基于PCA与自编码器的数控机床刀具磨损数据处理方法与流程
本发明属于数控加工刀具磨损监测技术领域,尤其涉及一种基于pca与自编码器的数控机床刀具磨损数据处理方法。
背景技术:
目前,最接近的现有技术:刀具磨损严重影响加工效率、工件质量和加工成本,是个不容忽视的问题,它对切削质量有着重大的影响,如能很好地预测刀具加工后的磨损状态,则能大大提高切削质量,避免了刀具在加工过程中报废,对保证加工质量和提高生产率具有重要意义。通常情况下,刀具磨损量难以直接测量,需要用到较为精密的仪器和复杂的测量方式,因此,采用间接预测方法已经成为一种常用的方法。通常,加工过程中的振动、切削力和声音信号中隐藏着刀具磨损的相关信息,因此被用于监控或者预测刀具的磨损状态。
目前,刀具磨损状态的预测方法大都属于基于数据驱动的预测方法。基于数据驱动的方法主要在于构建预测模型,对加工过程中的运行数据进行挖掘,得到运行数据与刀具磨损之间的隐含联系,进而实现预测。常用的模型包括支持向量机、隐马尔可夫模型、卷积神经网络、bp神经网络、长短期记忆网络和门控循环单元等。
在监测刀具磨损时,根据工作场合采用多种传感器来检测刀具的使用情况,在现有技术上,通常使用单一传感器信号的某种特征参数来表示刀具磨损状态,监测的准确性受限于某一传感器的精度,不能很好地检测刀具磨损状态。在实际情况,对传感器信息进行数据预处理、特征提取主要依赖于技术人员的信号处理技术和诊断经验,应用范围较小。
现有的基于数据驱动的方法在数控机床刀具磨损已经成为了常用的预测方法。但这类方法存在这一定的局限性,比如模型的数据处理能力不强导致预测精度低和应用性不广泛等问题。综上所述,提出一种预测精度高、应用范围广的预测模型是非常重要的。
综上所述,现有技术存在的问题是:现有的基于数据驱动的方法在数控机床刀具磨损存在这一定的局限性,模型的数据处理能力不强导致预测精度低和应用性不广泛等问题。
解决上述技术问题的难度:摆脱专家经验和人为因素的束缚,使算法模型能够自动提取特征。
解决上述技术问题的意义:现有技术应用性不广泛,大多依赖于人工提取特征,本发明旨在提出一种自适应的特征提取方法。
技术实现要素:
针对现有技术存在的问题,本发明提供了一种基于pca与自编码器的数控机床刀具磨损数据处理方法。
本发明是这样实现的,一种基于pca与自编码器的数控机床刀具磨损数据处理方法,所述基于pca与自编码器的数控机床刀具磨损数据处理方法包括:
第一步,获取具有刀具磨损量标签的训练数据和待测试数据,对数控机床上刀具传感器采集的数据进行归一化,得到具有刀具磨损量标签的训练数据和待测试数据;
第二步,构建具有刀具磨损量标签的刀具磨损特征数据集,利用主成分分析法对所得到具有刀具磨损量标签的训练数据进行数据融合;将融合后的数据输入到堆栈自编码器进行训练,得到具有刀具磨损量标签的影响刀具磨损特征数据集;
第三步,构建并训练基于bp神经网络的刀具磨损预测模型,构建基于bp神经网络的刀具磨损预测模型并进行训练,对训练完成的bp神经网络模型进行预测。
