第一递归处理模块和第二递归处理模块;
17、第一递归处理模块的输入为卷积编码器的输出,第一递归处理模块首先对其输入特征按时间轴进行切片,按帧独立地通过blstm网络建模频率轴的相关性,blstm网络后依次设置全连接层和归一化层进行后置处理,后置处理后得到的特征与第一递归处理模块的输入特征叠加构成第一特征;
18、然后对第一特征按频率轴进行切片,利用lstm网络对每个频率流的时间相关性建模,lstm网络后依次设置全连接层和归一化层进行后置处理,后置处理后得到的特征与第一特征叠加构成第一递归处理模块的输出;
19、第二递归处理模块的输入为第一递归处理模块的输出,第二递归处理模块首先对其输入特征按时间轴进行切片,按帧独立地通过blstm网络建模频率轴的相关性,blstm网络后依次设置全连接层和归一化层进行后置处理,后置处理后得到的特征与第二递归处理模块的输入特征叠加构成第二特征;
20、然后对第二特征按频率轴进行切片,利用lstm网络对每个频率流的时间相关性建模,lstm网络后依次设置全连接层和归一化层进行后置处理,后置处理后得到的特征与第二特征叠加构成第二递归处理模块的输出;
21、第二递归处理模块的输出即为频率-时间递归处理模块的输出;
22、s33:构建补偿生成器的卷积解码器,卷积解码器是卷积编码器的镜像,使用5个卷积块将其输入特征恢复到卷积编码器的输入特征大小,每个卷积块包括一个二维转置卷积层以及转置卷积层后依次设置的批归一化处理和prelu激活函数,其中最后两个卷积块的转置卷积层设置卷积步长为2;
23、卷积编码器的输出和频率-时间递归处理模块的输出在通道维度上拼接后,输入卷积解码器;卷积编码器的第四个卷积块的输出和卷积解码器的第一个卷积块的输出在通道维度上拼接后,输入卷积解码器的第二个卷积块;卷积编码器的第三个卷积块的输出和卷积解码器的第二个卷积块的输出在通道维度上拼接后,输入卷积解码器的第三个卷积块;卷积编码器的第二个卷积块的输出和卷积解码器的第三个卷积块的输出在通道维度上拼接后,输入卷积解码器的第四个卷积块;卷积编码器的第一个卷积块的输出和卷积解码器的第四个卷积块的输出在通道维度上拼接后,输入卷积解码器的第五个卷积块。
24、卷积解码器的输出即为补偿生成器的输出;
25、s34:构建度量鉴别器,首先通过4个二维卷积块对其输入特征进行特征提取,每个二维卷积块由依次连接的一个二维卷积层、一个实例归一化层和prelu激活函数构成,在第四个二维卷积块之后,进行全局平均池化操作,最后再通过两个全连接层和sigmoid函数激活输出。
26、优选的,卷积解码器的第一个卷积块、第二个卷积块、第三个卷积块、第四个卷积块、第五个卷积块的转置卷积层的卷积核大小和步长分别与卷积编码器的第五个卷积块、第四个卷积块、第三个卷积块、第二个卷积块、第一个卷积块的卷积层的卷积核大小和步长相同。
27、优选的,所述步骤s4包括:
28、s41:将步骤s2中听力损失谱与带噪训练语音的复频谱图特征叠合后得到的特征输入到补偿生成器中,将补偿生成器的输出和带噪训练语音的复频谱图特征相乘得到增强训练语音的复频谱图特征;
29、s42:对度量鉴别器进行训练:
30、首先,将度量鉴别器的两个输入分别置为带噪训练语音经过验配公式补偿后的干净补偿语音和增强训练语音,将度量鉴别器输出的预测分数与增强训练语音和干净补偿语音之间经hasqi计算得到的hasqi标签计算损失;其中,干净补偿语音和增强训练语音在输入度量鉴别器之前,分别将其复频谱图特征与听力损失谱叠合,将叠合后的特征输入度量鉴别器;
31、另外,将度量鉴别器的两个输入均置为干净补偿语音,将度量鉴别器输出的预测分数与全1向量计算损失,其中,干净补偿语音在输入度量鉴别器之前,将其复频谱图特征与听力损失谱叠合,将叠合后的特征输入度量鉴别器;
32、该步骤中度量鉴别器的总损失描述如下:
33、
34、其中,和hl分别为干净补偿语音、增强训练语音以及对应的听力损失图,d表示度量鉴别器网络,mhasqi表示hasqi计算出的hasqi标签;
35、将总损失反向传播至度量鉴别器,更新度量鉴别器的参数;
36、s43:对补偿生成器进行训练:
37、在该步骤度量鉴别器将冻结,不进行参数的更新,此时将度量鉴别器的两个输入分别置为干净补偿语音和增强训练语音,将度量鉴别器输出的预测分数与全1向量计算损失,另外还设置了感知质量相关的损失以强化模型对于噪声的抑制,包括pmsqe损失和pase损失,其中,干净补偿语音和增强训练语音在输入度量鉴别器之前,分别将其复频谱图特征与听力损失谱叠合,将叠合后的特征输入度量鉴别器;
38、该步骤中补偿生成器的总损失描述如下:
39、
40、其中,pmsqe根据干净补偿语音和增强训练语音的功率谱进行计算,而pase则利用预先训练的语音特征编码器度量增强训练语音和干净补偿语音之间的特征距离,α和β为感知质量相关损失的权重系数;
41、将总损失反向传播至补偿生成器,更新补偿生成器的参数;
42、s44:重复执行步骤s41~步骤s43,对补偿生成器和度量鉴别器进行交替训练,直至达到预设训练轮数或者补偿生成器的总损失小于预设数值,训练结束。
43、优选的,α设置为1,β设置为0.25。
44、优选的,所述步骤s5包括:
45、首先利用补偿生成器的输出与待测语音的复频谱图特征相乘得到增强待测语音的复频谱图特征,然后通过逆傅里叶变换将增强待测语音的复频谱图特征还原为增强待测语音的时域波形,最后通过重叠相加算法合成得到待测语音的增强语音波形,重叠相加算法是指增强待测语音的时域波形的帧与帧之间重叠部分的叠加。
46、有益效果:与现有技术相比,本发明具有如下显著的有益效果:
47、本发明所述结合听损补偿和语音降噪的语音增强方法,通过单一网络同时完成对噪声的抑制与针对听力图特化的频谱级补偿:
48、首先引入了听力图嵌入方法,使得网络能够学习听力图和频率区间的对应关系信息,其次利用度量鉴别器与补偿生成器的对抗性训练,通过度量鉴别器引导补偿生成器生成人耳感知质量更好的补偿语音,最后设置额外的补偿损失以进一步提升模型对于噪声的抑制。本发明通过度量生成对抗网络同时完成降噪与针对特定听力图的听损补偿,能够稳定有效地提升带噪环境下听损补偿的效果,方法巧妙新颖,具有良好的应用前景。
- 还没有人留言评论。精彩留言会获得点赞!