一种用于智慧监管的多目标监测方法与流程
本发明涉及语音处理,具体涉及一种用于智慧监管的多目标监测方法。
背景技术:
1、在环境中,通常是多人交流和对话,因此,若要分析其中每个人的说话内容,则需要找到每个人的说话声音时段。现有的找到多人说话中每个人说话时段的现有方法为:通过深度卷积神经网络建立端到端说话人数计算模型,以原始音频波形作为端到端说话人数计算模型的输入,预测出说话人数,然后根据说话人数再进行后续的语音分离,找到每个人说话的时段。现有方法直接使用原始音频波形,但是原始音频波形包含的数据量大,采用端到端说话人数计算模型也需要运用大运算力的深度卷积神经网络,因此其存在输入数据量大,模型结构复杂,计算量大的问题。
技术实现思路
1、针对现有技术中的上述不足,本发明提供的一种用于智慧监管的多目标监测方法解决了现有技术存在的输入数据量大,模型结构复杂,计算量大的问题。
2、为了达到上述发明目的,本发明采用的技术方案为:一种用于智慧监管的多目标监测方法,包括以下步骤:
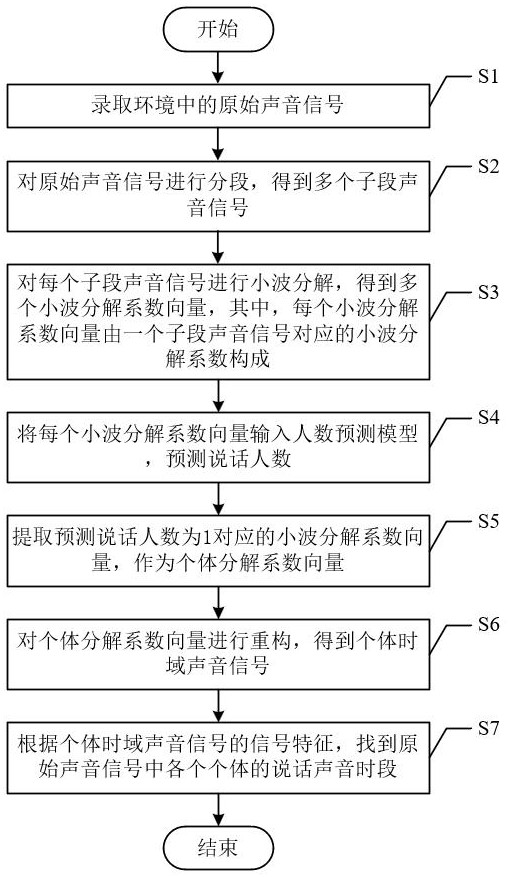
3、s1、录取环境中的原始声音信号;
4、s2、对原始声音信号进行分段,得到多个子段声音信号;
5、s3、对每个子段声音信号进行小波分解,得到多个小波分解系数向量,其中,每个小波分解系数向量由一个子段声音信号对应的小波分解系数构成;
6、s4、将每个小波分解系数向量输入人数预测模型,预测说话人数;
7、s5、提取预测说话人数为1对应的小波分解系数向量,作为个体分解系数向量;
8、s6、对个体分解系数向量进行重构,得到个体时域声音信号;
9、s7、根据个体时域声音信号的信号特征,找到原始声音信号中各个个体的说话声音时段。
10、进一步地,所述s4中人数预测模型包括:高频系数特征提取单元、低频系数特征提取单元、高频预测单元、低频预测单元和人数预测单元;
11、所述高频系数特征提取单元用于提取一个小波分解系数向量中高频部分的小波分解系数的特征值,得到高频特征值;
12、所述低频系数特征提取单元用于提取一个小波分解系数向量中低频部分的小波分解系数的特征值,得到低频特征值;
13、所述高频预测单元用于根据高频特征值和一个小波分解系数向量中高频部分的小波分解系数的长度,计算高频人数占比;
14、所述低频预测单元用于根据低频特征值和一个小波分解系数向量中低频部分的小波分解系数的长度,计算低频人数占比;
15、所述人数预测单元用于根据高频人数占比和低频人数占比,计算说话人数。
16、进一步地,所述高频特征值包括:高频系数均值和高频系数分布值;
17、所述高频系数均值用于取一个小波分解系数向量中高频部分的小波分解系数的均值;
18、所述高频系数分布值的公式为:
19、,
20、,
21、其中,gp为高频系数分布值,gi为高频部分的第i个小波分解系数,gc为高频部分的小波分解系数的均值,g为高频部分的小波分解系数的数量,max为取最大值,min为取最小值,gr为高频指数系数,为向上取整,| |为绝对值。
22、进一步地,所述低频特征值包括:低频系数均值和低频系数分布值;
23、所述低频系数均值用于取一个小波分解系数向量中低频部分的小波分解系数的均值;
24、所述低频系数分布值的公式为:
25、,
26、,
27、其中,dp为低频系数分布值,di为低频部分的第i个小波分解系数,dc为低频部分的小波分解系数的均值,d为低频部分的小波分解系数的数量,max为取最大值,min为取最小值,dr为低频指数系数,为向上取整,| |为绝对值。
28、进一步地,所述高频预测单元的表达式为:
29、,
30、其中,p1为高频人数占比,e为自然常数,ln为对数函数,gp为高频系数分布值,gc为高频部分的小波分解系数的均值,wgp为gp的权重,wgc为gc的权重,bg1为第一高频偏置,bg2为第二高频偏置,lg为高频部分的小波分解系数的长度,wlg为lg的权重,wg1为第一高频外层权重,wg2为第二高频外层权重。
31、进一步地,所述低频预测单元的表达式为:
32、,
