基于移动设备内置传感器的语音感知方法、系统及终端
本发明涉及信号处理,特别是涉及一种基于移动设备内置传感器的语音感知方法、系统及终端。
背景技术:
1、智能手机已经渗透到我们的日常生活中,成为不可或缺的通信接口。在所有不同的通信方式中,语音通信总是被认为是首选之一。
2、由于语音信息的特性,麦克风通常受到智能手机操作系统的严格权限管理,并且需要用户同意才能够访问。现有的研究和技术主要集中在如何通过利用通信协议的漏洞或通过植入系统后门来访问和使用麦克风来获得用户的通话、交流等语音内容。
3、现有的一些研究工作实现了初步的基于传感器的语音语义感知能力,但系统性能较弱,主要关注数字、关键词等,缺乏对连续信息的捕捉能力。
技术实现思路
1、鉴于以上所述现有技术的缺点,本发明的目的在于提供一种基于移动设备内置传感器的语音感知方法、系统及终端,用于解决现有技术中以上技术问题。
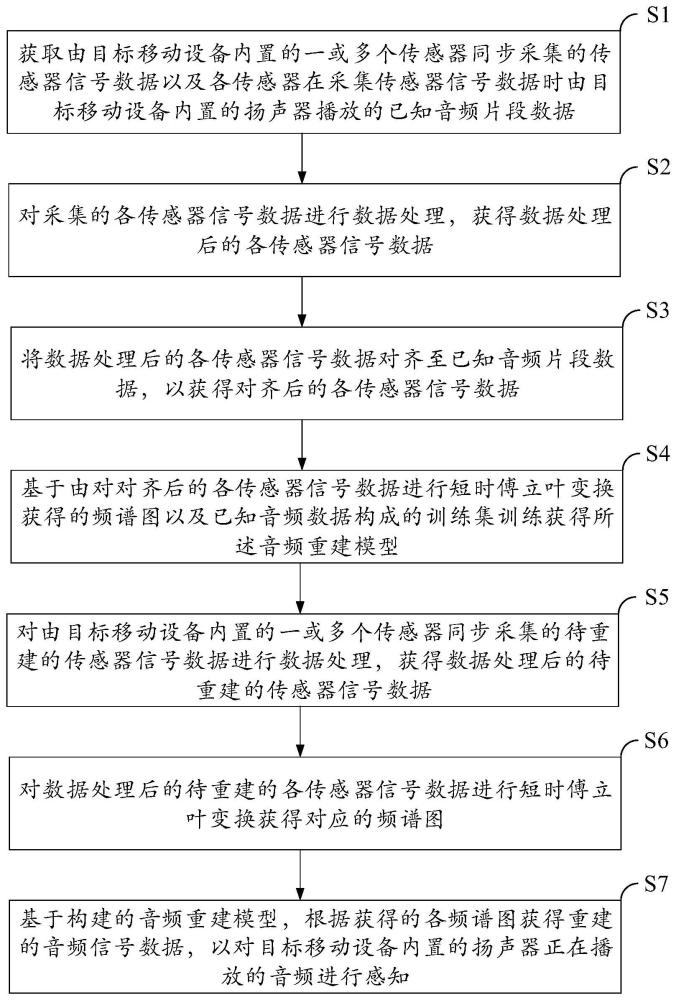
2、为实现上述目的及其他相关目的,本发明提供一种基于移动设备内置传感器的语音感知方法,所述方法包括:对由目标移动设备内置的一或多个传感器同步采集的待重建的传感器信号数据进行数据处理,获得数据处理后的待重建的传感器信号数据;对数据处理后的待重建的各传感器信号数据进行短时傅立叶变换获得对应的频谱图;基于构建的音频重建模型,根据获得的各频谱图获得重建的音频信号数据,以对目标移动设备内置的扬声器正在播放的音频进行感知;其中,构建音频重建模型的方式包括:获取由目标移动设备内置的一或多个传感器同步采集的传感器信号数据以及各传感器在采集传感器信号数据时由目标移动设备内置的扬声器播放的已知音频片段数据;其中,传感器信号数据相较于已知音频片段数据向后偏移;对采集的各传感器信号数据进行数据处理,获得数据处理后的各传感器信号数据;将数据处理后的各传感器信号数据对齐至已知音频片段数据,以获得对齐后的各传感器信号数据;基于由对对齐后的各传感器信号数据进行短时傅立叶变换获得的频谱图以及已知音频数据构成的训练集训练获得所述音频重建模型。
3、于本发明的一实施例中,由目标移动设备内置的加速度计、陀螺仪以及磁力计同步采集加速度计x轴、y轴、z轴数据与每个采样点对应的时间戳信息、陀螺仪x轴、y轴、z轴数据与每个采样点对应的时间戳信息以及由磁力计采集的磁力计x轴、y轴、z轴数据与每个采样点对应的时间戳信息。
4、于本发明的一实施例中,数据处理的方式包括:对采集的传感器信号数据进行线性插值获得稳定采样率的信号序列,并对信号序列通过高通滤波器滤除低频噪音。
5、于本发明的一实施例中,将数据处理后的传感器信号数据对齐至相对应的已知音频片段数据,以获得对齐后的传感器信号数据包括:基于数据处理后获得的加速度计x轴、y轴、z轴的信号序列计算加速度计x轴、y轴、z轴的信噪比;使用设定的滑动窗口获得数据处理后获得的加速度计x轴、y轴、z轴的信号序列各自的信号方差序列数据以及已知音频片段数据的方差序列数据;其中,所述信号方差序列数据包括:一次方差序列以及二次方差序列;将加速度计x轴、y轴、z轴的信号序列以及各自的信号方差序列数据与已知音频片段数据以及对应的信号方差序列数据以滑动窗口方式求余弦相似度,并基于加速度计x轴、y轴、z轴的信噪比计算在预设的需要被裁剪掉的采样点数量范围内的各采样点数量所对应的对齐评价分数;将对齐评价分数最高的采样点数量作为需裁剪的采样点数量对数据处理后获得的传感器信号数据进行裁剪。
