基于人工智能的智能语音识别与机器翻译系统的制作方法
本发明涉及人工智能,尤其是基于人工智能的智能语音识别与机器翻译系统。
背景技术:
1、机器翻译给人们带来了极大的便利,机器翻译技术日趋成熟和完善,但在一些对翻译细节要求比较高的场合,机器翻译引擎还存在不少不尽如人意的地方。现有技术中对于机器翻译的方法比较成熟,且几乎不需要人工撰写翻译规则,所有的翻译信息都是自动地从语料中学习而获得,因此该方法最大程度地发挥了计算机高速运算的特点,极大地降低了人工成本。
2、随着科技的进步,国际交流的日益繁杂和信息量急剧增加,机器翻译极大程度地应用于人们的各项生产、生活中,由于语音信息采集环境中声源状况复杂,杂音多,极易使采集到的声音夹杂大量无关语音,导致语音识别和翻译出现错误,不利于实时翻译,且未经除杂降噪处理的声音信息直接处理更容易导致识别错误。
技术实现思路
1、本发明的目的是通过提出基于人工智能的智能语音识别与机器翻译系统,以解决上述背景技术中提出的缺陷。
2、本发明采用的技术方案如下:
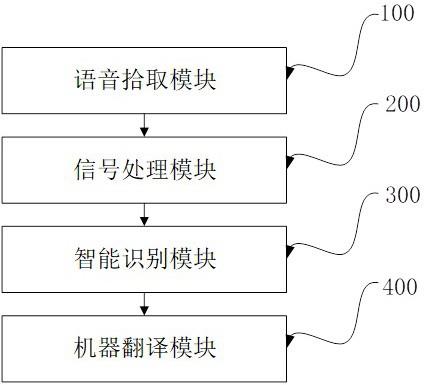
3、提供基于人工智能的智能语音识别与机器翻译系统,包括:
4、语音拾取模块:用于采集语音信号;
5、信号处理模块:用于对采集的语音信号进行去噪操作;
6、智能识别模块:用于对去噪处理后的语音信号进行语音信息的识别和特征提取;
7、机器翻译模块:用于根据提取的语音信号特征进行语音信号的翻译。
8、作为本发明的一种优选技术方案:所述去噪操作包括对语音信号基于改进的经验模态分解方法进行去噪处理和基于改进的小波阈值算法进行去噪处理。
9、作为本发明的一种优选技术方案:所述改进的经验模态分解方法具体如下:
10、在采集的语音信号上添加高斯白噪声构造新的个语音信号:
11、
12、其中,为独立正负成对且方差为1的高斯白噪声,为噪声系数;
13、对每个构造的新的语音信号通过emd分解获得第个imf分量并取平均值:
14、
15、
16、其中,为个imf分量平均值,为第个imf分量,为残余信号;
17、分解添加高斯白噪声的残余信号并取平均值,其中,为添加高斯白噪声经过emd分解后的第个imf分量:
18、
19、其中,为添加高斯白噪声的残余信号分解的个imf分量的平均值;
20、重复分解残余分量直至无法分解,得到最终的剩余残差,得到原始信号如下:
21、
22、其中,为第个imf分量平均值。
23、作为本发明的一种优选技术方案:所述改进的经验模态分解方法中,根据当前的snr水平自动调整,具体为:
24、计算语音信号的当前snr:
25、
26、其中,代表信号的功率,代表噪声的功率;
27、
28、
29、其中,为第个语音信号,为第个高斯白噪声,为样本数量;
30、根据高斯白噪声的目标订立目标snr为;
31、计算调整系数,;
32、将噪声系数乘以调整系数来得到新的噪声系数,。
33、作为本发明的一种优选技术方案:所述改进的小波阈值算法具体如下:
34、
35、
36、其中,为估计小波系数,为原始小波系数,为小波分解尺度,为正整数,为选择的阈值,为调整量,为数学常量,为调节因子。
37、作为本发明的一种优选技术方案:所述智能识别模块对语音信息的识别和特征提取具体如下:
38、基于去噪后的语音信号构建翻译语义映射的联合参数分析模型,通过对语音的谱峰监测采用连续光滑的曲线滤波,得到模糊语义关键词特征指向性函数,得到翻译输出的词汇指向性分布集:
39、
40、其中,为语音信号中的具体预警分布系数,为语音信号的谱长度,得到检测的语音信号的谱平均频率:
41、
42、其中,为语音信号的时频特征。
43、作为本发明的一种优选技术方案:所述机器翻译模块根据目标语言类型基于特征聚类检测翻译模型进行语音信号的翻译。
44、作为本发明的一种优选技术方案:所述特征聚类检测翻译模型具体如下:
45、
46、其中,为去噪后的语音信号幅度谱,为去噪后的语音信号相位谱,为模糊度匹配系数。
