语音识别方法、装置、设备和存储介质与流程
本申请属于语音识别,具体涉及一种语音识别方法、装置、设备和存储介质。
背景技术:
1、在高等级生物安全实验室场景下,实验人员可能需要记录大量的实验数据,如样品编号、浓度、重量等,但由于实验人员需要穿着特殊防护服,繁琐的手动操作会在一定程度上影响实验效率和实验过程的安全性,因此,语音识别系统被广泛应用于高等级生物安全实验室中,以协助实验人员对实验数据进行记录。
2、通常,在使用语音识别系统时,首先用户通过唤醒模块唤醒系统,然后将音频输入到语音识别模块进行识别,之后指令解析模块进行指令词解析,并根据解析获得的指令,对用户后续输入的语音内容进行处理并执行相应操作。
3、但是在实际使用场景中,实验室内可能存在噪音、实验人员可能穿着防护服,使得语音音频品质较差,且语音内容通常包含大量专业术语,与日常语言存在较大差异,使得现有的语音识别系统对语音内容的识别不够准确,影响了实验人员工作的顺利进行。
技术实现思路
1、针对上述问题,本申请提供了一种语音识别方法、装置、设备和存储介质。
2、第一方面,本申请提供一种语音识别方法,所述方法包括:
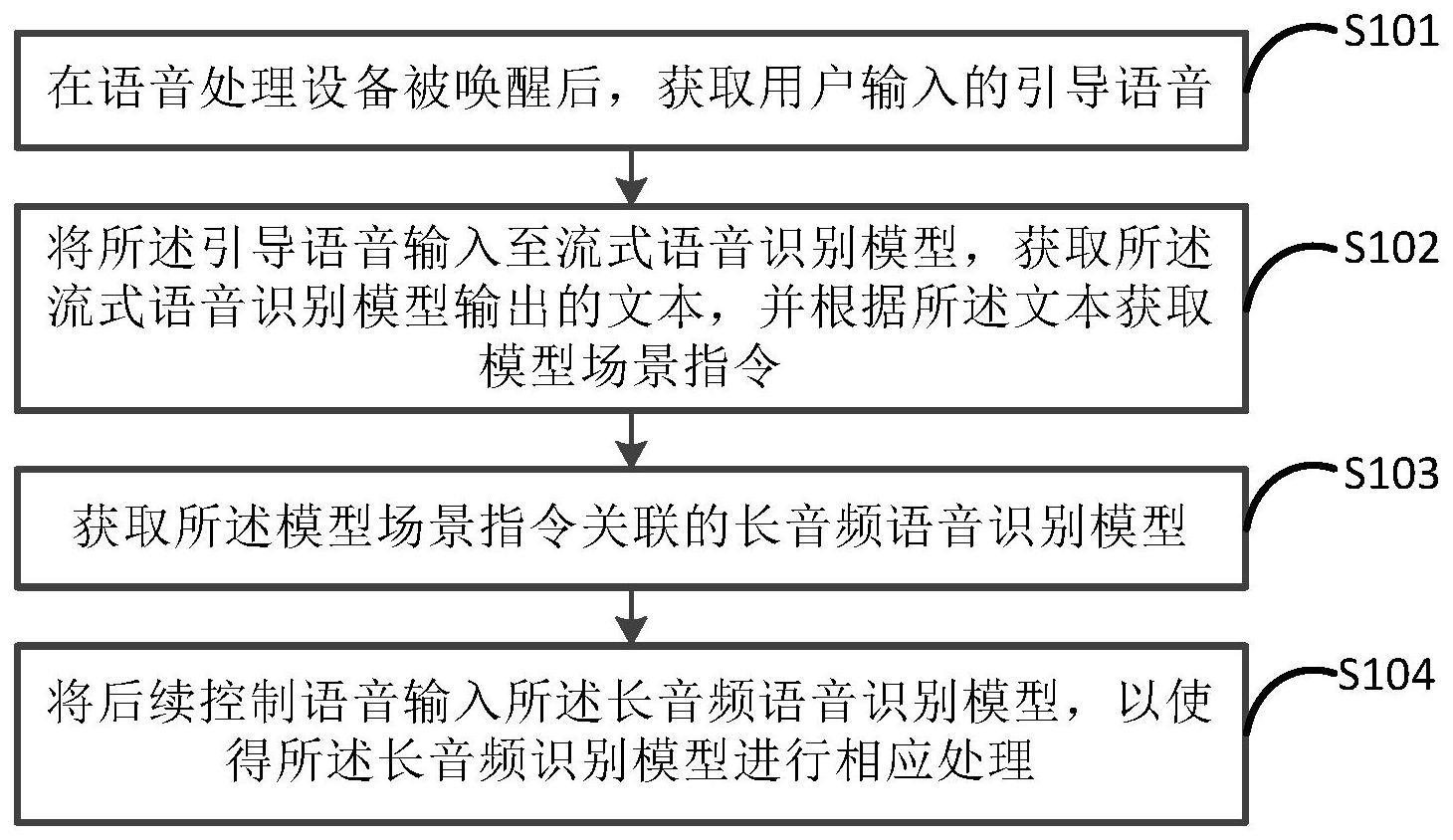
3、在语音处理设备被唤醒后,获取用户输入的引导语音;其中,所述语音处理设备通过用户语音和/或用户姿态唤醒;
4、将所述引导语音输入至流式语音识别模型,获取所述流式语音识别模型输出的文本,并根据所述文本获取模型场景指令,所述模型场景指令用于指示处理后续控制语音所需的目标模型;
5、获取所述模型场景指令关联的长音频语音识别模型,其中,所述长音频语音识别模型是根据大语音识别模型和所述模型场景指令匹配的小语音识别模型合并得到的,所述语音处理设备中存储有大语音识别模型和多个不同场景的小语音识别模型;
6、将后续控制语音输入所述长音频语音识别模型,以使得所述长音频识别模型进行相应处理。
7、可选的,所述根据所述文本获取模型场景指令,包括:
8、对所述文本进行解析,获取关键词;
9、将所述关键词与指令库中的模型场景指令进行匹配,获取与所述关键词匹配的模型场景指令,其中,所述指令库中的模型场景指令是根据小语音识别模型对应的场景预先生成的。
10、可选的,所述获取所述模型场景指令关联的长音频语音识别模型之前,所述方法还包括:
11、在训练过程中,加载预训练好的大语音识别模型及小语音识别模型;
12、冻结所述大语音识别模型的模型参数,通过模型场景对应的训练数据,训练小语音识别模型的模型参数,得到训练完成的小语音识别模型,并将所述小语音识别模型与模型场景指令进行关联。
