目标人声提取方法、电子设备及存储介质与流程
本技术涉及智能终端,尤其涉及一种目标人声提取方法、电子设备及存储介质。
背景技术:
1、近年来,voip(voice over internet protocol,基于ip的语音传输)通话、语音会议等被广泛应用。然而,在日常的voip通话、语音会议等场景中,目标人声在被设备麦克风接收的同时,其他声音(如非目标人声、非人声等)也会被该设备的麦克风收录,导致设备麦克风接收的声音为混合语音,影响了通话质量,降低了用户的听觉体验。
2、因此,如何在混合语音中提取到目标人声,以提升通话质量是亟待解决的问题。
技术实现思路
1、本技术实施例提供一种目标人声提取方法、电子设备及存储介质。针对多说话人语音混合场景,该方法能够实现在混合语音中提取出目标人声,以此提高通话质量,进而提升远端用户的听觉体验。
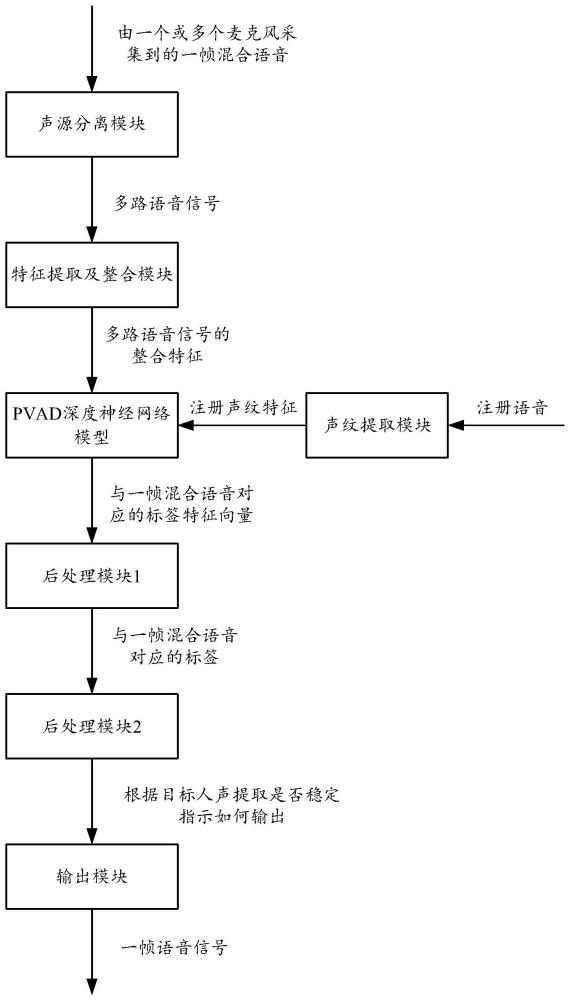
2、第一方面,本技术实施例提供一种目标人声提取方法。该方法应用于第一电子设备中,包括:第一电子设备获取当前帧混合语音;第一电子设备对当前帧混合语音进行声源分离,得到分离后的多路语音信号;第一电子设备将多路语音信号的整合特征以及目标人的声纹特征输入到pvad深度神经网络模型中,确定与当前帧混合语音对应的目标标签;其中,目标标签用于指示在多路语音信号中是否存在一路语音信号为目标人声,以及在多路语音信号中存在一路语音信号为目标人声时,目标标签还用于指示目标人声所在的语音信号分离通道;当目标标签指示在多路语音信号中存在一路语音信号为目标人声时,根据目标标签获取一路语音信号,作为与当前帧混合语音对应的目标人声提取结果。
3、在本实施例中,第一电子设备可以在帧级别上对混合语音进行目标人声提取操作。示例性的,第一电子设备可以是手机、平板电脑等。
4、在本实施例中,目标人的声纹特征可以是通过声纹提取模块对目标人的注册声音进行提取而得到的。
5、在本实施方式中,pvad深度神经网络模型的输入为多路语音信号的整合特征以及目标人的声纹特征,输出可以为与当前帧混合语音对应的标签。示例性的,若pvad深度神经网络模型输出标签0,则表示表明当前帧混合语音非目标人声;若pvad深度神经网络模型输出标签1~n中的任意一个,则表明目标人声在与该标签对应的分离语音通道上。
6、这样,针对多说话人语音混合场景,该方法能够实现在混合语音中提取出目标人声,以此提高通话质量,进而提升远端用户的听觉体验。
7、根据第一方面,第一电子设备将多路语音信号的整合特征以及目标人的声纹特征输入到pvad深度神经网络模型中之后,该方法还包括:
8、第一电子设备通过pvad深度神经网络模型输出与当前帧混合语音对应的标签特征向量;其中,标签特征向量中的各个元素值分别为与各个标签分别对应的概率值;第一电子设备将概率值最大的一个标签作为与当前帧混合语音对应的目标标签。
9、若一帧混合语音通过声源分离得到n路语音信号,则标签特征向量的维度为1×(n+1),在标签特征向量中各个元素值为与各个标签分别对应的概率值。也即,标签特征向量包括n+1个元素,这n+1个元素的值为与n+1个标签(如标签0、标签1、标签2、……、标签n)分别对应的概率。
