一种轧钢模型钢族层别分类优化方法与流程
本发明涉及一种轧钢模型钢族层别分类优化方法,属于热轧带钢轧制过程控制领域。
背景技术
在热轧带钢生产过程中,钢族层别是热连轧过程控制模型最重要的基础配置数据之一,是热物性参数、工艺参数、模型参数与自适应参数最基本的索引号,对轧制过程控制具有重要影响。传统的钢族层别划分主要依据碳当量与人工经验确定。传统方法能够对钢种硬度的大类进行比较合理的区分,但对于同一大类中不同出钢记号的硬度差异不能进行细致分辨,经常出现划分不合理的情况,要么将本该分开的钢种归为一类,要么划分过细,导致轧制模型自适应效果大打折扣。尤其当钢种换层别轧制时问题突出,模型设定精度显著下降,影响轧机辊缝设定和轧制稳定性。为了更准确地划分钢族层别,需要采用更有效的分类方法。
技术实现要素:
本发明的目的在于提供一种轧钢模型钢族层别分类优化方法,以解决上述问题。
本发明采用了如下技术方案:
一种轧钢模型钢族层别分类优化方法,其特征在于,包括:
步骤一:针对某钢族层别中的各卷带钢,根据模型自适应后计算过程中获得的最新轧制过程实测数据,计算得到后计算的变形速率
变形速率计算公式如下:
其中,ε为后计算的变形程度;
变形抗力计算公式:
其中,kmpos为后计算的变形抗力;ai、bi为模型待定参数;t为推算的实测轧制温度;xi为带钢各化学成分的含量;
步骤二:对每卷热轧带钢,根据实测的轧制力反求“等效实测”的变形抗力kmact,计算公式如下:
其中,kmact为“等效实测”的变形抗力;fact为实测轧制力,wact为实测带钢宽度,
步骤三:在同一张图上绘制
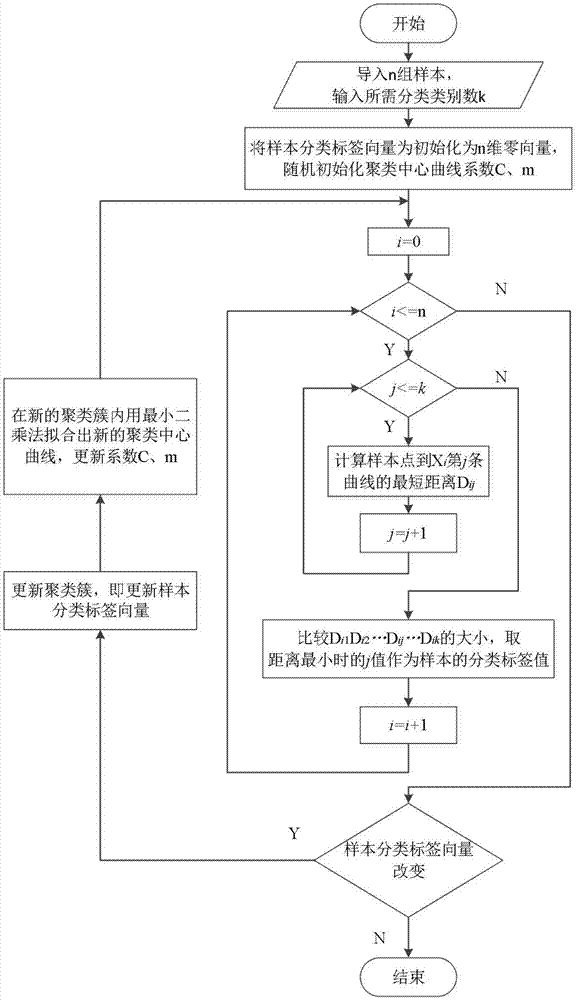
步骤四:针对钢族层别划分不合理的情况,采用一种新的线聚类算法来优化现有钢族层别的分类,确定需要划分到新层别的出钢记号,本发明的线聚类算法流程如图1所示,
(1)在数据集范围内随机初始化k条曲线作为聚类中心。由于变形抗力数据集存在
(2)计算所有样本点到这k条聚类中心线
对任意样本
1)计算xi到第j条聚类中心曲线
2)基于非线性最优化的一种算法——简单nelder-mead算法寻找dij的最小值mindij即为样本点xi到第j条聚类中心曲线的最短距离。
nelder-mead算法是求多维函数极值的一种单纯形算法。由于未利用任何求导运算,适合变元数不是很多的方程求极值。单纯形算法秉承“保证每一次迭代比前一次更优”的基本思想:先找出一个基本可行解,对它进行鉴别,看是否是最优解;若不是,则按照一定法则转换到另一改进后更优的基本可行解,再鉴别;若仍不是,则再转换,按此重复进行。因基本可行解的个数有限,故经有限次转换必能得出问题的最优解。点到曲线的距离实际上是点到曲线的最短路径,所以用nelder-mead算法可以方便求出其距离。
(3)采用最小二乘法分别对这k个簇的数据子集进行幂数曲线拟合,更新出c、m系数,即更新各聚类中心线,再重复步骤(2),直到前后两次迭代得到的聚类中心线一致停止迭代,完成聚类。
发明的有益效果
本发明基于积累的大量热连轧生产实测数据,采用聚类分析进一步优化现有的钢族层别分类,弥补了现有热轧模型钢族层别划分存在的不足。并且本专利提出的钢族层别分类优化方法已实际应用到宝钢1880、1580、梅钢1780等多个热连轧新建或改造项目中,提升了热轧模型钢族层别划分的精度,进而提升热轧带钢的模型设定精度与轧制稳定性,对热连轧新建或改造工程项目的模型调试、产品验证起到重要作用。
附图说明
图1是本发明提出的线聚类算法的流程图;
图2是某热连轧机组低碳钢变形抗力的分布;
图3分为两类的聚类结果;
图4分为三类的聚类结果。
具体实施方式
以下结合附图来说明本发明的具体实施方式。
本发明的轧钢模型钢族层别分类优化方法,步骤如下:
步骤一:针对某钢族层别中的各卷带钢,根据模型自适应后计算过程中获得的最新轧制过程实测数据,计算得到后计算的变形速率
