一种用于传声器的声音信号优化传输方法与流程
本发明涉及数据处理,具体涉及一种用于传声器的声音信号优化传输方法。
背景技术:
1、由于传声器的声音信号往往会受到外界环境的影响产生噪声,使得传声器的声音信号的质量下降,而为了提高声音信号的质量,则需要去除声音信号中的噪声信号。传统的对声音信号进行去噪的方法为小波阈值去噪;但是由于在实际情况中会存在多人同时说话的情况,会导致多个频率的信号相互叠加,导致模态混乱,使固定阈值的小波阈值去噪无法对多人同时说话时的声音信号进行取值无法的到良好的去噪效果。
技术实现思路
1、本发明提供一种用于传声器的声音信号优化传输方法,以解决现有的问题:传统的固定阈值的小波阈值去噪,无法对多人同时说话时的声音信号进行取值无法的到良好的去噪效果。
2、本发明的一种用于传声器的声音信号优化传输方法采用如下技术方案:
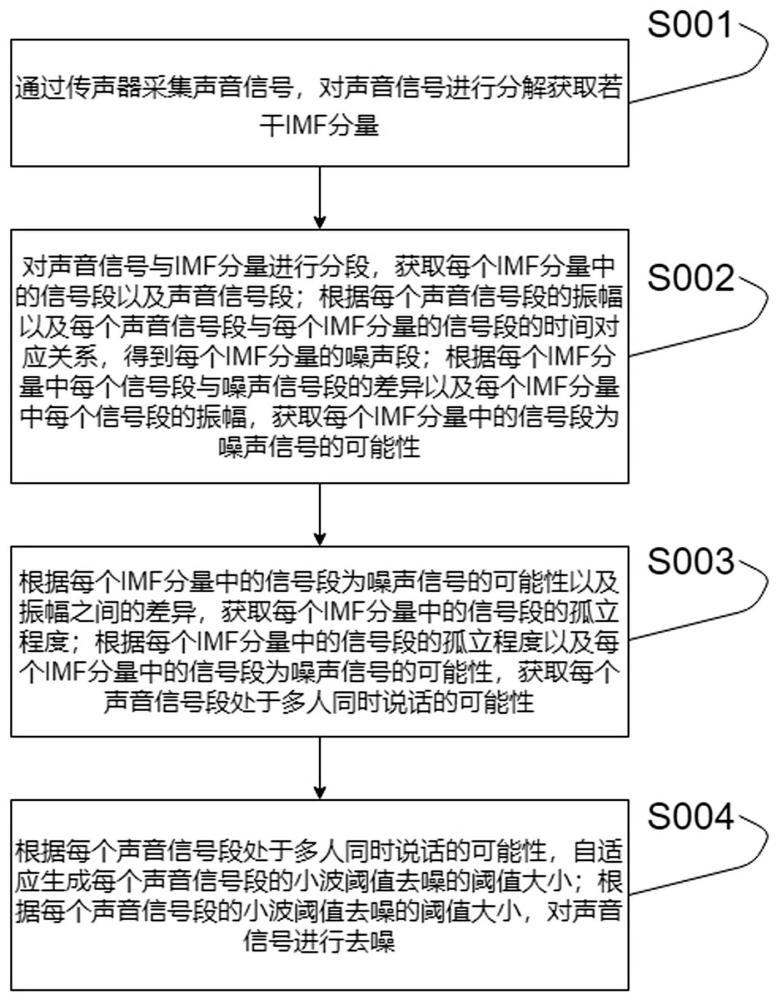
3、包括以下步骤:
4、通过传声器采集声音信号,对声音信号进行分解获取若干imf分量;
5、对声音信号与imf分量进行分段,获取每个imf分量中的信号段以及声音信号段;根据每个声音信号段的振幅以及每个声音信号段与每个imf分量的信号段的时间对应关系,得到每个imf分量的噪声段;根据每个imf分量中每个信号段与噪声信号段的差异以及每个imf分量中每个信号段的振幅,获取每个imf分量中的信号段为噪声信号的可能性;
6、根据每个imf分量中的信号段为噪声信号的可能性以及振幅之间的差异,获取每个imf分量中的信号段的孤立程度;根据每个imf分量中的信号段的孤立程度以及每个imf分量中的信号段为噪声信号的可能性,获取每个声音信号段处于多人同时说话的可能性;
7、根据每个声音信号段处于多人同时说话的可能性,自适应生成每个声音信号段的小波阈值去噪的阈值大小;根据每个声音信号段的小波阈值去噪的阈值大小,对声音信号进行去噪。
8、优选的,所述通过传声器采集声音信号,对声音信号进行分解获取若干imf分量,包括的具体方法为:
9、通过传声器采集声音信号,然后使用emd算法对声音信号分解,得到若干imf分量。
10、优选的,所述对声音信号与imf分量进行分段,获取每个imf分量中的信号段以及声音信号段,包括的具体方法为:
11、预设一个分段阈值,将每个imf分量信号以及声音信号分割成若干段长度为的信号段,得到每个imf分量中的信号段以及声音信号段,完成对每个imf分量的分段以及声音信号的分段。
12、优选的,所述根据每个声音信号段的振幅以及每个声音信号段与每个imf分量的信号段的时间对应关系,得到每个imf分量的噪声段,包括的具体方法为:
13、计算每个声音信号段中所有振幅均值,将振幅均值最小的声音信号段记为噪声信号段,将噪声信号段所对应的时间段记为噪声时间段,并将每个imf分量在噪声时间段下的imf分量信号段,记为每个imf分量的噪声段。
14、优选的,所述根据每个imf分量中每个信号段与噪声信号段的差异以及每个imf分量中每个信号段的振幅,获取每个imf分量中的信号段为噪声信号的可能性,包括的具体方法为:
15、对于第个imf分量中第个信号段,首先获取第个imf分量中第个信号段中所有振幅的方差与均值,结合第个imf分量的噪声段中所有振幅均值,获取第个imf分量中第个信号段为噪声信号的可能性,其具体的计算公式为:
16、;
