杂音抑制方法、可读介质、电子设备及程序产品与流程
本申请涉及音频,特别涉及一种杂音抑制方法、可读介质、电子设备及程序产品。
背景技术:
1、用户使用手机等电子设备中的视频软件播放视频或音乐软件播放音乐时,电子设备通常通过微型扬声器播放视频或音乐的音频数据。由于受体型限制,微型扬声器受限于瞬时电压、功率,输入信号的动态范围不宜过大。当音频数据包括有对话、独白等人声类型的音频数据时,音频数据的幅值可能会超过微型扬声器的限幅,导致音频数据产生削波,造成音频数据播放时产生杂音。为了避免音频数据播放时产生杂音,电子设备通常对音频数据中包含人声类型音频数据的频段进行整体抑制处理。
2、然而,音频数据中包含人声类型音频数据的频段可能还包括其他类型的音频数据,例如乐器演奏类型的音频数据。导致电子设备对音频数据中包含人声类型音频数据的频段进行整体抑制处理,在降低人声类型的音频数据幅值使其低于微型扬声器的限幅同时,还会降低其他类型的音频数据的幅值,影响其他类型的音频数据的正常播放,进而影响用户的听觉体验感。
技术实现思路
1、本申请的目的在于提供一种杂音抑制方法、可读介质、电子设备及程序产品。
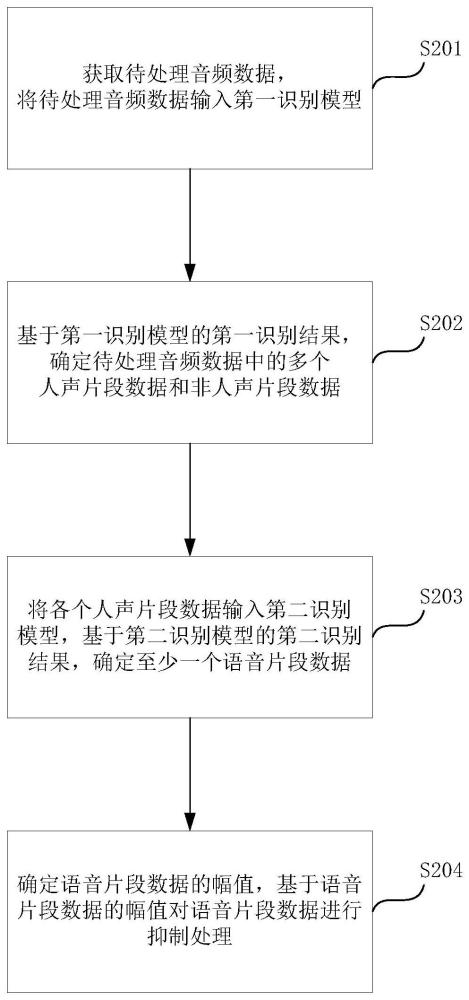
2、本申请的第一方面提供了一种杂音抑制方法,包括:获取待处理音频数据,将待处理音频数据输入第一识别模型;基于第一识别模型的第一识别结果,确定待处理音频数据中的人声片段数据和非人声片段数据;将人声片段数据输入第二识别模型,基于第二识别模型的第二识别结果,确定至少一个语音片段数据;确定语音片段数据的幅值,基于语音片段数据的幅值对语音片段数据进行抑制处理。
3、即在本申请实施例中,这里的第一识别模型指的是人声信号识别模型;第一识别结果指的是基于人声信号识别模型的识别结果;第二识别模型指的是语音信号识别模型;第二识别结果指的是基于语音信号识别模型的识别结果。
4、在上述第一方面的一种可能的实现中,人声片段数据包括人声信号数据,语音片段数据仅包括人声信号数据。
5、在上述第一方面的一种可能的实现中,确定语音片段数据的幅值,基于语音片段数据的幅值对语音片段数据进行抑制处理,包括:确定语音片段数据的基波信号数据的第一频率,以及多个谐波信号数据的第二频率;确定第一频率对应的第一幅值,以及多个第二频率对应的第二幅值;基于第一幅值和多个第二幅值对语音片段数据进行抑制处理。
6、即在本申请实施例中,这里的第一频率指的是基波信号数据的频率;第二频率指的是谐波信号数据的频率;第一幅值指的是基波信号数据的幅度;第二幅值指的是谐波信号数据的幅度。
7、在上述第一方面的一种可能的实现中,基于第一幅值和多个第二幅值对语音片段数据进行抑制处理,包括:将第一幅值降低至第三幅值,其中,第一幅值与第三幅值的比例为第一比例;将第二幅值降低至第四幅值,其中,第二幅值与第四幅值的比例为第二比例,第一比例与第二比例相同或不同。
8、即在本申请实施例中,这里的第三幅值指的是将语音片段数据的基波信号数据的幅度降低预设的幅值比例或预设的幅度阈值后的幅度;第四幅值指的是将语音片段数据的谐波信号数据的幅度降低预设的幅值比例或预设的幅度阈值后的幅度;第一比例指的是基波信号数据预设的幅值比例;第二比例指的是谐波信号数据预设的幅值比例。
9、在上述第一方面的一种可能的实现中,获取待处理音频数据,将待处理音频数据输入第一识别模型,包括:将待处理音频数据进行分帧处理,得到多个待处理音频子数据;确定各个待处理音频子数据的音频特征;将待处理音频子数据和待处理音频子数据的音频特征输入第一识别模型。
10、在上述第一方面的一种可能的实现中,第一识别模型的训练样本包括:人声类型和非人声类型的音频数据。
11、在上述第一方面的一种可能的实现中,基于第一识别模型的第一识别结果,确定待处理音频数据中的人声片段数据和非人声片段数据,包括:基于待处理音频子数据的音频特征,确定待处理音频子数据是否包括人声信号数据,其中,人声信号数据为人声类型的音频数据;将包括有人声信号数据的待处理音频子数据中作为人声片段数据,其中,人声片段数据包括人声信号数据;和/或,人声片段数据包括人声信号数据和非人声信号数据,其中,非人声信号数据为非人声类型的音频数据。
