一种智能多维音频分析与合成系统
本发明属于音频分析与合成,特别是涉及一种智能多维音频分析与合成系统。
背景技术:
1、随着科技的发展,音频处理技术在众多领域得到了广泛应用,在音频分析与合成技术领域中,存在以下几种技术,但它们都具有一定的局限性:
2、一、传统音频分析工具:这些工具通常基于频谱分析,能够提供音高、节奏、强度等基本音频特征的可视化。然而,它们往往缺乏对音频信号更深层次、多维度的分析能力,如情感色彩、风格特征等。
3、二、标准音频合成软件:这些软件依赖预设的音频库和合成器,通过调整参数来生成音效。然而,这些工具在创造独特和复杂的声音方面受限,通常不能根据复杂的音频分析结果来动态生成音效。
4、三、机器学习在音频处理中的应用:一些先进的系统开始应用机器学习,特别是深度学习技术,进行音频分类和识别。然而,虽然这些系统在音频识别方面取得了进展,但在音频的多维分析和基于这些分析的音频合成方面仍有发展空间。
5、四、实时音频处理技术:这种技术能够立即响应音频输入,用于现场表演和互动媒体。然而,在多维分析和复杂的音频合成方面,实时处理技术往往受到处理能力和算法复杂度的限制。
6、综上所述,现有的音频分析与合成技术在多维度分析、复杂音频合成以及将深入分析与创造性音频生成结合方面仍有提升空间。因此,本发明旨在填补这些空白,提供更全面、智能且创新的音频处理能力。
技术实现思路
1、本发明主要解决的技术问题是提供一种智能多维音频分析与合成系统,能够完成对音频的多维度分析、复杂音频的合成,以及深入分析与创新性音频生成的功能。
2、为解决上述技术问题,本发明采用的一个技术方案是:
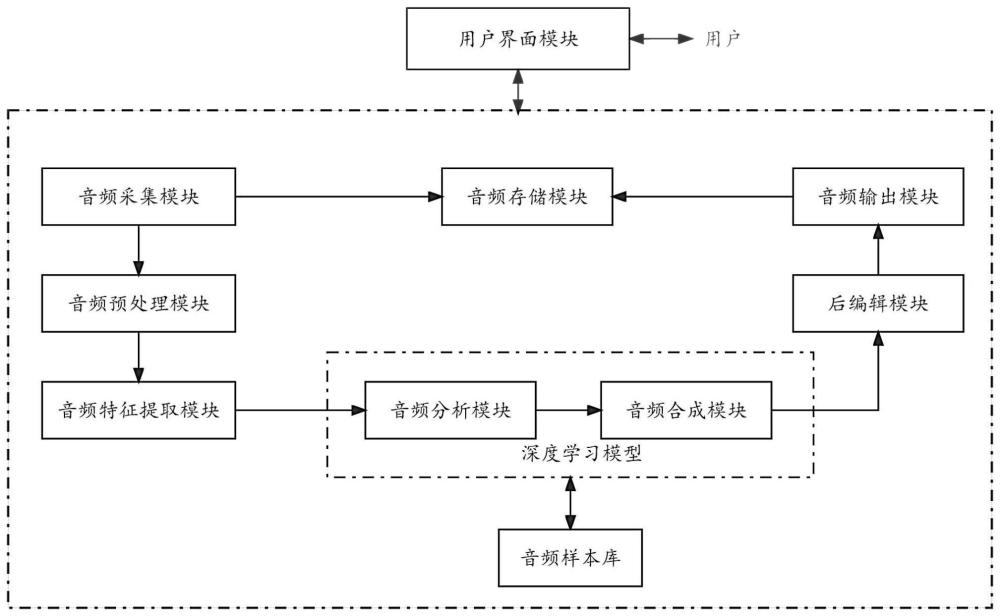
3、一种智能多维音频分析与合成系统,包括:
4、音频采集模块,用于采集音频信号;该模块用于采集音频信号,可以采用麦克风、录音设备等音频输入设备。
5、音频预处理模块,用于对采集的音频信号进行预处理,所述预处理包括去噪、滤波和增益;以消除环境噪声和其他干扰信号,提高音频质量。
6、音频特征提取模块,用于提取音频信号的特征信息,所述特征信息包括频域特征、时域特征和声学特征;以便后续的音频分析和合成。
7、音频分析模块,利用深度学习模型对提取的特征信息进行多维特征分析,多维特征分析包括语音识别、情感分析和语义分析;以实现对音频信号的深入理解和分析。
8、音频合成模块,根据深度学习模型的分析结果生成合成音频信号,包括语音合成、音乐合成和环境音效合成;
9、音频输出模块,用于输出合成音频信号;可以采用扬声器、耳机等音频输出设备。
10、音频存储模块,用于存储采集的音频信号和合成的音频信号;以便后续的回放和分析。
11、用户界面模块,用于显示音频分析与合成系统的状态和结果,并提供用户交互接口。使用户能够方便地操作音频分析和合成系统。
12、进一步的是,所述音频预处理模块包括:
13、噪声去除模块,采用自适应滤波算法和基于深度学习的噪声识别与分离算法相结合的用噪声去除算法,对输入的音频数据进行噪声过滤,以消除环境噪声和其他干扰信号;
14、音频信号增强模块,通过音频增强技术,对输入的音频信号进行增强处理;
15、音频格式转换模块,用于将输入的音频数据转换成目标格式。
16、进一步的是,所述音频特征提取模块包括:
