一种基于小样本合成的输电运检的语音识别的方法与流程
本发明涉及电力移动巡检语音识别,具体涉及一种基于小样本合成的输电运检的语音识别的方法。
背景技术:
1、从目前输电运检的运检结果记录方法上看,更多的是在现场保留图片、语音及文本记录,巡检完毕后将记录结果进行系统录入。在语音数据的识别上多采用人工识别,工作效率低且重复性高。而通用的语音识别模型在识别运检语音时,对于专业词汇和线路的识别常常不够精准。
2、中国发明专利cn114822545a公开了一种提高专业领域语音识别率的方法,主要用于识别专业领域或特定行业的语音。专业领域中通常涉及大量的专业术语以及该专业领域各个应用部门结合了本地特征的特有名词,如含有所在地点名称的设备名、工作段名称乃至专业者的人名,因而语音识别错误率比较高,提出二次差频原理,自动建立差频专用词库,包含保存本地专用词汇的一级差频子库和保存专业术语的二级差频子库,以差频专用词汇为中心匹配拼音与文字,采用任意位置转换机制。提高语音识别的准确率,特别是能识别本地专业部门的专用词汇。但是该公开的专业领域的语音识别方法不适用电力移动巡检领域现有的巡检结果记录情况以及输电运检的现场嘈杂环境。
3、因此,提供一个精准识别输电运检语音的方法以解决现有输电运检语音识别中存在的工作效率低、识别不够精准的问题。
技术实现思路
1、本发明要解决的技术问题是如何提供一个精准识别输电运检语音的方法。
2、为了解决上述技术问题,本发明提供了一种基于小样本合成的输电运检的语音识别的方法,所述方法包括:
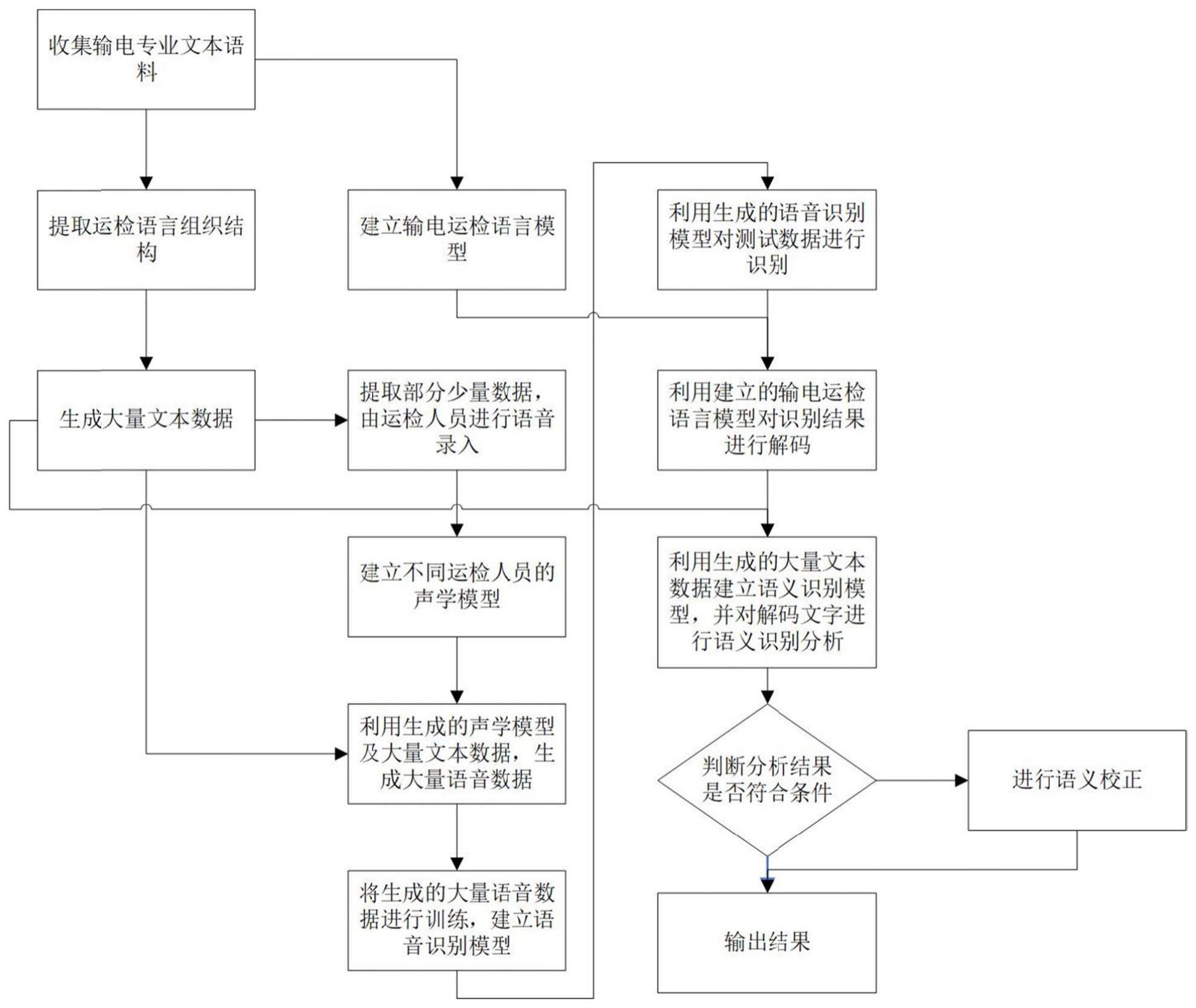
3、获取多个输电运检专业文本语料,依据所述多个输电运检专业文本语料分别建立输电运检专业语言模型和提取输电运检专业语言组织结构;
4、利用所述输电运检专业语言组织结构生成大量输电运检专业文本数据;
5、在所述大量输电运检专业文本数据中提取少量数据由多个输电运检人员进行语音录入以建立多个输电运检人员的声学模型;
6、利用所述多个输电运检人员的声学模型对在所述大量输电运检专业文本数据中提取少量数据后的剩余的所述大量输电运检专业文本数据训练生成对应的语音识别模型,并利用所述语音识别模型对测试数据进行识别;
7、利用建立的所述输电运检专业语言模型对所述测试数据的识别结果进行解码以识别出文字结果;以及
8、利用生成的所述大量输电运检专业文本数据建立语义识别模型,并对所述解码识别出的文字结果进行语义识别分析。
9、进一步的,所述方法还包括判断所述语义识别模型对所述解码识别出的文字结果进行语义识别分析的结果是否与所述解码识别出的文字结果相符合:
10、若符合,则输出所述解码识别出的文字结果;
11、若不符合,则基于所述语义识别分析的结果对所述解码识别出的文字结果进行语义校正。
12、进一步的,所述判断所述语义识别模型对所述解码识别出的文字结果进行语义识别分析的结果是否与所述解码识别出的文字结果相符合,具体包括以下步骤:
13、在生成的所述大量输电运检专业文本数据中进行关键字段提取,并打好标签进行训练生成对应的所述语音识别模型;
14、将建立的所述语义识别模型对语音识别的文字结果进行语义分割和所述关键词提取;
15、将所述提取的关键词与所述大量输电运检专业文本数据中提取的所述关键字段做相似度判断。
16、进一步的,将所述提取的关键词与所述大量输电运检专业文本数据中提取的所述关键字段做相似度判断过程中,所述相似度判断满足公式:
17、
