语音分离的方法、系统、计算设备和存储介质与流程
本公开涉及语音处理领域,特别涉及一种语音分离的方法、系统、计算设备和存储介质等。
背景技术:
1、目前在有些场景下需要语音分离技术,例如在多人同时讲话时至少将目标说话人的语音分离出来以便后续处理。
技术实现思路
1、本公开实施例提供了语音分离的方法、系统以及相应的执行这些方法的计算设备、计算机程序产品和非暂时性机器可读存储介质。
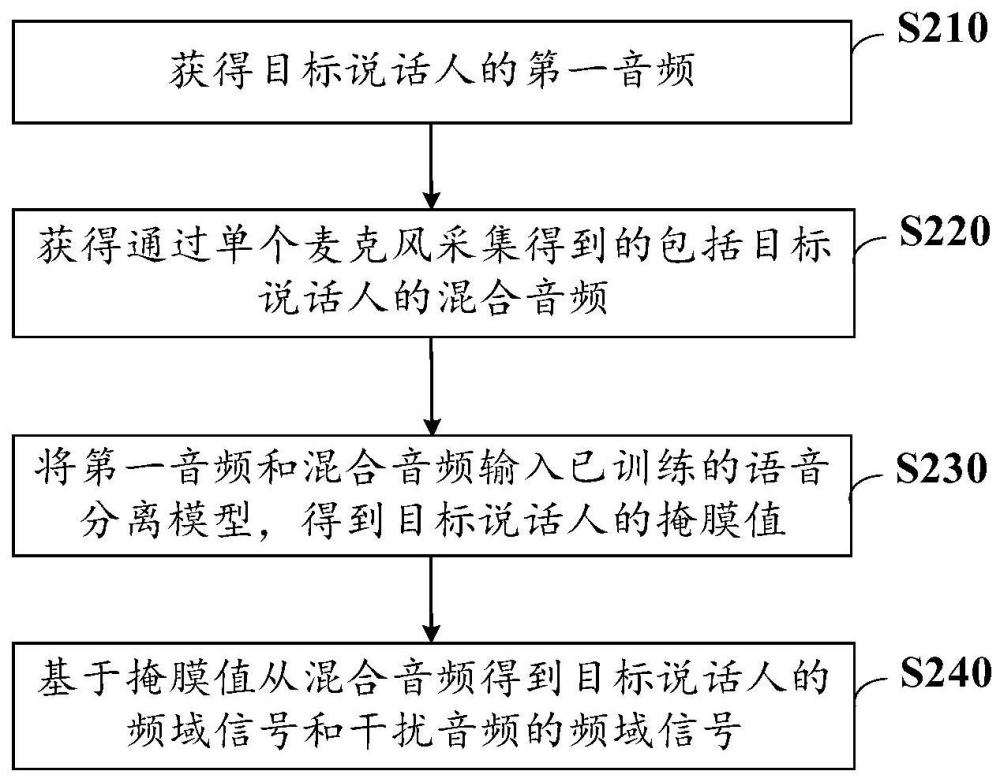
2、根据本公开实施例的第一个方面,提供了一种语音分离的方法,包括:获得目标说话人的第一音频;获得通过单个麦克风采集得到的包括目标说话人的混合音频;将所述第一音频和所述混合音频输入已训练的语音分离模型,得到目标说话人的掩膜值;以及基于所述掩膜值从所述混合音频得到所述目标说话人的频域信号和干扰音频的频域信号。
3、可选地,所述方法在将所述第一音频和所述混合音频输入已训练的语音分离模型之前还包括:对所述第一音频进行一次分帧处理得到多个第一音频帧;对所述混合音频进行两次分帧处理得到多个第一混合音频帧和多个第二混合音频帧,其中,所述第一混合音频帧和所述第二混合音频帧的帧长不同。
4、可选地,所述方法还包括:将多个所述第一音频帧和多个所述第二混合音频帧输入所述已训练的语音分离模型,得到每一所述第二混合音频帧下所述目标说话人的掩膜值;将多个所述第二音频帧进行傅里叶变换得到的频域信号以及每一所述第二混合音频帧下所述目标说话人的掩膜值分别生成所述目标说话人的频域信号和所述干扰音频的频域信号。
5、可选地,所述方法还包括:根据所述目标说话人的频域信号和所述干扰音频的频域信号的自功率谱,确定所述混合音频的来源;基于所述混合音频的来源确定最终的目标说话人的音频信号。
6、可选地,所述方法还包括:所述目标说话人的频域信号和所述干扰音频的频域信号的自功率谱差值不低于第一阈值,确定所述混合音频的来源仅包括所述目标说话人或干扰人;分别获得所述混合音频和所述第一音频的声纹特征;确定所述混合音频和所述第一音频的声纹特征之间的相似度超过第二阈值,以所述混合音频作为最终的目标说话人的音频信号。
7、可选地,所述方法还包括:所述目标说话人的频域信号和所述干扰音频的频域信号的自功率谱差值低于第一阈值,确定所述混合音频的来源包括所述目标说话人和干扰人;将所述目标说话人的频域信号转换到时域上得到所述目标说话人的时域信号;将所述目标说话人的时域信号作为最终的目标说话人的音频信号。
8、可选地,所述已训练的语音分离模型包括:第一特征提取层,用于提取所述混合音频的混合音频特征;第二特征提取层,用于提取所述第一音频的第一音频特征;特征融合层,用于融合所述混合音频特征和所述第一音频特征得到融合音频特征;目标说话人提取层,用于基于所述融合特征提取所述目标说话人的掩膜值。
9、可选地,所述方法在将所述混合音频输入第一特征提取层之前还包括:对所述混合音频进行傅里叶变换得到所述混合音频的频域信号;并且在将所述第一音频输入第二特征提取层之前还包括:将所述第一音频进行傅里叶变换得到所述第一音频的频域信号。
10、可选地,所述混合音频特征是所述混合音频的幅度谱,所述第一音频特征是所述第一音频的声纹特征。
11、可选地,所述方法在得到混合音频特征后还包括:将所述混合音频特征输入第一全连接层得到降维后的混合音频特征;并且在得到第一音频特征后还包括:将所述第一音频特征输入第二全连接层得到降维后的第一音频特征;融合降维后的混合音频特征和降维后的第一音频特征得到所述融合音频特征。
12、可选地,降维后的第一音频特征包括第一参数和第二参数,以所述第一参数为系数、所述第二参数为偏移量将所述混合音频的特征向量变换为所述融合特征向量。
