一种识别HLA‑A2/RMFPNAPYL的单域抗体的制作方法
本发明属于抗体技术领域,特别涉及一种识别hla-a2/rmfpnapyl的单域抗体及应用。
背景技术:
wilms瘤基因(wt1)于1990年由call、bonetta、gessler等3个研究小组分别用不同的方法在wilms瘤中发现并克隆,该基因定位于人染色体11p13,在正常组织中表达,在多种肿瘤中高表达。研究表明wt1是一种多功能转录调控因子,可调节与生长分化有关的生长因子及受体,如胰岛素样生长因子(igfs)、胰岛素样生长因子1受体(igf1r)、血小板衍生生长因子a(pdgfa)、表皮生长因子(egf)、单核巨噬细胞集落刺激因子(m-csf)、多药耐药基因1(mdr1)等,wt1通过影响其转录而产生多种生学效应,涉及细胞生长、分化及凋亡等(toskaeetal:biochemj,1:15,2014)。
研究发现几乎所有的白血病原始细胞(无论系别)都持续过表达wt1基因,与其在极少数生理性造血干细胞(cd34+)中短暂低表达形成鲜明对比。wt1对造血的作用表现为在急性白血病一个子集中的异常表达或突变,通过与各种造血调控因子相互作用调节其转录,从而参与造血细胞的增殖、分化、凋亡等白血病的形成过程。国外研究发现,80%以上的恶性黑色素瘤中wt1基因高表达,下调wt1基因可以抑制恶性黑素瘤细胞增殖、转移,促进细胞凋亡。loeb等研究发现wt1在90%的原发性乳腺癌中高表达,且出现wt1启动子甲基化过程,而在正常乳腺上皮组织中则低表达(loebdmetal:cancerres,3,921,2001)。由此表明,wt1蛋白质可以作为一个新的过度表达的肿瘤抗原。
oka等第一次将超表达的肿瘤抗原wt1作为mhc工类抗原限制性ctls作用的靶分子,用于t细胞介导的白血病免疫治疗(okay,stal:currentcancerdrug,2002)。他们选择并合成了4种来源于wti蛋白并含有hla-a2分子结合锚位的九聚肽链,db126肽段、wh187肽段、db235肽段(cmtwnqmnlresidues235-243)和wh242肽段(nlgatlkgvresidus242-250),结果证明其中两种肽段db126和wh187被证实在体外能与hla-a2分子结合,诱导产生wt1肽特异性ctl。
car-t虽然在治疗cd19阳性血液瘤取得不错的成绩,但抗体靶向的car无一例外地只能靶向这些表达在肿瘤细胞表面的抗原,而众多肿瘤相关抗原都是仅表达在细胞内部。tcr虽然既能识别胞外抗原也能识别通过抗原加工递呈至细胞表面的胞内抗原,但tcr通常需要从t细胞克隆中分离出特异性的αβtcr基因,难度较大,重复性不高。此外,转基因tcr还有tcr错配带来的潜在安全隐患,外源tcr的两条链可能会和内源tcr亚基发生错配,组合成新的tcr。这种错配的tcr会形成未知的特异性,可能会靶向正常组织,导致严重的移植物抗宿主反应。ochi等将抑制内源性tcr的sirna整合于表达外源识别w抗原的tcr表达框中,用于修饰t细胞,开展针对白血病的过继治疗,证实在内源tcr被抑制状态下表达识别wt1转基因tcr的t细胞具有更强的抑制肿瘤功能。
如果能制备出识别mhc多肽复合物的抗体分子,并表达至细胞表面,就可以将t细胞免疫和成熟的抗体技术相结合,开发出一种兼具抗体和t细胞优势的新型t细胞修饰治疗技术。作为这类技术的先驱,巴斯德研究所的kourilsky实验室早在1993年就成功地制备出单克隆抗体,能特异性识别和mhci类分子结合的t细胞表位多肽。两年后,丹麦技术大学andersen等使用噬菌体展示技术,获得可特异性识别流感病毒多肽的抗体,并可抑制相应病毒的感染。美国国立卫生研究院的germain研究组,使用hla-a2转基因小鼠,获得分泌识别ova经抗原加工的主导多肽h-2kb复合物的抗体的杂交瘤细胞。这种具有tcr特异性的抗体被用来定位、定量特异性多肽与mhc分子复合物,为研究抗原加工与递呈的机制提供了新的工具。
这类识别多肽mhc复合物的抗体,因具有t细胞受体功能,被称作tcr-like抗体,有时也叫做tcr-mimic抗体。本专利将这类具有mhc多肽复合物特异性的抗体命名为mar(mhcantigenreceptor),以便和修饰t细胞的car-t及tcr-t相区别。
mar作为新型的识别mhc多肽复合物的分子与car相比,因具有天然t细胞受体的功能,沿用生命进化过程中获得的自我异体识别机制,即可识别肿瘤胞外抗原,也可识别通过抗原加工形成的肿瘤内抗原,因而具有更广泛的应用,尤其针对实体瘤抗原,具有得天独厚的优势。和tcr相比,mar转入t细胞后,不存在与内源性tcr亚基错配的问题;而且作为抗体,比天然tcr具有与生俱来更高的亲和力,mar可能成为最有发展前途的修饰t细胞用于肿瘤治疗的一类分子。
文献中报导的大多数产生的mar分子基本上局限于在细胞水平上特异性识别mhc复合物或用于推测这些复合物,证明其实际应用的文献不多。willensen等将mage-a1多肽特异性,hla-a1限制性的mar用反转录病毒武装t细胞后,证明mar-a1具有特异性识别hla-a1/mage-a1双阳性黑色素瘤细胞,诱导t细胞释放干扰素,并在体外特异性杀伤这些黑色素瘤细胞,首次证实这类抗体的生物学功能(chamespetal:pans2000,97(14):7969-74)。在此基础上,gao等将mar连接跨膜蛋白片段及zeta链胞内信号片段后,成功武装nk或t细胞,这种mar-nk/mar-t不但能杀伤hla-a2阳性黑色素瘤细胞,而且可以抑制人黑色素瘤在免疫缺陷小鼠体内的生长(zhangg1etal:immunolcellbiol2013,91(10):615-24,zhangg2etal:scirep2014,4:3571)。首次证实mar修饰效应细胞可以抑制肿瘤细胞在动物体内的生长,为进一步开展临床研究用于治疗癌症打下了基础。
