跨语言域不变声学特征提取方法和系统
本发明涉及一种跨语言域不变声学特征提取方法和系统,属于深度学习。
背景技术:
1、受限于帕金森病患者语音样本的稀缺性和高昂的数据标注成本,基于语音的冻结步态声学分析发展缓慢。这是因为:语音样本的质量极易受采集环境和患者的配合程度等因素影响,同时数据的标签需要专业医生才能标注。截至目前,国内外已有少量公开的帕金森病语音数据集,这些数据集分别来自不同母语的受试者,采集方式亦存在差异,且单个数据集均存在数据容量不够大的问题。如果能够整合多个数据集进行模型的训练,这将能够极大地改善数据量不足的问题。
2、但传统的基于语音的声学分析技术对数据进行了一个基本假设:训练和测试数据来源于同一数据分布,表现为训练集和测试集在统计学上具有相似的统计概率分布,比如同属于步态冻结患者的语音在基频、jitter、shimmer等声学特征在数值上具有相似的分布范围。当使用来自不同国家的帕金森病患者语音数据集时,由于受试者母语发音特点的差异,将导致受试者语音提取的声学特征在统计概率分布上存在一定的差异,其数值的分布范围会受母语发音习惯的影响而改变。如果只是简单地将不同数据集的数据混合一起进行训练,必将为模型带来更多的混淆因素,使得模型的分析能力下降。传统的基于语音的声学分析方法无法有效地解决跨语言的分类识别问题,也无法将研究成果推广到分布在更广阔地域的患者使用。
3、有鉴于此,确有必要提出一种跨语言域不变声学特征提取方法和系统,以解决上述问题。
技术实现思路
1、本发明的目的在于提供一种跨语言域不变声学特征提取方法和系统,能够解决跨语言的冻结步态声学分析问题。
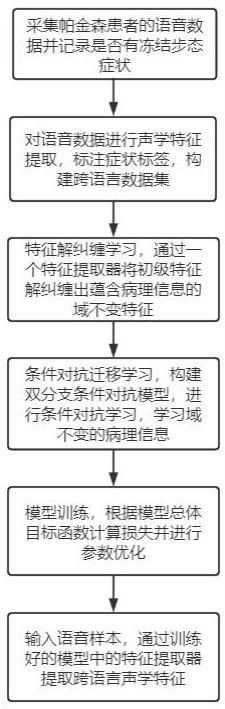
2、为实现上述目的,本发明提供了一种跨语言域不变声学特征提取方法,主要包括以下步骤:
3、步骤1、语音信号采集:采集母语不同的受试者参与语音采集任务的语音,以及记录受试者是否有冻结步态症状;
4、步骤2、对语音数据进行预处理,提取fbank特征,根据受试者是否存在冻结步态症状进行分类标签标注,同时还将根据数据来源于“源域”或“目标域”进行域标签标注;
5、步骤3、训练一个transformer编码块与多层前馈神经网络级联的特征提取器,将步骤2的样本特征向量输入该特征提取器,提取高级语义表达并将语音特征解纠缠为两个向量,其中,为网络参数;
6、步骤4、训练两个域鉴别器用于判断输入鉴别器的特征向量来自于“源域”或“目标域”,同时还将训练两个分类器用于预测输入的特征向量的症状标签;
7、步骤5、根据步骤4所获得的输出,进行模型的损失计算,并更新模型的网络参数;
8、步骤6、根据步骤5训练完成的模型,通过模型中的特征提取器,即可对输入的语音样本提取一个可用于冻结步态跨语言声学分析的域不变声学特征。
9、作为本发明的进一步改进,步骤1中,对语音信号采集的具体过程为:采集不同母语的受试者的语音,包括持续元音或重复音节,同时记录受试者是否有冻结步态症状,收集受试者使用“语言1”的语音数据,并整理为源域数据库;整理母语为“语言2”的语音数据并记为目标域数据库。
10、作为本发明的进一步改进,步骤2中,对语音数据进行去噪增强预处理,然后对语音信号提取fbank特征,根据受试者是否存在冻结步态症状进行分类标签标注,同时还将根据数据来源于“源域”或“目标域”进行域标签标注,具体过程为:
11、步骤21、对源域数据库中的原始语音数据进行预处理,并提取fbank特征,其中,第个样本的fbank特征记为,记其分类标签为 ,存在冻结步态时,标签用one-hot向量[1,0]表示,否则为[0,1],记其域标签为 ,用one-hot向量[1,0]标识样本来自源域,组成源域样本对,其中, s代表该数据来源于源域;
12、步骤22、对目标域数据库中的原始语音数据进行预处理,并提取fbank特征,其中,第个样本的fbank特征记为,记其分类标签为 ,存在冻结步态时,标签用one-hot向量[1,0]表示,否则为[0,1],记其域标签为 ,用one-hot向量[0,1]标识样本来自目标域,组成目标域样本对,其中, t代表该数据来源于目标域。
