语音合成方法、电子设备和存储介质与流程
本申请实施例涉及语音合成,特别是涉及一种语音合成方法、电子设备和存储介质。
背景技术:
1、相关技术中,有两种类型的离散语音表征被提出来,它们被称为语义编码和声学编码。语义编码,例如vq-wav2vec、wav2vec 2.0和hubert系列,是用语音识别的分辨标准或掩码预测来训练的,因此主要包含发音信息和少量的说话人信息。
2、而由音频编解码器模型引入的声学编码,例如soundstream和encodec,是为语音重建而训练的,因此包含更丰富的语音信息,例如说话人身份。典型的神经tts管道包含两个阶段:从文本中预测声学特征梅尔频谱,然后将梅尔频谱编码为波形。vqtts提出使用语义编码作为语音合成的中间表示,在自然度和鲁棒性方面,它被认为优于传统的语音特征梅尔频谱。然而,它只在单人数据集上进行了训练,并且没有考虑说话人的适应性。最近的一些模型,例如vall-e和spear tts,进一步扩展了离散代币的使用,通过续写性对说话人的适应性进行零拍(zero-shot)。具体来说,他们使用声学编码作为中间表征,并且通过自回归(ar,auto-regressive)方案生成它们。在推理过程中,他们从目标说话人提供的语音提示中进行ar续写,并且能够从输入文本中生成与给定提示一致的说话人身份的语音。
技术实现思路
1、本发明实施例提供了一种语音合成方法、电子设备和存储介质,用于至少解决上述技术问题之一。
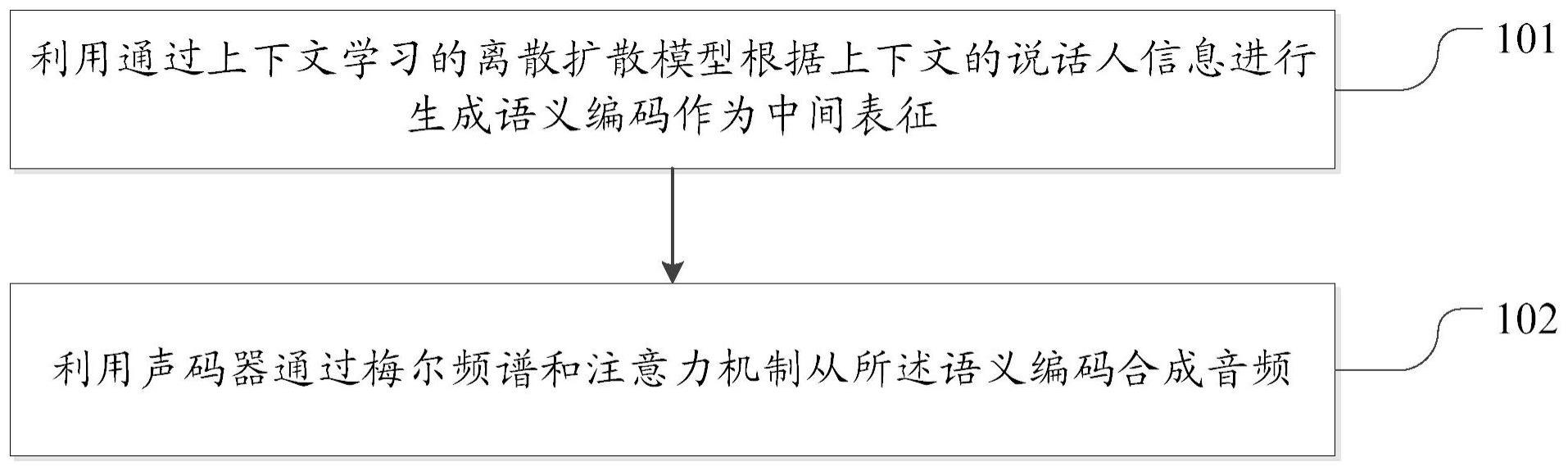
2、第一方面,本发明实施例提供了一种语音合成方法,包括:利用通过上下文学习的离散扩散模型根据上下文的说话人信息进行生成语义编码作为中间表征;利用声码器通过梅尔频谱和注意力机制从所述语义编码合成音频。
3、第二方面,本发明实施例提供一种电子设备,其包括:至少一个处理器,以及与所述至少一个处理器通信连接的存储器,其中,所述存储器存储有可被所述至少一个处理器执行的指令,所述指令被所述至少一个处理器执行,以使所述至少一个处理器能够执行本发明上述任一项语音合成方法。
4、第三方面,本发明实施例提供一种存储介质,所述存储介质中存储有一个或多个包括执行指令的程序,所述执行指令能够被电子设备(包括但不限于计算机,服务器,或者网络设备等)读取并执行,以用于执行本发明上述任一项语音合成方法。
5、第四方面,本发明实施例还提供一种计算机程序产品,所述计算机程序产品包括存储在存储介质上的计算机程序,所述计算机程序包括程序指令,当所述程序指令被计算机执行时,使所述计算机执行上述任一项语音合成方法。
6、本申请实施例的方法,可实现高质量、可编辑、可零样本自适应的语音合成。
技术特征:
1.一种语音合成方法,包括:
2.根据权利要求1所述的方法,用于语音编辑,其中,待编辑的语音为中间部分且具有上文和下文,
3.根据权利要求1所述的方法,用于语音续写,其中,待续写的语音为下文且具有上文,
4.根据权利要求1-3中任一项所述的方法,其中,所述离散扩散模型的训练包括:
5.根据权利要求1-3中任一项所述的方法,其中,所述通过上下文学习的离散扩散模型包括一个文本编码器、一个持续时间预测器、一个长度调节器和一个离散扩散模型解码器。
6.根据权利要求1-3中任一项所述的方法,其中,所述声码器的训练包括:
7.根据权利要求1-3中任一项所述的方法,其中,所述声码器包括两个语义编码器、一个卷积层和一个上采样层,其中,所述语义编码器包括多个基于conformer的块,每个块都有一个额外的交叉注意层,以纳入来自梅尔频谱的说话人信息。
8.一种电子设备,其包括:至少一个处理器,以及与所述至少一个处理器通信连接的存储器,其中,所述存储器存储有可被所述至少一个处理器执行的指令,所述指令被所述至少一个处理器执行,以使所述至少一个处理器能够执行权利要求1至7中任一项所述方法的步骤。
9.一种存储介质,其上存储有计算机程序,其特征在于,所述程序被处理器执行时实现权利要求1至7中任一项所述方法的步骤。
技术总结
本发明公开语音合成方法、电子设备和存储介质,其中,一种语音合成方法,包括:利用通过上下文学习的离散扩散模型根据上下文的说话人信息进行生成语义编码作为中间表征;利用声码器通过梅尔频谱和注意力机制从所述语义编码合成音频。本申请实施例的方法,可实现高质量、可编辑、可零样本自适应的语音合成。
技术研发人员:俞凯,杜晨鹏,郭奕玮,沈飞宇,梁正,刘知峻,陈谐
受保护的技术使用者:思必驰科技股份有限公司
技术研发日:
技术公布日:2024/1/16
- 还没有人留言评论。精彩留言会获得点赞!