语音合成方法、装置、电子设备及可读存储介质
本发明涉及语音合成,尤其涉及一种语音合成方法、装置、电子设备及可读存储介质。
背景技术:
1、随着语音信号处理技术的发展,语音合成逐渐成为语音信号处理领域的重要研究分支,其中,最常见的语音合成的技术手段为基于tts(text to speech,从文本到语音)对语音进行合成,从文本到语音合成是一个典型的多模态生成任务,这一任务将给定的文本输入序列转化为具有不同说话者身份、情绪、风格的语音输出。
2、目前,主流的文本到语音合成系统主要文本前端、声学模型以及声码器三个部分组成,通过文本到语音合成系统可以实现对目标说话人的语音波形的构建。
3、然而,如何解决现有语音合成方法的合成效率低下,且合成质量不高的问题,是语音合成技术领域亟待解决的重要课题。
技术实现思路
1、本发明提供一种语音合成方法、装置、电子设备及可读存储介质,用以克服现有语音合成方法的合成效率低下,且合成质量不高的缺陷,实现语音信号的快速、精确合成。
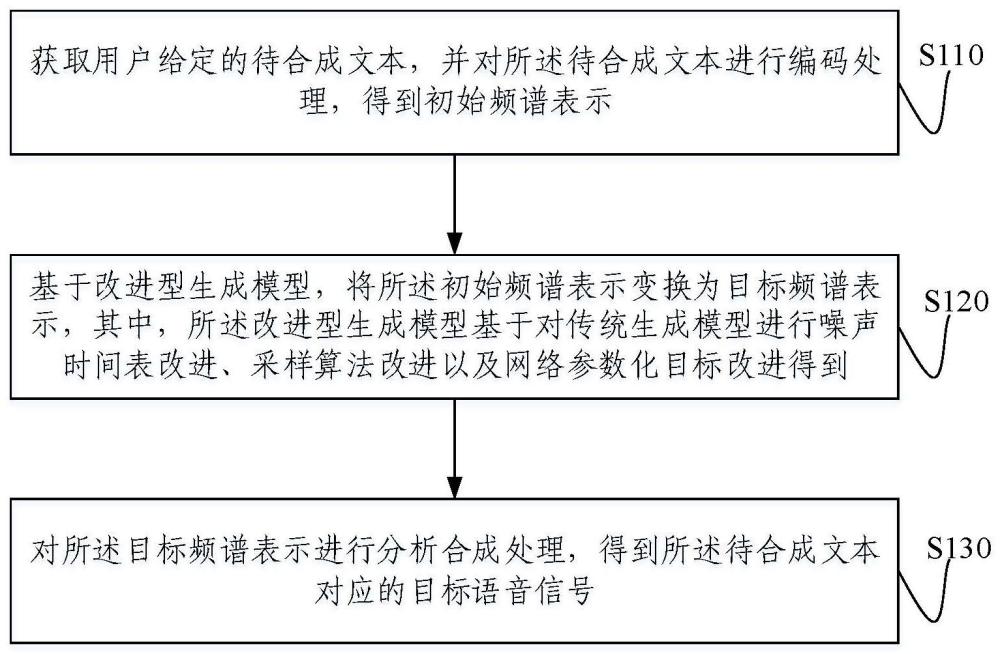
2、一方面,本发明提供一种语音合成方法,包括:获取用户给定的待合成文本,并对所述待合成文本进行编码处理,得到初始频谱表示;基于改进型生成模型,将所述初始频谱表示变换为目标频谱表示;对所述目标频谱表示进行分析合成处理,得到所述待合成文本对应的目标语音信号;其中,所述改进型生成模型基于对传统生成模型进行噪声时间表改进、采样算法改进以及网络参数化目标改进得到。
3、进一步地,所述改进型生成模型为改进型正向反向随机微分方程,所述改进型正向反向随机微分方程以所述初始频谱表示为输入,以所述目标频谱表示为输出。
4、进一步地,所述基于改进型生成模型,将所述初始频谱表示变换为目标频谱表示,包括:根据扩展的非对称噪声时间表和方差保留噪声时间表,计算所述改进型正向反向随机微分方程中的漂移系数和扩散系数;基于所述漂移系数和扩散系数,根据改进型采样算法计算得到所述目标语音信号。
5、进一步地,所述非对称噪声时间表与所述方差保留噪声时间表均为线性函数,其中,所述非对称噪声时间表的表达式如下:
6、
7、所述方差保留噪声时间表的表达式如下:
8、g2(t)=β0+t(β1-β0)
9、其中,β0为噪声时间表的下界超参数,t为[0,1]之间的时刻,β1为噪声时间表的上界超参数。
10、进一步地,所述基于所述漂移系数和扩散系数,根据改进型采样算法计算得到所述目标语音信号,包括:对所述改进型正向反向随机微分方程进行一阶离散化处理,得到一阶随机微分方程采样器;利用所述一阶随机微分方程采样器进行采样时引入温度变量,得到目标随机微分方程采样器;根据所述目标随机微分方程采样器,计算得到所述目标语音信号。
11、进一步地,所述目标随机微分方程采样器表示如下:
12、
13、其中,αt为t时刻的漂移项导出变量,为t时刻的漂移-扩散项导出变量,αs为s时刻的漂移项导出变量,为s时刻的漂移-扩散项导出变量,xs为在s时刻的采样点,xθ(xs,s)为生成模型在s时刻对于真实频谱表示的预测,∈为高斯噪声,为温度变量,i为与单位矩阵。
14、第二方面,本发明还提供一种语音合成装置,包括:初始频谱表示获取模块,用于获取用户给定的待合成文本,并对所述待合成文本进行编码处理,得到初始频谱表示;目标频谱表示生成模块,用于基于改进型生成模型,将所述初始频谱表示变换为目标频谱表示;目标语音信号合成模块,用于对所述目标频谱表示进行分析合成处理,得到所述待合成文本对应的目标语音信号;其中,所述改进型生成模型基于对传统生成模型进行噪声时间表改进、采样算法改进以及网络参数化目标改进得到。
