一种改进的二代测序用随机标签接头制作方法与流程
本发明涉及核酸测序技术领域,具体涉及一种用于改进的二代测序用随机标签接头的工艺优化。
背景技术:
随着技术的成熟以及成本的降低,二代测序因其测序通量上的优势,在科研以及临床转化领域正在逐渐取代传统的一代测序以及常规的pcr分子检测方法。
二代测序应用于临床目前还面临许多问题与挑战,其中一个突出问题就是测序较高的错误率。目前应用较广的二代测序平台主要有illumina平台(hiseq、miseq、nextseq等)和life的iontorrent平台(pgm和proton及衍生系列),两类二代测序的的测序错误率还较高(illumina平台0.1%,iontorrent平台1%)。
对于以肿瘤细胞突变为代表的体细胞突变(somaticmutation)检测来讲,由于肿瘤细胞之间的异质性,肿瘤样本中突变位点的比例可能非常低(1%);而在液态活检中,肿瘤游离dna的突变率甚至低于0.1%。由于较高的测序错误率背景,常规的二代测序平台无法检测出这些突变。目前主要通过分子标签(umiuniquemoueculeidentifier)的方法来克服这一问题。
分子标签是一小段dna片段,可以是固定序列的组合,也可以是随机序列,在测序前的文库制备阶段,通过给每一条原始dna模板上引入分子标签标记,来达到区分dna模板的目的;在后续的生物信息学分析阶段,通过分子标签的识别,就可以利用文库构建过程中产生的重复序列(duplication)来实现测序碱基的校正的目的。
分子标签技术主要包括pcr法和随机标签接头法,随机标签接头法由于更低的错误率(10-8)及更好的文库构建兼容性,应用更为广泛。
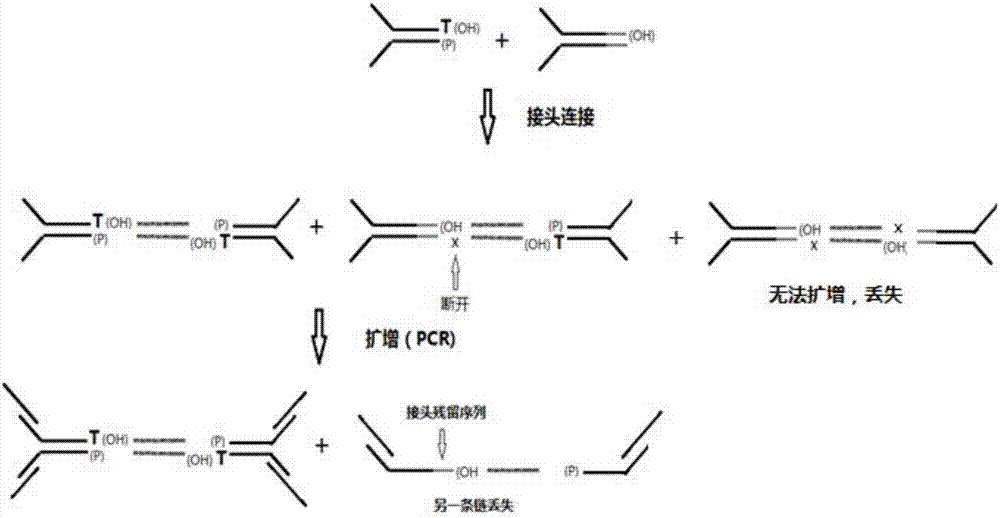
但随机标签接头由于其制作工艺的原因,最终制作的接头会有部分酶切不完整的平末端接头,这部分平末端接头的存在,会导致测序文库模板的丢失以及测序数据量的浪费(图1、图2)。而通过生物素标记接头制备的引物oligo方法虽然可以去除平末端接头,但该方法会增加接头的制备步骤,且亲和素磁珠纯化过程中由于操作不当,容易造成双链接头的解链,导致接头的部分失效。
因此,如何有效地去除随机标签接头中的平末端接头仍然是一个亟待需要解决的问题。
技术实现要素:
本发明的目的在于提供一种随机标签接头制备的优化工艺。
其特征在于,在接头制作的接头引物p7上引入spacer修饰,修饰的种类包括但不限于c6spacer、spacer18、dspacer等可以阻止聚合酶延伸的核酸修饰(图3)。在接头延伸步骤(图4),聚合酶遇到p7模板链的spacer位点后即终止延伸,留下一段5’突出末端;接下来的酶切步骤,内切酶去除包括spacer位点在内的突出末端,产生完整的接头;而酶切不充分残留的未被酶切接头,仍然保留较长5’突出末端。
在文库的构建过程中(图5),正常的接头通过末端的t碱基和模板dna末端的a碱基连接,形成完整的文库;未酶切接头因为带有较长的突出的5’末端,无法和带a尾的dna模板发生连接,不影响文库的构建。
随机标签接头由随机标签接头a、随机标签接头b和随机标签接头c组成,随机标签接头a、随机标签接头b和随机标签接头c分别由接头引物p5分别与spacer修饰的接头引物p7-a、接头引物p7-b和接头引物p7-c合成而得到,其中:
接头引物p5为seqidno:01
seq1:acactctttccctacacgacgctcttccgatct
接头引物p7-a为fffff(spacer)eeeeejjjjjnnnnnnnnnnnn连接在seqidno:02的5’端所得;
接头引物p7-b为fffff(spacer)eeeeekkkkknnnnnnnnnnnn连接在seqidno:02的5’端所得;
接头引物p7-c为fffff(spacer)eeeeelllllnnnnnnnnnnnn连接在seqidno:02的5’端所得;