wt1(126)(rmfpnapyl)是来源于肾母细胞瘤的hla-a2限制型优势表位(以下hla-a2/wt1(126)(rmfpnapyl)均简写为hla-a2/rmfpnapyl。wt1是一个公认的与肾母细胞瘤直接相关的抑癌基因,其在白血病、淋巴瘤和各类实体瘤中有过表达。基于识别这一有效的肿瘤靶标的tcr和mar均在临床前研究中表现突出,us9074000专利文献报告采用噬菌体展示scfv文库,筛选出可特异性识别hla-a2/rmfpnapyl复合物的scfv抗体。这种抗体可特异性结合用rmfpnapyl多肽装载的t2细胞,还可以结合hla-a2及wt1阳性的白血病细胞系bv173jmn。采用scfv获得的信息制备出完整的全人抗体。可以该上述细胞,诱导adcc,并可抑制这些肿瘤细胞的生长。zhao等采用噬菌体展示获得识别hla-a2/rmfpnapyl的抗体,进一步突变后,通过酵母展示及流式分选技术,获得亲和力提高10倍的scfv(kd=3nm)。用这种scfv制备的carz分子武装t细胞,可特异性杀伤hla-a2阳性及wt1阳性的bv173白血病细胞,并抑制这种肿瘤细胞在免疫缺陷小鼠体内的生长。
单域抗体仅含有抗体重链的一个可变区,是最小的全功能性的抗原结合片段,免疫原性较弱;更易通过血管壁,穿透实体瘤,有利于肿瘤的治疗。
技术实现要素:
本发明针对现有技术中存在的技术问题,提供一种识别hla-a2/rmfpnapyl的单域抗体,筛选得到的单域抗体能特异性的结合rmfpnapyl抗原与hla-a2的复合物,可开发成治疗肿瘤的抗体药物及其他有有益效果生物治疗产品。
本发明采用的技术方案是:
一种识别hla-a2/rmfpnapyl的单域抗体,所述单域抗体的氨基酸序列包括
互补决定区cdr1为seqidno.1,cdr2为seqidno.2和cdr3为seqidno.3;
或,所述单域抗体的氨基酸序列包含cdr1为seqidno.4,cdr2为seqidno.5和cdr3为seqidno.6;
或,所述单域抗体的氨基酸序列包含cdr1为seqidno.7,cdr2为seqidno.8和cdr3为seqidno.9;
或,所述单域抗体的氨基酸序列包含cdr1为seqidno.10,cdr2为seqidno.11和cdr3为seqidno.12;
一种识别hla-a2/rmfpnapyl的单域抗体,所述抗体为scfv或fc融合蛋白或完整抗体的一部分。
一种识别hla-a2/rmfpnapyl的单域抗体,所述抗体为单区抗体、或重链变区、轻链变区。
一种识别hla-a2/rmfpnapyl的单域抗体,所述抗体氨基酸序列为seqidno.13,seqidno.14,seqidno.15,seqidno.16。
一种识别hla-a2/rmfpnapyl的单域抗体,所述单域抗体包含所述互补决定区(cdr)中的一个或者两个以上的氨基酸序列,且至少与一个氨基酸序列最低具有79%同源性。
一种识别hla-a2/rmfpnapyl的单域抗体,所述单域抗体的氨基酸序列包含权利要求4中所述框架(fr,单域抗体除cdr以外的氨基酸序列)中的一个或者两个以上的氨基酸序列,且至少与一个氨基酸序列最低具有90%同源性。
一种融合蛋白,使用上列氨基酸序列与至少包含一个具治疗功能的多肽制备的融合蛋白。
一种融合蛋白,使用上列氨基酸序列与cd3抗体融合制备出来的融合蛋白,其氨基酸序列为seqidno.17。
一种融合蛋白,所述融合蛋白可以由各具有识别功能的多肽直接融合,也可以是通过接头肽连接的含1个或1个以上的识别功能多肽分子的融合蛋白。
一种多特异或多功能分子,上述的任一单域抗体为该多特异或多功能分子的一部分。
一种核酸分子,编码为上述的多肽分子。
一种载体,包含上述的核酸序列,由于遗传密码子具有兼并性,该核酸序列可以根据不同的应用目的而不同。
一种核酸分子表达的蛋白质,其核苷酸序列或者至少部分序列可以通过合适的表达系统进行表达,以得到相应的蛋白质或多肽;上述表达系统包括细菌,酵母菌,丝状真菌,哺乳动物细胞,昆虫细胞,植物细胞,或无细胞表达系统。
一种宿主细胞,包含可表达上述的单域抗体、融合蛋白、多特异或多功能分子、核酸分子、载体或蛋白质或多肽的宿主细胞。
与现有技术相比,本发明所具有的有益效果是:本发明合成人源噬菌体抗体文库,并通过三轮淘选,最终筛选到高亲合力的抗体。这些单域抗体均表现独特的识别能力,仅识别由由来自wt1的特异性多肽rmfpnapyl与hla-a2形成的复合物,而和其他对照多肽形成的复合物没有结合。这种特异性单域抗体不仅识别人工合成的hla-a2/rmfpnapyl复合物,而且可以结合天然抗原加工的,表达在肿瘤细胞表面的hla-a2/rmfpnapyl复合物,为进一步开发治疗肿瘤的生物制剂打下了基础。
附图说明
图1a为三轮淘选后第一板elisa检测;elisa所有孔均包被抗原hla-a2/rmfpnapyl,与淘筛的单个克隆噬菌体结合后,加入标记hrp的抗噬菌体的二抗。
