一种自适应抗混响的麦克风阵列语音增强方法及其系统
本发明属于语音信号处理,具体涉及一种自适应抗混响的麦克风阵列语音增强方法及其系统。
背景技术:
1、麦克风阵列在各种语音通信、交互场景中得到了越来越多的应用,但其接收的语音信号在实际应用混响环境中受不同界面反射形成的混响干扰,特别是由不同尺寸、材质、界面模式等多样化环境引起的高度随机、多变混响给传统的麦克风阵列语音增强算法带来了极大的困难,语音抗混响技术引起研究界和业界的广泛关注。
2、amar a等提出的基于波束形成的去混响算法通过空间滤波来抑制来自不同方向的反射声波。然而,波束形成算法的性能受到许多因素的影响,例如阵列的大小和信号本身。最严重的缺点是无法抑制来自声源方向的混响信号;
3、li y等提出的基于逆滤波的去混响算法包括两个步骤:盲系统识别和逆滤波计算。这种去混响的核心是通过盲估计方法获得房间混响信息,从而构造逆滤波器。由于通常盲估计算法不能保证实际环境中的性能,这种方法效果有限;
4、chen y等提出的加权预测误差(weighted prediction error,wpe)通过使用多个先前帧信号进行加权来预测当前帧信号中的混响分量,但在不同混响环境下如何优化确定wpe算法参数如加权系数影响了其实际应用;
5、kinoshita等提出一种基于神经网络频谱估计的去混响算法(dnn),对多通道的带噪语音进行语音特征提取后作为神经网络的输入,并以当前帧的混响幅度谱与估计的当前帧幅度谱的差作为神经网络输出,当前帧纯净语音的幅度谱为参考目标特征;
6、tan k等提出的rnnoise算法与传统算法的处理流程类似,基于掩蔽mask的方式,通过计算估计掩码后与对应时频点相乘来进行降噪,其中掩码的计算估计引入了深度学习算法;
7、hu y等设计了一种深度复数卷积循环神经网络(deep complex convolutionrecurrent network,dccrn),该模型使得cnn和rnn都能够处理复数运算,同时高效地结合dcu-net和crn已有的优势,采用了lstm来对时域内容建模,实验证明能够显著降低训练参数和计算资源消耗。
8、尽管传统的基于学习的去混响方法能够在设计良好的训练之后实现令人满意的性能,但是在失配环境下,由于其混响相关信息不包含在训练数据中,它们的性能趋于恶化。这个问题的直接解决方案是扩大数据样本,以覆盖尽可能多的环境,然而这对于麦克风阵列实际应用来说非常困难。
9、有鉴于此,提出一种自适应抗混响的麦克风阵列语音增强方法及其系统是非常具有意义的。
技术实现思路
1、为了解决现有深度学习等智能算法训练模型与实际条件不适配而导致算法效果减弱的痛点问题,本发明提供一种自适应抗混响的麦克风阵列语音增强方法及其系统,以解决上述存在的技术缺陷问题。
