一种声学场景分类的数据增强方法及系统
本发明涉及语音识别,尤其涉及一种声学场景分类的数据增强方法及系统。
背景技术:
1、深度学习在语音增强、自动语音识别(automatic speech recognition,asr)、声音分类、语音合成等各种音频处理任务中都取得了显著的成功。为了进一步提高它们的性能,许多研究努力集中在为特定的任务设计更好的网络架构。其中卷积神经网络、循环神经网络和卷积循环神经网络常被用作网络架构。虽然改进体系结构可以提供更好的性能,但这些方法容易过拟合,需要大量的训练数据。为了避免这个问题,人们已经在研究数据增强和正则化策略。
2、对于音频数据集的扩充,主要有两种方法:时域波形和时频域特征,如谱图、梅尔谱图和梅尔频倒谱系数。在dcase社区中,数据增强方法已被广泛用于克服数据有限的问题,对于波形数据,数据增强策略可以包括注入噪声、改变基音、改变速度、改变时间和速度扰动波形,在不干扰显著信息的情况下扩展数据集,在基于波形的方法中,裁剪是常用且有效的方法之一。salamon和bello提出利用时间拉伸、基音变换、动态范围压缩和添加外部数据集选择的背景噪声产生的额外训练数据,这些数据也应用于原始波形。针对时频域特征,specaugment提出了时间翘曲、频率掩蔽和时间掩蔽数据增强策略。虽然specaugment已经成功地应用到asr上,但是它在其他任务上的应用却受到了限制。例如,在语音增强任务中,时间轴和频率轴上的零掩码会降低性能。由于时频域特征是二维的,可以投影成二维图像,因此数据增强策略,特别是计算机视觉领域的混合样本数据增强(msda)类型。mixup通过改变一个随机参数γ来混合音频特征和标签的两个图像,该算法在图像分类任务中的性能已经被证明是有效的,但由于它将不同源分量的声谱图混合在一起的方式,在音频域中很难将它们分离出来。因此,mixup方法的性能受到了限制。cutout和specaugment分别对图像和谱图进行零掩码。虽然这些方法可以成功地应用于图像和谱图,但由于零掩蔽,显著的音频信息可能会丢失。cutmix随机附加一个图像的一部分到另一个图像。它应用一个随机生成的掩模来切割一个谱图区域并将其随机粘贴到另一个谱图区域。cutmix可以保留x1和x2的幅值信息,但是一幅图像的时频信息会随机移位到另一幅图像上,导致频移。
3、而且,上述这些增强方法只应用于深度神经网络的输入,而对隐藏空间的增强没有进行研究。mixup和between-class(bc)learning也是dcase任务中比较流行的数据增强方法,通过混合多个音频样本生成新的数据样本,并设计学习方法训练模型输出混合样本的预测。此外,chen et al.利用辅助分类器gan(acgan)生成假样本进行数据增强,但需要增加一个额外的鉴别器,这使得网络的收敛更加困难。
技术实现思路
