用于语音增强的神经网络训练的制作方法
本实施例总体上涉及神经网络,并且具体地涉及用于语音增强的训练神经网络。
背景技术:
1、用于增强音频信号中的语音的许多机器学习方法基于信噪比(snr)信息。这些方法通常需要大量的训练数据来训练机器学习模型(例如,神经网络模型)以计及噪声的大变化。因此,一旦机器模型被训练,机器学习模型可能太大以至于不能在诸如移动设备、可穿戴技术、或物联网(iot)设备之类的资源受限平台上实现。此外,用于增强音频信号中的语音的许多机器学习方法并非非常适合于远场应用,其中语音源位于距一个或多个音频捕获设备一定距离处。
技术实现思路
1、提供本
技术实现要素:
是为了以简化形式介绍将在以下具体实施方式中进一步描述的概念的选择。本发明内容不旨在标识所要求保护的主题的关键特征或必要特征,也不旨在限制所要求保护的主题的范围。
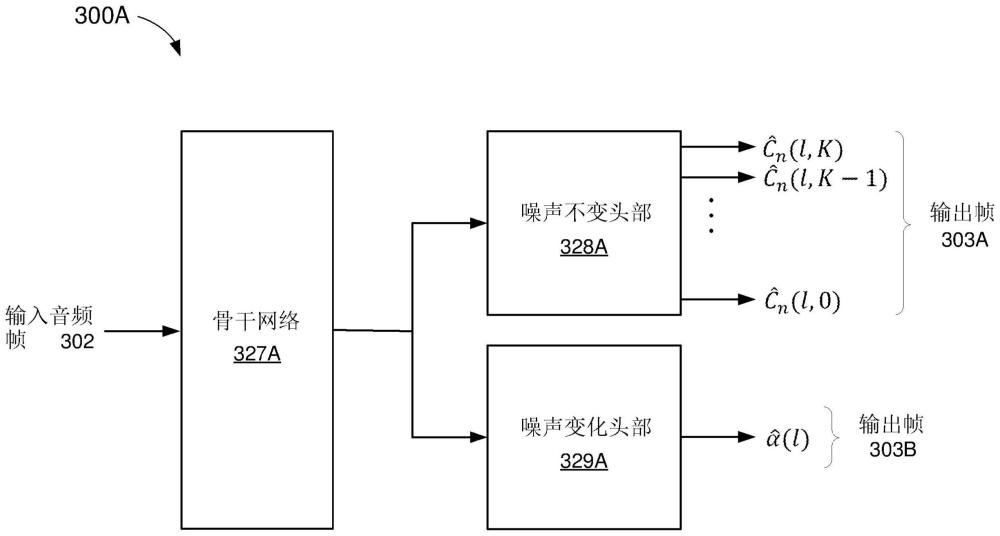
2、本公开的主题的一个创新方面可以在训练神经网络的方法中实现。该方法可以包括接收音频帧序列,以及基于神经网络将音频帧序列中的第一音频帧映射到第一输出帧。第一输出帧可以表示第一音频帧的噪声不变分量。该方法还可以包括基于第一输出帧与第一地面实况帧之间的差来确定第一损失值。该方法还可以包括基于神经网络将第一音频帧映射到第二输出帧,其中第二输出帧表示第一音频帧的噪声变化分量。另外,该方法可以包括:基于第二输出帧与第二地面实况帧之间的差来确定第二损失值;以及至少部分地基于第一损失值和第二损失值来更新神经网络。
3、本公开的主题的另一创新方面可以在包括处理系统和存储器的机器学习系统中实现。存储器可以存储指令,所述指令在由处理系统执行时使机器学习系统:接收音频帧序列,并且基于神经网络将音频帧序列中的第一音频帧映射到第一输出帧。第一输出帧可以表示第一音频帧的噪声不变分量。指令的执行还可以使机器学习系统基于第一输出帧与第一地面实况帧之间的差来确定第一损失值,并且基于神经网络将第一音频帧映射到第二输出帧。第二输出帧可表示第一音频帧的噪声变化分量。另外,指令的执行可以使机器学习系统基于第二输出帧与第二地面实况帧之间的差来确定第二损失值,并且至少部分地基于第一损失值和第二损失值来更新神经网络。
4、本公开的主题的另一创新方面可以在一种训练神经网络的方法中实现。该方法可以包括接收音频帧序列,以及基于第一神经网络将音频帧序列中的第一音频帧映射到第一输出帧。第一输出帧可以表示第一音频帧的噪声不变分量。该方法还可以包括基于第一输出帧与第一地面实况帧之间的差来确定第一损失值,以及至少部分地基于第一损失值来更新第一神经网络。
技术特征:
1.一种训练神经网络的方法,包括:
2.根据权利要求1所述的方法,其中所述第一音频帧到所述第二输出帧的映射进一步基于所述第一音频帧的相位。
