一种语音唤醒方法、电子设备和计算机可读存储介质与流程
【】本发明涉及声学,尤其涉及一种语音唤醒方法、电子设备和计算机可读存储介质。
背景技术
0、
背景技术:
1、相关技术中的语音唤醒方法,通常使用微型机电系统(micro-electro-mechanical system,简称mems)麦克风对语音信号进行采集,然后通过音频传输接口传输给中央处理器(central processing unit,简称cpu)的主控芯片,主控芯片通过运行算法实现语音唤醒功能,其中,mems麦克风需要借助外部cpu对语音信号的处理和识别,需要cpu长期保持在运行状态,功耗较高,且mems麦克风的功能单一,不利于产品模块化。
2、在语音唤醒方法的信号预处理过程中,常使用端点检测算法从一段包含噪声的语音信号中正确查找出语音信号的开始点和终止点,其中,端点检测算法为双门限检测算法,结合短时能量和短时过零点来区分语音的静音段,过渡音段和语音段以及结束段,双门限检测算法的误差和计算开销较大。
技术实现思路
0、
技术实现要素:
1、有鉴于此,本发明实施例提供了一种语音唤醒方法、电子设备和计算机可读存储介质,用以在降低电子设备功耗的同时,提高语音唤醒的准确性。
2、一方面,本发明实施例提供了一种语音唤醒方法,应用于电子设备,包括:
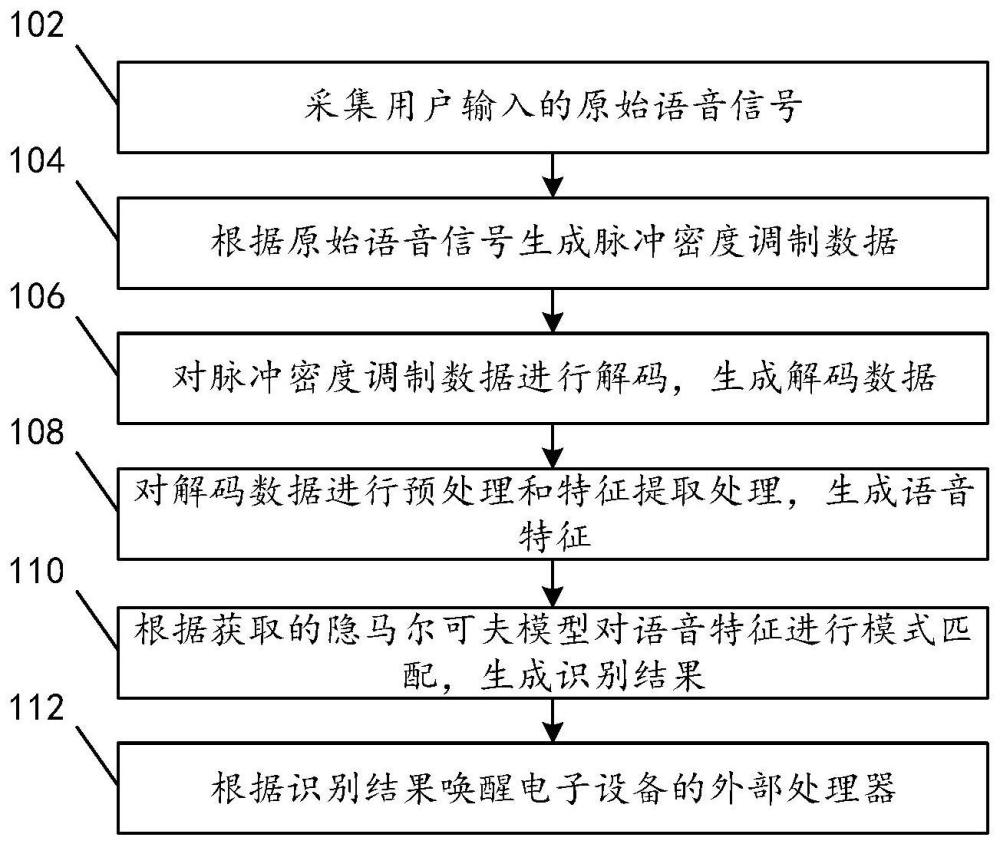
3、采集用户输入的原始语音信号;
4、根据所述原始语音信号生成脉冲密度调制数据;
5、对所述脉冲密度调制数据进行解码,生成解码数据;
6、对所述解码数据进行预处理和特征提取处理,生成语音特征;
7、根据获取的隐马尔可夫模型对所述语音特征进行模式匹配,生成识别结果;
8、根据所述识别结果唤醒所述电子设备的外部处理器。
9、可选地,所述对所述解码数据进行预处理和特征提取处理,生成语音特征,包括:
10、通过改进端点检测算法对所述解码数据进行预处理,生成原始语音信号的有效音段;
11、通过特征提取算法提取出所述有效音段的特征信息;
12、对所述特征信息进行矢量量化,生成语音特征。
13、可选地,所述通过改进端点检测算法对所述解码数据进行预处理,生成原始语音信号的有效音段,包括:
14、过滤所述解码数据中的干扰信号,生成过滤数据;
15、对所述过滤数据进行预加重处理,生成预加重数据;
16、对所述预加重数据进行分帧处理,生成多帧数据;
17、对多帧数据中的每帧数据进行加窗处理,生成加窗数据;
18、基于所述改进端点检测算法提取出所述加窗数据中的有效内容;
19、基于梅尔频率倒谱系数特征提取算法对所述有效内容进行计算,生成原始语音信号的有效音段。
20、可选地,所述改进端点检测算法包括公式其中,ρ为短时能量变化率,δ为短时能量阈值,为可调的影响因子。
21、可选地,所述根据获取的隐马尔可夫模型对所述语音特征进行模式匹配,生成识别结果,包括:
22、根据所述隐马尔可夫模型,使用前向算法对所述语音特征进行模式匹配,以通过设置的判别规则判定用户输入的原始语音信号中是否包括预设命令,生成识别结果。
23、可选地,所述根据所述隐马尔可夫模型,使用前向算法对所述语音特征进行模式匹配,以通过设置的判别规则判定用户输入的原始语音信号中是否包括预设命令,生成识别结果,包括:
24、采用矢量量化将二维的所述语音特征转换为一维的符号序列;
25、穷举当前帧的符号序列对应的所有可能状态序列,生成特征序列;
26、根据转移概率和发射概率,得到特征帧序列由每种状态序列产生的概率;
27、将每种状态序列中的状态数目扩展到特征帧的数量,将每种状态序列的概率求和,作为特征帧序列被识别成单词序列的似然概率;
28、计算特征帧序列中单词序列在语音模型中的概率作为单词序列的先验概率;
29、将所述似然概率和所述先验概率相乘作为单词序列的后验概率;
30、将后验概率中最大的单词序列作为识别结果。
31、另一方面,本发明实施例提供了一种电子设备,包括:外部处理器和智能麦克风,所述智能把麦克风包括麦克风和数字信号处理器;