10、这样,pvad深度神经网络模型基于多路语音信号的整合特征以及目标人的声纹特征对目标人声和非目标人声进行区分,并计算与各个标签分别对应的概率值,将概率值最大一个标签作为输出,以此标识对当前帧混合语音的目标人声提取结果。
11、根据第一方面,或者以上第一方面的任意一种实现方式,第一电子设备将多路语音信号的整合特征以及目标人的声纹特征输入到pvad深度神经网络模型中,确定与当前帧混合语音对应的目标标签,包括:
12、第一电子设备通过pvad深度神经网络模型输出与当前帧混合语音对应的标签特征向量;其中,标签特征向量中的各个元素值分别为与各个标签分别对应的概率值;
13、第一电子设备通过预设的有限状态机模型根据标签特征向量,确定与当前帧混合语音对应的目标标签;
14、其中,在有限状态机模型中,标签初始状态为与当前帧混合语音的前一帧混合语音对应的目标标签;有限状态机模型的状态转移条件用于减少目标标签序列中标签0的数量,标签0用于指示在多路语音信号中任意一路语音信号均非目标人声。
15、考虑到基于pvad深度神经网络模型的目标人声提取结果可能存在有误的情形,例如,针对一帧包含目标人声的混合语音,pvad深度神经网络模型得到与目标人声提取结果对应的标签为标签0(指示当前帧混合语音分离后的多路语音信号均非目标人声),使得与该帧混合语音对应的目标人声无法被成功提取。这样,在对连续的多帧混合语音进行目标人声提取时,可能会导致提取到的目标人声存在漏字的问题,从而影响用户的听觉体验。
16、在本实施方式中,为了减少提取到的目标人声的漏字问题,在有限状态机模型中,除了根据最大标签概率值进行标签状态转移,还对标签0到其他标签的状态转移条件进行了限定,以及对其他标签到标签0的状态转移条件进行了限定。其中,标签0到其他标签(标签1~标签n)的状态转移条件相对容易,而其他标签到标签0的状态转移条件相对更难。
17、根据第一方面,或者以上第一方面的任意一种实现方式,在有限状态机模型中:由标签0至标签x的状态转移条件为:且由标签x至标签0的状态转移条件为:且其中,标签特征向量为与标签x对应的概率值;m1、m2、m3为预设的阈值;m1>m2,m1>m3,标签x用于指示在多路语音信号中第x路语音信号为目标人声,1≤x≤n,x为整数,n为分离得到的语音信号总路数。
18、示例性的,当n=2时,阈值m1可以设置为0.9,阈值m2可以设置为0.5,阈值m3可以设置为0.1。
19、在本实施例中,在第一电子设备的有限状态机模型中,不仅根据最大标签概率值进行标签状态转移,标签0到标签x(标签1~标签n)的状态转移条件以及标签x(标签1~标签n)到标签0的状态转移条件还被进行了特殊限制,由标签0向标签x的状态转移条件相对容易,由标签x向标签0的状态转移条件相对较难,以通过有限状态机模型的处理来尽量减少最终输出标签序列中标签0的数量,进而使得在目标人声存在的时候能够尽量缓解提取到的目标人声的掉字问题。
20、根据第一方面,或者以上第一方面的任意一种实现方式,pvad深度神经网络模型包括卷积神经网络层、长短期记忆网络层和全连接层;
21、第一电子设备将多路语音信号的整合特征以及目标人的声纹特征输入到pvad深度神经网络模型中,包括:在pvad深度神经网络模型中,将多路语音信号的整合特征输入到卷积神经网络层中,得到多路语音信号的高维整合特征;将多路语音信号的高维整合特征和目标人的声纹特征输入到长短期记忆网络层中,得到综合特征;将综合特征输入到全连接层中,得到标签特征向量。