33、其中,p2为低频人数占比,e为自然常数,ln为对数函数,dp为低频系数分布值,dc为低频部分的小波分解系数的均值,wdp为dp的权重,wdc为dc的权重,bd1为第一低频偏置,bd2为第二低频偏置,ld为低频部分的小波分解系数的长度,wld为ld的权重,wd1为第一低频外层权重,wd2为第二低频外层权重。
34、进一步地,所述s7包括以下分步骤:
35、s71、提取每个子段声音信号的音调、响度和音色,构成原始声音特征向量;
36、s72、提取个体时域声音信号的音调、响度和音色,构成个体声音特征向量;
37、s73、计算个体声音特征向量与原始声音特征向量的相似度,在相似度大于相似阈值时,对应个体在子段声音信号中存在说话声音;
38、s74、根据各个体存在说话声音的子段声音信号,得到原始声音信号中各个个体的说话声音时段。
39、进一步地,所述s73中相似度的计算公式为:
40、,
41、,
42、,
43、,
44、其中,s为相似度,r1为音调相似度,r2为响度相似度,r3为音色相似度,u为比例系数,fs1为原始声音特征向量中音调元素,fin1为个体声音特征向量中音调元素,fs2为原始声音特征向量中响度元素,fin2为个体声音特征向量中响度元素,fs3为原始声音特征向量中音色元素,fin3为个体声音特征向量中音色元素。
45、进一步地,所述比例系数u取:音调相似度r1、响度相似度r2和音色相似度r3三者中相似度大于0.5的数量。
46、本发明的有益效果为:本发明将原始声音信号进行分段,得到多个子段声音信号,对每个子段声音信号进行小波分解,得到各个子段声音信号的小波分解系数向量,小波分解系数体现的是信号的成分,从而更容易体现声音信号的组成结构,一方面能减少数据量,另一方面能凸显信号的结构,再进行说话人数预测,在数据量大大减少后,人数预测模型结构更简单,计算量更小。找到预测说话人数为1对应的小波分解系数向量,再重构,得到个人的时域声音信号,根据个人的时域声音信号的信号特征,从原始声音信号中找出各个个体的说话声音时段,实现各个说话目标的说话监测。
技术特征:
1.一种用于智慧监管的多目标监测方法,其特征在于,包括以下步骤:
2.根据权利要求1所述的用于智慧监管的多目标监测方法,其特征在于,所述s4中人数预测模型包括:高频系数特征提取单元、低频系数特征提取单元、高频预测单元、低频预测单元和人数预测单元;
3.根据权利要求2所述的用于智慧监管的多目标监测方法,其特征在于,所述高频特征值包括:高频系数均值和高频系数分布值;
4.根据权利要求2所述的用于智慧监管的多目标监测方法,其特征在于,所述低频特征值包括:低频系数均值和低频系数分布值;
5.根据权利要求3所述的用于智慧监管的多目标监测方法,其特征在于,所述高频预测单元的表达式为:
6.根据权利要求3所述的用于智慧监管的多目标监测方法,其特征在于,所述低频预测单元的表达式为:
7.根据权利要求1所述的用于智慧监管的多目标监测方法,其特征在于,所述s7包括以下分步骤:
8.根据权利要求7所述的用于智慧监管的多目标监测方法,其特征在于,所述s73中相似度的计算公式为:
9.根据权利要求8所述的用于智慧监管的多目标监测方法,其特征在于,所述比例系数u取:音调相似度r1、响度相似度r2和音色相似度r3三者中相似度大于0.5的数量。
技术总结
本发明公开了一种用于智慧监管的多目标监测方法,属于语音处理技术领域,本发明将原始声音信号进行分段,得到多个子段声音信号,对每个子段声音信号进行小波分解,得到各个子段声音信号的小波分解系数向量,小波分解系数体现的是信号的成分,从而更容易体现声音信号的组成结构,一方面能减少数据量,另一方面能凸显信号的结构,再进行说话人数预测,在数据量大大减少后,人数预测模型结构更简单,计算量更小。找到预测说话人数为1对应的小波分解系数向量,再重构,得到个人的时域声音信号,根据个人的时域声音信号的信号特征,从原始声音信号中找出各个个体的说话声音时段,实现各个说话目标的说话监测。
技术研发人员:马进泉,张昭君,陈尔锋
受保护的技术使用者:深圳市科荣软件股份有限公司
技术研发日:
技术公布日:2024/3/21
- 还没有人留言评论。精彩留言会获得点赞!