17、式中,表示第个imf分量中第个信号段为噪声信号的可能性;表示第个imf分量中第个信号段中所有振幅的方差;表示第个imf分量中第个信号段中所有振幅的均值;表示第个imf分量的噪声段中所有振幅均值;表示线性归一化函数;表示绝对值运算。
18、优选的,所述根据每个imf分量中的信号段为噪声信号的可能性以及振幅之间的差异,获取每个imf分量中的信号段的孤立程度,包括的具体方法为:
19、对于计算第个imf分量中第个信号段的孤立程度,首先获取每个imf分量中第个信号段中所有振幅的均值,以及每个imf分量中第个信号段为噪声信号的可能性,根据每个imf分量中第个信号段中所有振幅的均值,以及每个imf分量中第个信号段为噪声信号的可能性,获取第个imf分量中第个信号段的孤立程度。
20、优选的,所述获取第个imf分量中第个信号段的孤立程度,包括的具体计算公式为:
21、;
22、式中,表示第个imf分量中第个信号段的孤立程度;表示imf分量的数量;表示第个imf分量中第个信号段中所有振幅的均值;表示第个imf分量中第个信号段中所有振幅的均值;表示第个imf分量中第个信号段为噪声信号的可能性;表示第个imf分量中第个信号段为噪声信号的可能性;表示线性归一化函数;表示绝对值运算。
23、优选的,所述根据每个imf分量中的信号段的孤立程度以及每个imf分量中的信号段为噪声信号的可能性,获取每个声音信号段处于多人同时说话的可能性,包括的具体方法为:
24、对于计算第个声音信号段处于多人同时说话的可能性;根据所有imf分量中第个信号段的孤立程度,以及所有imf分量中第个信号段为噪声信号的可能性,获取第个声音信号段处于多人同时说话的可能性,其具体的计算公式为:
25、;
26、式中,表示第个声音信号段处于多人同时说话的可能性;表示所有imf分量的第个信号段中的孤立程度最大值;表示所有imf分量的第个信号段中的孤立程度最小值;表示所有imf分量的第个信号段中的孤立程度次大值;表示所有imf分量的第个信号段中的为噪声信号的可能性最大值;表示线性归一化函数。
27、优选的,所述根据每个声音信号段处于多人同时说话的可能性,自适应生成每个声音信号段的小波阈值去噪的阈值大小,包括的具体方法为:
28、对于自适应生成第个声音信号段的小波阈值去噪的阈值,首先预设一个初始小波阈值;再根据所有imf分量中第个信号段的孤立程度,以及每个声音信号段处于多人同时说话的可能性,自适应生成第个声音信号段的小波阈值去噪的阈值,其具体的计算公式为:
29、;
30、式中,表示第个声音信号段的小波阈值去噪的阈值;表示所有imf分量中第个信号段中的孤立程度最大值;表示第个声音信号段处于多人同时说话的可能性;表示线性归一化函数。
31、优选的,所述根据每个声音信号段的小波阈值去噪的阈值大小,对声音信号进行去噪,包括的具体方法为:
32、根据每个声音信号段的小波阈值去噪的阈值大小,对每个声音信号段进行小波阈值去噪处理,完成对声音信号进行去噪。
33、本发明的技术方案的有益效果是:本发明通过对声音信号进行分解与分段,得到每个imf分量信号段与声音信号段,通过对多人同时说话时的声音信号所具有的特征进行分析,得到每个声音信号段处于多人同时说话的可能性,以此为依据自适应生成小波阈值去噪的阈值,避免了在对声音信号进行去噪时,丢失人说话时的信号特征,达到提高声音信号质量的目的。
- 还没有人留言评论。精彩留言会获得点赞!