一种基于注意力变分自编码器的短视频博主风格化语音合成方法
本发明涉及变分自编码器模型,更具体地说,本发明涉及一种基于注意力变分自编码器的短视频博主风格化语音合成方法。
背景技术:
1、语音合成技术是将文本转换为可被人类听懂的语音的技术。它利用计算机算法和声学模型的组合,将输入的文本转化为自然流畅的语音输出。随着计算机性能和语音合成算法的不断提升,语音合成系统变得更加复杂且输出质量更高。现如今,语音合成技术广泛应用于各个领域,如语音播报、虚拟博主语音合成等,为我们的日常生活带来了乐趣和便利。
2、传统的语音生成方法通常由前端和后端两个模块组成。前端模块负责对输入文本进行分析,提取后端模块所需的语言学信息,包括文本正则化、词性预测、多音字消歧、韵律预测等。后端根据前端的分析结果,采用特定的方法生成语音波形。
3、目前,语音合成通常采用端到端的方式,只需输入文本或注音字符,系统就可以直接生成相应的音频波形。然而,如果希望合成多种风格的声音,则需要具有不同说话人的声音样本以便合成,无法直接合成多种风格的声音。
技术实现思路
1、针对现有技术中出现的不足,本专利提出一种基于注意力变分自编码器的短视频博主风格化语音合成方法。基于注意力变分自编码器的短视频博主风格化语音合成方法能够生成多种风格化的声音。它根据提供的人物风格,无需提供特定说话人的声音样本,就能够合成多种风格化的语音。该方法还引入了大五人格和情感风格标签,使得可以合成具有多种不同人格和情感的声音。
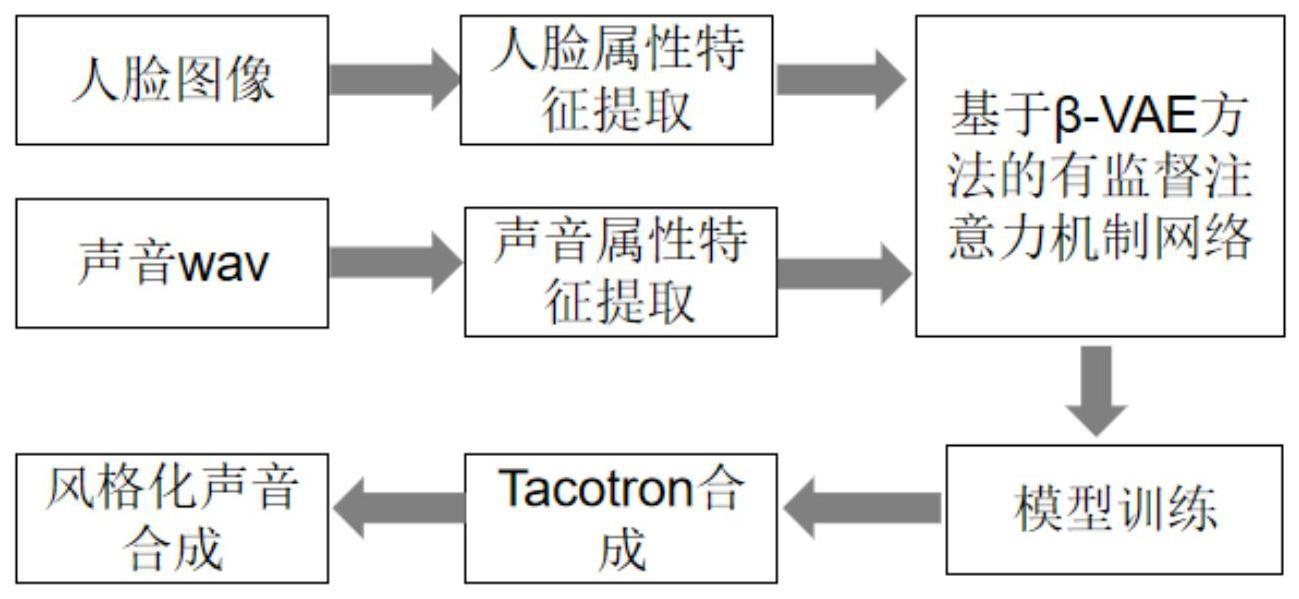
2、本发明的基于注意力变分自编码器的短视频博主风格化语音合成分为两个部分。第一部分为利用短视频博主视频构建风格化语音合成数据集。第二部分为通过一种基于注意力变分自编码器生成短视频博主风格化语音。再采用tacotron2生成模型从视频博主数据集中提取语音,并使用基于注意力的变分自动编码器将声音和短视频博主人物的属性相结合生成风格化的扬声器嵌入。然后使用tacotron2模型基于这些语音嵌入合成语音。通过博主相关的属性特征,合成风格化的声音。
3、为实现上述目的,本发明采用的技术方案:一种基于注意力变分自编码器的短视频博主风格化语音合成方法,包括以下步骤:
4、s1.构建人脸-语音数据集,下载第一印象数据集,从第一印象视频数据集中提取人脸图片和对应的语音声音;
5、s2.获得人脸关键特征的轮廓检测图像,输入步骤s1中的人脸数据集图像,利用deepface多个人脸属性特征提取模型,从步骤s1中的人脸数据集图像提取人脸的情感、大无人格的属性特征,并对声音数据集采用x-vector提取声音属性特征;
6、s3.构建基于β-vae方法的有监督注意力机制网络,在编码器和解码器之间增加1个iaff模块,结合注意力模块建立基于β-vae方法的有监督注意力机制网络;
7、采用x-vector提取的说话人嵌入特征通过编码器生成隐变量z,根据图像提取的说话人属性特征和隐变量z结合,然后经过iaff注意力模块,再送入到解码器进行解码,经过解码器解码以后,生成说话人嵌入;
8、在β-vae中添加condition,根据输入的属性条件合成风格化的语音,根据输入来进行输出,在训练集中是数据对(x,y),y是输入,即condition;x是我们期待的输出;
9、模型损失函数如下:
10、lcβvae=-dkl(q(z|x,y)||p(z|y))+β·eq(z|x,y)(log(p(x|z,y)))
11、其中,dkl是kl散度,使得编码器生成的隐变量尽可能符合标准正态分布,p代表真实向量,q代表结果向量,z代表隐向量,eq(z|x,y)代表重构损失,是解码器解码得到的向量和输入向量之间的mse损失,反映出vae生成的结果和输入之间的差异,对应的目标是使vae生成的结果和输入尽可能相似;
