基于人工智能的一体机人机交互系统和方法与流程
本发明涉及音频数据处理,具体涉及一种基于人工智能的一体机人机交互系统和方法。
背景技术:
1、现有一体机的人机交互主要通过语言媒介进行,一体机根据采集到的人类语言数据做出相应的反应,从而实现人机交互。在商场中存在许多基于人机交互的一体机,但是商场中声音嘈杂,导致一体机所采集到的人类语言数据受到背景声音的干扰较为严重,影响人机交互的进行,因此需要对一体机采集到的音频数据进行去噪处理。
2、现有技术通常通过计算量小、操作简单的谱减法对一体机接收到的音频数据进行去噪处理,但是谱减法会产生“音乐噪声”,导致对一体机所采集到的音频数据的去噪效果较差,从而使得一体机的人机交互效果较差。
技术实现思路
1、为了解决现有技术通过谱减法对一体机接收到的音频数据进行去噪的方法会导致一体机的人机交互效果较差的技术问题,本发明的目的在于提供一种基于人工智能的一体机人机交互系统和方法,所采用的技术方案具体如下:
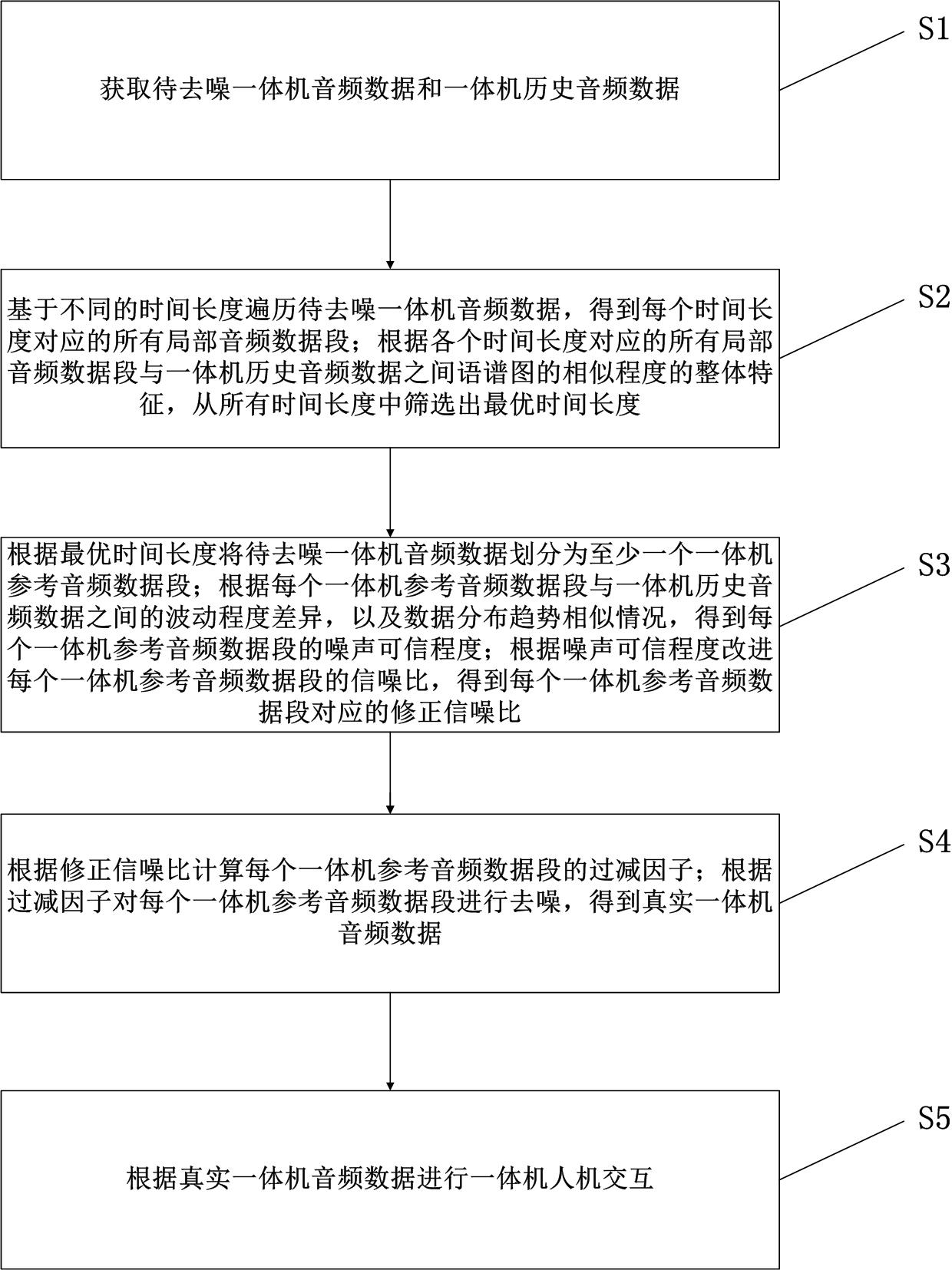
2、本发明提出了基于人工智能的一体机人机交互方法,所述方法包括:
3、获取待去噪一体机音频数据和一体机历史音频数据;
4、基于不同的时间长度遍历待去噪一体机音频数据,得到每个时间长度对应的所有局部音频数据段;根据各个时间长度对应的所有局部音频数据段与一体机历史音频数据之间语谱图的相似程度的整体特征,从所有时间长度中筛选出最优时间长度;
5、根据最优时间长度将待去噪一体机音频数据划分为至少一个一体机参考音频数据段;根据每个一体机参考音频数据段与一体机历史音频数据之间的波动程度差异,以及数据分布趋势相似情况,得到每个一体机参考音频数据段的噪声可信程度;根据所述噪声可信程度改进每个一体机参考音频数据段的信噪比,得到每个一体机参考音频数据段对应的修正信噪比;
6、根据所述修正信噪比计算每个一体机参考音频数据段的过减因子;根据所述过减因子对每个一体机参考音频数据段进行去噪,得到真实一体机音频数据;
7、根据所述真实一体机音频数据进行一体机人机交互。
8、进一步地,所述最优时间长度的获取方法包括:
9、依次选取每个时间长度中的每个局部音频数据段作为目标局部音频数据段,将目标局部音频数据段的时间长度作为目标时间长度;将一体机历史音频数据中所有与所述目标局部音频数据段对应的时间长度一致的音频数据段,作为对比音频数据段;将目标局部音频数据段的语谱图作为目标语谱图,将对比音频数据段的语谱图作为对比语谱图;