18、其中,n表示第n类字段,m表示该字段数据库中的第m个数据,wer(n,m)即为输出文字与参考文本的字错率输出,其中,s表示替换的字数,d表示删除的字数,i表示插入的字数,n表示所述参考文本的字数。
19、进一步的,基于所述语义识别分析的结果对所述解码识别出的文字结果进行语义校正的方法还包括设定校正阈值,将符合校正区间的字段信息完成校正调整,满足公式:
20、output(n)=data(n,x)0<wer(n)<check_threhold
21、其中,check_threhold为设定的所述校正阈值,data(n,x)为数据库中第n类第x条数据,其中,wer(n,x)=wer_n,即校正方法包括:
22、若所述字错率为0,则无需校正;
23、若所述字错率大于0且小于所述校正阈值,则取出所述输电运检专业文本数据库中与其相似度最高的字段信息,进行校正调整;
24、若所述字错率大于所述校正阈值,则存在信息抽取错误,无法校正。
25、进一步的,所述在大量输电运检专业文本数据中提取少量数据由多个输电运检人员进行语音录入以建立多个输电运检人员的声学模型,其中,还包括将模拟输电运检现场的噪音数据与所述多个输电运检人员的语音录入相融合,以生成更完整更真实的输电运检语音数据。
26、优选的,所述语音识别过程中的解码方法为贪心搜索方法且满足公式:
27、score_greedy(t)=max(p_t)
28、其中,score_greedy(t)表示在时间t的分数,p_t表示在时间t的模型输出的概率分布,max操作表示选择最大的概率。
29、进一步的,所述语音识别过程中的解码方法还包括设定的概率阈值,将所述解码方法中的输出概率与设定的概率阈值作比较:
30、若所述输出概率大于等于所述设定的概率阈值,则所述概率阈值为贪心解码的输出;
31、若所述输出概率小于所述设定的概率阈值,则使用集束搜索的解码方法做结果的输出,其中,所述集束搜索满足公式:
32、
33、其中,thredhold是判断设定阈值,
34、若所有时间步score_greddy的贪心输出大于等于所述设定阈值,则最后所述解码结果输出output为贪心解码输出序列;
35、若存在任何一步score_greddy(i)小于所述设定阈值,则最后所述解码结果输出output为所述集束搜索的解码输出序列beam_sreach_output。
36、进一步的,所述beam_sreach_output输出公式:
37、beam_sreach_output=max(y∧(i)),i=1,…,k
38、其中,在所述集束搜索解码过程中,将会生成k个部分解,每个所述部分解是一个序列y∧(i),i=1,…,k0,计算所述每个部分解的分数,所述分数的计算公式满足:
39、score(y∧(i))=sum(logp(y_t(i)∣y_1(i),…,y_(t-1)(i)))
40、其中,y_t(i)是表示所述部分解i在时间t的元素,y_1(i),…,y_(t-1)(i)表示所述部分解i在时间步1到t-1的元素。
41、进一步的,针对所述贪心搜索的分数不高的语音数据进行所述集束搜索再判断,以实现解码过程中的准确度与反应速度的动态平衡。
42、与现有技术相比,本发明具有如下有益效果:
43、本发明通过在大量输电运检专业文本数据中提取少量数据由不同输电运检人员进行语音录入以建立不同输电运检人员的声学模型,进而再进行解码、语义分析和校正,实现了一个基于小样本合成的输电运检语音识别的方法,且语音识别精准、识别效率高。
- 还没有人留言评论。精彩留言会获得点赞!