一种CT影像设备提示音生成方法、装置及系统与流程
本发明涉及智能信息处理,尤其涉及一种ct影像设备提示音生成方法、装置及系统。
背景技术:
1、ct系统的呼吸提示音是扫描过程的重要一环,病人的屏气效果对肺部扫描的成像质量有着较大的影像。目前呼吸提示音需要专人录制,提示音更改时需要请人重新录制,比较繁琐且成本较大。同时一些地区医院需要录入当地的方言,医院往往采用通过手机录制再导入ct系统的方式,过程复杂费时。
技术实现思路
1、为了克服上述技术缺陷,本发明的目的在于提供一种ct影像设备提示音生成方法、装置及系统,用于解决现有ct影像设备提示音需要专人录制且无法更改的问题。
2、本发明公开了一种ct影像设备提示音生成方法,包括:
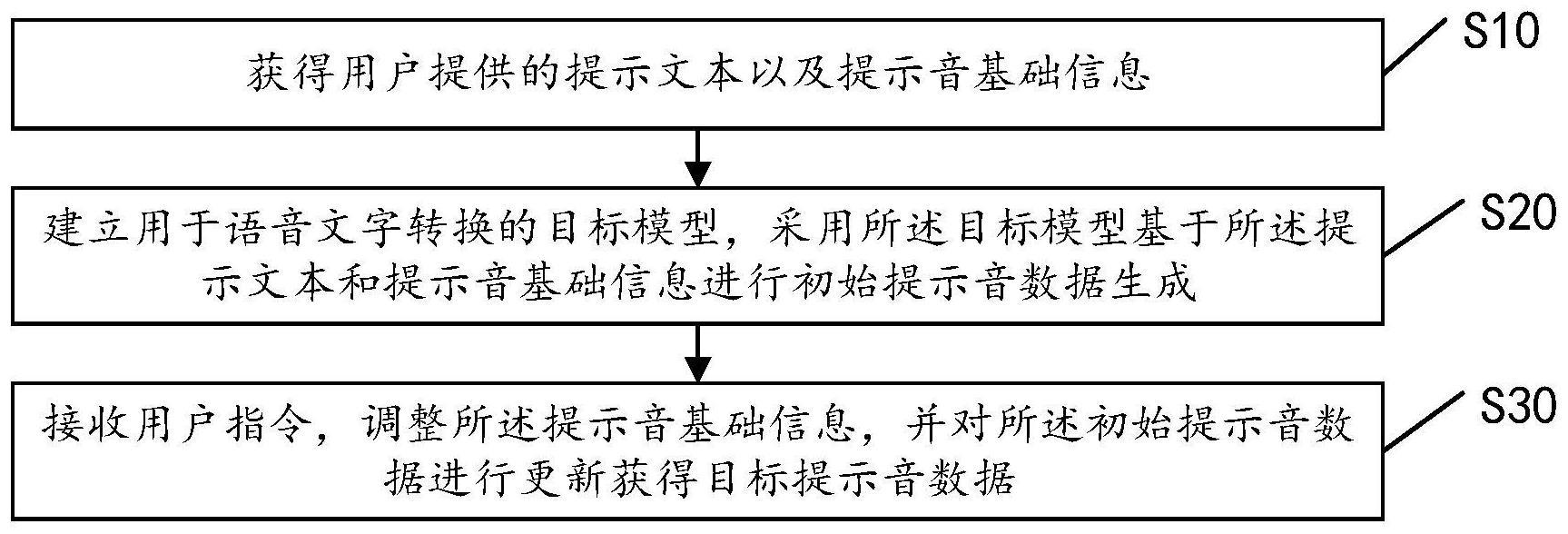
3、获得用户提供的提示文本以及提示音基础信息;
4、建立用于语音文字转换的目标模型,采用所述目标模型基于所述提示文本和提示音基础信息进行初始提示音数据生成;
5、接收用户指令,调整所述提示音基础信息,并对所述初始提示音数据进行更新获得目标提示音数据。
6、优选地,采用所述目标模型基于所述提示文本和提示音基础信息进行初始提示音数据生成,包括:
7、对所述提示文本进行预处理后编码,以获得处理数据;
8、将所述处理数据采用预训练好的循环神经网络进行处理,获得所述提示文本对应的语音特征,并生成语音波形;
9、根据所述语音波形基于所述提示音基础信息进行转换,生成初始提示音数据。
10、优选地,采用反卷积或反傅里叶变换将所述语音波形转换成初始提示音数据。
11、优选地,所述对所述提示文本进行预处理,包括:
12、对所述提示文本进行分词以及格式一致性转换。
13、优选地,在将所述处理数据采用预训练好的神经网络进行处理前,还包括:
14、获取所述处理数据,在预设数据库中确认是否存在与所述处理数据匹配的语音特征;
15、若是,则获取所述语音特征;
16、若否,则采用预训练好的神经网络进行处理,并在处理后更新至所述预设数据库中。
17、优选地,基于所述提示音基础信息进行转换,生成初始提示音数据,包括:
18、所述提示音基础信息包括音色、语速、音量;
19、根据所述提示音基础信息生成声学特征,根据所述声学特征对所述语音波形进行调整和变换,以生成初始提示音数据。
20、本发明还提供一种ct影像设备提示音生成装置,包括:
