一种绵羊多羔性状的SNP分子标记及其检测用引物组、试剂盒和应用的制作方法
本发明属于snp分子标记技术领域,具体涉及一种绵羊多羔性状的snp分子标记及其检测用引物组、试剂盒和应用。
背景技术:
产羔性状是绵羊的重要经济性状之一。因此,提高绵羊每胎的产羔数是提升生产经济效益的重要措施。产羔数是一个极其复杂的性状,受到饲料、遗传背景、饲养环境等诸多因素的影响,其中以遗传背景最为重要,不同品种绵羊之间的繁殖力具有显著的差异性。
应用基因组学方法的研究能在整个基因组的水平筛选出与绵羊繁殖性状相关的候选基因和分子标记,使学者们能够更深入的理解绵羊多羔性状的遗传机理,可对我国绵羊业的可持续发展将带来巨大的经济效益。目前,研究最多的是绵羊fecb基因。然而,实践中根据fecb基因型推断只产单羔的++型小尾寒羊中仍然能够观测到连续的高产羔数现象。由此推断小尾寒羊还存在其他的多羔主效基因。因此,需要进一步鉴定其他多羔主效基因以及致因突变位点,以望更准确地预测绵羊例如小尾寒羊等的多羔形状。
技术实现要素:
有鉴于背景技术中存在的问题,本发明的目的在于提供一种与绵羊多羔性状相关的snp分子标记及其检测用引物组、试剂盒和应用。
本发明提供了一种绵羊多羔性状的snp分子标记,所述snp分子标记含有位于绵羊第7号染色体上第89431097bp处多态性为c/g的核苷酸序列。
优选的,所述snp分子标记含有如seqidno.1所示的核苷酸序列,所述核苷酸序列的第200bp处多态性为c/g。
本发明提供了用于检测上述snp分子标记的引物组,其特征在于,包括第一引物、第二引物和延伸引物;
所述第一引物的核苷酸序列如seqidno.2所示;
所述第二引物的核苷酸序列如seqidno.3所示;
所述延伸引物的核苷酸序列如seqidno.4所示。
本发明提供了用于检测上述snp分子标记的试剂盒,包括dntps、taqdna聚合酶、mgcl2、pcr反应缓冲液和sap酶,还包括上述引物组。
优选的,所述引物组中第一引物和第二引物的使用浓度独立为0.45~0.55μmol/l;所述引物组中的延伸引物的浓度为0.6~1.3μmol/l。
优选的,所述试剂盒还包括基因型为gg的标准阳性模板dna。
本发明还提供了一种检测上述snp分子标记的方法,包括以下步骤:
1)提取待测绵羊的基因组dna;
2)以待测绵羊的基因组dna为模板,利用权利要求3所述引物组中的第一引物和第二引物进行pcr扩增反应获得pcr扩增产物;
3)用sap酶对步骤2)中获得的pcr扩增产物进行消化获得消化后的产物;
4)以消化后的产物为模板,利用权利要求3所述引物组中的延伸引物进行延伸反应获得延伸产物;
5)对所述延伸产物进行分析,确定所述snp位点的基因型。
优选的,步骤2)中所述pcr扩增反应使用的反应体系以5μl计包括:
所述pcr扩增反应的程序优选为:
预变性95℃,2min;
变性95℃,30s;
退火56℃,30s;
延伸72℃,60s;
所述变性、退火和延伸步骤进行45个循环后;72℃保持5min。
优选的,步骤3)中所述消化体系以2μl计包括:
10×sapbuffer0.17μl;
1.7u/μlsap酶0.3μl;
去离子水1.53μl;
所述消化的程序优选为:37℃,40min;85℃,5min。
优选的,步骤4)中所述延伸反应的体系以2μl计包括:
所述延伸反应的程序优选为:
94℃,30s;
[94℃,5s;(52℃,5s;80℃,5s)];其中所述(52℃,5s;80℃,5s)进行5个循环,所述[94℃,5s;(52℃,5s;80℃,5s)]进行40个循环;
72℃,3min。
本发明还提供了上述snp位点、引物组、试剂盒在绵羊辅助育种中的应用,所述应用在绵羊育种过程中,筛选所述snp位点为g碱基的绵羊进行后续育种。
有益效果:本发明提供了一种绵羊多羔性状的snp分子标记,所述snp分子标记含有位于绵羊第7号染色体上第89431097bp处多态性为c/g的核苷酸序列。所述snp位点的c/g碱基突变与绵羊多羔性状紧密相关,通过对所述snp位点进行分型即可确定待测绵羊产羔性能:当所述snp位点为g碱基时,绵羊具有单胎产多羔性状;当所述位点为c碱基时,绵羊无单胎产多羔性状。
