基于时频特征分离式transformer交叉融合架构的语音情感识别方法
本发明涉及一种基于时频特征分离式transformer交叉融合架构的语音情感识别方法,属于情感计算。
背景技术:
1、语音情感识别是指从语音信号中自动分析和识别出说话人的情感状态。它是语音识别、自然语言处理、情感计算等领域交叉的研究方向。随着社交媒体、智能语音助手、人机交互等领域的快速发展,语音情感识别越来越受到关注。
2、传统的语音情感识别方法主要是基于信号处理和分类器的结合,使用手工提取的音频特征,如mfcc、lpc等,并使用分类器,如支持向量机(svm)、高斯混合模型(gmm)等来识别情感状态。但是,这些方法依赖于手工特征提取和分类器选择,需要专业知识和经验,效果不稳定。
3、近年来,深度学习技术的发展使得语音情感识别取得了更好的效果。常用的深度学习模型包括卷积神经网络(cnn)、长短时记忆网络(lstm)、自编码器(ae)等。此外,注意力机制和transformer等模型也在语音情感识别中被广泛应用。
4、现有的语音情感识别研究主要面临以下问题:(1)数据不足和样本不平衡问题;(2)情感状态的定义和分类问题;(3)情感状态的多样性问题;(4)实时性和效率问题。这些问题需要进一步研究和解决。
5、transformer模型是一种深度神经网络,最初用于自然语言处理领域中的翻译任务。它的核心是self-attention机制,即在输入序列的所有位置上计算注意力向量,使得每个位置都能够获得输入序列中其他位置的信息,从而更好地理解整个序列的语义。这使得transformer模型在处理长序列时表现优秀,并成为自然语言处理领域中的重要模型。
6、近年来,transformer模型被引入到语音识别领域。其中,基于transformer模型的语音情感识别方法利用其在序列建模和长距离依赖建模方面的优势,从而在语音情感识别任务上取得了不错的效果。该方法通常首先利用声学特征提取器将语音信号转换为特征序列,然后使用transformer模型进行情感分类。在transformer模型中,每个时间步的输入特征向量通过self-attention机制进行编码,并利用位置编码加入时间步的信息。然后通过多层feed-forward网络进行分类预测。
7、扩张因果卷积属于cnn网络,因果卷积可以保留那些从前往后的神经元链接,这样就使得网络满足了时间上的前后依赖原则;扩张卷积可以扩大感受野,让每个卷积输出都包含较大范围的信息。由于因果卷积每一层的输出都是由前一层对应未知的输入及其前一个位置的输入共同得到,并且如果输出层和输入层之前有很多的隐藏层,那么一个输出对应的所有输入就越多,且输入和输出离得越远,就需要考虑越早之前的输入变量参与运算,这样会增加卷积的层数,而卷积层数的增加就带来:梯度消失,训练复杂,拟合效果不好的问题,因此扩张卷积就解决了这个问题:扩张卷积是通过跳过部分输入来使filter可以应用于大于filter本身长度的区域。等同于通过增加零来从原始filter中生成更大的filter。使用扩展卷积,就可以解决因果卷积带来的问题,扩张卷积可以使模型在层数不大的情况下有非常大的感受野。
8、该方法的优点在于,它将基于时频特征分离式transformer交叉融合架构和扩张因果卷积的建模方法引入语音情感识别,并能够对长序列进行有效建模,从而在语音情感识别任务上取得了不错的效果。然而,该方法的缺点在于需要大量的计算资源和数据进行训练,并且需要进行超参数调优。
