音频获取方法及装置、音频获取系统与流程
本发明涉及智能音频处理领域,具体而言,涉及一种音频获取方法及装置、音频获取系统。
背景技术:
1、听力障碍是指一个人在听觉方面出现的问题,导致其难以正常听到、理解和处理声音的能力受到限制。听力障碍可以是先天性的(出生时就存在),也可以是后天性的(在生长过程中出现);这种障碍可以是暂时的,也可以是永久性的。部分极重度听力障碍的人无法听到或理解声音,通常依赖于手语、读唇或使用听觉替代设备(如人工耳蜗)来进行交流。
2、目前面向听力障碍人员提供听力辅助的智能眼镜,主要是通过骨传导的方式,将声音信号增强并传递给听力障碍人员,帮助他们一定程度恢复“听觉”感知。例如,市面上的一种智能眼镜,在使用时首先需要开启传导设备,运用放大器将声音信号传送给骨传导耳机,然后用户即可通过骨传导耳机收听该多媒体文件的内容。还有一种智能头戴设备,在获取目标对象的位置信息之后,若目标对象位于目标拾音区域,则采集目标对象当前的音频信号,然后根据第一音频信号,对其进行放大处理,得到第二音频信号,之后再传输给用户。但是当听力障碍人员想要关注某一特定方向与位置的音源时,使用骨传导技术没有有效办法能对这一指定位置的声音进行增强。
3、但对于极重度听力障碍的人,骨传导的效果要弱于通过手术植入的人工耳蜗。同时,眼球追踪技术主要应用于视觉增强领域,对听力障碍人员的帮助主要是应用于辅助其阅读。例如,现有技术中的一种智能阅读辅助装置,通过智能传感输入单元输入信号,并通过信息智能处理单元向阅读架部件输出执行信号,无需使用者手动操作,有效解决了残障人士阅读纸质或者电子书籍时存在困难的问题,提高了残障人士阅读时的体验。但是现有方案中几乎都没有基于听力障碍人员的视觉注意力维度来进行听力增强。
4、针对上述现有技术中无法基于听力障碍人员的视觉注意力对某一特定位置的声音进行增强,导致听力障碍人员获取到的信息准确度较低的问题,目前尚未提出有效的解决方案。
技术实现思路
1、本发明实施例提供了一种音频获取方法及装置、音频获取系统,以至少解决现有技术中无法基于听力障碍人员的视觉注意力对某一特定位置的声音进行增强,导致听力障碍人员获取到的信息准确度较低的技术问题。
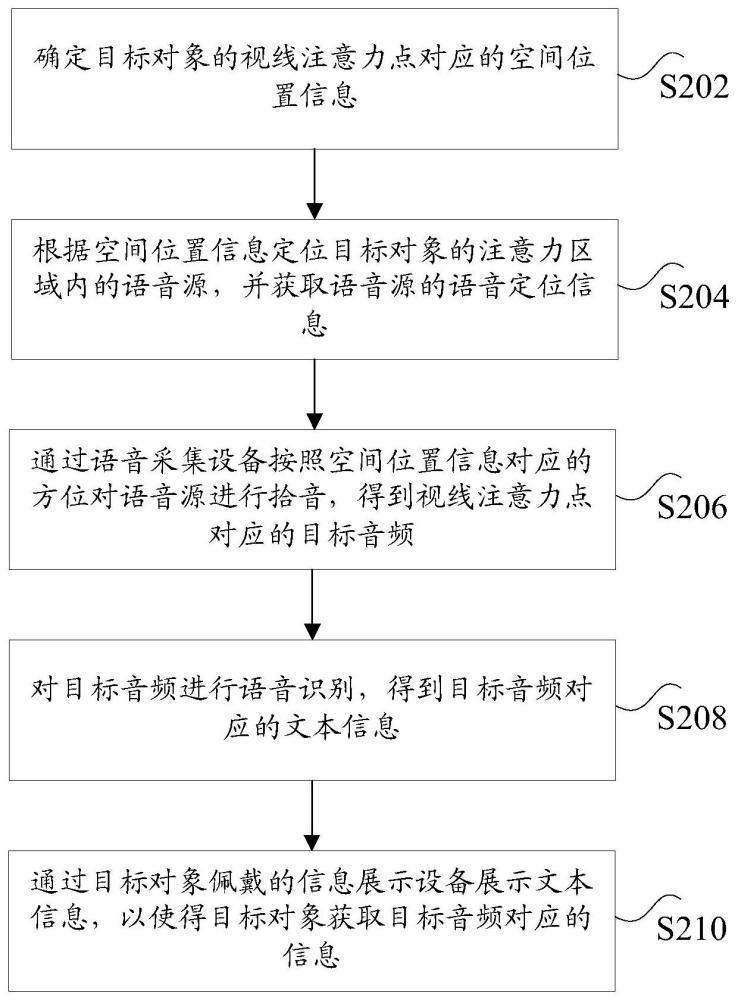
2、根据本发明实施例的一个方面,提供了一种音频获取方法,包括:确定目标对象的视线注意力点对应的空间位置信息;根据所述空间位置信息定位所述目标对象的注意力区域内的语音源,并获取所述语音源的语音定位信息;通过语音采集设备按照所述空间位置信息对应的方位对所述语音源进行拾音,得到所述视线注意力点对应的目标音频;对所述目标音频进行语音识别,得到所述目标音频对应的文本信息;通过所述目标对象佩戴的信息展示设备展示所述文本信息,以使得所述目标对象获取所述目标音频对应的信息。