本发明提供了用于检测所述snp分子比较的引物组、试剂盒及方法。本发明利用sequenom
本发明还提供了一种在绵羊育种过程中,通过筛选所述snp位点为g碱基的绵羊进行后续育种的应用。所述应用方法可实现自动化检测,在绵羊育种过程中将具有单胎产多羔性状的gg纯合个体和cg杂合个体选留下来,从而提高绵羊的繁殖力,对绵羊大规模分子育种具有潜在的应用价值。
附图说明
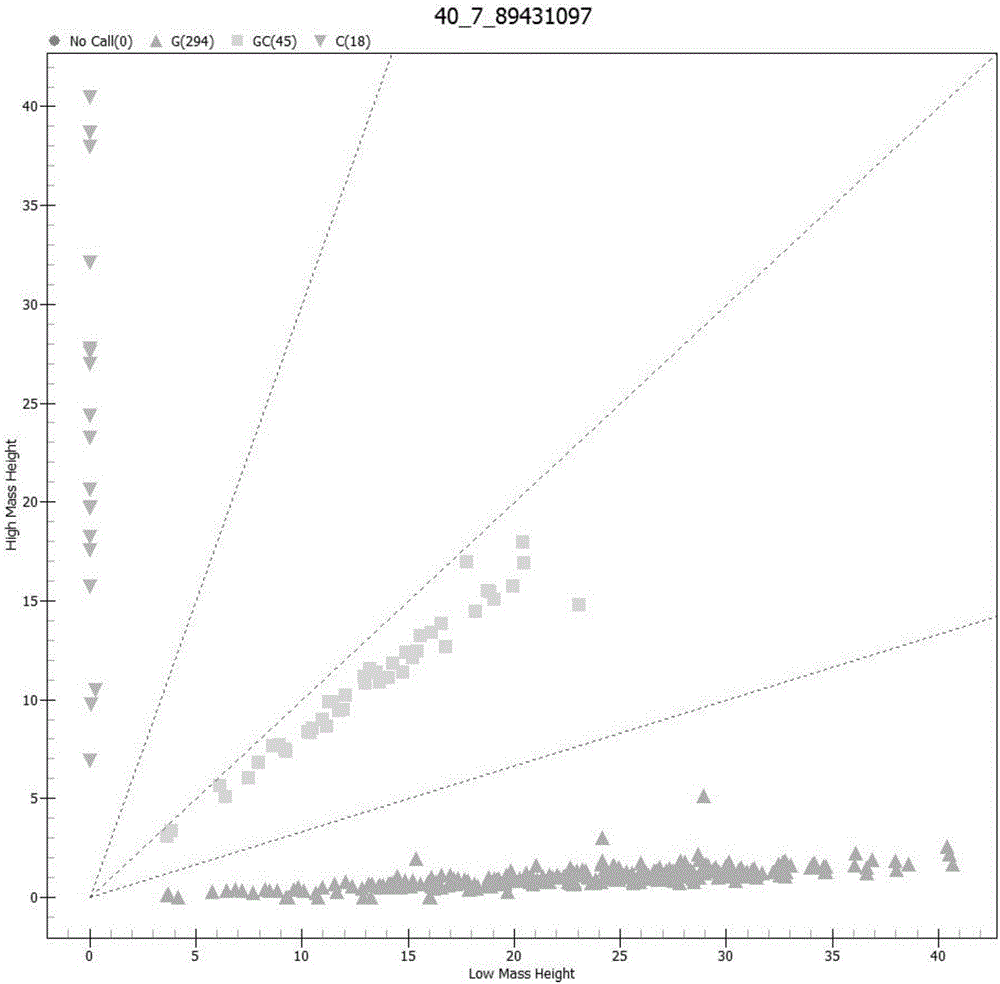
图1为本发明实施例1所述延伸产物的质谱检测结果。
具体实施方式
本发明提供了一种绵羊多羔性状的snp分子标记,所述snp分子标记含有位于绵羊第7号染色体上第89431097bp处多态性为c/g的核苷酸序列。在本发明中,所述snp位点位于绵羊第7号染色体上第89431097bp位点,nc_019464.2(89258662-89437438),所述位点上存在c/g碱基突变,与绵羊多羔具有显著的相关性。本发明还提供了一种优选的绵羊多羔性状的snp分子标记,所述snp分子标记含有如seqidno.1所示的核苷酸序列,所述核苷酸序列的第200bp处多态性为c/g。通过对所述snp位点进行分型可确定待测绵羊产羔性能:当所述位点为g碱基时,绵羊具有单胎产多羔性状;当所述位点为c碱基时,绵羊无单胎产多羔性状。在本发明中,所述snp位点信息基于的绵羊基因组序列信息版本号为oar_v3.1,2012年9月;所述snp位点位于促甲状腺激素受体基因tshr中。
本发明提供了利用sequenom
本发明还提供了利用sequenom
本发明还提供了利用sequenom
1)提取待测绵羊的基因组dna;
2)以待测绵羊的基因组dna为模板,利用所述引物组中的第一引物和第二引物进行pcr扩增反应获得pcr扩增产物;
3)用sap酶对步骤2)中获得的pcr扩增产物进行消化获得消化后的产物;
4)以消化后的产物为模板,利用所述引物组中的延伸引物进行延伸反应获得延伸产物;
5)对所述延伸产物进行分析,确定所述snp位点的基因型。
本发明首先提取待测绵羊的基因组dna。本发明对所述待测绵羊的种类没有特殊要求,任何种类的绵羊均可。在本发明的实施例中,所述绵羊为小尾寒羊。本发明对所述待测绵羊基因组的提取方法没有特殊限定,采用本领域常规的动物细胞基因组提取方法即可。在本发明具体实施过程中,采用血液基因组dna提取系统(目录号:dp349)进行提取。
本发明在获得所述待测绵羊基因组dna后,以待测绵羊的基因组dna为模板,利用所述引物组中的第一引物和第二引物进行pcr扩增反应获得pcr扩增产物。本发明中所述pcr扩增反应使用的反应体系以5μl计优选的包括:
所述pcr扩增反应的程序优选为:
预变性95℃,2min;
变性95℃,30s;
退火56℃,30s;
延伸72℃,60s;
所述变性、退火和延伸步骤进行45个循环后;72℃保持5min。本发明在所述pcr扩增完成后,优选的将pcr扩增产物保存于4℃。本发明所述pcr扩增反应结束后,所述pcr扩增产物中含有目标snps位点所在的dna片段。
本发明在获得所述pcr扩增产物后,用sap酶对获得的pcr扩增产物进行消化获得消化后的产物。在本发明中,所述消化体系以2μl计优选包括:10×sapbuffer0.17μl;1.7u/μlsap酶0.3μl和去离子水1.53μl。在本发明中,所述消化的程序优选为:37℃,40min;85℃,5min。本发明中所述消化后的产物优选的保存于4℃。本发明中所述消化的作用为消化掉pcr扩增反应体系中的引物序列和剩余的dntps。
本发明在获得所述消化产物后,以消化后的产物为模板,利用所述引物组中的延伸引物进行延伸反应获得延伸产物。本发明中,所述延伸反应的体系以2μl计优选的包括:
在本发明中,所述延伸反应的程序优选为:
94℃,30s;
[94℃,5s;(52℃,5s;80℃,5s)];其中所述(52℃,5s;80℃,5s)进行5个循环,所述[94℃,5s;(52℃,5s;80℃,5s)]进行40个循环;
72℃,3min。
在所述延伸体系中,本发明对所述10×iplexbufferplus、iplexterminator、0.6~1.3μmol/lprimermix和iplex酶的来源不作特别限定,本领域常规市售产品均可。在本发明的实施例中,上述组分的来源均为
本发明在获得所述延伸产物后,对所述延伸产物进行分析,确定所述snp位点的基因型。在本发明中,所述分析优选采用基质辅助激光解析电离飞行时间质谱技术。本发明优选将所述延伸产物点样至靶片上,并使用质谱仪对不同延伸产物的分子量差异进行检测,通过数据分析,即可得到各突变位点的具体基因型。在本发明更具体的实施方式中,所述质谱点样优选使用massarraynanodispenserrs1000进行;所述质谱分析优选使用massarraycompactsystem进行。本发明在所述质谱分析后,优选利用typer4.0软件检测质谱峰,并根据质谱峰图判读各样本目标位点基因型。
在本发明中,所述sequenom
本发明还提供了上述snp位点、引物组或者试剂盒在绵羊辅助育种中的应用。所述应用优选在绵羊育种过程中,筛选所述snp位点为g碱基的绵羊进行后续育种。在本发明中,所述snp位点的筛选优选的采用上述sequenom
下面结合实施例对本发明提供的技术方案进行详细的说明。以下实施例用于说明本发明,但不用来限制本发明的范围。若未特别指明,实施例均按照常规实验条件,如sambrook等分子克隆实验手册(sambrookj&russelldw,molecularcloning:alaboratorymanual,2001),或按照制造厂商说明书建议的条件。
实施例1
一种利用sequenom
1、实验材料
选取407只小尾寒羊绵羊为检测对象。
2、试剂及仪器
试剂:completegenotypingreagentkitfor
基因扩增:abi
质谱点样:massarraynanodispenserrs1000;
质谱分析:massarraycompactsystem;
所有试剂和仪器均购自北京康普森生物技术有限公司(beijingcompassbiotechnologyco.,ltd)。
3、基因组dna的提取
绵羊颈静脉采血1ml,用edta抗凝处理。使用天根血液基因组dna提取系统(目录号:dp349)进行提取dna。
4、sequenom
针对绵羊第7号染色体上第89431097bp位点(nm_001278566.1,基于绵羊基因组序列信息版本号oar_v4.0,2015年12月)设计引物组合。
pcr扩增引物的核苷酸序列如下:
1st-pcrp:tgtacacggacaactcc;
2nd-pcrp:tgtacacggacaactcg;
延伸引物序列及延伸产物如表1所示。
表1延伸引物序列及延伸产物
上述引物由北京康普森生物技术有限公司合成。
检测流程如下:
1)提取待测绵羊的基因组dna;
2)以待测绵羊的基因组dna为模板,利用上述引物2nd-pcrp和1st-pcrp进行pcr扩增反应;
3)用sap酶对pcr扩增产物进行消化;
4)以消化后的pcr扩增产物为模板,利用所述延伸引物s1进行延伸反应;
5)分析延伸产物,从而对绵羊tshr基因型进行判定。
其中,pcr扩增反应使用的反应体系以5μl计为:10ng/μl基因组dna1μl;10×pcr反应缓冲液0.5μl;25mmol/lmgcl20.4μl;25μmol/ldntps0.1μl;0.5μmol/lpcrprimermix1μl;5u/μltaqdna聚合酶0.2μl;去离子水1.8μl;
pcr扩增反应的扩增程序为:95℃2min;95℃30s,56℃30s,72℃60s,45个循环;72℃3min;4℃保存。