12、s4.以步骤s2得到的人脸属性特征和对应的声音特征作为训练数据集,使用adam训练步骤s3构建的基于β-vae方法的有监督注意力机制网络;
13、s5.输入属性特征值,根据步骤s2得到人脸属性特征和对应的声音特征,输入到步骤s4训练好的基于β-vae方法的有监督注意力机制网络中生成语音嵌入;
14、s6.利用多说话人tacotron2模型将步骤s5获得的风格化声音嵌入进行语音合成,合成声音。
15、步骤s2中,获得人脸属性特征和对应的语音特征包含如下步骤:
16、s2.1通过x-vector提取声音特征:x-vector接受任意长度的输入后将其转化为固定长度的特征表达;
17、s2.2根据脸型提取特征:采用mtcnn人脸检测模型来提取人脸标志以计算人脸形状,mtcnn网络结构是一个三级联级网络,分为p-net、r-net、和o-net三层网络结构;在mtcnn的三层网络结构中,网络输出形式为是否是人脸、边框回归值以及人脸特征点坐标;模型的最终损失函数具体可以表示为:
18、lmntcnn=αdetldet+αboxlbox+αlandmarksllandmarks
19、其中,αdetldet是人脸分类损失使用交叉熵作为损失函数,αboxlbox是边框回归值损失使用欧氏距离作为损失函数,αlandmarksllandmarks是人脸特征点坐标损失,使用欧氏距离作为损失函数;
20、s2.3根据情感、年龄、性别提取特征,采用deepface框架提取多个属性特征值;
21、s2.4根据体重提取特征,采用bmi体重预测模型,从图像中预测人物的体重属性特征;
22、s2.5根据大五人格提取特征,采用的是第一印象的短视频博主数据集,数据集中包含大五人格特征的标注,直接使用大五人格的属性特征。3.根据权利要求1所述的一种基于注意力变分自编码器的短视频博主风格化语音合成方法,其特征在于,步骤s6利用tacotron2模型将步骤s5获得的说话人风格化特征嵌入进行语音合成,生成的说话人特征嵌入经过tacotron模型合成为我们所听到的声音,根据属性标签合成不同风格的语音。
23、本申请与现有技术相比具有以下优点:基于注意力变分自编码器的短视频博主风格化语音合成方法通过加入新的iaff注意力机制模块,可以学习更全面的语音特征信息。该方法通过建立基于β-vae方法的有监督注意力机制网络,使人物属性特征和说话人声音相结合,可以根据人物属性标签合成不同风格的说话人声音。
技术特征:
1.一种基于注意力变分自编码器的短视频博主风格化语音合成方法,其特征在于,包括以下步骤:
2.根据权利要求1所述的一种基于注意力变分自编码器的短视频博主风格化语音合成方法,其特征在于,步骤s2中,获得人脸属性特征和对应的语音特征包含如下步骤:
3.根据权利要求1所述的一种基于注意力变分自编码器的短视频博主风格化语音合成方法,其特征在于,步骤s6利用tacotron2模型将步骤s5获得的说话人风格化特征嵌入进行语音合成,生成的说话人特征嵌入经过tacotron模型合成为我们所听到的声音,根据属性标签合成不同风格的语音。
技术总结
一种基于注意力变分自编码器的短视频博主风格化语音合成方法,属于变分自编码器网络模型技术领域。这种风格化语音合成方法将短视频博主语音合成方法分为两个部分,一部分利用短视频博主视频构建风格化语音合成数据集,第二部分为通过一种基于注意力变分自编码器合成风格化语音。该方法通过加入新的iAFF注意力机制模块,建立基于β‑VAE方法的有监督注意力机制网络,通过标签属性可以直接合成风格化博主语音。
技术研发人员:王元刚,陈波,段晓东
受保护的技术使用者:大连民族大学
技术研发日:
技术公布日:2024/1/16
- 还没有人留言评论。精彩留言会获得点赞!