3、可选地,确定目标对象的视线注意力点对应的空间位置信息,包括:利用视线追踪设备追踪所述目标对象的视线,得到视线追踪信息;根据所述视线追踪信息确定所述视线注意力点;根据所述注意力点确定所述空间位置信息。
4、可选地,根据所述空间位置信息定位所述目标对象的注意力区域内的语音源,并获取所述语音源的语音定位信息,包括:根据所述空间位置信息确定所述注意力区域;采用声源定位算法对所述注意力区域内的声音进行定位,得到所述语音定位信息。
5、可选地,通过语音采集设备按照所述空间位置信息对应的方位对所述语音源进行拾音,得到所述视线注意力点对应的目标音频,包括:根据所述空间位置信息确定所述语音采集设备的语音采集距离和语音采集方向;控制所述语音采集设备在所述语音采集方向上按照所述语音采集距离对所述语音源进行拾音,得到所述目标音频。
6、可选地,控制所述语音采集设备在所述语音采集方向上按照所述语音采集距离对所述语音源进行拾音,得到所述目标音频,包括:控制所述语音采集设备在所述语音采集方向上按照所述语音采集距离对所述语音源进行拾音,得到所述视线注意力点对应的初始音频;通过波束成形技术对所述初始音频进行去噪处理,得到所述目标音频。
7、可选地,对所述目标音频进行语音识别,得到所述目标音频对应的文本信息,包括:将所述目标音频输入至语音识别模型,以利用所述语音识别模型对所述目标音频进行语音识别,得到所述文本信息,其中,所述语音识别模型是预先使用多组训练数据通过机器学习训练得到的,所述多组训练数据中的每一组均包括:样本音频和与所述样本音频对应的样本文本信息。
8、可选地,该音频获取方法还包括:在确定所述目标对象的语音接收能力大于语音接收能力阈值时,在通过所述目标对象佩戴的信息展示设备展示所述文本信息,以使得所述目标对象获取所述目标音频对应的信息的过程中,将所述目标音频传输至所述目标对象佩戴的助听设备。
9、根据本发明实施例的另一方面,还提供了一种音频获取装置,包括:确定单元,用于确定目标对象的视线注意力点对应的空间位置信息;第一获取单元,用于根据所述空间位置信息定位所述目标对象的注意力区域内的语音源,并获取所述语音源的语音定位信息;第二获取单元,用于通过语音采集设备按照所述空间位置信息对应的方位对所述语音源进行拾音,得到所述视线注意力点对应的目标音频;第三获取单元,用于对所述目标音频进行语音识别,得到所述目标音频对应的文本信息;第四获取单元,用于通过所述目标对象佩戴的信息展示设备展示所述文本信息,以使得所述目标对象获取所述目标音频对应的信息。
10、可选地,所述确定单元,包括:第一获取模块,用于利用视线追踪设备追踪所述目标对象的视线,得到视线追踪信息;第一确定模块,用于根据所述视线追踪信息确定所述视线注意力点;第二确定模块,用于根据所述注意力点确定所述空间位置信息。