seq2:agatcggaagagcacacgtctgaactccagtcac
所述fffff为突出末端序列,spacer为spacer修饰位点,eeeee为酶切位点,jjjjj、kkkkk和lllll为定位标签序列且jjjjj、kkkkk和lllll各不相同,nnnnnnnnnnnn为随机分子标签序列。
其中:
fffff序列为非人源基因组的其它碱基序列(如酶切位点保护碱基序列等),长度需大于5个碱基,如5-20个碱基;6/7/8/9/10个碱基等。
spacer修饰位点为spacer修饰的碱基或碱基之间的spacer链,如dspacer,c3spacer,c6spacer,c12spacer,spacer9,spacer18等;spacer修饰的个数可以为1个、2个、3个等;2个以上(包括2个)的spacer可以跟第一个spacer串联,也可以分布于突出末端序列(fffff)中,spacer分布于突出末端序列中可以避免该序列可能带来的污染;
jjjjj包括但不限于5个相同碱基(例如5-10个不相同碱基);同样,kkkkk包括但不限于5个相同碱基(例如5-10个不相同碱基)、lllll包括但不限于5个相同碱基(例如5-10个不相同碱基),和eeeee包括但不限于5个相同碱基(例如5-10个不相同碱基),nnnnnnnnnnnn为4到12个随机碱基,且没有四个连续相同的碱基。
其中,所述nnnnnnnnnnnn表示为bdhvbdhv,其中b表示该位置是除a外的碱基,d位置表示该位置是除c外的碱基,h表示该位置是除g外的碱基,v表示该位置是除t外的碱基。
其中,所述jjjjj、kkkkk和lllll的序列可以和所述eeeee的序列部分重叠或完全重叠,当部分或完全重叠的时候,重叠部分的碱基只出现一次。
一种随机标签接头组的制备方法,其特征在于:包括如下步骤:
(1)退火:将接头引物p5、接头引物p7-a、接头引物p7-b、接头引物p7-c及缓冲液和适量去离子水混合后,进行退火处理得到退火接头a/b/c;
(2)延伸退火接头:对所得退火接头a/b/c进行聚合酶延伸得到延伸接头a/b/c;
(3)第一次沉淀:对所得延伸接头a/b/c分别进行乙醇或异丙醇沉淀纯化得到纯化后的延伸接头a/b/c;
(4)酶切:对纯化后的延伸接头a/b/c分别加入能够产生3’t突出末端的限制性内切酶进行酶切得到酶切接头a/b/c;
(5)第二次沉淀:将所得酶切接头a/b/c进行乙醇或异丙醇沉淀纯化后即得到所述多定位随机标签接头组。
本发明的有益效果
在接头的制作过程中(图4),通过在用于随机标签接头制作的p7oligo序列酶切位点之后引入spacer修饰,从而使酶切后制备的接头中残留的未酶切接头保留黏性末端,从而使其不能与文库dna模板(带a尾的平末端)以及正常接头(带t尾的平末端)连接,使接头制备过程中残留的未酶切接头不再参与文库的构建,从而减少建库的模板损失以及测序数据量的浪费。与生物素标记去除残留未酶切接头的方式相比,本发明不需要改变原有的接头制备过程,具有更好的工艺兼容性;且因为不需要用到生物素-亲和素纯化系统,降低了接头的制作成本。
附图说明
图1:接头制备后平末端接头的残留(agilent2100),方框中是接头制作过程产生的未被酶切的平末端接头。
图2:残留的平末端接头对文库构建的影响,模板连接过程中,由于平末端接头末端无磷酸化基团,因此跟dna模板的连接只能是单链连接,部分断开的连接产物无法扩增,最终造成模板的单链损失或双链损失。
图3:spacer修饰的未被酶切接头结构
图4:spacer修饰接头制作过程
图5:残留未酶切接头不参与文库构建。
具体实施方式
以下通过具体实施方式结合附图对本发明的技术方案进行进一步的说明和描述。
实施例1:改进后的接头制备(dspacer修饰接头)