进一步,所述第二步中利用主成分分析法对所得到具有刀具磨损量标签的训练数据进行数据融合包括以下步骤:
(1)将具有刀具磨损量标签的训练数据集组合成归一化传感器数据矩阵q;
(2)中心化数据矩阵q得到矩阵q*,再对矩阵q*进行转置得到矩阵(q*)t;
(3)根据矩阵q*和矩阵(q*)t计算相关系数矩阵r,令矩阵r的特征值从大到小排列为λ1,λ2,…,
(4)令矩阵r的特征值个数j=1,令主成分个数m=1;
(5)计算m个主成分的累计方差贡献率,数据融合的结果;
(6)判断数据融合的结果是否大于95%,若是,则利用m个主成分构成特征数据库,若否,则令j=j+1,返回(4)。
进一步,所述第二步将融合后的数据输入到堆栈自编码器进行训练,得到具有刀具磨损量标签的影响刀具磨损特征数据集包括以下步骤:
(1)初始化自编码器的参数,包括:自编码器输入神经元个数p,p=m,自编码器隐藏层层数n,稀疏性参数ρ,自编码器学习率α,训练批次numepochs,每训练批次的训练数据大小batchsize;
(2)利用得到的特征数据库作为输入训练第一个自编码器,训练得到的权重参数w和偏置参数b作为堆栈自编码器输入层和第一层的权重和偏置;
(3)将训练得到的隐含层,作为第二个自编码器的输入层进行训练,训练得到的权重参数w和偏置参数b作为堆栈自编码器第一层和第二层的权重和偏置;
(4)得到各层间的偏置与权重,完成对堆栈自编码器的训练,得到堆栈自编码器最后一层的输出作为影响刀具磨损的特征数据集。
进一步,所述第三步构建基于bp神经网络的刀具磨损预测模型的方法包括:
(1)建立bp神经网络模型,包括输入层、隐藏层和输出层的三层bp神经网络,在此模型中,输入层为堆栈自编码器的输出层,输出层单元数为1,输入层单元表示影响刀具磨损的特征,输出层单元是刀具的磨损值,隐藏层单元数是经公式推算确定,通过以下经验公式
(2)训练bp神经网络,bp神经网络隐藏层神经元的传递函数为sigmoid函数,输出层神经元的传递函数为relu函数,用于输出网络的预测结果,训练函数采用梯度下降算法,初始权值选为[0,1]之间的随机数;随机选取一部分影响刀具磨损的特征数据集进行训练,已建立的bp神经网络通过不断改善bp神经网络模型中的权值和阈值,直到收敛,完成训练。
进一步,所述第三步对训练完成的bp神经网络模型进行预测的方法包括:给定相应的预测传感器数据,得到影响刀具磨损的特征数据集,然后再通过bp神经网络模型计算后,输出层的值即为预测结果。
本发明的另一目的在于提供一种应用所述基于pca与自编码器的数控机床刀具磨损数据处理方法的数控加工刀具磨损检测系统。
本发明的另一目的在于提供一种应用所述基于pca与自编码器的数控机床刀具磨损数据处理方法的信息数据处理终端。
