机器人对话方法、系统、机器人和存储介质与流程
本发明涉及人工智能,尤其涉及一种机器人对话方法、系统、机器人和存储介质。
背景技术:
1、近年来,随着人工智能技术的快速发展,机器人成为产业界关注的一个热点,各种机器人层出不穷。目前用户主要通过语音对话的方式与机器人进行交互,其对话方案主要在云端完成,然而,对话方案中的特征提取与模型推理等操作耗时较大,在语音对话过程中机器人端到云端之间有一定时延,不能满足语音交互实时性的要求,用户体验不佳。因此,如何降低用户与机器人语音对话过程中机器人端到云端之间时延成为亟需解决的技术问题。
技术实现思路
1、本发明实施例提供一种机器人对话方法、系统、机器人和存储介质,用以提高机器人对话系统的性能,不仅降低了用户与机器人语音对话过程中的端到端之间的时延,还可以使得机器人可以更智能地与用户进行对话交互。
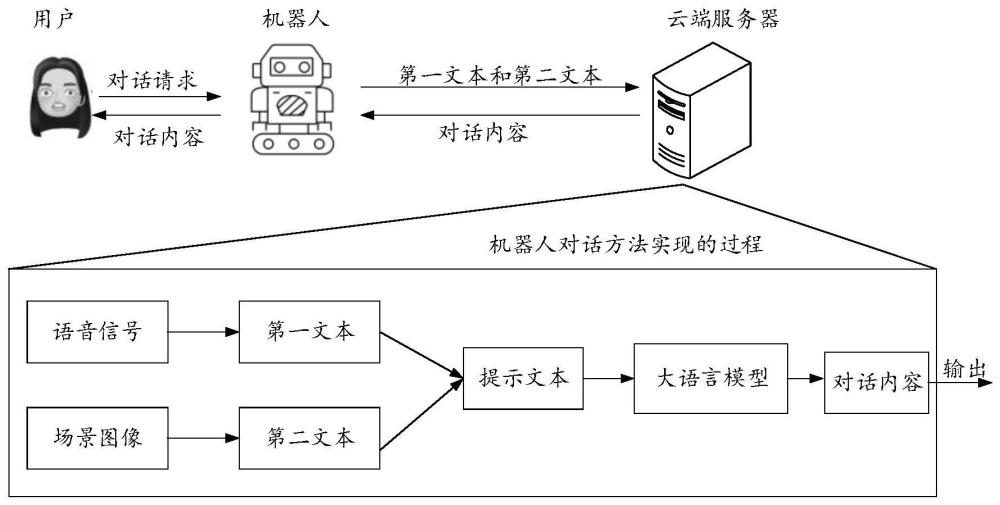
2、第一方面,本发明实施例提供一种机器人对话系统,所述系统包括:
3、机器人和云端服务器;
4、所述机器人,用于采集说话者的语音信号和所述说话者所在位置的场景图像,确定所述语音信号对应的第一文本以及所述场景图像对应的第二文本,并将所述第一文本和所述第二文本发送至所述云端服务器;所述第二文本用于描述所述场景图像的图像内容;
5、所述云端服务器,用于基于预设提示模板获取所述第一文本和所述第二文本对应的提示文本,并将所述提示文本输入至大语言模型,得到与所述提示文本对应的对话内容,将所述对话内容发送至所述机器人,以使得所述机器人基于所述对话内容与所述说话者进行对话交互;所述预设提示模板用于限定对所述第一文本和所述第二文本进行描述的内容格式,所述提示文本用于引导所述大语言模型进行推理。
6、第二方面,本发明实施例提供一种机器人对话方法,应用于机器人对话系统中的机器人,所述方法包括:
7、采集说话者的语音信号和所述说话者所在位置的场景图像,所述语音信号中包含所述说话者的语音;
8、确定所述语音信号对应的第一文本;
9、确定所述场景图像对应的第二文本,所述第二文本用于描述所述场景图像的图像内容;
10、将所述第一文本和所述第二文本发送至所述云端服务器,以使得所述云端服务器基于预设提示模板获取所述第一文本和所述第二文本对应的提示文本,并将所述提示文本输入至大语言模型,得到与所述提示文本对应的对话内容;所述预设提示模板用于限定对所述第一文本和所述第二文本进行描述的内容格式,所述提示文本用于引导所述大语言模型进行推理;
11、接收所述云端服务器发送的所述对话内容,并基于所述对话内容与所述说话者进行对话交互。
12、第三方面,本发明实施例提供一种机器人对话装置,位于机器人对话系统中的机器人,该装置包括:
13、采集模块,用于采集说话者的语音信号和所述说话者所在位置的场景图像,所述语音信号中包含所述说话者的语音;
14、第一确定模块,用于确定所述语音信号对应的第一文本;
15、第二确定模块,用于确定所述场景图像对应的第二文本,所述第二文本用于描述所述场景图像的图像内容;
16、发送模块,用于将所述第一文本和所述第二文本发送至所述云端服务器,以使得所述云端服务器基于预设提示模板获取所述第一文本和所述第二文本对应的提示文本,并将所述提示文本输入至大语言模型,得到与所述提示文本对应的对话内容;所述预设提示模板用于限定对所述第一文本和所述第二文本进行描述的内容格式,所述提示文本用于引导所述大语言模型进行推理;
17、交互模块,用于接收所述云端服务器发送的所述对话内容,并基于所述对话内容与所述说话者进行对话交互。
18、第四方面,本发明实施例提供一种机器人,包括:存储器、处理器、通信接口;其中,所述存储器上存储有可执行代码,当所述可执行代码被所述处理器执行时,使所述处理器执行如第二方面所述的机器人对话方法。
19、第五方面,本发明实施例提供了一种非暂时性机器可读存储介质,所述非暂时性机器可读存储介质上存储有可执行代码,当所述可执行代码被电子设备的处理器执行时,使所述处理器至少可以实现如第二方面所述的机器人对话方法。