10、根据目标语谱图与每个对比语谱图在相同时间下语音数据能量的分布趋势相似程度,得到目标语谱图与每个对比语谱图之间的语谱图相似度;将大于预设相似阈值的语谱图相似度作为参考语谱图相似度;根据目标语谱图的参考语谱图相似度数量、最大语谱图相似度和所述目标时间长度,得到目标局部音频数据段的相似度评价值,所述参考语谱图相似度数量、所述最大语谱图相似度和所述目标时间长度均与所述相似度评价值呈正相关;
11、将每个时间长度对应的所有局部音频数据段的相似度评价值的均值,作为每个时间长度的参考评价值;将参考评价值最大的时间长度作为最优时间长度。
12、进一步地,所述语谱图相似度的获取方法包括:
13、在每个语谱图中,以对应频率从小到大的顺序对每个时间上的所有语音数据能量进行曲线拟合,得到每个语谱图中的所有时间索引值对应的拟合曲线;通过时间序列分解算法得到所述拟合曲线中每个频率对应的分布趋势值;
14、在每个时间索引值下,计算目标语谱图对应的拟合曲线和每个对比语谱图对应的拟合曲线之间相同频率的分布趋势值差异,将所有分布趋势值差异的均值的负相关映射值,作为每个时间索引值下目标语谱图与每个对比语谱图之间的分布趋势相似度;
15、将所有时间索引值对应的分布趋势相似度的均值,作为目标语谱图与每个对比语谱图之间的语谱图相似度。
16、进一步地,所述噪声可信程度的获取方法包括:
17、将一体机历史音频数据中所有时间长度为最优时间长度的连续音频数据段,作为最优对比音频数据段;将一体机参考音频数据段对应的语音信号,作为参考语音信号;将最优对比音频数据段对应的语音信号,作为对比语音信号;
18、通过动态时间距离规整算法计算每个参考语音信号与各个对比语音信号之间的dtw距离;计算每个参考语音信号的音频幅度极差和每个对比语音信号的音频幅度极差;根据所述dtw距离、所述音频幅度极差以及对比语音信号数量构建噪声可信程度模型,根据噪声可信程度模型得到每个一体机参考音频数据段的噪声可信程度。
19、进一步地,所述噪声可信程度模型包括:
20、
21、其中,为第个一体机参考音频数据段的噪声可信程度,为第个一体机参考音频数据段的参考语音信号的音频幅度极差,为第个对比语音信号的音频幅度极差,为第个一体机参考音频数据段的参考语音信号与第个对比语音信号之间的dtw距离,为对比语音信号数量,为以自然常数e为底的指数函数,为归一化函数。