图1b为三轮淘选后第一板elisa检测数据分析;纵坐标为各孔在650nm下的光吸收值,横坐标为96个孔。
图2a为三轮淘选后第二板elisa检测;elisa所有孔均包被抗原hla-a2/rmfpnapyl。
图2b为三轮淘选后第一板elisa检测数据分析;纵坐标为各孔在650nm下的光吸收值,横坐标为96个孔。
图3a为四种不同序列的hla-a2/rmfpnapyl单域抗体对不同抗原的elisa检测;酶标板a、b两行包被抗原hla-a2/itdqvpfsv,c、d两行包被抗原hla-a2/nlvpmvatv,e、f两行包被抗原hla-a2/rmfpnapyl,g、h两行包被抗原hla-a2/sllmwitqc;line1为m5-h1,line2为ma对照;line3为m4对照;line4为m5-g3;line5为m5-f4;line6为阴性对照mb;line7为m5-c3。
图3b为四种不同序列的hla-a2/rmfpnapyl单域抗体对不同抗原的elisa检测数据分析;纵坐标为650nm下的光吸收值;横坐标1,2,3,4分别为四种抗原hla-a2/itdqvpfsv,hla-a2/nlvpmvatv,hla-a2/rmfpnapyl,hla-a2/sllmwitqc。a、b、c、d、e、f、g分别为m5-h1、ma对照、m4对照、m5一g3、m5-f4、mb对照、m5-c3。
图4为pet22b中表达的单域抗体纯化后的还原sds-page;marker的条带从小到大依次为14,25,30,40,50,70,100,120,160kd。line1为m5-h1,line2为m5-g3,line3为m5-f4。
图5为pet22b中单域抗体融合表达fc的质粒图谱示意图;单域抗体与fc之间通过linker(g4s)连接。
图6为pet22b中m5-h1-fc融合蛋白纯化后的还原sds-page;marker的条带从小到大依次为14,25,30,40,50,70,100,120,160kd。line1为还原态的m5-h1-fc。
图7为pcdna3.1中单域抗体融合表达fc的质粒图谱示意图;单域抗体与fc之间通过限制性酶连接,且单域抗体前有信号肽以及kozak序列。
图8为m5-f4与fc融合蛋白纯化后的sds-page的还原及非还原电泳图;marker的条带从小到大依次为14,25,30,40,50,70,100,120,160kd。line1和line2分别为还原态m5-f4-fc和非还原态m5-f4-fc。
图9为三种单价单域抗体对不同抗原的特异性检测数据分析;纵坐标为650nm下的光吸收值,横坐标1,2,3,4为四种抗原hla-a2/itdqvpfsv,hla-a2/nlvpmvatv,hla-a2/rmfpnapyl,hla-a2/sllmwitqc。三个样品分别为单价抗体m5-h1,m5-g3,m5-f4。
图10为两种fc融合抗体对不同抗原的特异性检测以及数据分析图;纵坐标为650nm下的光吸收值,横坐标1,2,3,4分别为四种抗原hla-a2/itdqvpfsv,hla-a2/nlvpmvatv,hla-a2/rmfpnapyl,hla-a2/sllmwitqc。两个样品为m5-h1-fc,m5-f4-fc。
图11为facs检测m5-f4-fc融合蛋白在细胞水平对hla-a2/rmfpnapyl的特异性识别;阴性对照1(negative)为bv-173细胞不加一抗只加二抗山羊抗人fc(fitc),阴性对照2(bm)为bv-173细胞加不结合hla-a2/rmfpnapy的fc融合蛋白bm以及二抗,实验组(m5-f4)为bv-173细胞加m5-f4-fc融合蛋白以及二抗。
图12为融合蛋白m5-h1-fc与hla-a2/rmfpnapyl复合物分子间相互作用及亲和力常数测定图;横坐标为时间,纵坐标为分子间相互结合的响应值(ru),1为参比通道,2为实验通道。
图13为融合蛋白m5-f4-fc与hla-a2/rmfpnapyl复合物分子间相互作用及亲和力常数测定图;横坐标为时间,纵坐标为分子间相互结合的响应值(ru),1为参比通道,2为实验通道。
图14为单域抗体融合蛋白在细胞水平上的特异性识别和杀伤,横坐标为抗体m5-h1-anticd3的浓度,纵坐标为杀伤效率。
具体实施方式
为使本领域技术人员更好的理解本发明的技术方案,下面结合附图和具体实施例对本发明作详细说明。
实施例1筛选hla-a2/rmfpnapyl复合物的单域抗体
1.1单域抗体噬菌体文库制备
1.1.1辅助噬菌体(bm13)的制备
将m13ke噬菌体复制子用alwni和afei双酶切,同时人工合成基因片段也用alwni和afei双酶切,然后用t4连接酶连接在一起。连接后转染tg1得到辅助噬菌体bm13。如此,原复制子中
tctggtggtggttctggtggcggctctgagggtggtggctctgagggtggcggttctgagggtggcggctctgagggaggcggttccggtggtggctct序列被人工合成基因序列所取代,即在噬菌体giii编码区域,添加了胰蛋白酶切割序列,一旦用作辅助噬菌体时,增加胰蛋白酶消化步骤,减少不含融合目的基因蛋白噬菌体的数目。
人工合成基因序列如下:
ccagccggcctttctgaggggtcgactatagaaggacgaggggcccacgaaggaggtggggtacccggttccgagggt
1.1.2噬菌体文库构建
1.1.2.1载体构建