20、第六方面,本发明实施例提供一种机器人对话方法,应用于机器人对话系统中的云端服务器,所述方法包括:
21、接收机器人发送的第一文本和第二文本,其中,所述机器人采集说话者的语音信号和所述说话者所在位置的场景图像,确定所述语音信号对应的第一文本以及所述场景图像对应的第二文本,并将所述第一文本和所述第二文本发送至所述云端服务器;所述第二文本用于描述所述场景图像的图像内容;
22、基于预设提示模板获取所述第一文本和所述第二文本对应的提示文本,所述预设提示模板用于限定对所述第一文本和所述第二文本进行描述的内容格式,所述提示文本用于引导所述大语言模型进行推理;
23、将所述提示文本输入至大语言模型,得到与所述提示文本对应的对话内容,将所述对话内容发送至所述机器人,以使得所述机器人基于所述对话内容与所述说话者进行对话交互。
24、第七方面,本发明实施例提供一种机器人对话装置,位于机器人对话系统中的云端服务器,该装置包括:
25、接收模块,用于接收机器人发送的第一文本和第二文本,其中,所述机器人采集说话者的语音信号和所述说话者所在位置的场景图像,确定所述语音信号对应的第一文本以及所述场景图像对应的第二文本,并将所述第一文本和所述第二文本发送至所述云端服务器;所述第二文本用于描述所述场景图像的图像内容;
26、获取模块,用于基于预设提示模板获取所述第一文本和所述第二文本对应的提示文本,所述预设提示模板用于限定对所述第一文本和所述第二文本进行描述的内容格式,所述提示文本用于引导所述大语言模型进行推理;
27、处理模块,用于将所述提示文本输入至大语言模型,得到与所述提示文本对应的对话内容,将所述对话内容发送至所述机器人,以使得所述机器人基于所述对话内容与所述说话者进行对话交互。
28、第八方面,本发明实施例提供一种云端服务器,包括:存储器、处理器、通信接口;其中,所述存储器上存储有可执行代码,当所述可执行代码被所述处理器执行时,使所述处理器至少可以实现如第六方面所述的机器人对话方法。
29、第九方面,本发明实施例提供了一种非暂时性机器可读存储介质,所述非暂时性机器可读存储介质上存储有可执行代码,当所述可执行代码被用户设备的处理器执行时,使所述处理器至少可以实现如第六方面所述的机器人对话方法。
30、本发明实施例提供的机器人对话方案中,主要包括机器人和云端服务器。机器人在与用户进行语音对话的过程中,机器人先采集说话者的语音信号和说话者所在位置的场景图像,而后确定语音信号对应的第一文本以及场景图像对应的第二文本,其中,第一文本用于描述语音内容,第二文本用于描述场景图像的图像内容。最后,机器人将处理后获得的第一文本和第二文本发送至云端服务器。云端服务器接收到机器人发送的第一文本和第二文本之后,首先基于预设提示模板获取第一文本和第二文本对应的提示文本,并将提示文本输入至大语言模型,得到与提示文本对应的对话内容。其中,预设提示模板用于限定对第一文本和第二文本进行描述的内容格式,基于预设提示模版,生成固定格式的提示文本,提示文本可以用于引导大语言模型进行推理,以得到更准确地对话内容。
31、上述方案,通过将对话处理过程分为两部分处理,即机器人对采集到的说话者的语音信号和场景图像进行预处理,获得对应的第一文本和第二文本,再将处理后的第一文本和第二文本传输至云端服务器,使得云端服务器可以直接对第一文本和第二文本进行处理,这样不仅提高了云端服务器的处理效率,还可以降低端到端之间的时延问题。另外,在进行对话处理时,结合了说话者所在环境的场景信息生成个性化地对话内容,可以提升用户体验感,并且通过预设提示模板获取语音信号和场景图像对应的提示文本,利用提示文本引导大语言模型可以更好地理解对话场景,并结合对话场景进行推理,以获得更精准地对话内容,使得机器人可以更加智能地与说话者进行对话交互。
- 还没有人留言评论。精彩留言会获得点赞!