一种阅读用声控辅助方法及装置与流程
本发明涉及阅读辅助,具体为一种阅读用声控辅助方法及装置。
背景技术:
1、现阶段很多产品推出了各自风格的智能对话系统,这类系统可以根据用户输入的内容自动生成带有特定风格的反馈内容,对于机器如何自动生成带有特定风格的反馈内容这一问题,较为成熟的解决办法为设置平行语料库,通过平行语料库中的句子对来实现,另外在申请号为201710817322.9的中国专利公开了“一种风格语句的生成方法、模型的训练方法、装置及设备,属于自然语言处理领域。所述方法包括:获取待转换的自然语句;将所述自然语句输入第一编码模型对所述自然语句中的风格信息进行过滤,生成所述自然语句对应的目标内容向量;根据设置的目标语言风格,从至少一种风格向量中确定与所述目标语言风格相对应的目标风格向量,将所述目标内容向量和所述目标风格向量输入第一解码模型,生成与所述自然语句对应的风格语句;保证了每种自然语句都能转换成具有目标语言风格的风格语句,提高了智能对话系统的智能化程度”,提供了一种通过编码模型解决前述问题的方案,具体步骤为①获取待转换的自然语句;②将所述自然语句输入第一编码模型对所述自然语句中的风格信息进行过滤,生成所述自然语句对应的目标内容向量;③根据设置的目标语言风格,从至少一种风格向量中确定与所述目标语言风格相对应的目标风格向量,将所述目标内容向量和所述目标风格向量输入第一解码模型,生成与所述自然语句对应的风格语句;
2、该技术方案对于设置平行语料库这一手段,在用户阅读的场景下,无法穷尽图书中所有语料信息(如果强行穷尽需要非常大的计算量);对于设置编码模型这一手段,一方面需要先生成自然语句,增加计算量、延长计算时间,往往无法对用户输入的内容进行及时反馈,另一方面模型中设置目标风格向量与平行语料库一样,无法穷尽图书中的所有风格信息,因此,目前还没有能够满足用户在阅读时,使用与阅读材料风格相匹配的智能对话系统这一需求的解决方案,另外,单纯的文字对话缺少趣味性,无法提高用户进行阅读的兴趣。
技术实现思路
1、本发明的目的在于提供一种阅读用声控辅助方法及装置,以解决上述背景技术中提出的问题。
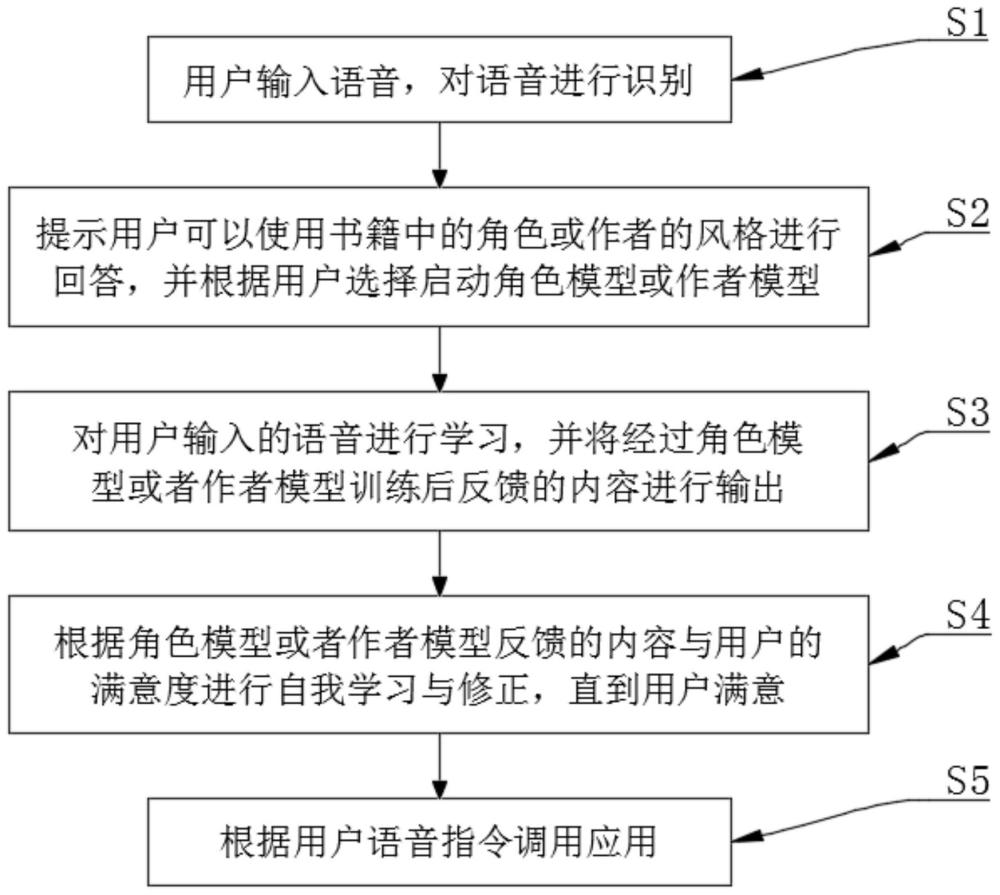
2、为实现上述目的,本发明提供如下技术方案:一种阅读用声控辅助方法,包括以下步骤:
3、s1、用户输入语音,对语音进行识别;
4、s2、提示用户可以使用书籍中的角色或作者的风格进行回答,并根据用户选择启动角色模型或作者模型;
5、s3、对用户输入的语音进行学习,并将经过角色模型或者作者模型训练后反馈的内容进行输出;
6、s4、根据角色模型或者作者模型反馈的内容与用户的满意度进行自我学习与修正,直到用户满意;
7、s5,根据用户语音指令调用应用。
8、优选的,所述步骤s1中,首先对语音数据进行采集,然后对采集到的语音数据进行预处理,然后提取出特征,随后创建声学模型,将特征信息输入到声学模型中进行训练,通过创建语言模型,将文本数据输入到语言模型中进行训练,并向解码器中输入标准字典,最后通过解码算法进行识别,输出文本完成语音识别,通过播报文本可使用户仅通过语音进行阅读辅助中的信息查询、获取与控制,把声学模型与语言模型组合在一起,以对特征序列o={o1,o2,o3,...,ot}进行处理,使用最大以后验证概率算法来得到最终识别结果;
9、最大以后验证概率算法如下:
10、
11、其中,表示语音识别的最终结果,w表示位置的词序列,p(w)表示w出现的先验概率,即语言模型概率,p(o|w)表示当未知的序列是w、声学模型输出的是o特征序列时的概率,即声学模型概率,p(o)表示声学特征o发生的概率;
12、p(o)只和声学特征有关,与w没有关系,因此语音识别基本方程可表示为:
13、
14、其中,logp(o|w)表示声学模型给出的评价值,logp(w)表示语言模型给出的评价值,当logp(o|w)与logp(w)的值越大,的值越大,表示最终识别结果就越大,λ作为权重系数,通过给定特殊值,使两种模型评价值更加均衡。