将puc19用hindiii和ndei双酶切,加入基于dp47抗体序列的重链人工单域抗体序列。单域抗体表达框架中,单域抗体与giii蛋白融合,中间加入myc和vsv-g标签,用于纯化或鉴定,构建成噬菌体展示载体pbg3。
1.1.2.2ssdna模板制备
大肠杆菌菌株cj236缺乏功能性dutpase和uracil-nglycosylase,可以产生尿嘧啶化单链dna模板。将pbg3质粒转染进入cj236并涂布在含carbenicillin(50μg/ml)和chloramphenicol(15μg/ml)琼脂平板上,培养过夜。挑选平板上筛选出的单个菌落到3ml2×ty肉汤培养基中(含上述同样浓度的双抗),37℃250rpm条件下培养过夜。次日取0.3ml过夜培养物加入30ml新鲜2×ty肉汤培养基中(carbenicillin50μg/ml),持续3-4小时培养,使od600=0.4-0.6,加入辅助噬菌体(按细菌:噬菌体个数比1∶10加入),37℃150rpm1小时,离心,将细菌沉淀重悬于60ml2×ty双抗培养基中,25℃250rpm培养22小时,离心弃沉淀。含噬菌体的上清液用5%peg(peg8000和300mmnacl调至浓度为5%)沉淀,然后重悬于pbs中,使用qiaprepspinm13试剂盒制备出ssdna。
1.1.2.3文库制备
文库制备用kunkel方法制备(kunkelta:pnas82:488,1985)cdr突变寡核苷酸链按下表合成:
olig_cdr1
ctgcgtctctcctgtgcagcctccggakwtansnttancnmtnasdhtrscnnttgggtccgccaggctccagggaa
olig_cdr2
gggtctagagtgggtatcarscnnkrnsvvwcgtagcggtagcacatactacgcagactccgtg
olig_cdr3a
gacaccgcggtatattattgcgcggrswnvsthtnnknnknnknnknnknnknnknnknnknnknnknnknnknnktggggtcagggaaccctggtcaccgtc
olig_cdr3b
cgaggacaccgcggtatattattgcgcggrswnvsthtnnknnknnknnknnknnknnknnknnktggggtcagggaaccctggtcaccgtcacc
寡核苷酸链的磷酸化
将人工合成的寡核苷酸链加入下列100ul50mmtris-hcl(用盐酸调ph至7.5),ph7.5含下列成份体系中:5ut4多核苷酸激酶,10mmmgcl2;1mmatp及5mmdtt,37℃1小时后,磷酸化好的的寡核苷酸链用pcr纯化试剂盒纯化。
磷酸化寡核苷酸与ssdna退火结合
将磷酸化寡核苷酸和uracilatedssdna(磷酸化寡核苷酸:ssdna=3∶1,ssdna由1.1.2.2中制备所得)溶于含10mm,mgcl2的50mmtris-hcl,ph7.5缓冲液中,90℃2分钟后,降至25℃(每分钟降低1℃/min)。
dsdna合成
将下述材料加入退火结合的磷酸化寡核苷酸与ssdna复合物中:0.55mmatp;0.8mmdntps;5mmdtt;15ut4dna合成酶及15ut7dna合成酶,
20℃3小时后,用qiaquickpcr纯化试剂盒纯化。将纯化后的dna待转化至电转感受态tg1中。
1.2bm13辅助噬菌体以及噬菌体文库的增值
bm13辅助噬菌体的增值
从基本琼脂培养基平板上挑取一个大肠杆菌tg1的新鲜单菌落,接种到20ml2×ty培养基中,温和摇动,37℃培养至od600约为0.8备用。将1.1.1中制备的原始bm13辅助噬菌体用2×ty培养基制备一系列10倍稀释的bm13噬菌体。各稀释度分别取10μl与200μltg1(od600=0.8)菌液混匀,振荡器温和震荡3s,并与上层琼脂培养基混匀,倾倒在预先平衡室温的ty平板上。转动平板以确保菌体和上层琼脂分布均匀。待上层培养基凝固后,于37℃生化培养箱倒置培养过夜。
次日挑选分离良好的单个噬菌体接种于装有2~3ml含25μg/ml卡那霉素的2×ty培养基的15ml培养管中。37℃,250rpm震荡培养12~16小时。将感染上清液转移至1.5ml无菌微量离心管,在微量离心机上,以最大转速,4℃离心2分钟。上清液转移至新管中4℃保存。
噬菌体文库的增值
将制备好的噬菌体文库接种至100ml含60μg/ml氨苄青霉素的2×ty培养基中,37℃,250rpm震荡培养至od600为0.8时,加入bm13至浓度为2×107pfu/ml。37℃,300rpm培养1小时,加入25μg/ml卡那霉素,37℃继续培养14~18小时。将菌液离心,上清液用5%peg沉淀,然后重悬于含5%脱脂奶粉的pbs中备用。
1.3筛选hla-a2/rmfpnayl复合物的单域抗体
1.3.1生物淘选
链酶亲和素免疫磁珠取25μl,加入一定量的生物素化的hla-a2/rmfpnapyl,室温结合5min。pbst及pbs洗2~3次。mpbs封闭2小时,pbst及pbs洗2~3次。将噬菌体文库加入磁珠中,室温孵育2小时。
移走未结合文库,磁珠用pbst及pbs各洗10次。向磁珠中加入0.01%胰酶溶液,室温孵育1小时。得胰酶洗脱液。
将胰酶洗脱液加入到30mltg1(od600=0.5)中,按1.2中方法增值第一次洗脱文库。
如此进行第二轮、第三轮淘选。挑取三轮淘选后所得的单菌落至96孔板中。按1.2中文库增值方法制备出培养物上清液。