22、其中,卷积神经网络层可以将多路语音信号的整合特征抽象到更高维度后,输入到长短期记忆网络层。在长短期记忆网络层,抽象到更高维度的多路语音信号的整合特征与注册声纹特征进行拼接,得到用于区分目标人声和干扰声音的综合特征。长短期记忆网络层可以有效利用历史信息,结合注册声纹所抽象出来的全局特征以及每帧混合语音提取到的局部特征,实现对目标人声和干扰声音的区分。进而,全连接层可以将长短期记忆网络层输出的特征映射成决策结果,输出标签特征向量。
23、根据第一方面,或者以上第一方面的任意一种实现方式,第一电子设备根据目标标签获取一路语音信号,作为与当前帧混合语音对应的目标人声提取结果,包括:如果根据目标标签确定当前目标人声提取稳定,则第一电子设备根据目标标签获取一路语音信号,作为与当前帧混合语音对应的目标人声提取结果。
24、根据第一方面,或者以上第一方面的任意一种实现方式,该方法还包括:如果根据目标标签确定当前目标人声提取不稳定,则第一电子设备将当前帧混合语音直接作为目标人声提取结果。
25、在本实施方式中,引入了突变平滑策略,第一电子设备根据输出标签突变情况判断当前目标人声提取情况是否稳定,进而根据判断结果指示输出模块选用目标人声提取结果进行输出,或者指示输出模块选用原混合语音进行输出。这样,针对输出标签较为平稳的连续多帧混合语音,输出模块选用目标人声提取结果进行输出,而针对输出标签突变过多的连续多帧混合语音,输出模块选用原混合语音进行输出,以此避免由于输出标签突变过多过快而导致用户对提取到的目标人声听觉体验不佳的问题。
26、根据第一方面,或者以上第一方面的任意一种实现方式,该方法还包括:第一电子设备根据与当前帧混合语音对应的目标标签统计当前标签突变数量;若当前标签突变数量不大于预设阈值,则第一电子设备确定当前目标人声提取稳定,否则第一电子设备确定当前目标人声提取不稳定。
27、其中,标签突变数量,用于指示与目标人声提取结果对应的标签突变情况;
28、例如,若与连续多帧语音信号对应的目标人声提取结果标签依次为“22222222221”,则该标签序列的最后两个标签“21”表示标签突变了一次,此时统计到的当前标签突变数量为1。
29、根据第一方面,或者以上第一方面的任意一种实现方式,在得到分离后的多路语音信号之后,该方法还包括:第一电子设备分别提取分离后的每路语音信号的log-mel频谱特征;第一电子设备将每路语音信号的log-mel频谱特征进行拼接,得到多路语音信号的整合特征。
30、假设,语音信号1的log-mel频谱特征1为[a1,a2,…,an],语音信号2的log-mel频谱特征2为[b1,b2,…,bn],……,语音信号n的log-mel频谱特征n为[n1,n2,…,nn],则这n个log-mel频谱特征拼接后,得到n路语音信号的整合特征为[a1,a2,…,an,b1,b2,…,bn,…,n1,n2,…,nn]。也即,若每路语音信号的log-mel频谱特征均为1×n向量,则n路语音信号的整合特征为1×nn向量。
31、根据第一方面,或者以上第一方面的任意一种实现方式,第一电子设备对当前帧混合语音进行声源分离,得到分离后的多路语音信号,包括:第一电子设备实时确定与当前帧混合语音对应的解混矩阵;第一电子设备基于解混矩阵对当前帧混合语音进行声源分离,得到分离后的多路语音信号。