6、于本发明的一实施例中,将加速度计x轴、y轴、z轴的信号序列以及各自的信号方差序列数据与已知音频片段数据以及对应的信号方差序列数据以滑动窗口方式求余弦相似度,并基于加速度计x轴、y轴、z轴的信噪比计算在预设的需要被裁剪掉的采样点数量范围内的各采样点数量所对应的对齐评价分数包括:使用滑动窗口将数据处理后获得的加速度计x轴、y轴、z轴的信号序列以及已知音频片段数据分别划分为相同数量的对齐窗口,在预设的需裁剪的采样点数量范围内对每一个对齐窗口计算对应每个采样点数量的余弦相似度,并根据加速度计x轴、y轴、z轴的信噪比作为权重加权计算所有对齐窗口的加权平均余弦相似度,获得对应每个采样点数量的序列对齐评价分数;使用滑动窗口将数据处理后获得的加速度计x轴、y轴、z轴各自的一次方差序列以及已知音频片段数据的一次方差序列分别划分为相同数量的对齐窗口,在预设的需裁剪的采样点数量范围内对每一个对齐窗口计算对应每个采样点数量的余弦相似度,并根据加速度计x轴、y轴、z轴的信噪比作为权重加权计算所有对齐窗口的加权平均余弦相似度,以获得对应每个采样点数量的一次方差序列对齐评价分数;使用滑动窗口将数据处理后获得的加速度计x轴、y轴、z轴各自的二次方差序列以及已知音频片段数据的二次方差序列分别划分为相同数量的对齐窗口,在预设的需裁剪的采样点数量范围内对每一个对齐窗口计算对应每个采样点数量的余弦相似度,并根据加速度计x轴、y轴、z轴的信噪比作为权重加权计算所有对齐窗口的加权平均余弦相似度,获得对应每个采样点数量的二次方差序列对齐评价分数;基于对应每个采样点数量的序列对齐评价分数、一次方差序列对齐评价分数以及二次方差序列对齐评价分数获得对应每个采样点数量最终的对齐评价分数。
7、于本发明的一实施例中,所述音频重建模型包括:多模态融合特征提取器以及声码器;其中,多模态融合特征提取器,用于对输入的加速度计x轴、y轴、z轴的频谱图、陀螺仪x轴、y轴、z轴的频谱图以及磁力计x轴、y轴、z轴的频谱图进行特征提取以及融合,输出单通道频谱图;所述声码器由在训练过程中互相对抗学习的生成器组件和鉴别器组件构成,用于根据输入的单通道频谱图输出重建的音频信号数据。
8、于本发明的一实施例中,所述多模态融合特征提取器包括:分别对应每个传感器模态的预卷积分支、特征维度拼合层以及整体卷积层;每个预卷积分支,用于对输入的对应传感器所对应的频谱图通过多层转置卷积进行升维,并输出对应传感器的特征矩阵;其中,每个预卷积分支由三层二维卷积层组成;特征维度拼合层,连接各预卷积分支,用于将输入的各传感器的特征矩阵整合为统一特征矩阵;其中,所述特征维度拼合层具有5个残差块,每个残差块由两个2d卷积层组成,且在每个卷积层之后应用实例归一化;整体卷积层,连接所述特征维度拼合层,用于对输入统一特征矩阵使用多个卷积层进行跨模态信息整合和特征提取获得单通道频谱图;其中,整体卷积层由三层上采样卷积层组成,且每层上采样卷积层由一个升采样层和一个二维卷积层构成。
