一种基于人类听觉反馈机制的声音活体检测方法及系统
本发明属于数字媒体处理,涉及一种声音活体检测方法及系统,具体涉及一种基于人类听觉反馈机制的声音活体检测方法及系统。
背景技术:
1、说话人验证(asv)凭借几条语音就能识别出说话人的真实身份。作为一种便捷、简单、准确的生物认证技术,asv无需复杂且难以记忆的密码、pin或基于知识的身份验证,已经在银行、零售金融、司法取证、语音交互等领域得到了广泛应用。
2、然而,asv的广泛应用也吸引了众多恶意的攻击,使其面临着极大的安全威胁。以录音重放、语音克隆(包括语音合成和语音转换)和对抗样本等为代表的语音伪造技术可以通过预先录制、合成或者扰动目标说话人的语音欺骗asv系统从而非法获取权限,造成人身或财产损失。因此,准确地识别出伪造语音、保护asv免受伪造攻击对于asv能够正常工作起着至关重要的作用。
3、针对语音伪造攻击,现有方法主要从两个方面来实现语音鉴伪。一方面是伪造语音检测,其主要思路是通过识别伪造痕迹来区分伪造语音与真实语音。然而,由于伪造痕迹的多样性及伪造方法的不断发展,这类检测方法对于未知伪造类型的虚假语音往往存在检测泛化性和鲁棒性不足的问题。另一种广泛采用方法是声音活体检测,即通过活体说话人与扬声器播放的声音之间的声学特征差异来判断当前声音是否来自一个真实的说话人。相较于第一种方法,声音活体检测更不容易受到未知伪造类型的干扰;由于伪造语音大多是通过扬声器播放的,因此声音活体检测具有更好的通用性。
4、现有的声音活体检测方法主要包括三种:基于传感器或类传感器设备、主动和被动的检测方法。基于传感器或类传感器设备的声音活体检测方法通常需要借助额外的传感器,这类检测方式成本较高,不容易部署和推广使用,对各种环境干扰的鲁棒性也有限。主动和被动的检测方法不需要借助传感器。主动的检测通过设备内置的扬声器发出人耳听不见的高频声学信号来检测人体的运动和位置,并以此来判断是否为活体,如嘴唇动作、胸腔震动和发声姿势等;然而,这样的方法很容易受到复杂环境因素的干扰。被动的检测仅使用收集到的语音进行活体检测,如声场、爆破声等;然而,现有的方法通常要求说话人保持特定的姿势、距离或对麦克风的排列方式有一定的要求,因此限制了该方法的应用范围,同时易受环境干扰的影响。另外,上述三种方法大多都缺乏泛化性,很难泛化至未知的说话人、性别甚至数据集。因此,非常有必要去实现一个部署成本低、检测准确率高、对各种环境干扰鲁棒、泛化性强的声音活体检测算法。
技术实现思路
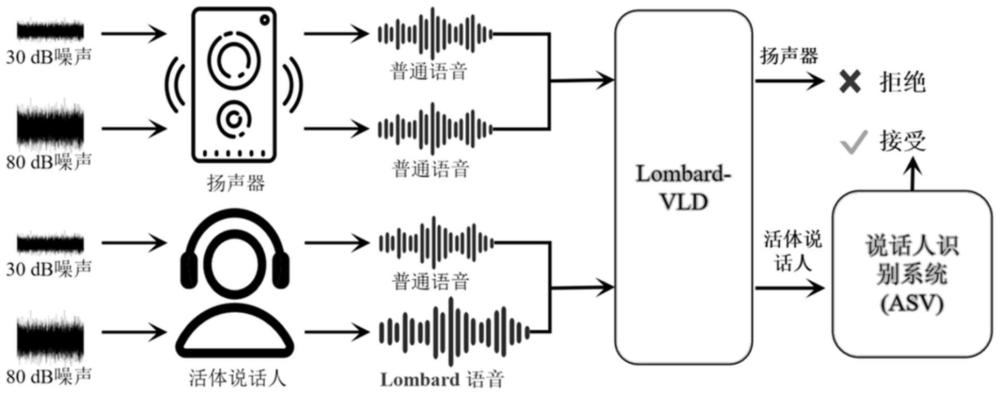
1、针对现有声音活体检测算法所普遍存在的成本高、检测准确率低、鲁棒性差、泛化性不足等问题,本发明从活体说话人在噪声环境下的听觉反馈机制这一新视角出发,利用lombard效应所导致的说话人发声模式的差异性改变,提供了一种基于人类听觉反馈机制的声音活体检测方法及系统,设计了基于参考的双输入模式和差分增强模块来提取差分特征,提高了声音活体检测算法的检测准确率、对环境干扰的鲁棒性和泛化性,并且不需要借助任何额外设备,也不需要用户保持特定姿势和距离,容易部署和应用。
2、本发明的方法所采用的技术方案是:一种基于人类听觉反馈机制的声音活体检测方法,包括以下步骤:
3、步骤1:采集用户普通语音和lombard语音;
4、步骤2:利用特征提取网络,提取普通语音和lombard语音的语音特征;
5、步骤3:利用差分增强网络,以普通语音的特征为参考,对lombard语音与普通语音之间的差异性特征进行提取和增强;
6、步骤4:利用特征融合和归一化网络,对增强后的差异性特征进行处理,得到固定长度的差分向量;
7、步骤5:差分向量通过一个全连接网络输出检测结果。
8、作为优选,步骤2中,所述特征提取网络,包括stft层、tdnn层和三个se-resblock层;
9、所述stft层,由短时傅里叶变换函数组成,用于将输入语音从时域变换到频域,并提取对应的梅尔语谱图;
10、所述tdnn层,由顺序连接的conv层、relu激活层和bn层组成,用于捕捉输入样本的时序信息;
11、所述三个se-resblock层,提取特征在多个感受野上的时序依赖,所述三个se-resblock层的输出均被输入接下来的差分增强网络。
12、作为优选,步骤3中,所述差分增强网络,包括全局池化层、softmax激活函数层、逐通道相乘层、逐像素相减层;
