远场语音数据扩充方法、服务器和电子设备与流程
本技术涉及语音,尤其涉及一种远场语音数据扩充方法、服务器和电子设备。
背景技术:
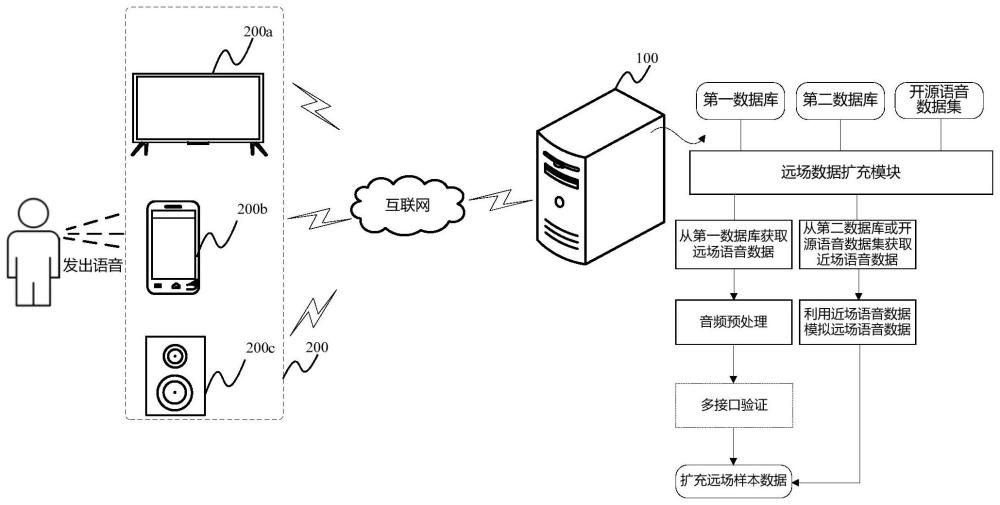
1、语音交互场景可以包括近场语音和远场语音,其中近场语音是指用户与声音采集器近距离的语音交互,例如用户手持智能手机并输入语音指令,用户长按遥控器的语音按键以向智能电视输入语音指令等。远场语音则是在相对较远的距离范围内进行的语音交互,例如用户在会议室、教室、智能家居等场景中发出语音指令,由场景中设置的如麦克风阵列等设备捕捉用户语音信号,再由语音系统对该语音信号进行处理和响应。
2、在开发远场语音的算法模型时,往往需要大量的与电子设备、与麦克风阵列适配的远场语音数据,该远场语音数据用于训练模型,以改进模型,或提升模型运算精度。但在实际积累远场语音数据时,存在如下问题:(一)如果使用设备采集远场语音数据,需耗费大量的时间和人力去录制语音数据,并对语音数据的文本进行标注,采集速度较慢,影响远场语音算法的研发效率和进度;(二)如果向某些供应商购买远场语音数据,可能存在所购买的数据与当前设备的数据采集信道不匹配等问题,且目前市面上远场语音数据数量较少,不足以涉猎所有应用场景和领域。
技术实现思路
1、本技术一些实施例提供了一种远场语音数据扩充方法、服务器和电子设备,以提升远场样本数据累积和扩充的速度,规避远场样本数据与设备、信道等不匹配的问题,通过线上持续性地动态扩充数据,实现对不同场景和领域的覆盖,进而提升模型训练效率和精度。
2、第一方面,本技术一些实施例提供一种服务器,包括:
3、第一通信器,用于与电子设备通信连接;
4、第一控制器,用于执行:
5、接收电子设备上传的语音数据,判别所述语音数据的类别;
6、如果所述语音数据为远场类别,将所述语音数据保存至第一数据库;
7、如果所述语音数据为近场类别,将所述语音数据保存至第二数据库;
8、根据所述第一数据库筛选远场样本数据,和/或,根据所述第二数据库或开源语音数据集中的近场语音数据模拟所述远场样本数据,所述远场样本数据用于训练远场语音处理模型;其中,所述开源语音数据集包括通过其他途径获取的近场语音数据;
9、存储所述远场样本数据。
10、在一些实施例中,所述第一控制器根据所述第一数据库筛选远场样本数据,包括:从所述第一数据库中获取符合第一筛选条件的第一远场语音数据集,所述第一筛选条件包括目标设备的设备信息、录制时间和地域信息;从所述第一远场语音数据集中获取符合第二筛选条件的目标远场语音数据,所述第二筛选条件包括目标音频时长和目标信噪比;对所述目标远场语音数据进行语音识别,得到目标文本信息;将所述目标远场语音数据和所述目标文本信息扩充为所述远场样本数据。
11、在一些实施例中,所述第一控制器根据所述第一数据库筛选远场样本数据,包括:从所述第一数据库中获取符合第一筛选条件的第一远场语音数据集,所述第一筛选条件包括目标设备的设备信息、录制时间和地域信息;从所述第一远场语音数据集中获取符合第二筛选条件的目标远场语音数据,所述第二筛选条件包括目标音频时长和目标信噪比;调用n个不同的语音识别接口,分别对所述目标远场语音数据进行语音识别,得到n个目标文本信息;其中,n为语音识别接口的调用数量,n大于1;如果n个目标文本信息完全一致,则将所述目标远场语音数据及其被唯一识别的所述目标文本信息扩充为所述远场样本数据。
12、在一些实施例中,所述第一控制器根据所述第二数据库中的近场语音数据模拟所述远场样本数据,包括:创建远场模拟房间,并设置麦克风阵列的拓扑结构;设置所述麦克风阵列、声源、声音播放器和噪声在所述远场模拟房间内的位置;从所述第二数据库或所述开源语音数据集获取近场语音数据,将所述近场语音数据设为声源信号,并在声源位置处播放所述进场语音数据;设置所述远场模拟房间内的声音环境,并模拟远场音频信号,得到多通信音频集;利用麦克风阵列算法,将多通道音频集转变为单通道语音数据;将所述单通道语音数据及其文本信息扩充为所述远场样本数据。
13、在一些实施例中,所述第一控制器设置所述远场模拟房间内的声音环境,并模拟远场音频信号,包括:控制所述声音播放器播放目标音频,并模拟包含回声的远场音频信号fs1,fs1=y+x*rir;其中,y表示所述麦克风阵列采集的声源信号,x表示所述声音播放器播放的回声信号,rir表示所述远场模拟房间的冲击响应,*表示卷积运算。
