一种声音类型识别修正方法、系统、装置及介质与流程
本发明涉及声音识别,尤其涉及一种声音类型识别修正方法、系统、装置及介质。
背景技术:
1、声音类型识别,依赖边缘ai(artificial intelligence,人工智能)声音识别设备,使用特定的麦克风或麦克风阵列,收集自然界声音并转换成数字信号,然后经过特定的ai算法,对声音类型进行分类。该技术广泛应用于环境噪声治理、声源定位、声源溯源或各类危机预警等方面。
2、现有的边缘ai声音识别设备,限制于其设备的算力、存储和网络,只能对声音进行相对单纯的分类,而获取的声音容易受到干扰,使得获取到的声音分类结果不精确。
技术实现思路
1、有鉴于此,本发明实施例的目的是提供一种声音类型识别修正方法、系统、装置及介质,能够对获取到的声音进行分类识别修正,从而减少声音受到的干扰,使得获取到的声音分类结果精确。
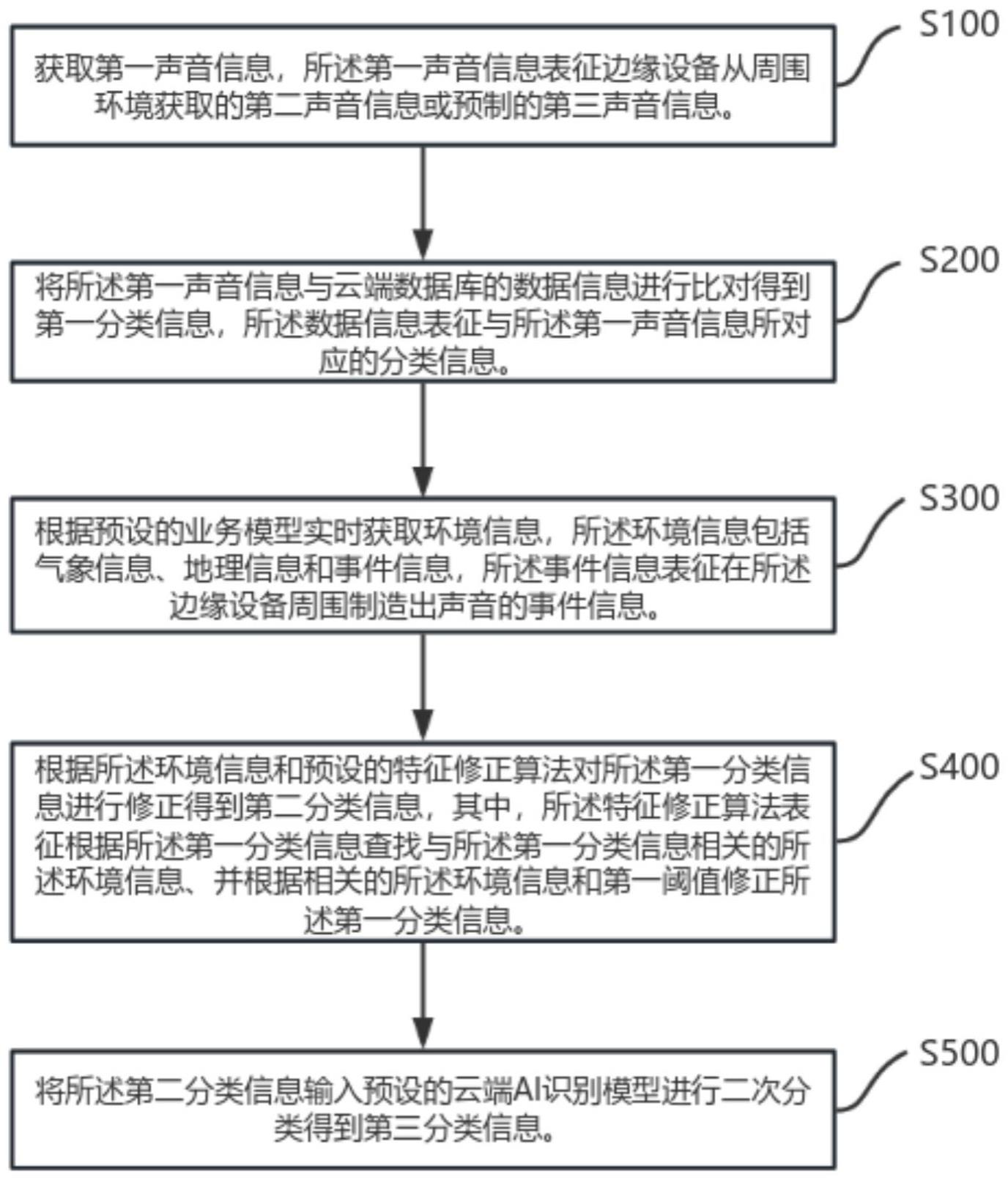
2、第一方面,本发明实施例提供了一种声音类型识别修正方法,包括以下步骤:
3、获取第一声音信息,所述第一声音信息表征边缘设备从周围环境获取的第二声音信息或预制的第三声音信息;
4、将所述第一声音信息与云端数据库的数据信息进行比对得到第一分类信息,所述数据信息表征与所述第一声音信息所对应的分类信息;
5、根据预设的业务模型实时获取环境信息,所述环境信息包括气象信息、地理信息和事件信息,所述事件信息表征在所述边缘设备周围制造出声音的事件信息;
6、根据所述环境信息和预设的特征修正算法对所述第一分类信息进行修正得到第二分类信息,其中,所述特征修正算法表征根据所述第一分类信息查找与所述第一分类信息相关的所述环境信息、并根据相关的所述环境信息和第一阈值修正所述第一分类信息;
7、将所述第二分类信息输入预设的云端ai识别模型进行二次分类得到第三分类信息。
8、可选地,所述根据所述环境信息和预设的特征修正算法对所述第一分类信息进行修正得到第二分类信息,具体包括:
9、根据所述第一分类信息和所述环境信息确定第一环境信息,所述第一环境信息表征与所述第一分类信息相关的所述气象信息、所述地理信息和事件信息中的任一项或任多项;
10、根据所述第一环境信息和所述第一阈值的大小,将所述第一分类信息修正为第二分类信息。
11、可选地,所述根据所述第一环境信息和所述第一阈值的大小,将所述第一分类信息修正为第二分类信息,具体包括:
12、基于所述第一环境信息获取与所述第一环境信息相对应的所述第一阈值,其中,所述第一环境信息与所述第一阈值通过对应表相对应;
13、基于所述第一环境信息获取与所述第一环境信息相对应的数据值,所述数据值表征所述第一环境信息进行数据化表示后的值;
14、若所述数据值小于所述第一阈值,则将所述第一分类信息修正为其他声音类型信息,此时,所述第二分类信息表示所述其他声音类型信息;
15、若所述数据值大于或等于所述第一阈值,则将所述第一分类信息修正为与所述第一环境信息对应的环境声音类型信息,此时,所述第二分类信息表示所述环境声音类型信息。
16、可选地,所述基于所述第一环境信息获取与所述第一环境信息相对应的数据值,具体包括:
17、根据所述第一环境信息获取若干个第二环境信息,其中,所述第一环境信息包括多个所述第二环境信息;
18、分别获取若干个所述第二环境信息相对应的所述数据值。
19、可选地,所述将所述第一声音信息与云端数据库的数据信息进行比对得到第一分类信息,具体包括:
20、获取所述第一声音信息的第一特征信息;
21、获取所述数据信息的多个第二特征信息;
