机器人的语音合成方法、装置和机器人系统与流程
本申请涉及人工智能机器人行为交互领域,特别是涉及机器人的语音合成方法、装置和机器人系统。
背景技术:
1、目前,随着技术的发展,服务型机器人被越来越广泛的应用,主要是用于与用户进行沟通交流。当用户输入语音指令后,机器人需要将需要播放的语音文本进行语音合成来回答用户的问题。目前普遍采用的是语音合成服务器将需要播放的完整的语音文本直接转换成语音文件,然后将语音文件下载至本地后进行播放。但是,当语音文本过长的时候,文本转换的时间也会相应拉长。因而,当语音文本过长时机器人需要等待整个语音文本完成转换和下载后才能进行播放。此种情况下,用户在输入完语音指令后需要等待较长的时间,进而导致语音播放效率较低。
2、针对相关技术中存在语音播放效率较低的问题,目前还没有提出有效的解决方案。
技术实现思路
1、在本实施例中提供了一种机器人的语音合成方法、装置和机器人系统,以解决相关技术中语音文本过长导致语音合成慢的问题。
2、第一个方面,在本实施例中提供了一种机器人的语音合成方法,包括:
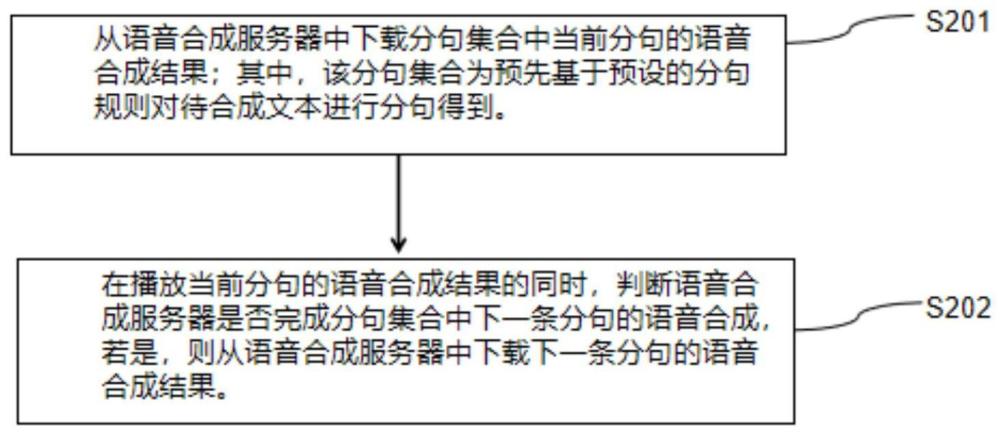
3、从语音合成服务器中下载分句集合中当前分句的语音合成结果;其中,分句集合为预先基于预设的分句规则对待合成文本进行分句得到;
4、在播放当前分句的语音合成结果的同时,判断所述语音合成服务器是否完成所述分句集合中下一条分句的语音合成,若是,则从所述语音合成服务器中下载所述下一条分句的语音合成结果。
5、在其中的一些实施例中,在从语音合成服务器中下载分句集合中当前分句的语音合成结果之前,还包括:
6、基于预设的分句规则对待合成文本进行分句,得到分句集合;
7、将所述分句集合发送至所述语音合成服务器,以依次对所述分句集合中的各条分句进行语音合成。
8、在其中的一些实施例中,基于预设的分句规则对待合成文本进行分句,得到所述分句集合,包括:
9、根据预设的标点符号集合,对所述待合成文本进行分句,得到所述分句集合。
10、在其中的一些实施例中,所述下一条分句在语音合成服务器中进行语音合成所需时间,与所述下一条分句的语音合成结果的下载所需时间之和,小于所述当前分句的语音合成结果播放所需时间。
11、在其中的一些实施例中,所述方法还包括:
12、若在播放完成所述当前分句的语音合成结果后,还未获取到所述下一条分句的语音合成结果,则判断在所述当前分句的语音合成结果播放完成的预设时段内,是否接收到所述下一条分句语音合成结果;
13、若是,则播放所述下一条分句的语音合成结果。
14、在其中的一些实施例中,所述方法还包括:
15、若在当前分句的语音合成结果播放完成的所述预设时段内,未接受到下一条分句的语音合成结果,则确认所述下一条分句语音合成失败。
16、第二个方面,在本实施例中提供了一种机器人的语音合成装置,包括:获取模块和判断模块;其中:
17、所述获取模块,用于从语音合成服务器中下载分句集合中当前分句的语音合成结果;其中,所述分句集合为预先基于预设的分句规则对待合成文本进行分句得到;
18、所述判断模块,用于在播放当前分句的语音合成结果的同时,判断所述语音合成服务器是否完成所述分句集合中下一条分句的语音合成,若是,则从所述语音合成服务器中下载所述下一条分句的语音合成结果。