1.3.2elisa鉴定
取一定量上清液做elisa鉴定。见图1a和图2a。
elisa步骤如下:用包被缓冲液将已知抗原稀释至1~10μg/ml,每孔加0.1ml,4℃过夜;次日洗涤3次;加一定稀释的待检样品0.1ml于上述已包被之反应孔中,置37℃孵育1小时,洗涤;加入新鲜稀释的酶标第二抗(anti-km13-hrp1∶5000)体0.1ml,37℃孵育60分钟,洗涤;最后一遍用ddw洗涤。于各反应孔中加入临时配制的tmb底物溶液0.1ml,37℃10~30分钟。用高级读板机在650nm波长下读板。
各孔光吸收值如如图1b和图2b。
其中,a:elisa所有孔均包被抗hla-a2/rmfpnapyl;每孔中抗体各不相同。b:数据分析纵坐标为各孔在650nm下的光吸收值,横坐标为96个孔,其中,1-8为a1、b1、c1、d1、e1、f1、g1、h1,9-16为a2、b2、c2、d2、e2、f2、g2、h2,依次类推,89-96为a12、b12、c12、d12、f12、f12、g12、h12。
选择图1和2中a650nm在0.8以上的克隆进行测序,得到多个不同的氨基酸序列,seqidno.13(m5-h1),seqidno.14(m5-g3),seqidno.15(m5-f4),seqidno.16(m5-c3)。
四种不同单域抗体对不同抗原的特异性和亲和力的elisa鉴定,见图3a。加入tmb20分钟后用高级读板机在650nm波长下测光吸收,数据整理如图3b。
其中,图3a:elisa酶标板a、b两行包被抗原hla-a2/itdqvpfsv,c、d两行包被抗原hla-a2/nlvpmvatv,e、f两行包被抗原hla-a2/rmfpnapyl,g、h两行包被抗hla-a2/sllmwitqc;每个孔中所加入的单域抗体均以培养上清液的形式加入。其中,line1的八个孔中均孵育一抗为m5-h1,line2为某一个对四种抗原有交叉反应的抗体ma;line3为hla-a2/nlvpmvatv的抗体,做阳性对照m4;line4为m5-g3;line5为m5-f4;line6为阴性对照mb;line7为m5-c3。每种抗体对一种抗原的亲和检测反应均有两个重复孔。
图3b:数据分析酶标板加入tmb20分钟后用高级读板机在650nm波长下读板,数据整理如图b。纵坐标为650nm下的光吸收值,图中显示a650均为两个重复孔的平均值。横坐标1,2,3,4分别为四种抗原hla-a2/itdqvpfsv,hla-a2/nlvpmvatv,hla-a2/rmfpnapyl,hla-a2/sllmwitqc。a、b、c、d、e、f、g分别为m5-h1、ma对照、m4对照、m5-g3、m5-f4、mb对照、m5-c3。
结果显示筛选得到阳性克隆m5-h1、m5-g3、m5-f4、m5-c3只对hla-a2/rmfpnapyl表现较高亲和力,对其它三个抗原基本不结合。
实施例2、单域抗体的表达
原核单域抗体表达
将四个单域抗体基因前后分别用ncoi和noti限制性内切酶克隆到pet22b上表达单价抗体。将构建好的载体转化至e.coli/de3中,第二天挑单克隆,37℃220rpm震荡培养至od600约0.5时,加入iptg(工作浓度为1mm)后,18℃220rpm诱导表达20h。检测蛋白表达情况。超声上清液用proteina纯化后跑sds-pag,见图4。其中,marker的条带从小到大依次为14,25,30,40,50,70,100,120,160kd。line1为m5-h1,line2为m5-g3,line3为m5-f4。单域抗体大小约为14kd。
在pet22b中融合fc表达为了形成双价抗体,将单域抗体基因通过noti和linker(g4s)与人源fc连接在一起,前后分别用ncoi和xhoi限制性内切酶克隆到pet22b上,质粒图谱见图5。
将构建好的载体转化至e.coli/de3中,第二天挑单克隆,37℃220rpm震荡培养至od600约0.5时,加入iptg(工作浓度为1mm)后,18℃220rpm诱导表达20小时。收集菌体后,用pbs(ph7.4)重悬均匀后超声破碎。超声破碎条件:600w,超声2秒,间隔6秒,共10分钟,16℃。超声后4℃12000rpm离心10分钟。
单域抗体m5-h1在pet22b中融合fc表达的蛋白用proteina纯化后的还原sds-page。见图6。marker的条带从小到大依次为14,25,30,40,50,70,100,120,160kd。line1为还原态的m5-h1-fc,大约43kd。
真核单域抗体fc融合蛋白的表达
为了形成双价抗体,单域抗体基因融合人源fc,并在抗体前面引入kozak序列以及信号肽后克隆到pcdna3.1上,质粒图谱见图7。单域抗体与fc之间引入通过bamhi酶切位点,单域抗体前使用hindiii限制性内切酶,fc后使用xbai限制性酶切。
将该重组质粒瞬时转染到293f中,培养4天后离心,收集上清液,并用proteina纯化。
其中,m5-f4融合fc的蛋白纯化后跑sds-pag,见图8。其中,a图为还原融合抗体m5-f4-fc纯化后电泳图,b图为非还原融合抗体m5-f4-fc纯化后电泳图。marker的条带从小到大依次为14,25,30,40,50,70,100,120,160kd。line1和line2分别为还原态m5-f4-fc和非还原态m5-f4-fc。
实施例3、单域抗体对hla-a2/rmfpnapyl复合物的特异性识别
