口语评测方法、装置、设备及存储介质与流程
本技术涉及口语评测,更具体的说,是涉及一种口语评测方法、装置、设备及存储介质。
背景技术:
1、口语评测是指对于受测者针对参考文本所朗读的音频进行评测的过程。口语测评场景可以包括背诵测评、朗读测评等。其中,背诵测评是指给定需要背诵的参考文本如课文,获取受测者以背诵的形式得到的目标音频,进而对目标音频从背诵完整度、发音准确度、背诵流利度等不同维度来评价背诵质量。朗读测评与背诵测评类似,区别仅在于参考文本不需要背诵,仅参照进行朗读即可。最终从朗读完整度、朗读准确度、朗读流利度等不同维度来评价朗读质量。
2、传统的口语评测方法一般是采用语音识别模型对受测目标音频进行识别,得到识别文本。进一步将识别文本与参考文本按照设定匹配规则进行匹配,得到完整度测评结果。这种级联式的测评方案在语音识别阶段会存在识别误差,并将该误差继承到后续匹配阶段,导致测评结果不准确。
技术实现思路
1、鉴于上述问题,提出了本技术以便提供一种口语评测方法、装置、设备及存储介质,以避免现有技术采用级联方案容易继承识别误差,导致测评结果不准确的问题。具体方案如下:
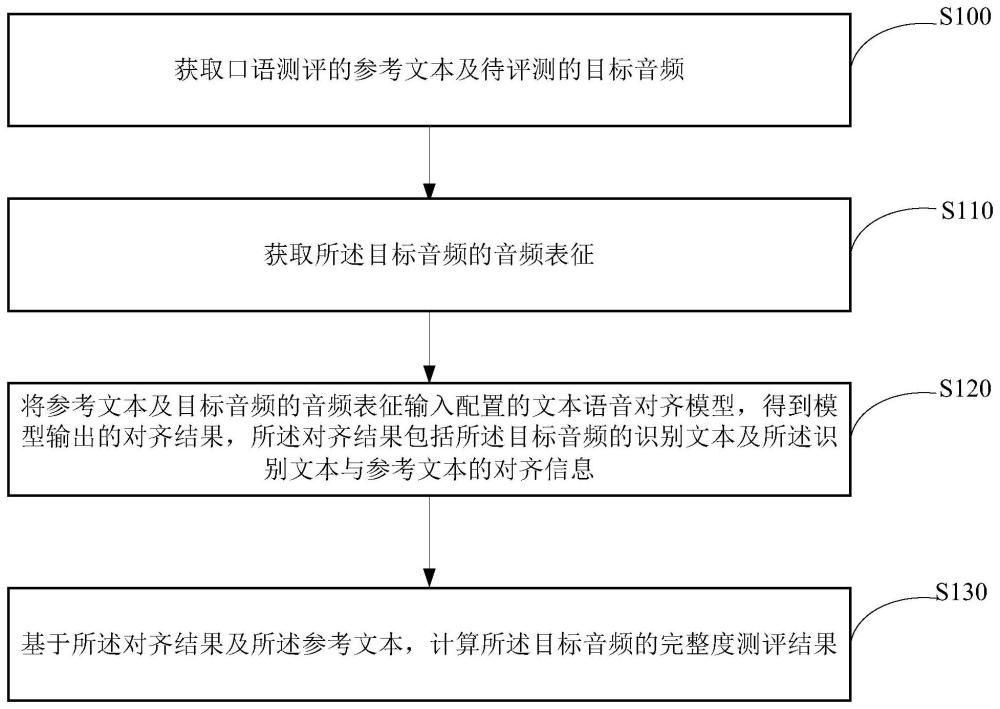
2、第一方面,提供了一种口语评测方法,包括:
3、获取口语测评的参考文本及待评测的目标音频;
4、获取所述目标音频的音频表征;
5、将所述参考文本及所述目标音频的音频表征输入配置的文本语音对齐模型,得到模型输出的对齐结果,所述对齐结果包括所述目标音频的识别文本及所述识别文本与所述参考文本的对齐信息;其中,所述文本语音对齐模型被配置为,提取输入的所述参考文本的嵌入表征,将所述嵌入表征与所述音频表征拼接,并基于拼接表征解码得到所述对齐结果的内部状态表示;
6、基于所述对齐结果及所述参考文本,计算所述目标音频的完整度测评结果。
7、优选地,所述识别文本与所述参考文本的对齐信息,包括:所述识别文本中各字符在所述参考文本中的位置编码,且所述识别文本中未能匹配到所述参考文本的字符,其位置编码采用第一设定标识表示。
8、优选地,获取所述目标音频的音频表征的过程,包括:
9、获取配置的语音识别模型对所述目标音频所提取的用于预测识别文本的隐层表征,作为所述目标音频的音频表征。
10、优选地,还包括:
11、获取所述语音识别模型对所述目标音频预测的识别文本的第一长度,并输入所述文本语音对齐模型,以供所述文本语音对齐模型基于所述第一长度及所述参考文本的第二长度得到输入位置编码表征,将所述输入位置编码表征和所述拼接表征融合,基于融合表征解码得到所述对齐结果。
12、优选地,所述文本语音对齐模型在训练阶段的训练数据包括:
13、对音频样本-参考文本组中的所述音频样本提取音频表征,由所述音频表征及所述参考文本组成输入训练样本;
14、标注所述音频样本的识别文本及所述识别文本与所述参考文本的对齐信息,由所述识别文本及所述对齐信息组成所述训练样本对应的样本标签。
15、优选地,所述音频样本-参考文本组中的音频样本包括:
16、对参考文本按照正常顺序朗读的音频样本;
17、对参考文本存在句子漏读以及句中字符漏读时的音频样本;
18、对参考文本存在句子增读以及句中字符增读时的音频样本。
19、优选地,所述语音识别模型被配置为,对输入的所述目标音频的声学特征进行编、解码,得到第一解码特征,以所述参考文本中的内容作为激励文本并提取特征,融合所述激励文本的特征和所述第一解码特征得到用于预测识别文本的隐层表征的内部状态表示。
20、优选地,所述激励文本为所述参考文本;或,
21、所述激励文本为动态激励文本,具体包括:当前时刻待解码字符在所述参考文本中的上下文信息。
22、优选地,所述语音识别模型包括:
23、编码器、解码器和动态文本激励模块;
24、所述编码器用于,对输入的所述目标音频的声学特征进行编码,编码特征送入所述解码器;