22、进一步地,所述修正信噪比的计算公式包括:
23、
24、其中,为第个一体机参考音频数据段的修正信噪比,为第个一体机参考音频数据段的噪声平均功率,为第个一体机参考音频数据段的信号平均功率,为第个一体机参考音频数据段的噪声可信程度,为以10为底的对数函数。
25、进一步地,所述过减因子的获取方法包括:
26、将每个一体机参考音频数据段对应的修正信噪比的负相关映射值与预设参考常数的和值,作为每个一体机参考音频数据段的过减因子。
27、进一步地,所述真实一体机音频数据的获取方法包括:
28、对于任意一个一体机参考音频数据段:
29、将一体机参考音频数据段的过减因子代入到谱减法中,通过带入过减因子后的谱减法对一体机参考音频数据段进行去噪,得到每个一体机参考音频数据对应的去噪一体机参考音频数据段;
30、将所有的去噪一体机参考音频数据段按照时间顺序组合,得到真实一体机音频数据。
31、进一步地,所述相似度评价值的获取方法包括:
32、将所述参考语谱图相似度数量、所述最大语谱图相似度和所述目标时间长度的乘积,作为目标局部音频数据段的相似度评价值。
33、本发明还提出了一种基于人工智能的一体机人机交互系统,包括存储器、处理器以及存储在所述存储器中并可在所述处理器上运行的计算机程序,处理器执行所述计算机程序时实现任意一项一种基于人工智能的一体机人机交互方法的步骤。
34、本发明具有如下有益效果:
35、考虑到商场中机器噪声对一体机采集到的音频数据的影响较大,机器噪声的变化较为稳定并且存在一定的规律,因此为了获取更加准确的噪声音频数据,本发明根据不同时间长度的局部音频数据段与一体机历史音频数据进行相似度的计算,得到噪声整体置信度最高的最优时间长度,进一步根据最优时间长度的一体机参考音频数据段与一体机历史音频数据进行对比分析,得到每个一体机参考音频数据段的噪声可信程度,得到的噪声音频数据更加准确,从而提高后续的去噪效果。进一步地根据噪声可信程度得到每个一体机参考音频数据段对应的更加准确的修正信噪比,通过修正信噪比调整每个一体机参考音频数据段的过减因子,并根据调整后的过减因子对一体机参考音频数据段进行去噪,得到去噪效果更好的真实一体机音频数据,从而使得根据真实一体机音频数据进行一体机人机交互的效果更好。综上所述,本发明通过对音频数据处理得到的真实一体机音频数据进行一体机人机交互的效果更好。
- 还没有人留言评论。精彩留言会获得点赞!