9、有鉴于此,确有必要提出一种基于时频特征分离式transformer交叉融合架构的语音情感识别方法,以解决上述问题。
技术实现思路
1、本发明目的在于提出一种基于时频特征分离式transformer交叉融合架构的语音情感识别方法,对现有深度神经网络进行部分改造和结合,提高计算机识别人类语音情感的正确率。
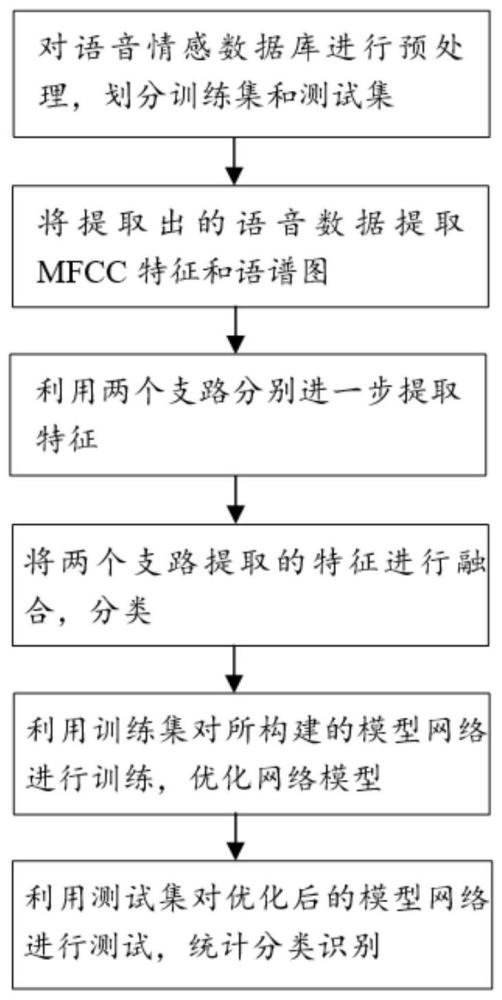
2、为实现上述目的,本发明提供了一种基于时频特征分离式transformer交叉融合架构的语音情感识别方法,包括如下步骤:
3、s1、对原始语音信号进行预处理,将所述原始语音信号转换为相应的特征表示,包括语谱图和音频梅尔频率倒谱系数;
4、s2、从所述特征表示中进行特征提取,使用两条支路提取特征,其中一条支路通过时频分离式transformer交叉融合架构提取特征,另一条支路通过扩张因果卷积网络提取特征;
5、s3、进行特征融合,使用transformer的多头自注意力机制来动态地融合时频分离式transformer交叉融合架构和扩张因果卷积输出特征;
6、s4、输出结果,使用输出层来对时频分离式transformer交叉融合架构的输出进行分类或回归,以使时频分离式transformer交叉融合架构适应训练数据,并对任务进行预测或分类。
7、作为本发明的进一步改进,所述步骤s2中的一条支路使用所述时频分离式transformer交叉融合架构来提取特征具体包括以下步骤:
8、s21、使用水平方向的transformer和垂直方向的transformer来分别提取时域和频域的特征,之后再将两个transformer的query矩阵交换,与原先的两路输出形成共四路不同的自注意力输出,并进行concat拼接;
9、s22、将时域上的投影标记分离为数据子样本,其可表示为t:,j=[t1,j,t2,j,…,tk,j]∈rk×d,从而得到一批n个数据样本,其中每个数据样本由k个token组成;同时,将类令牌t[cls]∈rk×d复制n次,并对每个数据样本t:,j添加一个副本,每个标记都添加一个可学习的位置嵌入;
10、s23、将频域上的投影标记分离为数据子样本,其可表示为从而得到一批n个数据样本,其中每个数据样本由i个token组成;同时,对于垂直transformer,复制类令牌k次,并为每个数据样本添加一个副本。
11、作为本发明的进一步改进,所述步骤s2还包括以下步骤:
12、s24、分离式交叉融合transformer模块,在水平方向的transformer和垂直方向的transformer内部执行的操作包括:设为x∈rm×d,表示m个令牌的序列,即t:,j或其中m∈{k,n},d是每个令牌的嵌入维数,设f为多头注意层,g为多层感知器,范数为归一化层,p,r∈rm×d为辅助张量;
13、所述transformer模块的表达形式如下:
14、p=f(norm(x))+x;
15、r=g(norm(p))+p;
16、所述transformer模块配置为根据全局上下文信息对每个实体进行编码来捕获所有m个实体之间的交互,通过多头注意力层f实现该目的;所述多头注意力层f用于从输入序列x中推导出q,k,v的值,所述多头注意力层f包括三个可学习的权重矩阵其中dq=dqk;输入序列x首先投射到所述权重矩阵后可以分别得到:
17、q=x·wq,k=x·wk,v=x·wv;
18、自注意力的输出表达为以下公式:
19、