2、第一方面,本发明提出了一种自适应抗混响的麦克风阵列语音增强方法,该方法包括如下步骤:
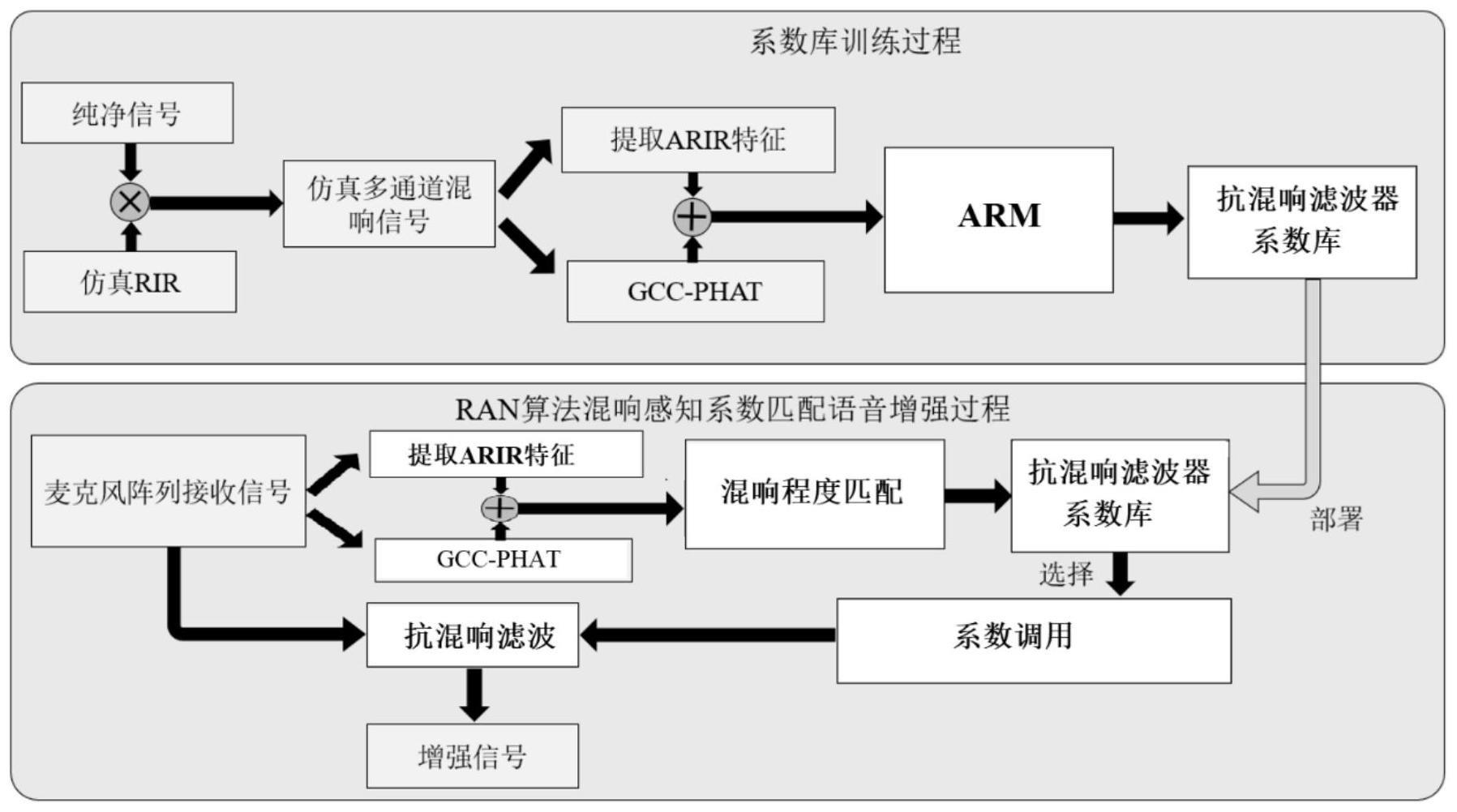
3、训练与预存步骤,响应于利用不同混响数据训练获得不同混响条件下的抗混响滤波器系数,形成抗混响滤波器系数库并预先保存以待后续选用;
4、估计与匹配步骤,对麦克风阵列实时接收到的信号进行混响特征提取,输入到混响程度分类器中进行估计,麦克风阵列根据估计结果选用预先保存的抗混响滤波器系数库,并在抗混响滤波器系数库中进行混响程度匹配选择调用合适的系数,将原始信号与经过混响程度匹配的抗混响滤波器系数进行抗混响滤波处理得到抗混响增强信号。
5、优选的,对麦克风阵列实时接收到的信号进行混响特征提取具体包括:
6、对原始麦克风阵列信号提取的gcc-phat特征以及近似房间混响感知特征arir两种特征进行特征融合,拼接成一维的特征输入向量作为训练抗混响滤波器系数库的神经网络模型模型arm的输入特征;
7、其中,近似房间混响感知特征arir通过麦克风阵列原始输入信号与麦克风阵列波束形成的输出信号进行互相关运算,以提取环境的近似混响特征;
8、其中,gcc-phat为本领域通用的信号特征形式,具体描述如下:
9、麦克风阵列i通道和j通道接收信号可表示为:
10、xi=ais(t-τi)+ni(t)
11、xj=ajs(t-τj)+nj(t)
12、其中s(t)表示声源信号,ai、aj分别为i通道和j通道的衰减系数,τi、τj分别为i通道和j通道的时延时间,ni(t)、nj(t)分别表示i通道和j通道采集的环境噪声,则gcc-phat特征表示为:
13、
14、
15、其中gij(ω)为通道间信号的互功率谱,xi(ω)和xj(ω)分别为xi(t)和xj(t)的傅里叶变换,(·)*表示取复共轭,φij(ω)为频域加权函数,其形式如下:
16、
17、近似房间混响感知特征arir表示如下:
18、
19、其中,m表示麦克风阵列通道数;ybf(n,θ0)表示麦克风阵列波束形成输出,xm(n)表示麦克风阵列第m通道的原始信号。
20、进一步优选的,还包括:抗混响滤波器系数库的神经网络模型arm采用标准dnn网络模型框架;
21、其中,原始麦克风阵列信号提取gcc-phat特征和arir特征进行特征融合,拼接成一维特征输入向量送入神经网络作为输入层,隐藏层采用双层的全连接层,网络的输出为特定混响条件下期望方向的波束形成系数,即训练目标,网络的输出层的维度是m×l,其中m为阵元个数,l为每个通道的系数阶数;
22、将输出结果作为卷积核参数与原始多通道信号进行卷积操作得到增强信号yout(n),并与目标参考信号ytarget(n)在时域上求损失,再进行梯度运算和反向传播。
23、进一步优选的,还包括:
24、arm模型采用mse作为训练的损失函数:
25、