变形速率计算公式如下:
其中,ε为后计算的变形程度;
变形抗力计算公式:
其中,kmpos为后计算的变形抗力;ai、bi为模型待定参数;t为推算的实测轧制温度;xi为带钢各化学成分的含量;
步骤二:对每卷热轧带钢,根据实测的轧制力反求“等效实测”的变形抗力kmact,计算公式如下:
其中,kmact为“等效实测”的变形抗力;fact为实测轧制力,wact为实测带钢宽度,
步骤三:在同一张图上绘制
步骤四、针对钢族层别划分不合理的情况,采用一种新的线聚类算法来优化现有钢族层别的分类,确定需要划分到新层别的出钢记号,
(1)在数据集范围内随机初始化k条曲线作为聚类中心。由于变形抗力数据集存在
(2)计算所有样本点到这k条聚类中心线
对任意样本
1)计算xi到第j条聚类中心曲线
2)基于非线性最优化的一种算法——简单nelder-mead算法寻找dij的最小值mindij即为样本点xi到第j条聚类中心曲线的最短距离。
nelder-mead算法是求多维函数极值的一种单纯形算法。由于未利用任何求导运算,适合变元数不是很多的方程求极值。单纯形算法秉承“保证每一次迭代比前一次更优”的基本思想:先找出一个基本可行解,对它进行鉴别,看是否是最优解;若不是,则按照一定法则转换到另一改进后更优的基本可行解,再鉴别;若仍不是,则再转换,按此重复进行。因基本可行解的个数有限,故经有限次转换必能得出问题的最优解。点到曲线的距离实际上是点到曲线的最短路径,所以用nelder-mead算法可以方便求出其距离。
(3)采用最小二乘法分别对这k个簇的数据子集进行幂数曲线拟合,更新出c、m系数,即更新各聚类中心线,再重复步骤(2),直到前后两次迭代得到的聚类中心线一致停止迭代,完成聚类。
下面以宝钢1880热连轧机组的某钢族层别为例来进行说明。选取1880生产的某低碳钢所在钢族层别的3000条带钢数据,此钢族层别的代码设为1001。根据步骤一至步骤三的操作流程获得如图2所示的散点图。由图2可见:“变形速率-变形抗力”数据散点图存在两块分割比较明显的分布区域,表明该钢族层别中存在差异较为明显的多个类别,需要进一步细分钢族层别。
下面应用本专利技术对模型钢族层别分类进行优化。热轧带钢变形抗力与变形速率之间存在近似幂函数关系,存在关系式:
其中,c与m均为待定参数。
为了便于分析过程的描述,下面只取后计算的“变形速率-变形抗力”数据来进行说明。变形抗力数据
对图2中后计算的“变形速率-变形抗力”数据集
如图3所示,原数据集在图上被明显分为两类,“·”形数据点均匀分布在线条为实线的聚类曲线cluster_line1:
进一步追踪这些数据点所对应的出钢记号,发现“·”形数据点主要为an0691d1、ap0740d5和dp0161d1等出钢记号,“×”形数据点主要为ap1055e5等出钢记号。
由图4可见,原数据集在图上被明显分为三类。其中,“·”形数据点均匀分布在线条为实线的聚类曲线cluster_line1:
进一步追踪对应的出钢记号发现:“·”形数据点主要为dp0161d1等出钢记号,“×”形数据点主要为an0691d1等出钢记号,“◆”形数据点为ap1055e5等出钢记号。
分析表明,同属于原钢族层别代码1001中的ap1055e5、an0691d1和dp0161d1等几个出钢记号中,ap1055e5的变形抗力显著高于an0691d1和dp0161d1,而dp0161d1的变形抗力要稍微低于其它钢种。为了提高轧制力模型的预报精度,需要将ap1055e5划分到新的钢族层别。对于dp0161d1,由于和an0691d1差别还不是很大,可以继续保留在原来的层别。
本专利提出的钢种层别分类优化方法已应用到宝钢1880、宝钢1580、梅钢1780等多个热连轧工程项目中,对热连轧新建或改造工程项目的模型调试、达标达产和产品验证起到重要作用。
- 还没有人留言评论。精彩留言会获得点赞!