将接头引物p5,接头引物p7-a,接头引物p7-b、接头引物p7-c四个引物(接头引物p5为seqidno:1;接头引物p7-a为fffff(spacer)eeeeejjjjjnnnnnnnnnnnn连接在seqidno:02的5’端所得;接头引物p7-b为fffff(spacer)eeeeekkkkknnnnnnnnnnnn连接在seqidno:02的5’端所得;接头引物p7-c为fffff(spacer)eeeeelllllnnnnnnnnnnnn连接在seqidno:02的5’端所得;合成厂家:生工生物工程(上海)股份有限公司)用ddh2o(或te缓冲液)稀释至100um;
其中fffff(spacer)序列为tcttcttc-dspacer-t-dspacer-ttcttct
spacer修饰位点选用dspacer,eeeee为酶切位点,jjjjj/kkkkk/lllll为定位标签序列,nnnnnnnnnnnn为随机分子标签序列。
同时fffff/eeeee/jjjjj/kkkkk/lllll包括但不限于5个相同碱基;nnnnnnnnnnnn为4到12个随机碱基,且没有四个连续相同的碱基。
随机标签接头的制备方法步骤如下:
退火:在15ml离心管中配制以下体系:接头引物p5:1ml,接头引物p7(a):334ul,接头引物p7(b):334ul,接头引物p7(c):334ul,nebbuffer2:300ul,ddh2o:700ul;共3ml。将此体系混匀后进行如下反应:水浴锅中95℃,5min;然后立刻放入装有95℃热水的烧杯中,室温条件下缓慢降温至24-27℃;
退火片段延伸:在原15ml离心管中加入:10×nebbuffer:200ul,25mmdntpmix:200ul,500mmdtt:6ul,klenowexo-(5u/ul):100ul,用ddh2o补足体积至5ml,混匀后,37℃恒温箱中旋转混匀,孵育1h。
第一次沉淀:向上述所得产物中加入1/10体积的naac(3m)和2.5倍体积的无水乙醇,混匀后置于-20℃2h;13000g离心30min;去上清,加入5ml70%乙醇漂洗沉淀,4℃,13000g离心30min;去上清,室温晾干dna20-30min,用3mlddh2o重悬dna,并用quantus测浓度。
酶解(以hpych4iii内切酶为例,酶切位点:acngt,相应的接头引物p7序列eeeee改为acagt):取上述所得片段延伸产物,根据其质量x(ug)加入10×nebcutsmartbuffer:2xul,hpych4iii(5u/ul):2xul,用ddh2o补足体积至20xul,混匀后,37℃恒温箱中旋转孵育,酶解16h。
第二次沉淀:向上述酶解产物中加入1/10体积的naac和2.5倍体积的无水乙醇,混匀后置于-20℃2h;4℃,13000g离心30min;去上清,加入10ml70%乙醇漂洗沉淀,4℃,13000g离心30min;去上清,室温晾干dna20-30min,用1.5mltelowbuffer重悬dna,即为最终随机标签接头,接头经质控合格后进行分装,-20℃冻存备用。
实施例2:改进后的接头制备(spacer18修饰接头)
将接头引物p5,接头引物p7-a,接头引物p7-b、接头引物p7-c四个引物(接头引物p5为seqidno:1;接头引物p7-a为fffff(spacer)eeeeejjjjjnnnnnnnnnnnn连接在seqidno:02的5’端所得;接头引物p7-b为fffff(spacer)eeeeekkkkknnnnnnnnnnnn连接在seqidno:02的5’端所得;接头引物p7-c为fffff(spacer)eeeeelllllnnnnnnnnnnnn连接在seqidno:02的5’端所得;合成厂家:生工生物工程(上海)股份有限公司)用ddh2o(或te缓冲液)稀释至100um;
其中fffff(spacer)序列为tcttcttcttc(spacer18)ttcttct
spacer修饰位点选用spacer18,eeeee为酶切位点,jjjjj/kkkkk/lllll为定位标签序列,nnnnnnnnnnnn为随机分子标签序列。