单域抗体对抗原复合物的特异性识别
pet22b上表达的单域抗体,收集菌体后,用pbs重悬均匀后超声破碎。超声破碎条件:600w,超声2秒,间隔6秒,共10分钟,16℃。超声后4℃12000rpm离心10分钟,取上清液做对不同抗原的特异性的elisa鉴定(proteina-hrp为二抗)并读板,数据整理分析见图9。其中,纵坐标为650nm下的光吸收值,横坐标1,2,3,4为四种抗原hla-a2/itdqvpfsv,hla-a2/nlvpmvatv,hla-a2/rmfpnapyl,hla-a2/sllmwitqc。三个样品分别为在pet22b中单独表达的m5-h1,m5-g3,m5-f4的超声上清液。
结果显示,在pet22b中单体形式表达的单域抗体,可以特异性识别hla-a2/rmfpnapyl,对其他抗原复合物不结合,另外,其体外结合抗原的能力弱于该抗体展示在噬菌体末端,其原因可能是单独表达时抗体均为单价,导致结合抗原能力减弱。
融合蛋白m5-h1-fc、m5-g3-fc和m5-f4-fc对抗原复合物的特异性识别
pet22b中表达的融合蛋白m5-h1-fc,m5-g3-fc,以及在pcdna3.1中表达的融合蛋白m5-f4-fc纯化后对不同抗原的特异性识别和亲和力鉴定,数据分析见图10。其中,纵坐标为650nm下的光吸收值,横坐标1,2,3,4分别为四种抗原hla-a2/itdqvpfsv,hla-a2/nlvpmvatv,hla-a2/rmfpnapyl,hla-a2/sllmwitqc。结果表明,原核表达和真核表达的的融合抗体均对hla-a2/rmfpnapyl特异性识别,且对其他抗原复合物不结合,无交叉反应。
实施例4、融合蛋白m5-f4-fc特异性识别天然加工的,表达在肿瘤细胞表面的hla-a2/rmfpnapyl复合物
用bv-173细胞(表达hla-a2/rmfpnapy)检测m5-f4-fc(实施例2中的融合蛋白)对hla-a2/rmfpnapy的特异性识别和亲和力。结果见图11。
bv-173细胞表面有hla-a2/rmfpnapy,利用流式细胞检测技术检测m5-f4-fc融合蛋白对hla-a2/rmfpnapy的特异性识别和高亲和力。其中实线negative为bv-173细胞不加一抗只加二抗山羊抗人fc(fitc),bm为bv-173细胞加不结合hla-a2/rmfpnapy的fc融合蛋白bm以及二抗,m5-f4为bv-173细胞加m5-f4-fc融合蛋白以及二抗。
实施例5、融合蛋白m5-f4-fc和m5-h1-fc与hla-a2/rmfpnapyl复合物分子间相互作用及亲和力常数测定
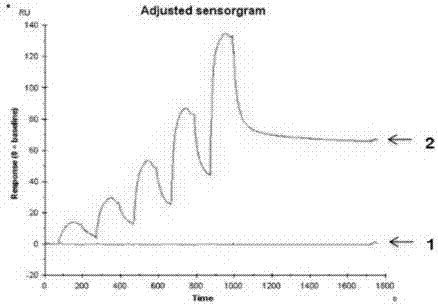
利用等离子共振技术进行rmfpnapyl/hla-a2的抗体融合蛋白m5-h1-fc和m5-f4-fc与rmfpnapyl/hla-a2的相互作用及亲和力常数测定。实验选用链霉亲和素偶联的传感芯片(senserchipsa),以hbs+ep+为流动相缓冲液。在传感芯片的一个通道上固定不相关抗原sllmwitqc/hla-a2作为参比抗原,另一个通道上固定rmfpnapyl/hla-a2作为实验抗原,参比抗原用来检测背景结合情况。分别稀释融合抗体m5-f4-fc,m5-h1-fc,从10nm到220nm浓度进行进样,样品同时流经固定有sllmwitqc/hla-a2和rmfpnapyl/hla-a2的通道表面。实验所得数据由biacoret200仪器进行采集并分析,反应动力学曲线以1:1binding模型进行拟合,并计算结合速率常数(ka),解离速率常数(kd),亲和力常数(kd)。其中,横坐标为时间,纵坐标为分子间相互结合的响应值(ru),1为参比通道,2为实验通道。
实验结果表明,融合抗体m5-h1-fc与rmfpnapyl/hla-a2发生特异性结合,与参比抗原无交叉反应,不结合。结合速率常数2.48e+04(1/ms),解离速率常数5.78e-04(1/s),亲和力常数2.33e-08(m),见图12;
融合抗体m5-f4-fc与rmfpnapyl/hla-a2发生特异性结合,与参比抗原无交叉反应,不结合。结合速率常数6.94e+04(1/ms),解离速率常数4.18e-04(1/s),亲和力常数6.03e-09(m),见图13。
实施例6、融合蛋白m5-h1-anticd3的细胞杀伤实验
将m5-h1与cd3抗体基因融合在pet22b上,构建一个双特异抗体,并在大肠杆菌中融合表达,并纯化后进行杀伤实验。m5-h1与cd3抗体融合蛋白序列为seqidno.17。
使用eutda细胞毒性试剂盒(perkinelmer,ad0116)进行体外杀伤实验,向1*10e6靶细胞bv173中加2.5ulbatda试剂,37℃孵育30分钟,然后使用细胞培养基洗细胞3-5次,取2*10e4个bv173靶细胞(100ul)铺于96孔板内。
逐级稀释目的蛋白至浓度为50、5、0.5、0.05ng/ul,分别向适量t细胞(中加入100、10、1、0.1、0.01ng目的蛋白37℃孵育1-2小时。加入铺有靶细胞的96孔板中,37℃、5%co2孵育2小时。背景对照:t细胞培养基与bv173细胞培养基混合,37℃、5%co2孵育2小时;最大释放:取等量bv173靶细胞加入100ul1%triton裂解液,37℃、5%co2孵育2小时;自发释放:取等量bv173靶细胞加入等量t细胞培养基37℃、5%co2孵育2小时。
