一种文本生成音频方法及系统
本发明涉及语音处理,尤其涉及一种文本生成音频方法及系统。
背景技术:
1、文本生成音频(text-to-audio,tta)生成是一种新兴应用,旨在基于文本提示合成多样化的音频输出。随着人工智能在生成式人工智能(artificial intelligencegenerated content,aigc)领域的整合,tta应用的范围显著扩大,涵盖了电影配音、音乐创作等领域。
2、早期的tta模型主要依赖于单一标签,导致音频生成单调,受限于有限的标签空间和生成能力。与之相反,自然描述性文本提供了更全面和细致的信息。因此,后续的工作开发了基于文本内容的模型。一些研究使用扩散模型框架实现文本生成音频,另外其他模型使用基于transformer解码器结构的自回归模型。
3、现有技术在通过文本合成音频的过程中,通常需要首先将参考的音频转化为梅尔频谱,经过梅尔编码器得到梅尔隐式特征,再结合梅尔隐式特征和文本生成合成的音频,梅尔频谱虽然为对照原始音频的数据,但是梅尔频谱并没有对原始音频的数据进行进一步的处理,导致最终合成的音频效果较差。
技术实现思路
1、鉴于此,本发明的实施例提供了一种文本生成音频方法,以消除或改善现有技术中存在的一个或更多个缺陷。
2、本发明的一个方面提供了一种文本生成音频方法,所述方法的步骤包括扩散模型训练和音频推理;
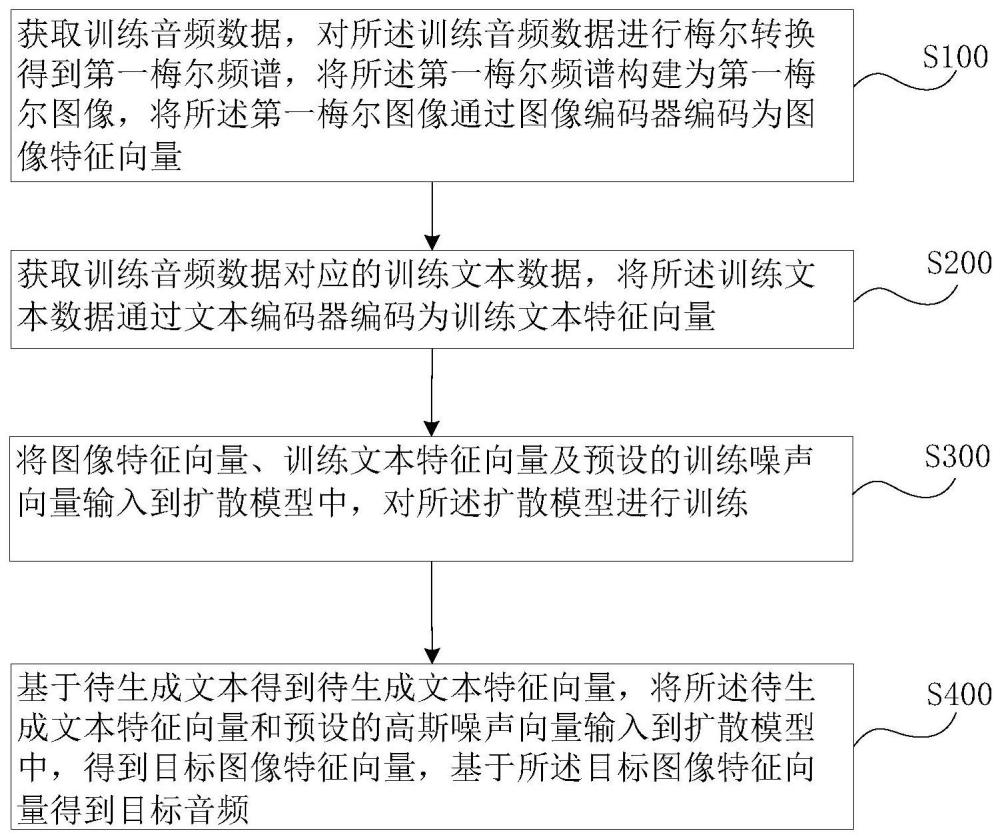
3、在所述扩散模型训练的步骤中,获取训练音频数据,对所述训练音频数据进行梅尔转换得到第一梅尔频谱,将所述第一梅尔频谱构建为第一梅尔图像,将所述第一梅尔图像通过图像编码器编码为图像特征向量;
4、获取训练音频数据对应的训练文本数据,将所述训练文本数据通过文本编码器编码为训练文本特征向量;
5、将图像特征向量、训练文本特征向量及预设的训练噪声向量输入到扩散模型中,对所述扩散模型进行训练;
6、在音频推理的步骤中,基于待生成文本得到待生成文本特征向量,将所述待生成文本特征向量和预设的高斯噪声向量输入到扩散模型中,得到目标图像特征向量,基于所述目标图像特征向量得到目标音频。
7、采用上述方案,本方案区别于现有技术采用的对梅尔频谱进行编码的方式,本方案在梅尔频谱的基础上,进一步将所述第一梅尔频谱构建为第一梅尔图像,再通过图像编码器编码为图像特征向量,图像编码器能够基于图像中每个像素点进行编码,相对于原始的梅尔频谱编码的方式,本方案中的图像特征向量中能够结合更多的数据,得到结合更多音频特征的图像特征向量,进而使最终合成的音频效果更好。
8、在本发明的一些实施方式中,在基于所述目标图像特征向量得到目标音频的步骤中,对所述目标图像特征向量通过图像解码器进行解码,得到对应的目标梅尔图像,将所述目标梅尔图像构建为目标梅尔频谱,将所述目标梅尔频谱通过声码器构建为目标音频。
9、在本发明的一些实施方式中,在将所述目标梅尔图像构建为目标梅尔频谱的步骤中,将所述目标梅尔图像压缩为单通道图像,获取单通道的目标梅尔图像对应的目标梅尔频谱。
10、在本发明的一些实施方式中,获取单通道的目标梅尔图像对应的目标梅尔频谱的步骤还包括,对单通道的目标梅尔图像对应的目标梅尔频谱中每个频谱点进行逆标准化处理,结合每个逆标准化处理后的频谱点,得到逆标准化处理后的目标梅尔频谱。
11、在本发明的一些实施方式中,将所述第一梅尔频谱构建为第一梅尔图像的步骤包括:
12、将所述第一梅尔频谱对应构建为初始梅尔图像,所述初始梅尔图像为单通道图像;
13、将所述初始梅尔图像的通道进行复制,得到多通道的第一梅尔图像。
14、在本发明的一些实施方式中,扩散模型包括顺序设置的多个扩散网络,在将图像特征向量、训练文本特征向量及预设的训练噪声向量输入到扩散模型中,对所述扩散模型进行训练的步骤中,所述图像特征向量通过多个噪声融合步骤将多个训练噪声向量与图像特征向量相加,使图像特征向量融合训练噪声向量,将融合后的图像特征向量和训练文本特征向量输入到扩散模型中,所述扩散模型的每个扩散网络分别输出一个预测的训练噪声向量,基于预测的训练噪声向量和实际的训练噪声向量构建损失函数,对扩散模型进行训练。
15、在本发明的一些实施方式中,在基于预测的训练噪声向量和实际的训练噪声向量构建损失函数的步骤中,采用如下公式计算损失函数值:
16、
17、其中,lθ表示损失函数值,∈θ表示预测的训练噪声向量,∈表示实际的训练噪声向量。
18、在本发明的一些实施方式中,将所述第一梅尔频谱构建为第一梅尔图像的步骤包括对所述第一梅尔频谱进行标准化处理,在对所述第一梅尔频谱进行标准化处理的步骤中,所述第一梅尔频谱中包括多个频谱点,对所述频谱点的数值进行标准化处理,得到每个频谱点的标准化数值,结合全部频谱点的标准化数值,得到标准化处理后的所述第一梅尔频谱。
19、在本发明的一些实施方式中,在将所述待生成文本特征向量和预设的高斯噪声向量输入到扩散模型中,得到目标图像特征向量的步骤中,所述扩散模型的每个扩散网络输出预测的噪声向量,将预设的高斯噪声向量减去预测的噪声向量,得到目标图像特征向量。
20、在本发明的一些实施方式中,所述扩散模型训练的步骤还包括对训练音频数据的第一梅尔图像和训练文本数据进行数据增强;
21、在对训练音频数据的第一梅尔图像进行数据增强的步骤中,对训练数据的每张第一梅尔图像基于时间进行拉伸,并在拉伸后进行裁剪,对裁剪后的第一梅尔图像进行随机拼接或者随机加权平均,得到数据增强后的第一梅尔图像;
22、在对训练文本数据进行数据增强的步骤中,对所述训练文本数据随机替换动词或名词,并随机打乱所述训练文本数据的语序,再进行随机拼接,得到数据增强后的训练文本数据。
23、本发明的第二方面还提供一种文本生成音频系统,该系统包括计算机设备,所述计算机设备包括处理器和存储器,所述存储器中存储有计算机指令,所述处理器用于执行所述存储器中存储的计算机指令,当所述计算机指令被处理器执行时该系统实现如前所述方法所实现的步骤。
24、本发明的第三方面还提供一种计算机可读存储介质,其上存储有计算机程序,该计算机程序被处理器执行时以实现前述文本生成音频方法所实现的步骤。
25、本发明的附加优点、目的,以及特征将在下面的描述中将部分地加以阐述,且将对于本领域普通技术人员在研究下文后部分地变得明显,或者可以根据本发明的实践而获知。本发明的目的和其它优点可以通过在说明书以及附图中具体指出并获得。
26、本领域技术人员将会理解的是,能够用本发明实现的目的和优点不限于以上具体所述,并且根据以下详细说明将更清楚地理解本发明能够实现的上述和其他目的。
技术特征:
1.一种文本生成音频方法,其特征在于,所述方法的步骤包括扩散模型训练和音频推理;
2.根据权利要求1所述的文本生成音频方法,其特征在于,在基于所述目标图像特征向量得到目标音频的步骤中,对所述目标图像特征向量通过图像解码器进行解码,得到对应的目标梅尔图像,将所述目标梅尔图像构建为目标梅尔频谱,将所述目标梅尔频谱通过声码器构建为目标音频。