21、获取模块,用于获得用户提供的提示文本以及提示音基础信息;
22、生成模块,用于建立用于语音文字转换的目标模型,采用所述目标模型基于所述提示文本和提示音基础信息进行初始提示音数据生成;
23、调整模块,用于接收用户指令,调整所述提示音基础信息,并对所述初始提示音数据进行更新获得目标提示音数据。
24、本发明还提供一种ct影像系统,包括ct影像设备以及所述的ct影像设备提示音生成装置。
25、采用了上述技术方案后,与现有技术相比,具有以下有益效果:
26、本申请根据用户提供的提示音文本和提示音基础信息,采用目标模型将提示音文本转换成音频特征,而后根据提示音基础信息进行波形变换,以获得初始提示音数据,还可根据用于指令再次进行调整,以获得目标提示音数据,自主生成提示音,解决现有ct影像设备提示音需要专人录制且无法更改的问题。
技术特征:
1.一种ct影像设备提示音生成方法,其特征在于,包括:
2.根据权利要求1所述的提示音生成方法,其特征在于,采用所述目标模型基于所述提示文本和提示音基础信息进行初始提示音数据生成,包括:
3.根据权利要求2所述的提示音生成方法,其特征在于:
4.根据权利要求2所述的提示音生成方法,其特征在于,所述对所述提示文本进行预处理,包括:
5.根据权利要求2所述的提示音生成方法,其特征在于,在将所述处理数据采用预训练好的神经网络进行处理前,还包括:
6.根据权利要求2所述的提示音生成方法,其特征在于,基于所述提示音基础信息进行转换,生成初始提示音数据,包括:
7.一种ct影像设备提示音生成装置,其特征在于,包括:
8.一种ct影像系统,其特征在于,包括ct影像设备以及权利要求7所述的ct影像设备提示音生成装置。
技术总结
本发明提供了一种CT影像设备提示音生成方法、装置及系统,涉及智能信息处理技术领域,包括:获得用户提供的提示文本以及提示音基础信息;建立用于语音文字转换的目标模型,采用所述目标模型基于所述提示文本和提示音基础信息进行初始提示音数据生成;接收用户指令,调整所述提示音基础信息,并对所述初始提示音数据进行更新获得目标提示音数据,解决现有CT影像设备提示音需要专人录制且无法更改的问题。
技术研发人员:陆俊杰,柴春华,张亭亭,王瑶法
受保护的技术使用者:明峰医疗系统股份有限公司
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!