15、优选的,所述步骤s1中对语音数据进行预处理包括语音预加重,以增强语音数据中高频部分的能力,进而提高语音的分辨率,然后对语音进行分帧操作,得到信号频率的大致轮廓,便于对语音特征进行提取,在语音特征提取时,对每一帧信号进行快速傅里叶变换,经过快速傅里叶变换后得到该帧语音信号的频谱图,然后以时间顺序将每帧语音信号的频谱合到一起,然后对每帧语音信号进行处理,最后对频谱进行倒谱运算,以完成对语音数据的预处理。
16、优选的,所述步骤s2中,在提示用户可以使用书籍中的角色或者作者的风格进行回答前,需要进行角色模型或作者模型的建立,首先将图书文件上传,通过对图书内容进行扫描和识别以获取图书内容,然后根据图书中所有的角色及图书的作者对图书内容进行拆分并且重构,然后存储至图书数据库中,然后利用大模型对图书中所有的角色及图书的作者进行建模,包括不同角色的语音内容和语气,通过大模型对图书内容中的相关性内容按照不同角色进行分类,然后从该图书中挖掘出角色所涉及的会话,构建角色相关的会话语料,并通过网络学习该图书同一作者类似作品中的角色信息、权威专家解读角色的信息等其他维度的信息来源,对角色模型进行完善,对于作者模型,使用权威专家解读作者的信息、作者自传等其他维度的信息来源,对角色模型进行完善,以此建立风格不同的角色模型和内容全面的作者模型,然后用户根据需要选择启动角色模型或作者模型。
17、优选的,所述步骤s3中,通过大模型对用户输入的语音进行学习,包括用户语音年龄分析,然后根据用户年龄对角色模型或者作者模型的语气、语速以及回答内容进行适龄处理,在用户与对话的角色进行语音交流时,根据对话角色和用户的请求query,在角色的会话语料中检索相似会话,用于角色的少样本学习,然后提供构建系统prompt,结合角色少样本语料,以及与用户的会话历史,重新组合构建成阅读助手prompt。
18、优选的,所述步骤s3中,当产生会话请求时,对会话query在图书数据库中进行相关性检索,将用户语音中提及的与角色相关的内容在图书数据库中找出,得到候选相关片段,当阅读助手prompt重新组合完成后,基于大模型能力,结合知识库相关片段和阅读助手prompt,生成符合该角色特点的会话应答,然后通过语音与用户进行应答,然后根据用户的请求将经过角色模型或者作者模型训练后反馈的语音内容进行输出,并不断地与用户进行会话应答,直到用户停止应答。
19、优选的,所述步骤s4中,根据对话角色和请求query,在与用户对话的过程中,进行自我学习和修正,通过语音识别对用户与阅读助手prompt对话时每一次问答进行记录,然后通过大模型进行归纳,其中出现频率最高的特征用作为下次相关回答内容,以提高用户满意度。
20、优选的,所述步骤s5中,通过语音识别来检索用户指令中与正在阅读的图书相关的所有游戏或应用,然后调用出指令中的具体游戏或应用,以提高用户使用的趣味性。
21、一种阅读用声控辅助装置,其适用于任意一项所述的一种阅读用声控辅助方法,包括:至少一个处理器和存储器;
22、所述存储器存储计算机执行指令;
23、所述至少一个处理器执行所述存储器存储的计算机执行指令,以实现如任意一项所述的一种阅读用声控辅助方法。
24、与现有技术相比,本发明的有益效果是:
25、1、本发明通过设置角色模型与作者模型,在不需要将书籍全部信息进行学习的前提下,很好地确定了书籍或其他阅读材料的风格,并且增加了专家解读等维度的训练素材,使得阅读助手输出内容的风格更加符合原著,不仅减少了计算量,缩短了计算时间,还能及时地对用户发出的指令进行反馈,提高了通过声控辅助阅读的效果,提高了阅读的乐趣;
26、2、本发明通过嵌入与图书相关的应用,使得阅读助手在回复用户时不再局限于文字,可以回复与书籍相关的小游戏,避免了在阅读时仅通过单纯的文字语音进行对话,提高了用户的阅读兴趣,增加了用户使用的趣味性。
- 还没有人留言评论。精彩留言会获得点赞!