20、其中k`是k的转置,则通过水平transformer得到的三个可学习的权重矩阵分别记为q1,k1,v1,通过垂直transformer得到的三个可学习的权重矩阵分别记为q2,k2,v2;此时,由于query矩阵是用于计算当前位置语音与其他非当前位置语音的关联度,可以交换两个transformer得到query矩阵,即得到q2,k1,v1和q1,k2,v2;即可得到四个自注意力的输出:z1,z2,z3,z4,分别为:
21、
22、
23、
24、
25、将四个所述自注意力的输出z1,z2,z3,z4使用concat拼接特征,得到总的输出z=concat(z1,z2,z3,z4)。
26、作为本发明的进一步改进,所述步骤s2中一条支路使用分离式transformer架构并加入随机掩码模块,具体包括:
27、s25、在语音频谱transformer的预训练中,使用固定长度的10s音频,并将其转换为大小为1024×128的频谱图,所述语音频谱transformer将频谱图分成512个16×16patch,其中8个在频率维度,64个在时间维度;所述语音频谱transformer配置为在预训练期间对单个的频谱图patch添加掩码,以使所述时频分离式transformer交叉融合架构学习输入数据的时间和频率结构;其中,在水平方向的transformer中随机添加垂直方向的条状掩码,以增强所述时频分离式transformer交叉融合架构学习频率特征,在垂直方向的transformer中随机添加水平方向的条状掩码,以增强所述时频分离式transformer交叉融合架构学习时间特征。
28、作为本发明的进一步改进,所述步骤s2中的一条支路使用扩张因果卷积网络与lstm网络并联来提取有用的特征,具体包括:将输入的语音片段提取出所述音频梅尔频率倒谱系数的特征后,送入一个由扩张因果卷积网络与lstm网络并联形成的网络;所述扩张因果卷积网络属于cnn网络,其中,因果卷积用以保留从前往后的神经元链接,以使网络满足时间上的前后依赖原则;扩张卷积用以扩大感受;使用所述因果卷积,将对序列问题抽象为:根据x1,x2…,xt和y1,y2…,yt-1去预测yt,使得yt接近于实际值,其公式为:
29、
30、作为本发明的进一步改进,所述lstm网络是一种特殊的循环神经网络,所述lstm网络中包括输入门、遗忘门和输出门,lstm网络配置为处理长序列,以避免训练过程中的梯度消失和梯度爆炸问题,实现对长序列的建模;所述lstm网络中的每个神经元都有一个状态向量和一个输出向量,状态向量用于存储过去的信息,输出向量用于输出当前的信息,在每个时间步,lstm网络会根据当前的输入和前一个时间步的状态向量,计算出所述输入门、遗忘门和输出门的输出,并根据所述输入门、遗忘门和输出门的输出来更新状态向量和输出向量,其中,所述输入门用于控制当前输入的重要性,所述遗忘门用于控制过去状态的重要性,所述输出门用于控制当前输出的重要性。
31、本发明的有益效果是包括:分离式transformer中,利用水平和垂直两个方向的transformer分别提取时域和频域的特征,再交换query矩阵获得交叉融合特征,获得比基于传统特征学习的方法更好的情感识别效果,显著降低了计算量。同时,因果卷积可以保留那些从前往后的神经元链接,这样就使得网络满足了时间上的前后依赖原则;扩张卷积可以扩大感受野,让每个卷积输出都包含较大范围的信息。
- 还没有人留言评论。精彩留言会获得点赞!