32、所述麦克风,用于采集用户输入的原始语音信号;
33、所述数字信号处理器,用于根据所述原始语音信号生成脉冲密度调制数据;对所述脉冲密度调制数据进行解码,生成解码数据;对所述解码数据进行预处理和特征提取处理,生成语音特征;根据获取的隐马尔可夫模型对所述语音特征进行模式匹配,生成识别结果;将所述识别结果发送至所述外部处理器;
34、所述外部处理器,用于根据所述识别结果进行自唤醒。
35、可选地,所述数字信号处理器接收服务器发送的隐马尔可夫模型,所述隐马尔可夫模型是服务器训练的。
36、可选地,所述外部处理器包括中央处理器或系统级芯片。
37、另一方面,本发明实施例提供了一种计算机可读存储介质,所述计算机可读存储介质包括存储的程序,其中,在所述程序运行时控制所述计算机可读存储介质所在设备执行上述语音唤醒方法。
38、本发明实施例提供的语音唤醒方法的技术方案中,采集用户输入的原始语音信号;根据原始语音信号生成脉冲密度调制数据;对脉冲密度调制数据进行解码,生成解码数据;对解码数据进行预处理和特征提取处理,生成语音特征;根据获取的隐马尔可夫模型对语音特征进行模式匹配,生成识别结果;根据识别结果唤醒电子设备的外部处理器。本发明实施例提供的技术方案中,通过对解码数据进行预处理和特征提取处理,生成语音特征;根据获取的隐马尔可夫模型对语音特征进行模式匹配,生成识别结果并根据识别结果唤醒电子设备的外部处理器,实现了语音唤醒功能,在降低电子设备功耗的同时,提高语音唤醒的准确性。
技术特征:
1.一种语音唤醒方法,其特征在于,应用于电子设备,包括:
2.根据权利要求1所述的方法,其特征在于,所述对所述解码数据进行预处理和特征提取处理,生成语音特征,包括:
3.根据权利要求2所述的方法,其特征在于,所述通过改进端点检测算法对所述解码数据进行预处理,生成原始语音信号的有效音段,包括:
4.根据权利要求2或3所述的方法,其特征在于,所述改进端点检测算法包括公式其中,ρ为短时能量变化率,δ为短时能量阈值,为可调的影响因子。
5.根据权利要求1所述的方法,其特征在于,所述根据获取的隐马尔可夫模型对所述语音特征进行模式匹配,生成识别结果,包括:
6.根据权利要求5所述的方法,其特征在于,所述根据所述隐马尔可夫模型,使用前向算法对所述语音特征进行模式匹配,以通过设置的判别规则判定用户输入的原始语音信号中是否包括预设命令,生成识别结果,包括:
7.一种电子设备,其特征在于,包括:外部处理器和智能麦克风,所述智能把麦克风包括麦克风和数字信号处理器;
8.根据权利要求7所述的电子设备,其特征在于,所述数字信号处理器接收服务器发送的隐马尔可夫模型,所述隐马尔可夫模型是服务器训练的。
9.根据权利要求7所述的电子设备,其特征在于,所述外部处理器包括中央处理器或系统级芯片。
10.一种计算机可读存储介质,其特征在于,所述计算机可读存储介质包括存储的程序,其中,在所述程序运行时控制所述计算机可读存储介质所在设备执行权利要求1至6中任意一项所述的语音唤醒方法。
技术总结
本发明实施例提供了一种语音唤醒方法、电子设备和计算机可读存储介质。该方法包括:采集用户输入的原始语音信号;根据原始语音信号生成脉冲密度调制数据;对脉冲密度调制数据进行解码,生成解码数据;对解码数据进行预处理和特征提取处理,生成语音特征;根据获取的隐马尔可夫模型对语音特征进行模式匹配,生成识别结果;根据识别结果唤醒电子设备的外部处理器。本发明实施例提供的技术方案中,通过对解码数据进行预处理和特征提取处理,生成语音特征;根据获取的隐马尔可夫模型对语音特征进行模式匹配,生成识别结果并根据识别结果唤醒电子设备的外部处理器,实现了语音唤醒功能,在降低电子设备功耗的同时,提高语音唤醒的准确性。
技术研发人员:郑梓涛,姜敏,陶洪焰
受保护的技术使用者:瑞声声学科技(深圳)有限公司
技术研发日:
技术公布日:2024/3/4
- 还没有人留言评论。精彩留言会获得点赞!