15、第三方面,本发明还提供一种电子设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现如上述任一种所述的语音合成方法。
16、第四方面,本发明还提供一种非暂态计算机可读存储介质,其上存储有计算机程序,该计算机程序被处理器执行时实现如上述任一种所述的语音合成方法。
17、第五方面,本发明还提供一种计算机程序产品,包括计算机程序,所述计算机程序被处理器执行时实现如上述任一种所述的语音合成方法。
18、本发明提供的一种语音合成方法,通过获取用户给定的待合成文本,并对待合成文本进行编码处理,得到初始频谱表示,进而基于改进型生成模型,将初始频谱表示变换为目标频谱表示,从而,对目标频谱表示进行分析合成处理,得到待合成文本对应的目标语音信号;其中,改进型生成模型基于对传统生成模型进行噪声时间表改进、采样算法改进以及网络参数化目标改进得到。该方法通过改进型生成模型对粗略的频谱表示进行变换,克服了现有语音合成方法的合成效率低下且合成质量不高的缺陷,极大地提升了合成语音信号的质量,还有效提升了语音信号的合成效率。
技术特征:
1.一种语音合成方法,其特征在于,包括:
2.根据权利要求1所述的语音合成方法,其特征在于,所述改进型生成模型为改进型正向反向随机微分方程,所述改进型正向反向随机微分方程以所述初始频谱表示为输入,以所述目标频谱表示为输出。
3.根据权利要求2所述的语音合成方法,其特征在于,所述基于改进型生成模型,将所述初始频谱表示变换为目标频谱表示,包括:
4.根据权利要求3所述的语音合成方法,其特征在于,所述非对称噪声时间表与所述方差保留噪声时间表均为线性函数,其中,
5.根据权利要求3所述的语音合成方法,其特征在于,所述基于所述漂移系数和扩散系数,根据改进型采样算法计算得到所述目标语音信号,包括:
6.根据权利要求5所述的语音合成方法,其特征在于,所述目标随机微分方程采样器表示如下:
7.一种语音合成装置,其特征在于,包括:
8.一种电子设备,包括存储器、处理器及存储在所述存储器上并可在所述处理器上运行的计算机程序,其特征在于,所述处理器执行所述程序时实现如权利要求1至6中任一项所述的语音合成方法。
9.一种非暂态计算机可读存储介质,其上存储有计算机程序,其特征在于,所述计算机程序被处理器执行时实现如权利要求1至6中任一项所述的语音合成方法。
10.一种计算机程序产品,包括计算机程序,其特征在于,所述计算机程序被处理器执行时实现如权利要求1至6中任一项所述的语音合成方法。
技术总结
本发明提供一种语音合成方法、装置、电子设备及可读存储介质,其中的方法包括:获取用户给定的待合成文本,并对待合成文本进行编码处理,得到初始频谱表示;基于改进型生成模型,将初始频谱表示变换为目标频谱表示;对目标频谱表示进行分析合成处理,得到待合成文本对应的目标语音信号;其中,改进型生成模型基于对传统生成模型进行噪声时间表改进、采样算法改进以及网络参数化目标改进得到。该方法通过改进型生成模型对粗略的频谱表示进行变换,克服了现有语音合成方法的合成效率低下且合成质量不高的缺陷,极大地提升了合成语音信号的质量,还有效提升了语音信号的合成效率。
技术研发人员:朱军,何冠德,郑凯文
受保护的技术使用者:清华大学
技术研发日:
技术公布日:2024/4/17
- 还没有人留言评论。精彩留言会获得点赞!