一种基于改进谱减法的语音去噪方法
本发明属于语音增强,具体涉及一种基于改进谱减法的语音去噪方法。
背景技术:
1、语音去噪部署于语音系统前端,用于抑制噪声下语音信号的退化失真,提升语音信号的听觉质量和可懂性,以解决语音识别、声纹识别、场景录音和听力辅助等任务在某些极端场景下,噪声频谱污染严重、语音质量低下,进而影响到后端任务性能的共性问题。因此噪声问题是领域关注重点,有较多语音去噪方法被提出和应用。
2、目前已有的单通道和基于麦克风阵列的信号处理去噪方法和深度学习去噪方法尽管解决了部分场景的噪声问题,但仍然存在一些技术层面的不足,从而实际应用受限。这些不足可概括为如下方面:
3、(1)单通道的去噪方法中,如维纳滤波要求预期的纯净语音已知,小波变换的适用范围有限且去噪效果一般不佳,基于统计学和子空间的去噪方法计算量大,不适合于实时任务;
4、(2)基于麦克风阵列的去噪方法存在一定的实际部署问题,多个麦克风部署成本高昂,且某些极端场景的麦克风阵列构型下形成的波束噪声抑制一般,甚至是不可行的;
5、(3)深度学习的去噪方法多是数据驱动的,去噪效果依赖于训练数据质量和规模,且参数量庞大,实际部署有一定门槛,应用有限。
6、因此,亟需一种适用性强、运算量小、实时性高、部署成本低的语音去噪方法。
技术实现思路
1、有鉴于此,本发明的目的在于提供一种基于改进谱减法的语音去噪方法。本发明旨解决现有语音去噪方法针对语音识别、声纹识别、场景录音和听力辅助等任务,存在适用范围小、运算量大、实时性差、部署成本高的问题。
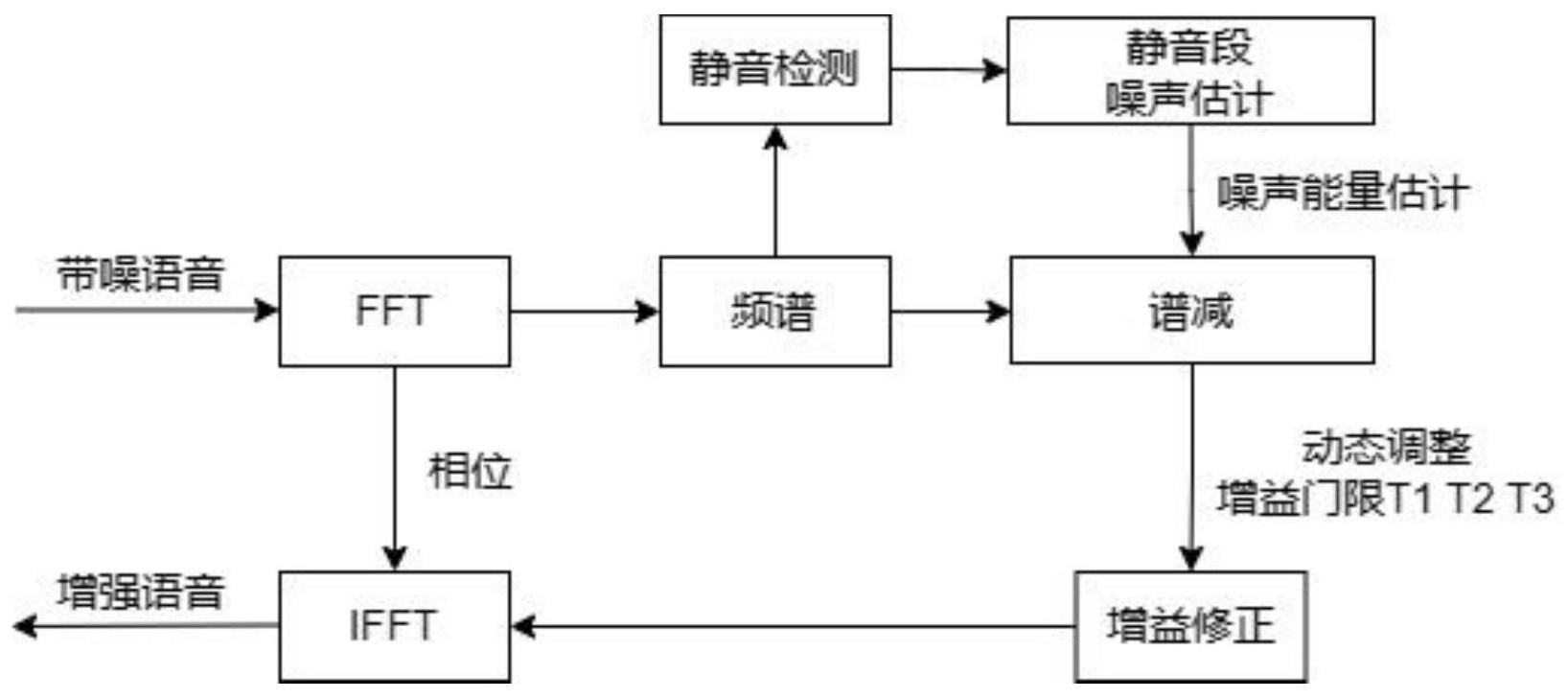
2、为达到上述目的,本发明提供了一种基于改进谱减法的语音去噪方法,包括以下步骤:
3、s1.输入带噪语音,对带噪语音的信号进行预处理,将信号从时域维度转换到帧维度;
4、s2.采用傅里叶变换,获取信号全段频谱;
5、s3.逐帧计算人声所在子频带的频谱能量占比;
6、s4.生成语音屏蔽掩码,估计噪声;
7、s5.根据调节因子划分语音浊音、语音清音和噪声;
8、s6.对语音浊音、语音清音、噪声进行谱减后权重修正。
9、进一步,所述步骤s1中,预处理操作包括预加重、分帧和加窗。
10、进一步,所述步骤s1中,加窗选用汉宁窗函数。
11、进一步,所述步骤s3包括以下子步骤:
12、s3.1在频域上划分出人声能量集中的子频带,子频带的频率区间:300至3400hz;
13、s3.2统计人声所在子频带的频谱能量esub与信号全频域上的频谱能量eall;
14、s3.3计算子频带的频谱能量占比ren,计算表达式如下:
15、进一步,所述步骤s3.2中,人声所在子频带的频谱能量esub,计算表达式如下:
16、
17、式中,fstart、fend均为截止频率,fstart=300hz,fend=3400hz;s为频率f对应的幅值。
18、进一步,所述步骤s4包括以下子步骤:
19、s4.1设置能量占比阈值ten,通过能量占比阈值ten比较产生帧维度的语音段的屏蔽掩码maskn,maskn的计算表达式如下:
20、
21、s4.2语音屏蔽掩码与频谱能量相乘,得到噪声频谱估计。
22、进一步,所述步骤s4.1中,能量占比阈值ten为0.6。
23、进一步,所述步骤s5包括以下子步骤:
24、s5.1信号全段逐帧计算平均幅度和过零率两频域特征,取比值作为抑制函数的调节因子,如下式:
25、
26、式中,aa代表音频信号平均幅度;zcr代表短时过零率;f代表抑制函数的调节因子;
27、s5.2根据调节因子划分噪声、浊音和清音的门限值t1和t2,如下式:
28、t1=α1*max(f)+α2*min(f)