13、所述普通语音特征,依次通过全局池化层、softmax激活函数层后,输出通道级别的参考权重;所述逐通道相乘层,用于参考权重先选择lombard语音特征中与普通语音特征相关的频带维度并进行加权计算;所述逐像素相减层,用于将所述逐通道相乘层输出的加权后的lombard语音特征其从原始lombard语音特征中减去,从而得到只与lombard效应导致的频域变化相关的差分特征。
14、作为优选,步骤4中,所述特征融合和归一化网络,由顺序连接的conv层、relu激活函数层、注意力统计池化层、bn层、全连接层和bn层组成。
15、作为优选,所述特征提取网络、差分增强网络和特征融合和归一化网络,构成声音活体检测网络;所述声音活体检测网络,是训练好的声音活体检测网络;训练中,采用附加角间距损失来对差分向量进行分类训练,通过拉近类内距离、拉远类间距离来获得高区分度的特征,其损失函数表示如下:
16、
17、其中,m和s是超参数,表示边距和缩放尺度;yi表示真实的标签且n设为2。
18、本发明的系统所采用的技术方案是:一种基于人类听觉反馈机制的声音活体检测系统,包括以下模块:
19、信息采集模块,用于采集用户普通语音和lombard语音;
20、特征提取模块,用于利用特征提取网络,提取普通语音和lombard语音的语音特征;
21、差分增强模块,用于利用差分增强网络,以普通语音的特征为参考,对lombard语音与普通语音之间的差异性特征进行提取和增强;
22、归一化处理模块,用于利用特征融合和归一化网络,对增强后的差异性特征进行处理,得到固定长度的差分向量;
23、检测模块,差分向量通过一个全连接网络用于输出检测结果。
24、作为优选,所述特征提取网络,包括stft层、tdnn层和三个se-resblock层;
25、所述stft层,由短时傅里叶变换函数组成,用于将输入语音从时域变换到频域,并提取对应的梅尔语谱图;
26、所述tdnn层,由顺序连接的conv层、relu激活层和bn层组成,用于捕捉输入样本的时序信息;
27、所述三个se-resblock层,提取特征在多个感受野上的时序依赖,所述三个se-resblock层的输出均被输入接下来的差分增强网络。
28、作为优选,所述差分增强网络,包括全局池化层、softmax激活函数层、逐通道相乘层、逐像素相减层;
29、所述普通语音特征,依次通过全局池化层、softmax激活函数层后,输出通道级别的参考权重;所述逐通道相乘层,用于参考权重先选择lombard语音特征中与普通语音特征相关的频带维度并进行加权计算;所述逐像素相减层,用于将所述逐通道相乘层输出的加权后的lombard语音特征其从原始lombard语音特征中减去,从而得到只与lombard效应导致的频域变化相关的差分特征。
30、作为优选,所述特征融合和归一化网络,由顺序连接的conv层、relu激活函数层、注意力统计池化层、bn层、全连接层和bn层组成。
31、作为优选,所述特征提取网络、差分增强网络和特征融合和归一化网络,构成声音活体检测网络;所述声音活体检测网络,是训练好的声音活体检测网络;训练中,采用附加角间距损失来对差分向量进行分类训练,通过拉近类内距离、拉远类间距离来获得高区分度的特征,其损失函数表示如下:
32、
33、其中,m和s是超参数,表示边距和缩放尺度,分别固定为0.2和30。yi表示真实的标签且n设为2,因为此检测任务可以看作是二分类任务。
34、相对于现有技术,本发明的有益效果是:
35、1.创新的视角。本发明首次将人类听觉反馈机制引入到说话人验证系统(asv)的反欺骗中,并提出了利用活体说话人说话模式的变化来检测语音活体的lombard-vld框架。
36、2.有效的方法。为了解决lombard效应对不同说话人、语音内容、背景噪声水平等的依赖性,本发明设计了一种基于参考的双输入模式和差分增强网络,以提高lombard-vld的鲁棒性和泛化性。
37、3.优异的性能。lombard-vld在性能上相较于之前的方法取得了四个方面的优势:1)低成本,对传感器或特定姿势和距离没有要求;2)高准确率,能在两个不同的数据集下分别达到100%和99.76%的检测准确率;3)强鲁棒性,对各种环境因素具有鲁棒性;4)良好的泛化性,可以泛化至到未知的说话人、性别甚至数据集。
- 还没有人留言评论。精彩留言会获得点赞!