13、可选的,所述小语音识别模型是根据不同的实验室场景的训练数据生成的;
14、所述小语音识别模型用于处理实验数据和/或控制实验设备。
15、可选的,所述将所述后续控制语音输入所述长音频语音识别模型之前,所述方法还包括:
16、获取所述模型场景指令对应的实验室噪音,其中,所述实验室噪音是预先存储的实验室场景下实验设备在安静状态下运行产生的噪音;
17、根据所述实验室噪音,对所述后续控制语音进行降噪处理,得到降噪处理后的后续控制语音。
18、可选的,若所述语音处理设备被用户姿态唤醒,则所述语音处理设备被唤醒,包括:
19、在视频流中出现用户时,按时间顺序提取所述视频流中的多个视频帧;
20、针对每个视频帧,获取所述视频帧中的骨骼点坐标信息,并根据所述骨骼点坐标信息获取所述视频帧的特征信息;
21、根据按时间顺序排列的多个视频帧的特征信息,获取多帧动作特征,并判断所述多帧动作特征是否与预设唤醒动作匹配;
22、若是,则所述语音处理设备被唤醒。
23、可选的,所述针对每个视频帧,获取所述视频帧中的骨骼点坐标信息,并根据所述骨骼点坐标信息获取所述视频帧的特征信息,包括:
24、针对每个视频帧,获取上半身肢体骨骼点坐标信息;
25、根据所述上半身肢体骨骼点坐标信息,依次连接上半身的骨骼点,得到多个骨骼向量;
26、按照预设顺序,获取相邻两个有交点的骨骼向量的角度信息;
27、根据所述预设顺序对所述角度信息进行排列,得到所述视频帧的特征信息。
28、第二方面,本申请提供一种语音识别装置,所述装置包括:
29、获取模块,用于在语音处理设备被唤醒后,获取用户输入的引导语音,其中,所述语音处理设备通过用户语音和/或用户姿态唤醒;
30、通讯模块,用于将所述引导语音输入至流式语音识别模型;
31、匹配模块,用于获取所述流式语音识别模型输出的文本,并根据所述文本获取模型场景指令,所述模型场景指令用于指示处理后续控制语音所需的目标模型;获取所述模型场景指令关联的长音频语音识别模型,其中,所述长音频语音识别模型是根据大语音识别模型和所述模型场景指令匹配的小语音识别模型合并得到的,所述语音处理设备中存储有大语音识别模型和多个不同场景的小语音识别模型;
32、所述通讯模块,还用于将后续控制语音输入所述长音频语音识别模型,以使得所述长音频识别模型进行相应处理。
33、第三方面,本申请提供一种语音处理设备,包括:存储器和至少一个处理器;
34、所述存储器用于存储计算机程序;
35、所述至少一个处理器用于运行所述存储器中存储的计算机程序以实现如第一方面所述的方法。
36、第四方面,本申请提供一种计算机可读存储介质,其上存储有计算机程序;
37、所述计算机程序被处理器执行时实现如第一方面所述的方法。