13、可选地,所述第一音频包括目标说话人的注册音频中的至少一部分;并且/或者所述混合音频为实时采集得到的音频。
14、根据本公开实施例的第二个方面,提供了一种语音分离模型的训练方法,已训练的语音分离模型用于如上述第一个方面中的任一方案所述的方法以实现语音分离,包括:获取混合训练音频,其中,所述混合训练音频至少包括目标说话人信号和噪声信号;将所述混合训练音频输入第一特征提取层得到混合训练音频特征;获取目标说话人的第一训练音频;将所述第一训练音频输入第二特征提取层得到第一训练音频特征;融合所述混合训练音频特征和所述第一训练音频特征得到融合训练音频特征,将所述融合训练音频特征输入目标说话人提取层得到所述目标说话人的掩膜值;基于所述掩膜值、所述混合训练音频得到目标说话人分离信号,基于所述目标说话人分离信号和所述目标说话人信号对所述语音分离模型进行训练。
15、可选地,所述方法在将所述混合训练音频输入第一特征提取层之前还包括:对所述混合训练音频进行傅里叶变换得到所述混合训练音频的频域信号;并且在将所述第一训练音频输入第二特征提取层之前还包括:将所述第一训练音频进行傅里叶变换得到所述第一训练音频的频域信号。
16、可选地,所述混合训练音频特征是所述混合训练音频的幅度谱,所述第一训练音频特征是所述第一训练音频的声纹特征。
17、可选地,所述方法在得到混合训练音频特征后还包括:将所述混合训练音频特征输入第一全连接层得到降维后的混合训练音频特征;并且在得到第一训练音频特征后还包括:将所述第一训练音频特征输入第二全连接层得到降维后的第一训练音频特征;融合降维后的混合训练音频特征和降维后的第一训练音频特征得到所述融合训练音频特征。
18、可选地,基于所述目标说话人掩膜、所述混合训练音频得到目标说话人分离信号,包括:将所述目标说话人掩膜作用于所述混合训练音频得到目标说话人的频域分离信号;对所述频域分离信号进行傅里叶逆变换得到所述目标说话人分离信号。
19、可选地,基于所述目标说话人分离信号和所述目标说话人信号对所述语音分离模型进行训练,包括:计算所述目标说话人分离信号和所述目标说话人信号的损失值;基于所述损失值迭代更新所述语音分离模型,直到所述语音分离模型收敛。
20、根据本公开实施例的第三个方面,提供了一种语音分离系统,包括:至少具有一个麦克风的可穿戴设备,所述可穿戴设备被配置为:确定目标说话人的第一音频;通过一个麦克风采集得到包括目标说话人的混合音频;将所述第一音频和所述混合音频发送至和所述可穿戴设备通信连接的终端设备;
21、所述终端设备包括已训练的语音分离模型,所述终端设备被配置为:接收所述可穿戴设备发送的所述第一音频和所述混合音频,将所述第一音频和所述混合音频输入所述已训练的语音分离模型,得到目标说话人的掩膜值;基于所述掩膜值从所述混合音频得到所述目标说话人的频域信号和干扰音频的频域信号。根据本公开实施例的第四个方面,提供了一种计算设备,包括:处理器;以及存储器,其上存储有可执行代码,当可执行代码被处理器执行时,使处理器执行如上述第一个方面或上述第二个方面中的任一方案所述的方法。
22、根据本公开实施例的第五个方面,提供了一种非暂时性机器可读存储介质,其上存储有可执行代码,当可执行代码被电子设备的处理器执行时,使处理器执行如上述第一个方面或上述第二个方面中的任一方案所述的方法。
23、根据本公开实施例的第六个方面,提供了一种计算机程序产品,包括可执行代码,当所述可执行代码被电子设备的处理器执行时,使所述处理器执行如上述第一个方面或上述第二个方面中的任一方案所述的方法。
- 还没有人留言评论。精彩留言会获得点赞!