综上所述,本发明的优点及积极效果为:本发明通过pca和sae对数据进行处理得到特征数据库,之后将特征数据库输入到bp神经网络进行训练得到刀具磨损预测模型,不仅有效的提升了模型的预测能力,也使模型的应用范围更加广泛,经过调整可以广泛应用于各种数控机床刀具的磨损预测。本发明通过pca和sae处理数据的方法,能充分挖掘输入数据中的重要特征,然后将得到的数据特征输入到bp神经网络中,利用bp神经网络的拟合能力,将提取的特征映射到预测结果上,实现数控机床刀具磨损的预测。通过上述两种方法的结合,能充分发挥各自的独特作用,实现单个神经网络不能实现的效果,单个神经网络需要的数据量大,常用于解决分类问题,在解决回归问题的时候虽然能拟合任意直线,但是会存在过拟合现象而导致泛化能力不强;本发明在特征层面先利用主成分分析对数据进行降噪,再用自编码器学习数据中的潜在特征,再借由神经网络的拟合能力对特征进行映射来预测刀具磨损;特点是对于不同类型的数据都能先发掘特征再进行预测,相比单个神经网络而言,输入数据有一定的趋势性,对不同类型的数据可以取得比单个神经网络较好的成果。
与现有技术与方法对比,本发明具有以下优势:
本发明提出的基于pca-sae的刀具磨损预测方法有机结合了pca、sae和bp三种神经网络,充分发挥了各自的优势。相比于单种网络,本发明具有更强的特征提取能力,能充分挖掘输入数据中的特征,提高模型的预测能力。
本发明考虑到了数控机床加工过程中多传感器信号的数据特征,充分挖掘了传感器信号的特征,操作简单,适用性广,能广泛应用到各种数控机床刀具的磨损预测中。在数控加工刀具磨损状态预测领域,本发明首次提出由pca-sae和bp神经网络处理加工数据的方法,本发明具有较强的创新型和实用性。
附图说明
图1是本发明实施例提供的基于pca与自编码器的数控机床刀具磨损数据处理方法流程图。
图2是本发明实施例提供的基于pca与自编码器的数控机床刀具磨损数据处理方法实现流程图。
图3是本发明实施例提供的sae模型图。
图4是本发明实施例提供的bp神经网络模型图。
图5是本发明实施例提供的本发明和单个bp神经网络进行刀具磨损预测,得到的结果示意图;
图中:(a)利用单个bp神经网络得到的结果;(b)为用本发明方法得到的结果。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
针对现有技术存在的问题,本发明提供了一种基于pca与自编码器的数控机床刀具磨损数据处理方法,下面结合附图对本发明作详细的描述。
如图1所示,本发明实施例提供的基于pca与自编码器的数控机床刀具磨损数据处理方法包括以下步骤:
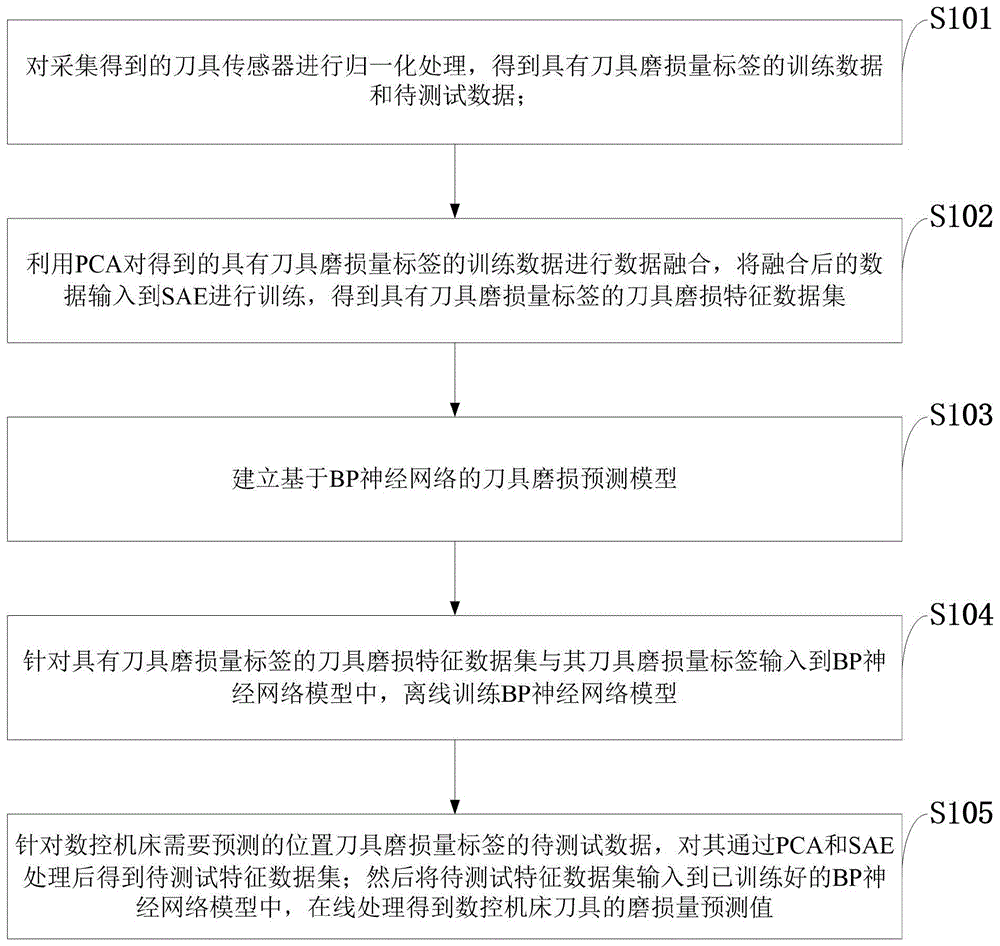
s101:对采集得到的刀具传感器进行归一化处理,得到具有刀具磨损量标签的训练数据和待测试数据;
s102:利用pca对得到的具有刀具磨损量标签的训练数据进行数据融合,将融合后的数据输入到sae进行训练,得到具有刀具磨损量标签的刀具磨损特征数据集;
s103:建立基于bp神经网络的刀具磨损预测模型;
s104:针对具有刀具磨损量标签的刀具磨损特征数据集与其刀具磨损量标签输入到bp神经网络模型中,离线训练bp神经网络模型;
s105:针对数控机床需要预测的位置刀具磨损量标签的待测试数据,对其通过pca和sae处理后得到待测试特征数据集;然后将待测试特征数据集输入到已训练好的bp神经网络模型中,在线处理得到数控机床刀具的磨损量预测值。