47、作为本发明的一种优选技术方案:所述机器翻译模块还根据目标语言种类进行翻译译文的整理。
48、作为本发明的一种优选技术方案:所述信号处理模块和所述机器翻译模块基于改进萤火虫算法分别进行imf分量个数预模糊度匹配系数的寻优。
49、作为本发明的一种优选技术方案:所述改进萤火虫算法具体如下:
50、
51、其中,为第只萤火虫的初始化位置,为间的随机数,、分别为萤火虫位置的上限和下限,为萤火虫种群数量;
52、萤火虫基于下式进行位置更新:
53、
54、其中,为第只萤火虫第次迭代的位置,为第只萤火虫第次迭代的位置,第只萤火虫第次迭代的位置;
55、对于萤火虫种群中亮度最高的萤火虫基于如下扰动进行位置更新:
56、
57、其中,为步长因子,为萤火虫种群中亮度最高的萤火虫第次迭代的位置,为萤火虫种群中亮度最高的萤火虫第次迭代的位置;
58、若算法运行到最大迭代次数或种群中相邻萤火虫的最大距离小于时,算法停止迭代;以亮度最高的萤火虫对应的位置为最优值,否则进行下一次迭代直至获取最优值。
59、本发明提供的基于人工智能的智能语音识别与机器翻译系统,与现有技术相比,其有益效果有:
60、本发明基于改进的经验模态分解方法和改进的小波阈值算法进行双重去噪处理,改进的经验模态分解方法能够在很大程度上消除模态混叠的问题,提高了分解效率,减小了噪声的残留和重构误差;改进的小波阈值算法利用指数函数的逼近性以及其在固定区间变换迅速的特点,能够合理控制函数的逼近速度,提高跟踪效率。通过双重去噪处理能够大大提升获取的语音信号的质量,同时基于特征提取处理和改进萤火虫算法优化的翻译模型提升机器翻译速度与翻译质量。
技术特征:
1.基于人工智能的智能语音识别与机器翻译系统,其特征在于,包括:
2.根据权利要求1所述的基于人工智能的智能语音识别与机器翻译系统,其特征在于:所述改进的经验模态分解方法具体如下:
3.根据权利要求2所述的基于人工智能的智能语音识别与机器翻译系统,其特征在于:所述改进的经验模态分解方法中,根据当前的snr水平自动调整,具体为:
4.根据权利要求3所述的基于人工智能的智能语音识别与机器翻译系统,其特征在于:所述改进的小波阈值算法具体如下:
5.根据权利要求4所述的基于人工智能的智能语音识别与机器翻译系统,其特征在于:所述智能识别模块(300)对语音信息的识别和特征提取具体如下:
6.根据权利要求5所述的基于人工智能的智能语音识别与机器翻译系统,其特征在于:所述机器翻译模块(400)根据目标语言类型基于特征聚类检测翻译模型进行语音信号的翻译。
7.根据权利要求6所述的基于人工智能的智能语音识别与机器翻译系统,其特征在于:所述特征聚类检测翻译模型具体如下:
8.根据权利要求7所述的基于人工智能的智能语音识别与机器翻译系统,其特征在于:所述机器翻译模块(400)还根据目标语言种类进行翻译译文的整理。
9.根据权利要求8所述的基于人工智能的智能语音识别与机器翻译系统,其特征在于:所述信号处理模块(200)和所述机器翻译模块(400)基于改进萤火虫算法分别进行imf分量个数预模糊度匹配系数的寻优。
10.根据权利要求9所述的基于人工智能的智能语音识别与机器翻译系统,其特征在于:所述改进萤火虫算法具体如下:
技术总结
本发明涉及人工智能技术领域,尤其为基于人工智能的智能语音识别与机器翻译系统,包括:语音拾取模块:用于采集语音信号;信号处理模块:用于对采集的语音信号进行去噪操作。智能识别模块:用于去噪处理后的语音信号进行语音信息的识别和特征提取;机器翻译模块:用于根据提取的语音信号特征进行语音信号的翻译。本发明基于改进的经验模态分解方法和改进的小波阈值算法进行双重去噪处理,能够大大提升获取的语音信号的质量,同时基于特征提取处理和改进萤火虫算法优化的翻译模型提升机器翻译速度与翻译质量。
技术研发人员:陈小波,彭小芳
受保护的技术使用者:北京神码数字技术有限公司
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!