一种基于音源分离的自动记谱方法和装置
本申请涉及音频处理,尤其涉及一种基于音源分离的自动记谱方法和装置。
背景技术:
1、自动记谱技术是音乐领域中一项令人兴奋的创新,它的出现为音乐分析和创作提供了重要的工具。通过自动记谱,音乐家和研究人员可以将复杂的音乐作品转化为可视化的乐谱表示,从而更好地理解和分析音乐结构。
2、但是,传统的自动记谱技术常常被用于单一乐器,在面对多个音源时容易受到混叠和干扰,难以准确地分离不同乐器的声音。因此,需要对多个音源进行音源分离,通常使用音源分离模型实现音源的分离。音源分离模型使用之前需要进行训练,然而,训练数据的获得十分困难,因此训练可靠的乐器模型也并不容易。因此,亟需一种方法解决训练数据获取困难、音源分离模型无法训练的问题。
技术实现思路
1、有鉴于此,本申请提供一种基于音源分离的自动记谱方法和装置,用以解决训练数据获取困难、音源分离模型无法训练的问题。
2、具体地,本申请是通过如下技术方案实现的:
3、本申请第一方面提供一种基于音源分离的自动记谱方法,所述方法应用于预先训练的音源分离模型,
4、其中,所述音源分离模型为多个,每个所述音源分离模型与一种乐器相对应,基于原始数据集建立每个乐器对应的数据集,用于训练每个乐器对应的音源分离模型,所述方法包括:
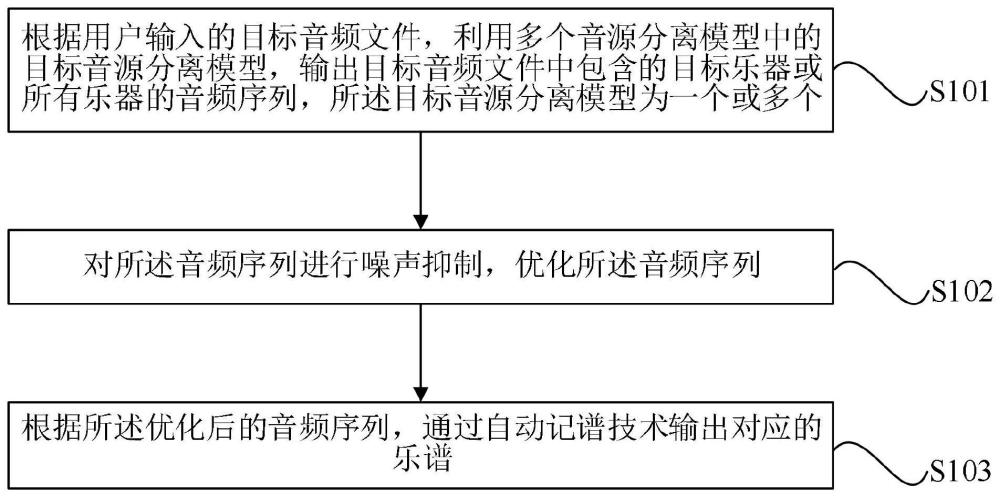
5、根据用户输入的目标音频文件,利用多个音源分离模型中的目标音源分离模型,输出目标音频文件中包含的目标乐器或所有乐器的音频序列,所述目标音源分离模型为一个或多个;
6、对所述音频序列进行噪声抑制,优化所述音频序列;
7、根据所述优化后的音频序列,通过自动记谱技术输出对应的乐谱。
8、本申请第二方面提供一种基于音源分离的自动记谱装置,其特征在于,所述装置应用于预先训练的音源分离模型,
9、其中,所述音源分离模型为多个,每个所述音源分离模型与一种乐器相对应,基于原始数据集建立每个乐器对应的数据集,用于训练每个乐器对应的音源分离模型,所述装置包括:输出模块和优化模块,其中,
10、所述输出模块,用于根据用户输入的目标音频文件,利用多个音源分离模型中的目标音源分离模型,输出目标音频文件中包含的目标乐器或所有乐器的音频序列,所述目标音源分离模型为一个或多个;
11、所述优化模块,用于对所述音频序列进行噪声抑制,优化所述音频序列;
12、所述输出模块,还用于根据所述优化后的音频序列,通过自动记谱技术输出对应的乐谱。
13、本申请第三方面提供一种计算机可读存储介质,其上存储有计算机程序,所述程序被处理器执行时实现本申请第一方面提供的任一项所述方法的步骤。