离心后取清置于96孔平板中,加入europium溶液,室温孵育15分钟,使用时间分辨荧光分析法测量荧光值。
计算杀伤效率:杀伤效率={(实验值-自发释放值)/(最大释放值-自发释放值)}*100%。
自发释放效率={(自发释放值-背景对照值)/(最大释放值-背景对照值)}*100%。
本发明所叙述的一些术语具有如下含义:
同源性:描述两个或更多氨基酸序列相似程度,第一个氨基酸序列和第二个氨基酸序列之间同源性的百分比可以通过公式:(第一个氨基酸序列中与第二个氨基酸序列中相应位置处的氨基酸序列相同的氨基酸残基的数量)/(第一个氨基酸序列中氨基酸总数)*100%来计算,其中第二个氨基酸序列只能够的某个氨基酸的缺失、插入、替换或添加(与第一个氨基酸相比)被认为是有差别。同源性百分比也可以利用已知的用于序列匹配的计算机运算程序如ncbiblast获得。
密码子,又称三联体密码子,指对应于某种氨基酸的核苷酸三联体。在转译过程中决定该种氨基酸插入生长中多肽链的位置。
以上通过实施例对本发明进行了详细说明,但所述内容仅为本发明的示例性实施例,不能被认为用于限定本发明的实施范围。本发明的保护范围由权利要求书限定。凡利用本发明所述的技术方案,或本领域的技术人员在本发明技术方案的启发下,在本发明的实质和保护范围内,设计出类似的技术方案而达到上述技术效果的,或者对申请范围所作的均等变化与改进等,均应仍归属于本发明的专利涵盖保护范围之内。
sequencelisting
<110>天津天锐生物科技有限公司
<120>一种识别hla-a2/rmfpnapyl的单域抗体
<160>17
<210>1
<211>9
<212>prt
<213>人工序列
<400>1
tyrargileserseraspaspmetser
15
<210>2
<211>6
<212>prt
<213>人工序列
<400>2
thriletyrgluthrasp
15
<210>3
<211>12
<212>prt
<213>人工序列
<400>3
argalaasnphetyrsergluglnpropheglnphe
1510
<210>4
<211>9
<212>prt
<213>人工序列
<400>4
aspthrvalasnalagluaspmetser
15
<210>5
<211>6
<212>prt
<213>人工序列
<400>5
thriletyrvalasnasp
15
<210>6
<211>16
<212>prt
<213>人工序列
<400>6
serleuasnvalgluaspproglygluserasnthrglumetlysser
151015
<210>7
<211>9
<212>prt
<213>人工序列
<400>7
valmetvalthrasngluaspmetgly
15
<210>8
<211>6
<212>prt
<213>人工序列
<400>8
seriletyrvalthrasp
15
<210>9
<211>12
<212>prt
<213>人工序列
<400>9
argleuasnmetalahistyralagluvalglyser
1510
<210>10
<211>9
<212>prt
<213>人工序列
<400>10
aspthrpheserasnasptyrmetgly
15
<210>11
<211>6
<212>prt
<213>人工序列
<400>11
alaileglnthrthrgly
15
<210>12
<211>18
<212>prt
<213>人工序列
<400>12
glyarggluleuasptyrserglnglnglyargpheaspprohisleuasnser
151015
<210>13
<211>120
<212>prt
<213>人工序列
<400>13
glnvalglnleuleugluserglyglyglyleuvalglnproglyglyserleu
151015
argleusercysalaalaserglytyrargileserseraspaspmetsertrp
20253035
valargglnalaproglylysglyleuglutrpvalserthriletyrgluthr
404550
aspglyserthrtyrtyralaaspservallysglyargphethrileserarg
55606570
aspasnserlysasnthrleutyrleuglnmetasnserleuargalagluasp
75808590
thralavaltyrtyrcysalaargalaasnphetyrsergluglnprophegln
95100105
phetrpglyglnglythrleuvalthrvalserser
110115120
<210>14
<211>124
<212>prt
<213>人工序列
<400>14
glnvalglnleuleugluserglyglyglyleuvalglnproglyglyserleu
151015
argleusercysalaalaserglyaspthrvalasnalagluaspmetsertrp
20253035
valargglnalaproglylysglyleuglutrpvalserthriletyrvalasn
404550
aspglyserthrtyrtyralaaspservallysglyargphethrileserarg