3.根据权利要求2所述的文本生成音频方法,其特征在于,在将所述目标梅尔图像构建为目标梅尔频谱的步骤中,将所述目标梅尔图像压缩为单通道图像,获取单通道的目标梅尔图像对应的目标梅尔频谱。
4.根据权利要求3所述的文本生成音频方法,其特征在于,获取单通道的目标梅尔图像对应的目标梅尔频谱的步骤还包括,对单通道的目标梅尔图像对应的目标梅尔频谱中每个频谱点进行逆标准化处理,结合每个逆标准化处理后的频谱点,得到逆标准化处理后的目标梅尔频谱。
5.根据权利要求1所述的文本生成音频方法,其特征在于,将所述第一梅尔频谱构建为第一梅尔图像的步骤包括:
6.根据权利要求1~5任一项所述的文本生成音频方法,其特征在于,扩散模型包括顺序设置的多个扩散网络,在将图像特征向量、训练文本特征向量及预设的训练噪声向量输入到扩散模型中,对所述扩散模型进行训练的步骤中,所述图像特征向量通过多个噪声融合步骤将多个训练噪声向量进行融合,将融合后的图像特征向量和训练文本特征向量输入到扩散模型中,所述扩散模型的每个扩散网络分别输出一个预测的训练噪声向量,基于预测的训练噪声向量和实际的训练噪声向量构建损失函数,对扩散模型进行训练。
7.根据权利要求6所述的文本生成音频方法,其特征在于,在基于预测的训练噪声向量和实际的训练噪声向量构建损失函数的步骤中,采用如下公式计算损失函数值:
8.根据权利要求1所述的文本生成音频方法,其特征在于,将所述第一梅尔频谱构建为第一梅尔图像的步骤包括对所述第一梅尔频谱进行标准化处理,在对所述第一梅尔频谱进行标准化处理的步骤中,所述第一梅尔频谱中包括多个频谱点,对所述频谱点的数值进行标准化处理,得到每个频谱点的标准化数值,结合全部频谱点的标准化数值,得到标准化处理后的所述第一梅尔频谱。
9.根据权利要求1所述的文本生成音频方法,其特征在于,在将所述待生成文本特征向量和预设的高斯噪声向量输入到扩散模型中,得到目标图像特征向量的步骤中,所述扩散模型的每个扩散网络输出预测的噪声向量,将预设的高斯噪声向量减去预测的噪声向量,得到目标图像特征向量。
10.一种文本生成音频系统,其特征在于,该系统包括计算机设备,所述计算机设备包括处理器和存储器,所述存储器中存储有计算机指令,所述处理器用于执行所述存储器中存储的计算机指令,当所述计算机指令被处理器执行时该系统实现如权利要求1~9任一项所述方法所实现的步骤。
技术总结
本发明提供一种文本生成音频方法及系统,所述方法的步骤包括扩散模型训练和音频推理;在所述扩散模型训练的步骤中,对训练音频数据进行梅尔转换得到第一梅尔频谱,将所述第一梅尔频谱构建为第一梅尔图像,将所述第一梅尔图像通过图像编码器编码为图像特征向量;获取训练音频数据对应的训练文本数据,将训练文本数据通过文本编码器编码为训练文本特征向量;将图像特征向量、训练文本特征向量及预设的训练噪声向量输入到扩散模型中,对扩散模型进行训练;在音频推理的步骤中,基于待生成文本得到待生成文本特征向量,将待生成文本特征向量和预设的高斯噪声向量输入到扩散模型中,得到目标图像特征向量,基于所述目标图像特征向量得到目标音频。
技术研发人员:李雅,薛锦隆,邓雅月,高迎明
受保护的技术使用者:北京邮电大学
技术研发日:
技术公布日:2024/4/17
- 还没有人留言评论。精彩留言会获得点赞!