同时fffff/eeeee/jjjjj/kkkkk/lllll包括但不限于5个相同碱基;nnnnnnnnnnnn为4到12个随机碱基,且没有四个连续相同的碱基。
随机标签接头的制备方法步骤如下:
退火:在15ml离心管中配制以下体系:接头引物p5:1ml,接头引物p7(a):334ul,接头引物p7(b):334ul,接头引物p7(c):334ul,nebbuffer2:300ul,ddh2o:700ul;共3ml。将此体系混匀后进行如下反应:水浴锅中95℃,5min;然后立刻放入装有95℃热水的烧杯中,室温条件下缓慢降温至24-27℃;
退火片段延伸:在原15ml离心管中加入:10×nebbuffer:200ul,25mmdntpmix:200ul,500mmdtt:6ul,klenowexo-(5u/ul):100ul,用ddh2o补足体积至5ml,混匀后,37℃恒温箱中旋转混匀,孵育1h。
第一次沉淀:向上述所得产物中加入1/10体积的naac(3m)和2.5倍体积的无水乙醇,混匀后置于-20℃2h;13000g离心30min;去上清,加入5ml70%乙醇漂洗沉淀,4℃,13000g离心30min;去上清,室温晾干dna20-30min,用3mlddh2o重悬dna,并用quantus测浓度。
酶解(以hpych4iii内切酶为例,酶切位点:acngt,相应的接头引物p7序列eeeee改为acagt):取上述所得片段延伸产物,根据其质量x(ug)加入10×nebcutsmartbuffer:2xul,hpych4iii(5u/ul):2xul,用ddh2o补足体积至20xul,混匀后,37℃恒温箱中旋转孵育,酶解16h。
第二次沉淀:向上述酶解产物中加入1/10体积的naac和2.5倍体积的无水乙醇,混匀后置于-20℃2h;4℃,13000g离心30min;去上清,加入10ml70%乙醇漂洗沉淀,4℃,13000g离心30min;去上清,室温晾干dna20-30min,用1.5mltelowbuffer重悬dna,即为最终随机标签接头,接头经质控合格后进行分装,-20℃冻存备用。
实施例3:改进后的接头制备(c6spacer修饰接头)
将接头引物p5,接头引物p7-a,接头引物p7-b、接头引物p7-c四个引物(接头引物p5为seqidno:1;接头引物p7-a为fffff(spacer)eeeeejjjjjnnnnnnnnnnnn连接在seqidno:02的5’端所得;接头引物p7-b为fffff(spacer)eeeeekkkkknnnnnnnnnnnn连接在seqidno:02的5’端所得;接头引物p7-c为fffff(spacer)eeeeelllllnnnnnnnnnnnn连接在seqidno:02的5’端所得;合成厂家:生工生物工程(上海)股份有限公司)用ddh2o(或te缓冲液)稀释至100um;
其中fffff(spacer)序列为tcttcttct(c6spacer)tc(c6spacer)ttcttct
spacer修饰位点选用c6spacer,eeeee为酶切位点,jjjjj/kkkkk/lllll为定位标签序列,nnnnnnnnnnnn为随机分子标签序列。
同时fffff/eeeee/jjjjj/kkkkk/lllll包括但不限于5个相同碱基;nnnnnnnnnnnn为4到12个随机碱基,且没有四个连续相同的碱基。
随机标签接头的制备方法步骤如下:
退火:在15ml离心管中配制以下体系:接头引物p5:1ml,接头引物p7(a):334ul,接头引物p7(b):334ul,接头引物p7(c):334ul,nebbuffer2:300ul,ddh2o:700ul;共3ml。将此体系混匀后进行如下反应:水浴锅中95℃,5min;然后立刻放入装有95℃热水的烧杯中,室温条件下缓慢降温至24-27℃;