38、本申请提供的语音识别方法,通过在语音处理设备被唤醒后,获取用户输入的引导语音;其中,所述语音处理设备通过用户语音和/或用户姿态唤醒;将所述引导语音输入至流式语音识别模型,获取所述流式语音识别模型输出的文本,并根据所述文本获取模型场景指令,所述模型场景指令用于指示处理后续控制语音所需的目标模型;获取所述模型场景指令关联的长音频语音识别模型;将后续控制语音输入所述长音频语音识别模型,以使得所述长音频识别模型进行相应处理;有效提高了所述语音处理设备的唤醒准确率、成功率和语音识别的准确性,有效降低了相应设备误操作的概率,为实验室工作的顺利进行提供了有力的保障。
技术特征:
1.一种语音识别方法,其特征在于,所述方法包括:
2.根据权利要求1所述的方法,其特征在于,所述根据所述文本获取模型场景指令,包括:
3.根据权利要求1所述的方法,其特征在于,所述获取所述模型场景指令关联的长音频语音识别模型之前,所述方法还包括:
4.根据权利要求1所述的方法,其特征在于,所述小语音识别模型是根据不同的实验室场景的训练数据生成的;
5.根据权利要求4所述的方法,其特征在于,所述将所述后续控制语音输入所述长音频语音识别模型之前,所述方法还包括:
6.根据权利要求1所述的方法,其特征在于,若所述语音处理设备被用户姿态唤醒,则所述语音处理设备被唤醒,包括:
7.根据权利要求6所述的方法,其特征在于,所述针对每个视频帧,获取所述视频帧中的骨骼点坐标信息,并根据所述骨骼点坐标信息获取所述视频帧的特征信息,包括:
8.一种语音识别装置,其特征在于,所述装置包括:
9.一种语音处理设备,其特征在于,包括:存储器和至少一个处理器;
10.一种计算机可读存储介质,其特征在于,其上存储有计算机程序;
技术总结
本申请属于语音识别技术领域,具体涉及一种语音识别方法、装置、设备和存储介质;本申请提供的语音识别方法,通过在语音处理设备被唤醒后,获取用户输入的引导语音;语音处理设备通过用户语音和/或用户姿态唤醒;将引导语音输入至与流式语音识别模型,获取流式语音识别模型输出的文本,并根据文本获取模型场景指令;获取模型场景指令关联的长音频语音识别模型;将后续控制语音输入长音频语音识别模型,以使得长音频识别模型进行相应处理;有效提高了所述语音处理设备的唤醒准确率、成功率和语音识别的准确性,有效降低了相应设备误操作的概率,为实验室工作的顺利进行提供了有力的保障。
技术研发人员:李文鹏,王琪,刘占杰,李云鹏,李然
受保护的技术使用者:青岛海尔生物医疗科技有限公司
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!