11、可选地,所述第一获取单元,包括:第三确定模块,用于根据所述空间位置信息确定所述注意力区域;第二获取模块,用于采用声源定位算法对所述注意力区域内的声音进行定位,得到所述语音定位信息。
12、可选地,所述第二获取单元,包括:第四确定模块,用于根据所述空间位置信息确定所述语音采集设备的语音采集距离和语音采集方向;控制模块,用于控制所述语音采集设备在所述语音采集方向上按照所述语音采集距离对所述语音源进行拾音,得到所述目标音频。
13、可选地,所述控制模块,包括:控制子模块,用于控制所述语音采集设备在所述语音采集方向上按照所述语音采集距离对所述语音源进行拾音,得到所述视线注意力点对应的初始音频;获取子模块,用于通过波束成形技术对所述初始音频进行去噪处理,得到所述目标音频。
14、可选地,所述第三获取单元,包括:第三获取模块,用于将所述目标音频输入至语音识别模型,以利用所述语音识别模型对所述目标音频进行语音识别,得到所述文本信息,其中,所述语音识别模型是预先使用多组训练数据通过机器学习训练得到的,所述多组训练数据中的每一组均包括:样本音频和与所述样本音频对应的样本文本信息。
15、可选地,该音频获取装置还包括:传输单元,用于在确定所述目标对象的语音接收能力大于语音接收能力阈值时,在通过所述目标对象佩戴的信息展示设备展示所述文本信息,以使得所述目标对象获取所述目标音频对应的信息的过程中,将所述目标音频传输至所述目标对象佩戴的助听设备。
16、根据本发明实施例的另一方面,还提供了一种音频获取系统,所述音频获取系统使用上述任一种所述的音频获取方法。
17、根据本发明实施例的另一方面,还提供了一种计算机可读存储介质,所述计算机可读存储介质包括存储的程序,其中,所述程序执行上述任意一种所述的音频获取方法。
18、根据本发明实施例的另一方面,还提供了一种处理器,所述处理器用于运行程序,其中,所述程序运行时执行上述任意一种所述的音频获取方法。
19、在本发明实施例中,确定目标对象的视线注意力点对应的空间位置信息;根据空间位置信息定位目标对象的注意力区域内的语音源,并获取语音源的语音定位信息;通过语音采集设备按照空间位置信息对应的方位对语音源进行拾音,得到视线注意力点对应的目标音频;对目标音频进行语音识别,得到目标音频对应的文本信息;通过目标对象佩戴的信息展示设备展示文本信息,以使得目标对象获取目标音频对应的信息。通过以上技术方案,达到了基于听力障碍人员的视线注意力对获取某一特定位置声音信号进行精确拾音,并将拾音结果转换成文本信息,通过信息展示设备展示该文本信息的目的,实现了根据眼球追踪所输出的位置信息,对麦克风阵列的声音实现了更加精准的位置定位与声音增强的技术效果,进而解决了现有技术中无法基于听力障碍人员的视觉注意力对某一特定位置的声音进行增强,导致听力障碍人员获取到的信息准确度较低的技术问题。
- 还没有人留言评论。精彩留言会获得点赞!