9、于本发明的一实施例中,所述生成器组件包括:预卷积层、4个上采样模块以及卷积层;其中,每个上采样模块由一个转置卷积层和三个残差模块组成;所述鉴别器组件包括:3个鉴别器,用于在训练时分别对目标音频数据、两倍降采样的目标音频数据以及四倍降采样的目标音频数据进行操作,以供获得用于生成器组件和鉴别器组件之间的对抗性训练的输出结果;其中目标音频数据包括:由生成器组件输出的音频数据以及输入的已知音频片段数据。
10、为实现上述目的及其他相关目的,本发明提供一种基于移动设备内置传感器的语音感知系统,所述系统包括:数据处理模块,用于对由目标移动设备内置的一或多个传感器同步采集的待重建的传感器信号数据进行数据处理,获得数据处理后的待重建的传感器信号数据;
11、频谱获取模块,连接所述数据处理模块,用于对数据处理后的待重建的各传感器信号数据进行短时傅立叶变换获得对应的频谱图;
12、音频信号重建模块,连接所述频谱获取模块,用于基于构建的音频重建模型,根据获得的各频谱图获得重建的音频信号数据,以对目标移动设备内置的扬声器正在播放的音频进行感知;
13、其中,构建音频重建模型的方式包括:
14、获取由目标移动设备内置的一或多个传感器同步采集的传感器信号数据以及各传感器在采集传感器信号数据时由目标移动设备内置的扬声器播放的已知音频片段数据;其中,传感器信号数据相较于已知音频片段数据向后偏移;对采集的各传感器信号数据进行数据处理,获得数据处理后的各传感器信号数据;将数据处理后的各传感器信号数据对齐至已知音频片段数据,以获得对齐后的各传感器信号数据;基于由对对齐后的各传感器信号数据进行短时傅立叶变换获得的频谱图以及已知音频数据构成的训练集训练获得所述音频重建模型。
15、为实现上述目的及其他相关目的,本发明提供一种基于移动设备内置传感器的语音感知终端,包括:一或多个存储器及一或多个处理器;所述一或多个存储器,用于存储计算机程序;所述一或多个处理器,连接所述存储器,用于运行所述计算机程序以执行所述基于移动设备内置传感器的语音感知方法。
16、如上所述,本发明是一种基于移动设备内置传感器的语音感知方法、系统及终端,具有以下有益效果:本发明通过对由目标移动设备内置的一或多个传感器同步采集的传感器信号数据进行数据处理,并对数据处理后的各传感器信号数据进行短时傅立叶变换获得对应的频谱图,再基于构建的音频重建模型,根据获得的各频谱图获得重建的音频信号数据,以对目标移动设备内置的扬声器正在播放的音频进行感知。本发明实现了基于收集的内置传感器的传感器信号,在低采样率(400hz)限制下进行语音内容重建。提高了基于智能手机内置传感器语音重建方法的性能,能够大大增加相关技术的应用能力。
- 还没有人留言评论。精彩留言会获得点赞!