26、其中,yout(n)表示增强的单通道输出信号,ytarget(n)表示幅度控制权重后的目标信号,lall为样本总数。
27、进一步优选的,还包括:神经网络模型arm的训练次数epoch设置为300次,批处理大小batch_size设置为24,学习率采用指数型衰减,初始设置为0.001,衰减率为0.98,并采用adma优化器。
28、进一步优选的,还包括:
29、获得近似房间混响感知特征arir后根据计算公式计算arir能量衰减比rarir;
30、根据计算获得的arir能量衰减比rarir与混响时间rt60对应映射关系进行混响程度适配;
31、arir能量衰减比rarir计算公式如下:
32、
33、其中,rarir越大则表示衰减越厉害,则表征越小的房间混响程度。
34、进一步优选的,所述训练与预存步骤在服务器或计算机端进行,所述估计与匹配步骤在嵌入式系统上进行。
35、第二方面,本发明实施例还提供一种自适应抗混响的麦克风阵列语音增强系统,该系统包括计算机系统和嵌入式系统,所述计算机系统包括训练模块和预存模块,所述嵌入式系统包括估计模块、匹配模块和处理模块:
36、训练模块,用于利用不同混响数据训练获得不同混响条件下抗混响滤波器系数,形成抗混响滤波器系数库;
37、预存模块,用于预先保存形成的抗混响滤波器系数库以待后续选用;
38、估计模块,用于对麦克风阵列实时接收到的信号进行混响特征提取,输入到混响程度分类器中进行估计;
39、匹配模块,用于麦克风阵列选用预先保存的抗混响滤波器系数库,并在抗混响滤波器系数库中进行混响程度匹配选择调用合适的系数;
40、处理模块,用于将原始信号与经过混响程度匹配的抗混响滤波器系数进行抗混响滤波处理得到抗混响增强信号。
41、优选的,所述嵌入式系统包括特征提取模块、arm模型模块和计算模块:
42、特征提取模块,用于对原始麦克风阵列信号提取的gcc-phat特征以及近似房间混响感知特征arir两种特征进行特征融合,拼接成一维特征输入向量作为训练抗混响滤波器系数库的神经网络模型模型arm的输入特征;
43、arm模型模块,用于训练抗混响滤波器系数库的神经网络模型arm并保存使用。
44、计算模块,用于获得近似房间混响感知特征arir后根据计算公式计算arir能量衰减比rarir。
45、与现有技术相比,本发明的有益成果在于:
46、(1)本发明的技术方案具备以自适应方式在不同混响环境下进行抗混响处理的功能,同时,通过事先训练并预存抗混响滤波器系数,实际使用中调取预存抗混响滤波器系数的方式,可显著降低实际应用中的系统实现复杂度。
47、(2)本发明公开的一种自适应抗混响的麦克风阵列语音增强方法可在不同混响环境进行自适应抗混响处理,从而提高麦克风阵列在不同混响环境下的语音增强性能。
- 还没有人留言评论。精彩留言会获得点赞!