对pcr扩增产物进行消化,使用的sap酶消化体系以2μl计包括:10×sapbuffer0.17μl;1.7u/μlsap酶0.3μl和去离子水1.53μl;在本发明中,所述消化的程序为:37℃,40min;85℃,5min。本发明中所述消化后的产物优选的保存于4℃。本发明中所述消化的作用为消化掉pcr扩增反应体系中的引物序列和剩余的dntps。反应条件为:37℃40min,85℃5min,4℃保存。
延伸反应体系以以2μl计为:10×iplexbufferplus0.2μl;iplexterminator0.2μl;0.6-1.3μmol/lprimermix0.94μl;iplex酶0.041μl;去离子水0.619μl;
反应条件为:94℃30s;94℃5s,52℃5s,80℃5s,5个循环,40个循环;72℃3min;4℃保存。
将树脂纯化后的延伸产物移至384孔spectrochip(sequenom)芯片上,进行maldi-tof-ms(基质辅助激光解析电离飞行时间质谱)反应,利用typer4.0软件检测质谱峰,并根据质谱峰图判读各样本目标位点基因型。经质谱分析得到pcr扩增产物大小为103bp,延伸产物的质谱检测结果如图1所示。由图可看出该位点有三种基因型,其中第一条虚线处倒三角图标代表检测到18个cc型,中间的虚线处正方形图标代表检测到45个cg型,最下面一条虚线处的正三角图标代表检测到294个gg型。
统计结果:待测绵羊第7号染色体上第89431097bp位点不同基因型分析统计结果见表2。
表2待测绵羊第7号染色体上第89431097bp位点不同基因型分析统计
待测绵羊第7号染色体上第89431097bp位点不同基因型与小尾寒羊产羔数关联分析统计结果见表3。
表3待测绵羊第7号染色体上第89431097bp位点不同基因型与小尾寒羊产羔数关联分析
注:a、b表示差异显著(p<0.05)。
以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
序列表
<110>中国农业科学院北京畜牧兽医研究所
<120>一种绵羊多羔性状的snp分子标记及其检测用引物组、试剂盒和应用
<160>4
<170>siposequencelisting1.0
<210>1
<211>401
<212>dna
<213>绵羊(ovisaries)
<400>1
tcctcacgagccactacaagctgactgtcccacgcttcctcatgtgcaacctggccttcg60
cagatttctgcatggggttgtatctgctcctcatcgcctccgtagacctctacactcagt120
ccgagtactacaaccatgccatcgactggcagacaggccctggctgcaacacagctggct180
tcttcaccgtctttgccagcgagttgtccgtgtacacactgacggtcatcaccttggagc240
gctggtacgccatcacctttgccatgcacctggaccgcaagatccgcctctggcacgcct300
acgtcatcatgctggggggctgggtctgctgcttcctgcttgccctgctccctttggtgg360
gaataagcagctatgccaaggtcagcatctgcctgcccatg401
<210>2
<211>17
<212>dna
<213>人工序列(artificialsequence)
<400>2
tgtacacggacaactcc17
<210>3
<211>17
<212>dna
<213>人工序列(artificialsequence)
<400>3
tgtacacggacaactcg17
<210>4
<211>16
<212>dna
<213>人工序列(artificialsequence)
<400>4
tgtacacggacaactc16
- 还没有人留言评论。精彩留言会获得点赞!