32、为了实时地估计出解混矩阵,需要在每一帧混合语音信号被获取到时,对解混矩阵进行更新。在实时估计出解混矩阵之后,即可基于下文中的式(2)将获取到的当前帧混合语音信号分离为n路语音信号。
33、根据第一方面,或者以上第一方面的任意一种实现方式,该方法还包括:当目标标签指示在多路语音信号中任意一路语音信号均非目标人声时,第一电子设备将当前帧混合语音直接作为目标人声提取结果。
34、根据第一方面,或者以上第一方面的任意一种实现方式,第一电子设备获取当前帧混合语音,包括:第一电子设备获取由第一电子设备的一个或多个麦克风采集到的当前帧混合语音;
35、相应的,在第一电子设备根据目标标签获取一路语音信号,作为与当前帧混合语音对应的目标人声提取结果之后,该方法还包括:按照混合语音的帧序,第一电子设备将与当前帧混合语音对应的目标人声提取结果发送至第二电子设备;其中,第二电子设备与第一电子设备已建立通信连接。
36、这样,针对多说话人语音混合场景,第一电子设备首先对混合语音进行目标人声提取,再将提取到的目标人声向第二电子设备发送,以此提高了通话质量,进而提升了第二电子设备侧用户的听觉体验。
37、第二方面,本技术实施例提供一种电子设备。该电子设备包括:一个或多个处理器;存储器;以及一个或多个计算机程序,其中一个或多个计算机程序存储在存储器上,当计算机程序被一个或多个处理器执行时,使得电子设备执行第一方面以及第一方面中任意一项的目标人声提取方法。
38、第二方面以及第二方面的任意一种实现方式分别与第一方面以及第一方面的任意一种实现方式相对应。第二方面以及第二方面的任意一种实现方式所对应的技术效果可参见上述第一方面以及第一方面的任意一种实现方式所对应的技术效果,此处不再赘述。
39、第三方面,本技术实施例提供一种计算机可读存储介质。该计算机可读存储介质包括计算机程序,当计算机程序在电子设备上运行时,使得电子设备执行第一方面以及第一方面中任意一项的目标人声提取方法。
40、第三方面以及第三方面的任意一种实现方式分别与第一方面以及第一方面的任意一种实现方式相对应。第三方面以及第三方面的任意一种实现方式所对应的技术效果可参见上述第一方面以及第一方面的任意一种实现方式所对应的技术效果,此处不再赘述。
41、第四方面,本技术实施例提供一种计算机程序产品,包括计算机程序,当计算机程序被运行时,使得计算机执行如第一方面或第一方面中任意一项的目标人声提取方法。
42、第四方面以及第四方面的任意一种实现方式分别与第一方面以及第一方面的任意一种实现方式相对应。第四方面以及第四方面的任意一种实现方式所对应的技术效果可参见上述第一方面以及第一方面的任意一种实现方式所对应的技术效果,此处不再赘述。
43、第五方面,本技术提供了一种芯片,该芯片包括处理电路、收发管脚。其中,该收发管脚和该处理电路通过内部连接通路互相通信,该处理电路执行如第一方面或第一方面中任意一项的目标人声提取方法,以控制接收管脚接收信号,以控制发送管脚发送信号。
44、第五方面以及第五方面的任意一种实现方式分别与第一方面以及第一方面的任意一种实现方式相对应。第五方面以及第五方面的任意一种实现方式所对应的技术效果可参见上述第一方面以及第一方面的任意一种实现方式所对应的技术效果,此处不再赘述。
- 还没有人留言评论。精彩留言会获得点赞!