12、在上述第一方面的一种可能的实现中,将人声片段数据输入第二识别模型,基于第二识别模型的第二识别结果,确定至少一个语音片段数据,包括:确定人声片段数据的音频特征,将人声片段数据和人声片段数据的音频特征输入至第二识别模型,其中,第二识别模型以语音类型和非语音类型的音频数据作为训练样本确定,语音类型的音频数据仅包括人声信号数据,非语音类型的音频数据包括人声信号数据和非人声信号数据;基于第二识别模型的第二识别结果,将仅包括人声信号数据的人声片段数据作为语音片段数据。
13、在上述第一方面的一种可能的实现中,第一识别模型包括以下至少一种:支持向量机模型、k邻近算法模型、决策树模型、朴素贝叶斯模型、fm因子分析模型;第二识别模型包括以下至少一种:深度神经网络模型、卷积神经网络模型、循环神经网络模型。
14、在上述第一方面的一种可能的实现中,待处理音频子数据的音频特征至少包括以下一种:频谱质心、短时能量、过零率、梅尔频率倒谱系数、频谱平坦度。
15、本申请的第二方面提供了一种可读介质,可读介质上存储有指令,该指令在电子设备上执行时使电子设备执行上述第一方面中的任意一种方法。
16、本申请的第三方面提供了一种电子设备,包括:处理器和存储器,其中,存储器用于存储由电子设备的一个或多个处理器执行的指令,以及处理器,是电子设备的处理器之一,用于执行上述第一方面的任意一种方法。
17、本申请的第四方面提供了一种程序产品,该程序产品中包括指令,在该指令被电子设备执行时可以使电子设备实现上述第一方面及上述第一方面的各种可能实现提供的任意一种方法。
技术特征:
1.一种杂音抑制方法,其特征在于,包括:
2.根据权利要求1所述的方法,其特征在于,所述人声片段数据包括人声信号数据,所述语音片段数据仅包括人声信号数据。
3.根据权利要求1所述的方法,其特征在于,所述确定所述语音片段数据的幅值,基于所述语音片段数据的幅值对所述语音片段数据进行抑制处理,包括:
4.根据权利要求3所述的方法,其特征在于,所述基于所述第一幅值和多个所述第二幅值对所述语音片段数据进行抑制处理,包括:
5.根据权利要求1所述的方法,其特征在于,所述获取待处理音频数据,将所述待处理音频数据输入第一识别模型,包括:
6.根据权利要求5所述的方法,其特征在于,所述第一识别模型的训练样本包括:人声类型和非人声类型的音频数据。
7.根据权利要求6所述的方法,其特征在于,所述基于所述第一识别模型的第一识别结果,确定所述待处理音频数据中的人声片段数据和非人声片段数据,包括:
8.根据权利要求7所述的方法,其特征在于,所述将所述人声片段数据输入第二识别模型,基于所述第二识别模型的第二识别结果,确定至少一个语音片段数据,包括:
9.根据权利要求1所述的方法,其特征在于,
10.根据权利要求1所述的方法,其特征在于,所述待处理音频子数据的音频特征至少包括以下一种:频谱质心、短时能量、过零率、梅尔频率倒谱系数、频谱平坦度。
11.一种可读介质,其特征在于,所述可读介质上存储有指令,该指令在电子设备上执行时使电子设备执行权利要求1至10中任一项所述的方法。
12.一种电子设备,其特征在于,包括:处理器和存储器,其中,
13.一种程序产品,其特征在于,所述程序产品中包括指令,所述指令在电子设备上执行时使所述电子设备实现权利要求1至10中任一项所述的方法。
技术总结
本申请涉及音频技术领域,公开了一种杂音抑制方法、可读介质、电子设备及程序产品。该方法包括:获取待处理音频数据,将待处理音频数据输入第一识别模型;基于第一识别模型的第一识别结果,确定待处理音频数据中的多个人声片段数据和非人声片段数据;将各个人声片段数据输入第二识别模型,基于第二识别模型的第二识别结果,确定至少一个语音片段数据;确定语音片段数据的幅值,基于幅值对语音片段数据进行抑制处理。本申请实施例提供的方法,通过识别出语音片段数据,仅对语音片段数据进行抑制处理,在对语音片段数据进行抑制处理以避免失真的同时,不会影响用户对非语音片段数据和非人声片段数据的听感。
技术研发人员:石磊
受保护的技术使用者:上海艾为电子技术股份有限公司
技术研发日:
技术公布日:2024/5/10
- 还没有人留言评论。精彩留言会获得点赞!