一种基于ad-hoc麦克风阵列的多通道语音去混响融合方法
本发明属于语音识别,具体涉及一种基于ad-hoc麦克风阵列的多通道语音去混响融合方法。
背景技术:
1、随着技术的进步,语音作为一种计算机界面也成为人机交互的关键,越来越多地被应用在各种智慧场景中。在封闭空间中,除了说话人的声音,麦克风不可避免地受到室内混响的干扰,这将导致不同程度地降低语音的可懂度和清晰度,使移动通信设备的效率大大降低。因此,我们需要进行去混响处理,其目标是从麦克风中接收到的带混响音频中去除混响成分,仅保留预测得到的干净音频。
2、一种常见的多通道去混响方法是将深度学习与传统的信号处理方法相结合,这些模型旨在以数学推导的方式模拟混响过程,例如空间滤波器等。其中,desnet(dereverberation,,enhancement and separation net)架构使用了基于深度神经网络(dnn,deep neural networks)的加权预测误差(wpe,weighted prediction error)模块进行去混响。这种方法基本上基于统计信号处理理论。另一种策略是使用dnn计算波束形成器的权重,例如mc-csm(multi-channel complex spectral mapping)、eabnet(embeddingand beamforming network)、pcg-aiid system、tparn(triple-path attentiverecurrent network)和fasnet-tac(filter-and-sum network transform-average-concatenate)等。
3、但是,上述模型均应用于固定阵列中。随着配备麦克风的便携的数码设备的增加,复杂的听觉场景可能包含几十个带有麦克风的移动设备,且麦克风的空间位置信息未知。
4、然而,上述方法主要用于固定麦克风阵列。目前,基于自组织麦克风阵列的方法日渐得到了新的关注,这种方式是将随机分布在空间中且不知道位置的麦克风设备加以组织进行处理。且因为该方法可能缺乏对设备位置的先验知识,所以简单地迁移为固定阵列量身定制的去混响策略可能不是最佳选择。而如何充分利用自组织麦克风阵列下空间信息来进行语音去混响似乎尚未得到充分探索。
5、据我们所知,只进行了一些关于语音增强的相关工作。例如,xiao-lei zhang提出首先选择一个最佳信道,然后将单信道语音增强应用于上述信道。然而,这种方法需要手动选择频道,这增加了该过程的复杂性。anselm lohmann等人采用了局部波束形成方法,并将其与用于语音增强的去混响质量感知评估(pevd)相结合。尽管如此,上述分析方法并没有针对性地解决去混响问题。
技术实现思路
1、为了克服现有技术的不足,本发明提供了一种基于ad-hoc麦克风阵列的多通道语音去混响融合方法,通过学习多通道输入特征之间的时频特征,有效地集成空间信息,使网络能够有选择地加权每个通道的重要性,从而提高多通道去混响的性能。通过自注意力机制或图注意机制来实现上述操作,并且可以在去混响网络的不同位置上灵活使用该模块。无论将该模块放置在去混响网络的哪个位置,本发明方法的去混响性能均得到了改善。
2、本发明解决其技术问题所采用的技术方案包括如下步骤:
3、步骤1:构建自注意力融合模块,用于进行通道间的信息融合;
4、对于每个帧t,多通道输入为df表示频率域中的维度数量,c表示通道数;查询q、键k和值v子空间的维度为e,在第m个注意力头时,它们的计算方式如下:
5、
6、其中查询、键和值的嵌入层分别由矩阵和表示,其中dk=e/k,k表示注意力头的数量;第m个注意力头在通道c处的可训练的参数表示为其中*∈k,q,v;
7、第m个注意力头的输出计算如下:
8、
9、其中所有注意力头的输出被加以连接:
10、
11、其中是线性投影层的权重矩阵,输出
12、为了防止梯度消失,设置了一个残差直接连接输入与输出。
13、步骤2:构建图注意力融合模块;
14、设输入为zt,其中建立一个完整的图,被称为g,图中每个单独的节点由一个不同的行向量表示;
15、对于第m个注意力头,通过可学习参数和将zt投影到一个dm维度的空间中进行初始化:
16、
17、将查询和键矩阵表示为和对于每个查询和键,它们的分数使用以下公式计算:
18、
19、
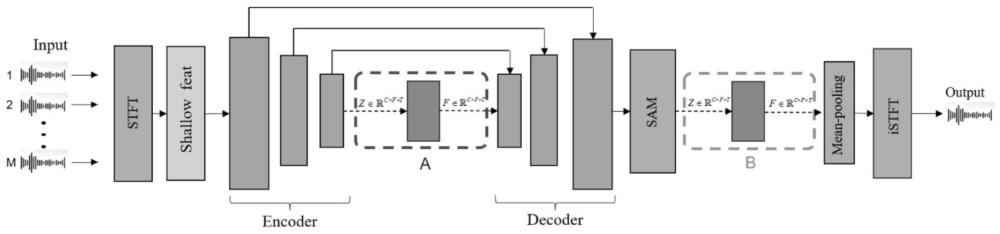
20、其中是一个可学习的向量;使用softmax函数来归一化所有相邻通道上的注意力分数;对于第m个头,通道c的聚合输出由表示:
21、
22、其中n(c)表示通道c的相邻通道;所有节点的聚合特征被连接起来:
23、
24、得到聚合模块的输出如下:
25、
26、步骤3:采用两阶段的训练方法,首先训练一个单通道语音去混响网络,训练完成得到网络参数;
27、步骤4:将步骤3得到的网络参数用在多通道语音去混响网络中;
28、步骤5:将多通道语音去混响网络中,将编码器和解码器之间的位置称为位置a,将监督注意力模块sam与平局池化层之间的位置称为位置b;
29、步骤6:将自注意力融合模块和图注意力融合模块分别放置在位置a或位置b,构成四种组合,从而形成四种改进的多通道语音去混响网络;
30、步骤7:采用自组织麦克风阵列获取样本数据,对四种改进的多通道语音去混响网络分别进行训练,得到最终改进的多通道语音去混响网络,用于多通道语音去混响融合。
31、优选地,所述四种改进的多通道语音去混响网络中,放置在位置a或位置b的自注意力融合模块和图注意力融合模块,其通道维度均与多通道语音去混响网络哦输入通道维度一致。
32、本发明的有益效果如下:
33、(1)与现有多通道去混响技术相比,本发明采用了可以适用于自组织麦克风阵列的多通道语音去混响融合模块。其中,自注意力融合模块采用自注意力机制,通过学习不同通道之间的时空特征,在每个帧内为每个通道选择性地分配权重。图注意力融合模块将不同通道视为图的顶点,通过聚合相邻通道的空间信息来增强每帧的信息。上述两种模块均可以在麦克风位置信息未知的情况下,实现对麦克风的去混响操作,从而提高模型去混响的效果。
34、(2)与现有多通道去混响技术相比,本发明可以在不同麦克风数量和不同t60值混响的实验条件下均获得较好的实验结果,这证明了所提方法在不同实验环境下的鲁棒性。
35、(3)与现有多通道去混响技术相比,本发明采用两阶段训练法,最初训练一个单通道去混响网络,随后固定参数,在基于自组织麦克风阵列的网络中独立训练通道融合模块,且在语音去混响网络中的位置是灵活的。上述操作简化了多通道训练的过程,大大提高了训练的效率。
36、(4)与单通道语音增强算法相比,本发明避免了手动选择通道的复杂过程,可以对多通道音频进行直接处理。
- 还没有人留言评论。精彩留言会获得点赞!