14、在一些实施例中,所述第一控制器设置所述远场模拟房间内的声音环境,并模拟远场音频信号,包括:模拟包含回声混响的远场音频信号fs2,fs2=y*rir。
15、在一些实施例中,所述第一控制器设置所述远场模拟房间内的声音环境,并模拟远场音频信号,包括:在噪声位置施加噪声信号,并模拟包含噪声的远场音频信号fs3,fs3=y+z*(10^(-snr/20));其中z表示所述噪声信号,snr表示目标信噪比,*表示卷积运算,^表示次方运算。
16、在一些实施例中,所述第一控制器设置所述远场模拟房间内的声音环境,并模拟远场音频信号,包括:
17、模拟同时包含回声和混响的远场音频信号fs4,fs4=x*rir+y*rir;
18、和/或,模拟同时包含回声和噪声的远场音频信号fs5,fs5=y+x*rir+z*(10^(-snr/20));
19、和/或,模拟同时包含混响和噪声的远场音频信号fs6,fs6=y*rir+z*(10^(-snr/20));
20、和/或,模拟同时包含回声、混响和噪声的远场音频信号fs7,fs7=x*rir+y*rir+z*(10^(-snr/20))。
21、在一些实施例中,所述多通道音频集包括fs1′、fs2′、fs3′、fs4′、fs5′、fs6′和fs7′中的任意一个;fs1′=|fs1|×s;fs2′=|fs2|×s;fs3′=|fs3|×s;fs4′=|fs4|×s;fs5′=|fs5|×s;fs6′=|fs6|×s;fs7′=|fs7|×s;其中,|fs1|表示远场音频信号fs1的振幅,|fs2|表示远场音频信号fs2的振幅,|fs3|表示远场音频信号fs3的振幅,|fs4|表示远场音频信号fs4的振幅,|fs5|表示远场音频信号fs5的振幅,|fs6|表示远场音频信号fs6的振幅,|fs7|表示远场音频信号fs7的振幅,s为音量扰动系数,×表示乘法运算。
22、第二方面,本技术一些实施例还提供一种电子设备,包括:
23、第二通信器,用于与第一方面所述的服务器通信连接;
24、声音采集器,用于采集用户输入的语音数据;
25、第二控制器,用于执行:
26、获取所述声音采集器采集的语音数据,所述语音数据中包括由所述声音采集器设置的类别标识,所述类别标识用于指示所述语音数据为近场类别或远场类别;
27、将所述语音数据上传至所述服务器。
28、第三方面,本技术一些实施例还提供一种远场语音数据扩充方法,包括:
29、接收电子设备上传的语音数据,判别所述语音数据的类别;
30、如果所述语音数据为远场类别,将所述语音数据保存至第一数据库;
31、如果所述语音数据为近场类别,将所述语音数据保存至第二数据库;
32、根据所述第一数据库筛选远场样本数据,和/或,根据所述第二数据库或开源语音数据集中的近场语音数据模拟所述远场样本数据,所述远场样本数据用于训练远场语音处理模型;其中,所述开源语音数据集包括通过其他途径获取的近场语音数据;
33、存储所述远场样本数据。
34、第四方面,本技术一些实施例还提供一种计算机存储介质,该计算机存储介质中存储有程序指令,当程序指令在计算机上运行时,使得计算机执行以上各方面及其各个实现方式中涉及的方法。
35、本技术实施例中,服务器可以接收多个不同电子设备上传的语音数据,并识别语音数据的类别,将远场语音数据存入第一数据库,将近场语音数据存入第二数据库,实现服务器端按语音数据类别进行分类存储。第一数据库存储有各电子设备上传的大量远场语音数据,第一数据库可以持续性第累积和扩充数据,这样服务器可以根据应用场景和模型训练要求,从第一数据库中筛选匹配的数据作为可供模型训练的远场样本数据。
36、第二数据库存储有个电子设备上传的大量近场语音数据,第二数据库也可持续性地累积和扩充数据,利用第二数据库或者开源语音数据集中包括近场语音数据去模拟远场语音数据,一方面可以充分利用第二数据库,另一方面服务器可以从多途径获取模拟所需的近场语音数据,进而增加远场样本数据的扩充途径,提升远场样本数据累积和扩充的速度,无需向供应商购置数据,也规避了远场样本数据与设备信道等不匹配的问题,通过线上扩充数据,实现对不同场景和领域的覆盖,有利于提升模型训练的效率和精度。尤其是,当第一数据库和第二数据库的两种扩充模式共同运行时,可以使远场样本数据的扩充速度显著提升。
- 还没有人留言评论。精彩留言会获得点赞!