19、第三个方面,在本实施例中提供了一种机器人系统,应用于上述第一方面所述的机器人的语音合成方法。
20、第四方面,在本实施例中提供了一种电子装置,包括存储器、处理器以及存储在所述存储器上并可在所述处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现上述第一个方面所述的机器人的语音合成方法。
21、第五个方面,在本实施例中提供了一种存储介质,其上存储有计算机程序,该程序被处理器执行时实现上述第一个方面所述的机器人的语音合成方法。
22、与相关技术相比,本实施例提供的机器人的语音合成方法、装置和机器人系统,能够实现语音文本的合成、下载以及播放的并行执行,从而降低了播放之前等待语音文本合成和下载的时长,进而提高了机器人语音播放的效率。
23、本申请的一个或多个实施例的细节在以下附图和描述中提出,以使本申请的其他特征、目的和优点更加简明易懂。
技术特征:
1.一种机器人的语音合成方法,其特征在于,包括:
2.根据权利要求1所述的机器人的语音合成方法,其特征在于,在从语音合成服务器中下载分句集合中当前分句的语音合成结果之前,所述方法还包括:
3.根据权利要求2所述的机器人的语音合成方法,其特征在于,所述基于预设的分句规则对待合成文本进行分句,得到所述分句集合,包括:
4.根据权利要求1所述的机器人的语音合成方法,其特征在于,所述下一条分句在语音合成服务器中进行语音合成所需时间,与所述下一条分句的语音合成结果的下载所需时间之和,小于所述当前分句的语音合成结果播放所需时间。
5.根据权利要求1至4中任一项所述的机器人的语音合成方法,其特征在于,所述方法还包括:
6.根据权利要求5所述的机器人的语音合成方法,其特征在于,所述方法还包括:
7.一种机器人的语音合成装置,其特征在于,包括:获取模块和判断模块;其中:
8.一种机器人系统,其特征在于,应用权利要求1至6中任一项所述的机器人的语音合成方法。
9.一种电子装置,包括存储器和处理器,其特征在于,所述存储器中存储有计算机程序,所述处理器被设置为运行所述计算机程序以执行权利要求1至6中任一项所述的机器人的语音合成方法。
10.一种计算机可读存储介质,其上存储有计算机程序,其特征在于,所述计算机程序被处理器执行时实现权利要求1至6中任一项所述的机器人的语音合成方法的步骤。
技术总结
本申请涉及一种机器人的语音合成方法、装置和机器人系统,其中,该机器人的语音合成方法包括:从语音合成服务器中下载分句集合中当前分句的语音合成结果;其中,分句集合为预先基于预设的分句规则对待合成文本进行分句得到;在播放当前分句的语音合成结果的同时,判断语音合成服务器是否完成分句集合中下一条分句的语音合成,若是,则从语音合成服务器中下载下一条分句的语音合成结果。通过本申请,能够实现语音文本的合成、下载以及播放的并行执行,从而降低了播放之前等待语音文本合成和下载的时长,进而提高了机器人语音播放的效率。
技术研发人员:方伟,宛敏红,付强,穆宗昊,姜娜,肖永雄,白炳潮
受保护的技术使用者:之江实验室
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!