1、本发明提供一种声学场景分类的数据增强方法及系统,用以解决现有技术中语音识别场景中音频数据集增强扩充存在的缺陷。
2、第一方面,本发明提供一种声学场景分类的数据增强方法,包括:
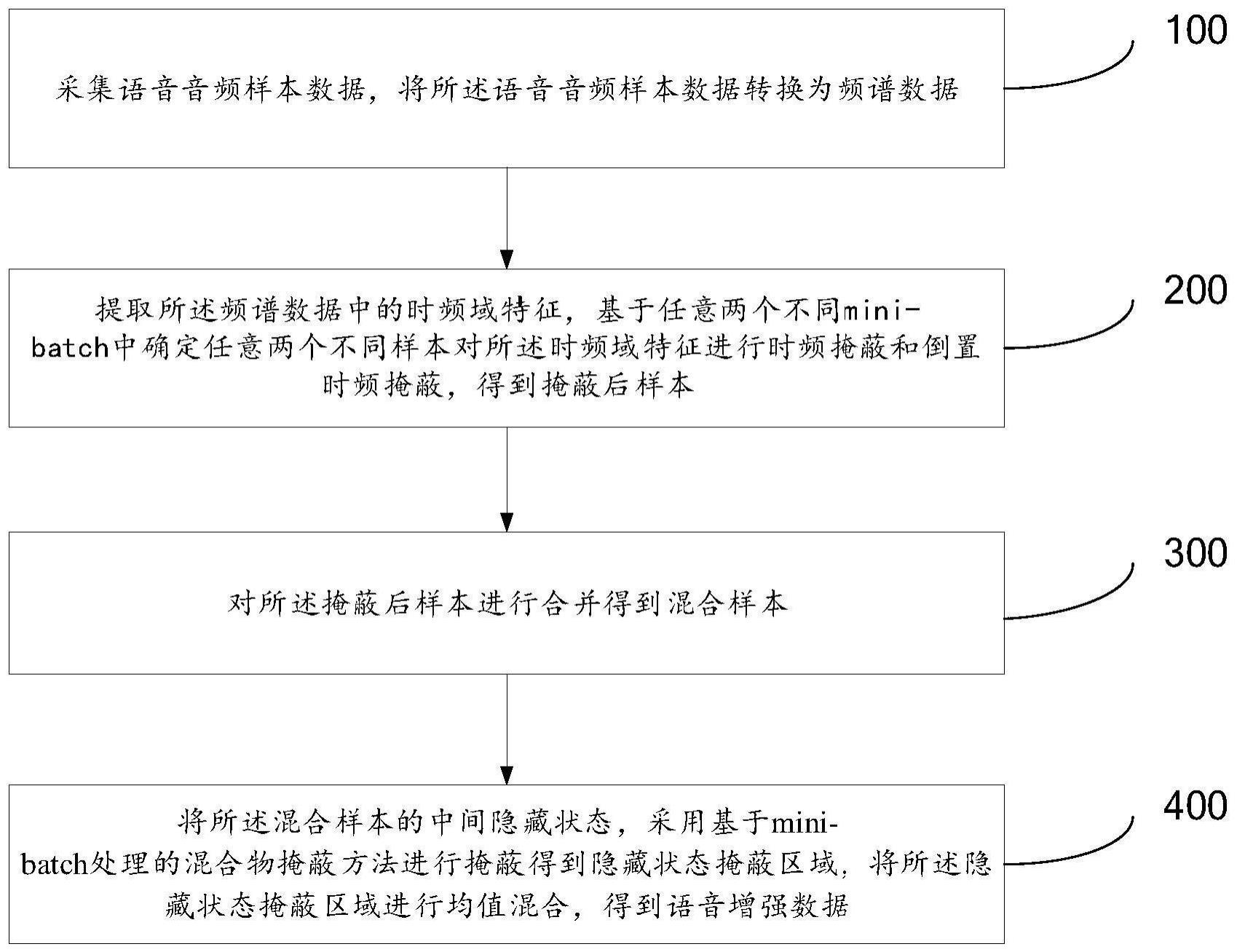
3、采集语音音频样本数据,将所述语音音频样本数据转换为频谱数据;
4、提取所述频谱数据中的时频域特征,基于任意两个不同小批量mini-batch中确定任意两个不同样本对所述时频域特征进行时频掩蔽和倒置时频掩蔽,得到掩蔽后样本;
5、对所述掩蔽后样本进行合并得到混合样本;
6、将所述混合样本的中间隐藏状态,采用基于mini-batch处理的混合物掩蔽方法进行掩蔽得到隐藏状态掩蔽区域,将所述隐藏状态掩蔽区域进行均值混合,得到语音增强数据。
7、根据本发明提供的一种声学场景分类的数据增强方法,采集语音音频样本数据,将所述语音音频样本数据转换为频谱数据,包括:
8、对所述语音音频样本数据进行预加重,得到预加重信号;
9、以预设采样点对所述预加重信号进行分帧,得到分帧后信号;
10、采用汉明窗对所述分帧后信号进行加窗处理,得到加窗信号;
11、对所述加窗信号进行快速傅里叶变换,确定三角带通滤波器的中心频率和滤波器个数之间间隔,对快速傅里叶变换后信号进行带通滤波后取对数,输出每个滤波器组对数能量;
12、基于所述每个滤波器组对数能量和所述滤波器个数之间间隔进行离散余弦变换,得到梅尔频谱数据。
13、根据本发明提供的一种声学场景分类的数据增强方法,提取所述频谱数据中的时频域特征,基于任意两个不同小批量mini-batch中确定任意两个不同样本对所述时频域特征进行时频掩蔽和倒置时频掩蔽,得到掩蔽后样本,包括:
14、在0至3中选取整数随机数,以所述整数随机数作为重复次数,确定基准频率频带宽度、基准时间频带宽度和预设频带选择系数,所述预设频带选择系数位于0至1之间;
15、基于所述基准频率频带宽度确定起始频带频率,基于所述基准时间频带宽度确定起始时间频率;
16、根据所述起始频带频率、所述基准频率频带宽度和所述预设频带选择系数得到结束频带频率,根据所述起始时间频率、所述基准时间频带宽度和所述预设频带选择系数确定结束时间频率;
17、根据所述重复次数重复执行频率掩蔽和时间掩蔽,获得所述掩蔽后样本。
18、根据本发明提供的一种声学场景分类的数据增强方法,对所述掩蔽后样本进行合并得到混合样本,包括:
19、获取任一时频域特征及对应的时频域标签,所述任一时频域特征属于频率间隔、时间间隔和时频域特征构成的维度空间;
20、在第一mini-batch中确定第一训练样本,在第二mini-batch中确定第二训练样本,在0至1区间内确定第一二进制掩码和第二二进制掩码,所述第一二进制掩码用于从两个图像中进行删除和填充位置,所述第二二进制掩码用于填充为1;