退火片段延伸:在原15ml离心管中加入:10×nebbuffer:200ul,25mmdntpmix:200ul,500mmdtt:6ul,klenowexo-(5u/ul):100ul,用ddh2o补足体积至5ml,混匀后,37℃恒温箱中旋转混匀,孵育1h。
第一次沉淀:向上述所得产物中加入1/10体积的naac(3m)和2.5倍体积的无水乙醇,混匀后置于-20℃2h;13000g离心30min;去上清,加入5ml70%乙醇漂洗沉淀,4℃,13000g离心30min;去上清,室温晾干dna20-30min,用3mlddh2o重悬dna,并用quantus测浓度。
酶解(以hpych4iii内切酶为例,酶切位点:acngt,相应的接头引物p7序列eeeee改为acagt):取上述所得片段延伸产物,根据其质量x(ug)加入10×nebcutsmartbuffer:2xul,hpych4iii(5u/ul):2xul,用ddh2o补足体积至20xul,混匀后,37℃恒温箱中旋转孵育,酶解16h。
第二次沉淀:向上述酶解产物中加入1/10体积的naac和2.5倍体积的无水乙醇,混匀后置于-20℃2h;4℃,13000g离心30min;去上清,加入10ml70%乙醇漂洗沉淀,4℃,13000g离心30min;去上清,室温晾干dna20-30min,用1.5mltelowbuffer重悬dna,即为最终随机标签接头,接头经质控合格后进行分装,-20℃冻存备用。
实施例4:优化后接头测序pf值改善情况(测序质量)
以30ng打断后白细胞dna(平均长度220bp)起始建库,实验分4组,第一组使用正常的随机标签接头进行文库构建,其余三组分别使用实施例1-3中制备的dspacer、spacer18和c6spacer修饰的优化工艺制作的随机标签接头建库,建库试剂盒使用nebnextultraiidnalibraryprepkit,文库构建步骤如下:
(1)取30ng打断dna加入7ulnebnextultraiiendprepreactionbuffer和3ulnebnextultraiiendprepenzymemix,用去离子水补足体积至60ul,pcr仪上20℃,30min→65℃,30min→4℃维持;
(2)上述体系加入1ul接头,然后加入30ulnebnextultraiiligationmastermix和1ulnebnextligationenhancer,混匀后20℃反应15min。连接产物使用0.9×ampure磁珠进行纯化,纯化后使用23ul纯化水洗脱;
(3)pcr管中加入23ul上述连接产物,i5、i7index引物各1ul(25um),和25ulnebnextultraiiq5mastermix,混匀后pcr仪上进行如下反应:
98℃,30s;
98℃,10s→65℃,75s(8个循环);
65℃,5min;
4℃维持
pcr完成后使用0.9×磁珠进行纯化,然后使用quantus(promega)和2100bioanalyzer(agilent)进行质控
构建的文库质控合格后使用illuminanextseq500平台进行测序,测序试剂为midoutputkit(300cycles),phix掺入比例为1%,每个文库数据量为1gb,测序结果如下:
使用优化工艺接头可以明显降低接头残余序列,其中,三种接头spacer修饰,dspacer效果最好。
以上所述,仅为本发明的较佳实施例而已,故不能依此限定本发明实施的范围,即依本发明专利范围及说明书内容所作的等效变化与修饰,皆应仍属本发明涵盖的范围内。
<110>厦门艾德生物医药科技股份有限公司
<120>一种改进的二代测序用随机标签接头制作方法
<160>2
210>1
<211>33
<212>dna
<213>人工序列
<400>1
acactctttccctacacgacgctcttccgatct33
<210>2
<211>34
<212>dna
<213>人工序列
<400>2
agatcggaagagcacacgtctgaactccagtcac34
- 还没有人留言评论。精彩留言会获得点赞!