17、频域特征提取模块,用于提取音频信号的频域特征,频域特征包括梅尔频率倒谱系数和线性预测倒谱系数;
18、时域特征提取模块,用于提取音频信号的时域特征,时域特征包括短时能量和过零率;
19、时频域特征提取模块,用于提取音频信号的时频域特征,时频域特征包括小波变换系数和连续小波变换系数;
20、声调特征提取模块,用于提取音频信号的声调特征,声调特征包括基频和共振峰;
21、语速特征提取模块,用于提取音频信号的语速特征,语速特征包括音节数和音节时长;
22、韵律特征提取模块,用于提取音频信号的韵律特征,韵律特征包括音高、音长和音强。
23、进一步的是,所述音频分析模块包括:
24、语音识别模块,用于将音频信号转换为文本信息,文本信息包括语音内容;
25、情感分析模块,用于分析音频信号中的情感信息,情感信息包括喜悦、愤怒、悲伤、惊讶和恐惧。
26、语义分析模块,用于分析音频信号中的语义信息,语义信息包括主题、话题和事件;
27、说话人识别模块,用于识别音频信号中的说话人身份。
28、进一步的是,所述音频合成模块包括:
29、语音合成模块,用于将文本信息转换为语音信号;
30、音乐合成模块,用于根据音乐信息生成合成音乐信号;
31、情感合成模块,用于根据情感信息合成具有相应情感的语音信号;
32、环境音效合成模块,用于根据环境音效信息生成合成环境音效信号;
33、说话人合成模块,用于根据说话人身份合成具有相应说话人特征的语音信号。
34、进一步的是,所述音频存储模块包括:
35、音频信号存储模块,用于存储采集的音频信号;
36、合成音频信号存储模块,用于存储合成的音频信号。
37、进一步的是,用户界面模块包括:
38、显示模块,用于显示音频分析与合成系统的状态和结果;
39、交互接口模块,用于提供用户交互接口。
40、进一步的是,所述深度学习模型为卷积神经网络、循环神经网络或长短期记忆网络中的任一种。
41、进一步的是,所述系统还包括后编辑模块,用于用户对音频合成模块合成后的音频信息进行效果处理,所述效果处理包括声音的强度调整、音调调整和音色调整,以及混响处理和回声处理。
42、进一步的是,所述系统还包括音频样本库,用于提供深度学习模型音频样本数据训练和改进音频分析和合成算法。
43、本发明的有益技术效果是:
44、通过将深度学习技术应用于音频处理,实现了音频信号的多维特征分析,涵盖语音识别、情感分析、语义分析等领域。同时,根据深度学习模型的分析结果,生成合成音频信号,包括语音合成、音乐合成、环境音效合成等。本发明还采用了音频预处理模块,对采集的音频信号进行去噪、滤波和增益等预处理,并通过音频存储模块存储采集和合成的音频信号,从而提升音频质量和存储效率。此外,本发明通过用户界面模块提供用户交互接口,便于用户操作音频分析和合成系统。
45、另外,本发明的深度学习模型可以采用卷积神经网络、循环神经网络或长短期记忆网络中的任一种,实现对音频信号的深度学习和特征提取。同时,该系统还可配备后编辑模块和音频样本库,以便对音频合成结果进行调整和改进。
46、总之,本发明将深度学习技术应用于音频处理,实现了音频信号的多维特征分析和合成,提升了音频质量和存储效率,同时简化了音频分析和合成系统的操作。
- 还没有人留言评论。精彩留言会获得点赞!