13、作为本发明的进一步改进,步骤3中,训练一个基于transformer编码块与多层前馈神经网络级联的特征提取器,其中,为网络参数,对原始的fbank特征进行解纠缠获得一个蕴含病理信息的域不变声学特征向量和一个包含域信息的特征向量,具体过程为:
14、步骤31、将步骤2所述的特征向量输入至由transformer编码块与多层前馈神经网络级联的特征提取器,该特征提取器的输出为两个同样长度的向量,其中一个向量为对特征向量解纠缠后获得的包含语音病理信息的高级表征向量,另外一个为对特征向量解纠缠后获得的包含域信息的高级表征向量。
15、作为本发明的进一步改进,步骤4中,训练两个域鉴别器用于判断输入鉴别器的特征向量来自于“源域”或“目标域”,同时还将训练两个分类器用于预测输入的特征向量的症状标签,具体过程为:
16、步骤41、将步骤3所述的特征向量输入分类器,其中为网络参数,获取第个样本的症状标签,将特征向量和其通过分类器获得的标签进行叉乘,再将结果输入域鉴别器进行识别,获得其域标签,其中,为网络参数;
17、步骤42、将步骤3所述的特征向量输入域鉴别器,其中,为网络参数,获取第个样本的域标签,将特征向量和其通过域鉴别器获得的标签进行叉乘,再将结果输入分类器识别其症状标签,获得结果,其中,为网络参数。
18、作为本发明的进一步改进,步骤5中,根据步骤4所获得的输出,进行模型的损失计算,并更新模型的网络参数,具体过程为:
19、步骤51、对于病理信息特征向量,其通过分类器,和领域鉴别器的对抗学习,融合病理信息并排除域信息,为了排除域信息,我们将通过最小化分类器的损失,同时最大化域鉴别器的损失,因此我们将有如下所示的目标函数:
20、,
21、其中,为分类器的损失函数,为域鉴别器的损失函数;
22、步骤52、对于域特征向量与病理信息特征向量不同的是,其通过分类器,和域鉴别器的对抗学习,融合域信息并排除病理特征信息,为了排除病理信息,我们将通过最小化域鉴别器的损失,同时最大化分类器的损失,因此,我们将有如下所示的目标函数:,
23、其中,为分类器的损失函数,为域鉴别器的损失函数;
24、步骤53、对于病理信息特征向量,为进一步确保其排除了域信息并与域特征向量不同,我们通过对每个域数据提取的病理信息特征向量和领域特征向量在子空间上实施正交约束来定义差分损失,将差分损失最小化以促进信息的解纠缠,记矩阵为由源域数据提取的病理信息特征向量作为行组成的矩阵,矩阵为由源域数据提取的域信息特征向量作为行组成的矩阵,矩阵为由目标域数据提取的病理特征向量作为行组成的矩阵,为由目标域数据提取的域信息特征向量作为行组成的矩阵,其目标函数计算方式为:
25、,
26、其中,表示矩阵转置;
27、步骤54、模型的总体优化目标函数为:,模型将根据这个总体优化目标函数采用sgd优化方法。
28、作为本发明的进一步改进,还包括进行模型的优化与参数的迭代:
29、,
30、固定特征提取器的参数、分类器的参数、域鉴别器的参数,并最大化如下损失函数:
31、。
32、作为本发明的进一步改进,步骤6中,根据步骤5训练完成的模型,通过模型中的特征提取器,即可对输入的语音样本提取一个可用于冻结步态跨语言声学分析的域不变声学特征,具体过程为:根据步骤5所述方法训练好的模型,固定特征提取器输出特征向量这一支路的模型参数,通过这个训练好的特征提取器即可对输入的语音样本提取一个可用于冻结步态跨语言声学分析的域不变声学特征,获得最终的输出结果为一个跨语言分析声学特征。
33、为实现上述目的,本发明还提供了一种跨语言域不变声学特征提取系统,应用如上所述的跨语言域不变声学特征提取方法。
34、作为本发明的进一步改进,所述跨语言域不变声学特征提取系统包括:语音数据预处理模块、特征解纠缠学习模块、条件对抗迁移学习模块、模型训练与参数优化模块和冻结步态声学特征提取模块。
35、本发明的有益效果是:本发明在面对时序数据时能够捕获更加长的时序依赖关系,帮助基于语音的跨域冻结步态分析模型实现更好的性能,使得获取到的域不变病理声学特征的域不变特性得到更好地保证。
- 还没有人留言评论。精彩留言会获得点赞!