22、将所述第一特征信息分别与多个所述第二特征信息进行对比得到多个特征相似值,其中,一个所述特征相似值对应一个所述第二特征信息,一个所述第二特征信息对应一种声音类型信息;
23、将多个所述特征相似值进行对比得到最大特征相似值;
24、将所述最大特征相似值与第二阈值进行比对得到所述第一分类信息。
25、可选地,所述将所述最大特征相似值与第二阈值进行比对得到所述第一分类信息,具体包括:
26、将所述最大特征相似值与所述第二阈值进行比对得到比对结果;
27、若所述最大特征相似值大于或等于所述第二阈值,则将所述最大特征相似值对应的所述声音类型信息作为所述第一分类信息;
28、否则,将未知声音类型信息作为所述第一分类信息。
29、可选地,所述将所述第二分类信息输入预设的云端ai识别模型进行二次分类得到第三分类信息之后,还包括:
30、将所述第三分类信息与所述第三分类信息所对应的所述第一声音信息存储到所述云端数据库。
31、第二方面,本发明实施例提供了一种声音类型识别修正方法系统,包括:
32、第一模块,用于获取第一声音信息,所述第一声音信息表征边缘设备从周围环境获取的第二声音信息或预制的第三声音信息;
33、第二模块,用于将所述第一声音信息与云端数据库的数据信息进行比对得到第一分类信息,所述数据信息表征与所述第一声音信息所对应的分类信息;
34、第三模块,用于根据预设的业务模型实时获取环境信息,所述环境信息包括气象信息、地理信息和事件信息,所述事件信息表征在所述边缘设备周围制造出声音的事件信息;
35、第四模块,用于根据所述环境信息和预设的特征修正算法对所述第一分类信息进行修正得到第二分类信息,其中,所述特征修正算法表征根据所述第一分类信息查找与所述第一分类信息相关的所述环境信息、并根据相关的所述环境信息和第一阈值修正所述第一分类信息;
36、第五模块,用于将所述第二分类信息输入预设的云端ai识别模型进行二次分类得到第三分类信息。
37、第三方面,本发明实施例提供了一种声音类型识别修正方法装置,包括:
38、至少一个处理器;
39、至少一个存储器,用于存储至少一个程序;
40、当所述至少一个程序被所述至少一个处理器执行,使得所述至少一个处理器实现如上所述的方法。
41、第四方面,本发明实施例提供了一种计算机可读存储介质,其中存储有处理器可执行的程序,所述处理器可执行的程序在由处理器执行时用于执行如上所述的方法。
42、实施本发明实施例包括以下有益效果:本发明实施例提供一种声音类型识别修正方法,包括:获取第一声音信息,所述第一声音信息表征边缘设备从周围环境获取的第二声音信息或预制的第三声音信息;将所述第一声音信息与云端数据库的数据信息进行比对得到第一分类信息,所述数据信息表征与所述第一声音信息所对应的分类信息;根据预设的业务模型实时获取环境信息,所述环境信息包括气象信息、地理信息和事件信息,所述事件信息表征在所述边缘设备周围制造出声音的事件信息;根据所述环境信息和预设的特征修正算法对所述第一分类信息进行修正得到第二分类信息,其中,所述特征修正算法表征根据所述第一分类信息查找与所述第一分类信息相关的所述环境信息、并根据相关的所述环境信息和第一阈值修正所述第一分类信息;将所述第二分类信息输入预设的云端ai识别模型进行二次分类得到第三分类信息。获取到第一声音信息后,通过预设的云端数据库的数据信息来比对,从而保证第一声音信息的初步分类准确,并通过实时环境信息和特征修正算法来修正第一分类信息得到第二分类信息,从而优化分类结果,免除干扰,最后进过云端ai识别模型进行二次分类得到最终的分类结果,更近一步保证了分类结果的准确性,从而提高了识别声音类型的准确性。
- 还没有人留言评论。精彩留言会获得点赞!