21、由所述第一训练样本中的时频域特征与所述第一二进制掩码进行元素积乘法,以及所述第二训练样本中的时频域特征与所述第一二进制掩码进行元素积乘法之后求和,得到所述混合样本中的时频域特征;
22、由所述第一训练样本中的标签与所述第二训练样本中的标签进行加权求和,得到所述混合样本中的标签。
23、根据本发明提供的一种声学场景分类的数据增强方法,将所述混合样本的中间隐藏状态,采用基于mini-batch处理的混合物掩蔽方法进行掩蔽得到隐藏状态掩蔽区域,将所述隐藏状态掩蔽区域进行均值混合,得到语音增强数据,包括:
24、在任一mini-batch中确定目标样本初始隐藏状态和另一样本隐藏状态,获取时间域的连续时间帧个数、起始时间和时间帧数,获取频率域的连续频率通道数、起始频率和频率信道数;
25、分别以所述起始时间和所述连续时间帧个数,以及所述时间帧数构建的搜索范围内,依次计算所述混合样本的目标样本初始隐藏状态以及另一样本隐藏状态的均值,得到目标样本增强隐藏时间状态;
26、分别以所述起始频率和所述连续频率通道数,以及所述频率信道数构建的搜索范围内,依次计算所述混合样本的目标样本初始隐藏状态以及另一样本隐藏状态的均值,得到目标样本增强隐藏频率状态;
27、由所述目标样本增强隐藏时间状态和所述目标样本增强隐藏频率状态输出所述语音增强数据。
28、根据本发明提供的一种声学场景分类的数据增强方法,所述目标样本初始隐藏状态和所述另一样本隐藏状态均属于由所述时间帧数和所述频率信道数构建的维度空间。
29、第二方面,本发明还提供一种声学场景分类的数据增强系统,包括:
30、采集转换模块,用于采集语音音频样本数据,将所述语音音频样本数据转换为频谱数据;
31、提取掩蔽模块,用于提取所述频谱数据中的时频域特征,基于任意两个不同mini-batch中确定任意两个不同样本对所述时频域特征进行时频掩蔽和倒置时频掩蔽,得到掩蔽后样本;
32、混合模块,用于对所述掩蔽后样本进行合并得到混合样本;
33、增强模块,用于将所述混合样本的中间隐藏状态,采用基于mini-batch处理的混合物掩蔽方法进行掩蔽得到隐藏状态掩蔽区域,将所述隐藏状态掩蔽区域进行均值混合,得到语音增强数据。
34、第三方面,本发明还提供一种电子设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现如上述任一种所述声学场景分类的数据增强。
35、第四方面,本发明还提供一种非暂态计算机可读存储介质,其上存储有计算机程序,该计算机程序被处理器执行时实现如上述任一种所述声学场景分类的数据增强。
36、本发明提供的声学场景分类的数据增强方法及系统,通过应用时频掩蔽来混合不同的音频数据样本,有效地保持每个音频样本的频谱相关性,还应用于中间隐藏空间增强,使模型不仅能关注特征中最具鉴别性的部分,而且能关注特征整体部分,从而提高了泛化能力。
- 还没有人留言评论。精彩留言会获得点赞!