55606570
aspasnserlysasnalaleutyrleuglnmetasnserleuargalagluasp
75808590
thralavaltyrtyrcysalaserleuasnvalgluaspproglygluserasn
95100105
thrglumetlyssertrpglyglnglythrleuvalthrvalserser
110115120
<210>15
<211>120
<212>prt
<213>人工序列
<400>15
glnvalglnleuleugluserglyglyglyleuvalglnproglyglyserleu
151015
argleusercysalaalaserglyvalmetvalthrasngluaspmetglytrp
20253035
valargglnalaproglylysglyleuglutrpvalserseriletyrvalthr
404550
aspglyserthrtyrtyralaaspservallysglyargphethrileserarg
55606570
aspasnserlysasnthrleutyrleuglnmetasnserleuargalagluasp
75808590
thralavaltyrtyrcysalaargleuasnmetalahistyralagluvalgly
95100105
sertrpglyglnglythrleuvalthrvalserser
110115120
<210>16
<211>126
<212>prt
<213>人工序列
<400>16
glnvalglnleuleugluserglyglyglyleuvalglnproglyglyserleu
151015
argleusercysalaalaserglyaspthrpheserasnasptyrmetglytrp
20253035
valargglnalaproglylysglyleuglutrpvalseralaileglnthrthr
404550
glyglyserthrtyrtyralaaspservallysglyargphethrileserarg
55606570
aspasnsergluasnthrleutyrleuglnmetasnserleuargalagluasp
75808590
thralavaltyrtyrcysalaglyarggluleuasptyrserglnglnglyarg
95100105
aspprohisleuasnsertrpglyglnglythrleuvalthrvalserpheser
110115120125
<210>17
<211>298
<212>prt
<213>人工序列
<400>17
glnvalglnleuleugluserglyglyglyleuvalglnproglyglyserleu
151015
argleusercysalaalaserglytyrargileserseraspaspmetsertrp
20253035
valargglnalaproglylysglyleuglutrpvalserthriletyrgluthr
404550
aspglyserthrtyrtyralaaspservallysglyargphethrileserarg
55606570
aspasnserlysasnthrleutyrleuglnmetasnserleuargalagluasp
75808590
thralavaltyrtyrcysalaargalaasnphetyrsergluglnprophegln
95100105
phetrpglyglnglythrleuvalthrvalserseralaalaalaglyglygly
110115120125
glyseraspilelysleuglnglnserglyalagluleualaargproglyala
130135140
servallysmetsercyslysthrserglytyrthrphethrargtyrthrmet
145150155160
histrpvallysglnargproglyglnglyleuglutrpileglytyrileasn
165170175180
proserargglytyrthrasntyrasnglnlysphelysasplysalathrleu
185190195
thrthrasplysserserserthralatyrmetglnleuserserleuthrser
200205210215
gluaspseralavaltyrtyrcysalaargtyrtyraspasphistyrcysleu
220225230
asptyrtrpglyglnglythrthrleuthrvalserservalgluglyglyser
235240245250
glyglyserglyglyserglyglyserglyglyvalaspaspileglnleuthr
255260265270
glnserproalailemetseralaserproglyglulysvalthrmetthrcys
275280285
argalaserserservalsertyrmetasn
290295
- 还没有人留言评论。精彩留言会获得点赞!