3.根据权利要求2所述的方法,其中所述第一音频帧到所述第二输出帧的映射进一步基于所述第一音频帧的幅度。
4.根据权利要求1所述的方法,其中所述第二输出帧进一步表示所述第一音频帧的所述噪声不变分量中的能量的量相对于所述第一音频帧的能量的量的比率。
5.根据权利要求1所述的方法,其中接收的第一音频帧是基于频谱幅度来归一化的。
6.根据权利要求1所述的方法,其中所述第一音频帧包括多个子帧,且其中所述多个子帧中的每一个与相应频率仓相关联。
7.根据权利要求1所述的方法,其中所述神经网络的更新包括:
8.根据权利要求7所述的方法,其中所述神经网络的所述更新还包括:
9.根据权利要求1所述的方法,还包括:
10.一种机器学习系统,包括:
11.根据权利要求10所述的机器学习系统,其中所述第一音频帧到所述第二输出帧的映射进一步基于所述第一音频帧的相位。
12.根据权利要求11所述的机器学习系统,其中所述第一音频帧到所述第二输出帧的映射进一步基于所述第一音频帧的幅度。
13.根据权利要求10所述的机器学习系统,其中所述第二输出帧进一步表示所述第一音频帧的所述噪声不变分量中的能量的量相对于所述第一音频帧的能量的量的比率。
14.根据权利要求10所述的机器学习系统,其中接收的第一音频帧是基于频谱幅度来归一化的。
15.根据权利要求10所述的机器学习系统,其中所述第一音频帧包括多个子帧,并且其中所述多个子帧中的每一个与相应频率仓相关联。
16.根据权利要求10所述的机器学习系统,其中所述神经网络的更新还使所述机器学习系统:对至少所述第一损失值和所述第二损失值求和以确定总损失值。
17.根据权利要求16所述的机器学习系统,其中所述神经网络的所述更新还使所述机器学习系统:
18.根据权利要求10所述的机器学习系统,其中所述指令的执行还使所述机器学习系统:基于所述神经网络将所述音频帧序列中的第二音频帧映射到第三输出帧,其中所述第三输出帧表示所述第二音频帧的噪声不变分量;
19.一种训练神经网络的方法,包括:
20.根据权利要求19所述的方法,还包括:
技术总结
一种训练神经网络的方法可以包括:接收音频帧序列;以及基于神经网络将音频帧序列中的第一音频帧映射到第一输出帧。第一输出帧可以表示第一音频帧的噪声不变分量。该方法还可包括基于第一输出帧与第一地面实况帧之间的差确定第一损失值。该方法可以包括基于神经网络将第一音频帧映射到第二输出帧。第二输出帧可表示第一音频帧的噪声变化分量。该方法还可以包括:基于第二输出帧与第二地面实况帧之间的差来确定第二损失值;以及至少部分地基于第一损失值和第二损失值来更新神经网络。
技术研发人员:S·莫萨耶布普尔·卡斯卡里,A·普亚
受保护的技术使用者:辛纳普蒂克斯公司
技术研发日:
技术公布日:2024/5/16
- 还没有人留言评论。精彩留言会获得点赞!