在本发明的优选实施例中,根据磨损量值对数控机床刀具进行更换或者修复处理。
在本发明的优选实施例中,步骤s102利用pca对得到的具有刀具磨损量标签的训练数据进行数据融合,将融合后的数据输入到sae进行训练,得到具有刀具磨损量标签的刀具磨损特征数据集具体如下:
步骤一,将具有刀具磨损量标签的训练数据集组合成归一化传感器数据矩阵q;
步骤二,中心化数据矩阵q得到矩阵q*,再对矩阵q*进行转置得到矩阵(q*)t;
步骤三,根据矩阵q*和矩阵(q*)t计算相关系数矩阵r,令矩阵r的特征值从大到小排列为λ1,λ2,…,
步骤四,令矩阵r的特征值个数j=1,即令主成分个数m=1;
步骤五,计算m个主成分的累计方差贡献率,即数据融合的结果;
步骤六,判断数据融合的结果是否大于95%,若是,则利用m个主成分构成特征数据库,若否,则令j=j+1,返回步骤四;
步骤七,初始化自编码器的参数,包括:自编码器输入神经元个数p,p=m,自编码器隐藏层层数n,稀疏性参数ρ,自编码器学习率α,训练批次numepochs,每训练批次的训练数据大小batchsize;
步骤八,利用所得到的特征数据库作为输入训练第一个自编码器,训练得到的权重参数w和偏置参数b作为堆栈自编码器输入层和第一层的权重和偏置;
步骤九,将步骤二中训练得到的隐含层,作为第二个自编码器的输入层进行训练,训练得到的权重参数w和偏置参数b作为堆栈自编码器第一层和第二层的权重和偏置;
步骤十,依此类推,得到各层间的偏置与权重,完成对堆栈自编码器的训练,得到堆栈自编码器最后一层的输出作为影响刀具磨损的特征数据集。
在本发明的优选实施例中,步骤s103的bp神经网络模型构建方法为:建立bp神经网络模型,包括输入层、隐藏层和输出层的三层bp神经网络,在此模型中,输入层为堆栈自编码器的输出层,输出层单元数为1,输入层单元表示影响刀具磨损的特征,输出层单元是刀具的磨损值,隐藏层单元数是经公式推算确定,通过以下经验公式
下面结合测试对本发明的技术效果作详细的描述。
本发明实施例使用的数据来自加州大学伯克利分校的best实验室提供的铣削数据集,该数据集代表了铣床在各种工况下的运行实验,为研究刀具的磨损,分别采用声发射传感器、振动传感器、电流传感器三种不同类型的传感器采集不同位置的数据。数据集中包含16种不同运行次数的情况,记录了刀具从开始运行到达到磨损极限时间内的不同传感器数据。
选择同一工况下的数据划分训练集和测试集,分别就本发明所述的步骤和单个bp神经网络进行刀具磨损预测,得到的结果如下,图5(a)为利用单个bp神经网络得到的结果,图5(b)为用本发明方法得到的结果.
根据结果对比可以看出,本发明所提出的方法对刀具磨损的预测相比于利用单个bp神经网络得到的结果而言更加贴近刀具磨损的真实值,能较好的反映刀具磨损情况。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!