14、本申请提供的基于音源分离的自动记谱方法和装置,根据用户输入的目标音频文件,通过利用多个音源分离模型中的目标音源分离模型,输出目标音频文件中包含的目标乐器或所有乐器的音频序列,所述目标音源分离模型为一个或多个,并对所述音频序列进行噪声抑制,优化所述音频序列,进而根据所述优化后的音频序列,通过自动记谱技术输出对应的乐谱。这样,通过对普通的音频数据集进行预先处理得到目标乐器对应的训练的数据集,进而利用所述目标乐器的数据集训练得到目标音源分离模型,可以直接从普通的音频中获得目标乐器的训练样本,无需提供特定的音频样本,解决了训练数据获取困难、音源分离模型无法训练的问题;另一方面,通过预先训练好的目标音源分离模型和自动记谱技术输出目标音频文件的乐谱,实现了多乐器识别和分离的效果,且目标音源分离模型是经过针对性构建的样本训练的,模型精度高于现有技术中的模型,进而音频的分离和识别效果优于现有技术。
技术特征:
1.一种基于音源分离的自动记谱方法,其特征在于,所述方法应用于预先训练的音源分离模型,
2.根据权利要求1所述的方法,其特征在于,所述音源分离模型的训练过程,包括:
3.根据权利要求2所述的方法,其特征在于,所述基于第一数据集,提取目标乐器的数据集,包括:
4.根据权利要求3所述的方法,其特征在于,所述调整各个查找到的文件中的文件内容和文件格式,形成标准化的查找到的文件夹,所述标准化的查找到的文件夹中只包含第二指定格式的文件,包括:
5.根据权利要求2所述的方法,其特征在于,所述利用每一个所述目标乐器的数据集训练所述目标乐器对应的音源分离模型,得到训练好的音源分离模型,包括:
6.根据权利要求1所述的方法,其特征在于,当输出的音频序列是目标乐器的音频序列时,直接将分离后的音频序列存储到内存。
7.根据权利要求1所述的方法,其特征在于,当输出的音频序列是目标音频文件中包含的所有乐器的音频序列时,所述方法还包括:
8.根据权利要求1所述的方法,其特征在于,所述音源分离模型包括下采样模块、上采样模块、中间层和输出层;其中,下采样模块用于对输入的音频信号进行降采样,以减小音频信号的时间分辨率;上采样模块用于将降采样的音频信号恢复到原始的时间分辨率;中间层用于提取高级特征,以便执行音频源分离或音频合成任务;输出层用于将网络的最终输出映射到所需的输出维度;其中,下采样模块与上采样模块通过中间层连接;上采样模块与输出层连接。
9.根据权利要求1所述的方法,其特征在于,所述根据所述优化后的音频序列,通过自动记谱技术输出对应的乐谱,包括:
10.一种基于音源分离的自动记谱装置,其特征在于,所述装置应用于预先训练的音源分离模型,
技术总结
本申请提供一种基于音源分离的自动记谱方法和装置。本申请提供的基于音源分离的自动记谱方法,包括:根据用户输入的目标音频文件,利用多个音源分离模型中的目标音源分离模型,输出目标音频文件中包含的目标乐器或所有乐器的音频序列,目标音源分离模型为一个或多个;对音频序列进行噪声抑制,优化音频序列;根据优化后的音频序列,通过自动记谱技术输出对应的乐谱,通过对数据集进行预先处理得到目标乐器的数据集,进而利用所述目标乐器的数据集训练得到目标音源分离模型,解决了训练数据获取困难、音源分离模型无法训练的问题;通过目标音源分离模型和自动记谱技术输出目标音频文件的乐谱,实现了多乐器识别和分离的效果。
技术研发人员:周若华,张钰航
受保护的技术使用者:北京建筑大学
技术研发日:
技术公布日:2024/5/9
- 还没有人留言评论。精彩留言会获得点赞!