29、t2=β1*max(f)+β2*min(f)
30、式中,α1、α2代表t1对应的调节因子,α1+α2=1;β1、β2代表t2对应的调节因子,β1+β2=1;
31、f<t1,划分为噪声;t1<f<t2,划分为清音;t2<f,划分为浊音。
32、进一步,所述步骤s6的具体步骤如下:
33、设置谱减后信号频谱权重,噪声段的修正权重为w1,语音清音段的修正权重为w2,浊音段的修正权重为w3,然后作谱减后信号的权重修正,得到去噪后的信号频谱,如下式:
34、
35、式中,为去噪后的信号频谱;为噪声段的信号频谱;为语音清音段的信号频谱;为浊音段的信号频谱。
36、进一步,所述步骤s6中,噪声段的修正权重w1为0.6,语音清音段的修正权重w2为0.8,浊音段的修正权重w3为1.1
37、本发明的有益效果在于:
38、本发明公开了一种基于改进谱减法的语音去噪方法,针对语音识别、声纹识别、场景录音和听力辅助等任务中的噪声问题,能够实时的、有效的抑制平稳和非平稳噪声,显著提升语音信噪比,同时,能够保证语音信号有效部分不受前端去噪带来的失真影响,适用于各语音任务下系统的前端去噪,提升系统处理速率及性能。
39、本发明的其他优点、目标和特征在某种程度上将在随后的说明书中进行阐述,并且在某种程度上,基于对下文的考察研究,对本领域技术人员而言将是显而易见的,或者可以从本发明的实践中得到教导。本发明的目标和其他优点可以通过下面的说明书来实现和获得。
技术特征:
1.一种基于改进谱减法的语音去噪方法,其特征在于,包括以下步骤:
2.根据权利要求1所述的一种基于改进谱减法的语音去噪方法,其特征在于:所述步骤s1中,预处理操作包括预加重、分帧和加窗。
3.根据权利要求2所述的一种基于改进谱减法的语音去噪方法,其特征在于:所述步骤s1中,加窗选用汉宁窗函数。
4.根据权利要求1所述的一种基于改进谱减法的语音去噪方法,其特征在于,所述步骤s3包括以下子步骤:
5.根据权利要求4所述的一种基于改进谱减法的语音去噪方法,其特征在于:所述步骤s3.2中,人声所在子频带的频谱能量esub,计算表达式如下:
6.根据权利要求5所述的一种基于改进谱减法的语音去噪方法,其特征在于,所述步骤s4包括以下子步骤:
7.根据权利要求6所述的一种基于改进谱减法的语音去噪方法,其特征在于:所述步骤s4.1中,能量占比阈值ten为0.6。
8.根据权利要求7所述的一种基于改进谱减法的语音去噪方法,其特征在于,所述步骤s5包括以下子步骤:
9.根据权利要求8所述的一种基于改进谱减法的语音去噪方法,其特征在于,所述步骤s6的具体步骤如下:
10.根据权利要求9所述的一种基于改进谱减法的语音去噪方法,其特征在于,所述步骤s6中,噪声段的修正权重w1为0.6,语音清音段的修正权重w2为0.8,浊音段的修正权重w3为1.1。
技术总结
本发明公开了一种基于改进谱减法的语音去噪方法,包括以下步骤:输入带噪语音,对带噪语音的信号进行预处理,将信号从时域维度转换到帧维度;采用傅里叶变换,获取信号全段频谱;逐帧计算人声所在子频带的频谱能量占比;生成语音屏蔽掩码,估计噪声;根据调节因子划分语音浊音、语音清音和噪声;对语音浊音、语音清音、噪声进行谱减后权重修正。本发明一种基于改进谱减法的语音去噪方法,能够实时的、有效的抑制平稳和非平稳噪声,显著提升语音信噪比,同时能够保证语音信号有效部分不受前端去噪带来的失真影响,适用于各语音任务下系统的前端去噪,提升系统处理速率及性能。
技术研发人员:尹宏鹏,唐丹,秦岩,蒋炜杰,易旻晗
受保护的技术使用者:重庆大学
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!