25、所述动态文本激励模块用于,根据当前时刻待解码字符在所述参考文本中确定上下文信息,将所述上下文信息作为动态激励文本并对所述动态激励文本进行编码,编码特征送入所述解码器;
26、所述解码器用于,结合上一时刻的解码字符和所述编码器输入的编码特征进行解码,得到第一解码特征,融合所述第一解码特征和所述动态文本激励模块输入的编码特征得到隐层表征,基于所述隐层表征预测当前时刻的解码字符。
27、优选地,基于所述对齐结果及所述参考文本,计算所述目标音频的完整度测评结果的过程,包括:
28、在所述对齐结果所包含的对齐信息中,剔除所述第一设定标识的位置编码,并对剩余的各位置编码进行去重,计算去重后各位置编码的第一数量;
29、将所述第一数量与所述参考文本所包含字符的总数量的比值,作为所述目标音频的完整度得分。
30、优选地,还包括:
31、获取所述文本语音对齐模型对输入数据提取的用于预测所述对齐结果的隐层表征,作为文本语音对齐表征;
32、将所述参考文本及所述文本语音对齐表征输入配置的朗读评分模型,得到模型输出的所述目标音频的流利度测评结果和准确度测评结果,由所述流利度测评结果、所述准确度测评结果和所述完整度测评结果组成所述目标音频的整体测评结果;
33、其中,所述朗读评分模型以训练音频经所述文本语音对齐模型提取的文本语音对齐表征,及所述训练音频对应的参考文本作为训练样本,以所述训练音频标注的流利度得分和准确度得分作为样本标签训练得到。
34、优选地,所述待评测的目标音频为获取的用户实时朗读的音频;
35、则该方法还包括:
36、在终端界面上显示所述参考文本,以及,在用户朗读过程中,基于所述对齐结果将实时得到的识别文本在所述参考文本上所对齐的字符通过第一标记显示,以实现口语跟踪显示。
37、优选地,所述口语测评的参考文本为指定需要背诵的文本,所述目标音频为用户针对所述参考文本的背诵音频;
38、或,
39、所述口语测评的参考文本为指定需要朗读的文本,所述目标音频为用户针对所述参考文本的朗读音频。
40、第二方面,提供了一种口语评测装置,包括:
41、数据获取单元,用于获取口语测评的参考文本及待评测的目标音频;
42、音频表征获取单元,用于获取所述目标音频的音频表征;
43、模型调用单元,用于将所述参考文本及所述目标音频的音频表征输入配置的文本语音对齐模型,得到模型输出的对齐结果,所述对齐结果包括所述目标音频的识别文本及所述识别文本与所述参考文本的对齐信息;其中,所述文本语音对齐模型被配置为,提取输入的所述参考文本的嵌入表征,将所述嵌入表征与所述音频表征拼接,并基于拼接表征解码得到所述对齐结果的内部状态表示;
44、完整度计算单元,用于基于所述对齐结果及所述参考文本,计算所述目标音频的完整度测评结果。
45、第三方面,提供了一种口语评测设备,包括:存储器和处理器;
46、所述存储器,用于存储程序;
47、所述处理器,用于执行所述程序,实现如前所述的口语评测方法的各个步骤。
48、第四方面,提供了一种存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时,实现如前所述的口语评测方法的各个步骤。
49、借由上述技术方案,本技术提出了一种基于文本语音对齐的口语评测方式,与传统的先通过语音识别模型对目标音频进行识别,进一步将识别文本与参考文本进行匹配的级联方案不同的是,本技术配置了文本语音对齐模型,该模型的输入为目标音频的音频表征及参考文本,模型被配置为提取参考文本的嵌入表征,并将嵌入表征与音频表征进行拼接,基于拼接表征解码得到对齐结果,对齐结果包括了目标音频的识别文本及识别文本与参考文本的对齐信息,由此可见,本技术的文本语音对齐模型采用了目标音频的音频表征,用于对齐目标音频和参考文本,通过文本语音对齐模型即可端到端的直接预测得到对齐结果,避免了传统方案识别结果中产生的级联误差。在得到对齐结果后可以进一步基于对齐结果和参考文本来计算目标音频的完整度测评结果,提高了口语完整度测评结果的准确度。
- 还没有人留言评论。精彩留言会获得点赞!