植物表达增强子的制作方法
[0001]
本发明涉及在植物中有活性的表达增强子。本发明还涉及在植物中表达目的蛋白质,并且提供了用于在植物中生产目的蛋白质的方法和组合物。
背景技术:
[0002]
植物作为重组蛋白质的生产系统具有巨大潜力。在植物中产生外源蛋白质的一种方法是产生稳定的转基因植物品系。然而,这是耗时且劳动密集的过程。转基因植物的替代方法是使用基于植物病毒的表达载体。基于植物病毒的载体可使蛋白质在植物中快速、高水平、瞬时表达。
[0003]
使用基于rna植物病毒的载体已经获得了植物中外源蛋白质的高水平瞬时表达,该病毒包括诸如豇豆花叶病毒(cpmv)的豇豆花叶病毒属病毒(参见例如wo2007/135480、wo2009/087391、us2010/0287670,sainsbury f.等人,2008,plant physiology;148:121-1218;sainsbury f.等人,2008,plant biotechnology journal;6:82-92;sainsbury f.等人,2009,plant biotechnology journal;7:682-693;sainsbury f.等人,2009,methods in molecular biology,recombinant proteins from plants,第483卷:25-39)。
[0004]
当豇豆花叶病毒(cpmv)的rna-2的5
′
utr发生修饰时,与野生型cpmv 5
′
utr相比产生了额外的表达增强子活性(如由目标核酸或目标蛋白质的表达水平确定)。例如,cpmv rna-2载体(u162c;ht)中第161位起始密码子的突变提高了由在第512位起始密码子之后插入的序列编码的蛋白质的表达水平。这使得不需要病毒复制产生就可以生产高水平外源蛋白质,称为cpmv-ht系统(wo2009/087391;sainsbury and lomonossoff,2008,plant physiol.148,1212-1218)。在peaq表达质粒(sainsbury等,2009,plant biotechnology journal,7,682~693页;us 2010/0287670)中,待表达的序列位于5
′
utr和3
′
utr之间。peaq系列中的5’utr带有u162c(ht)突变。
[0005]
已经描述了cpmv 5
′
utr区的其他修饰,其进一步提高了植物中目的核酸的表达。例如“cmpv ht+”(包含cpmv 5
′
utr的核苷酸1~160,在位置115-117和位置161-163处具有修饰的atg;wo2015/143567;通过引用并入本文)以及“cpmvx”(长度为x=160、155、150或114个核酸;wo2015/103704;通过引用并入本文)。cmpvx的一个例子是表达增强子“cpmv 160”。与使用操作性地连接“cpmv ht”表达增强子的相同核酸序列产生相同目的蛋白质相比,与“cpmv ht+”操作性地连接的核酸序列的表达导致由该核酸序列编码的目的蛋白质的产生显着增加(参见wo2015/143567的图2和3)。此外,使用操作性地连接“cpmv ht”表达增强子的相同核酸序列产生相同目的蛋白质相比,操作性地连接“cpmv 160”表达增强子的核酸序列的表达导致该核酸序列编码的目的蛋白质的产生显着增加(参见wo2015/143567的图2和图3)。
[0006]
diamos等人(frontiers in plant science,2016,卷171-15页;其通过引用并入本文)描述了几种表达增强子,其可用于提高植物中蛋白质的产量(参见diamos等的表2,包括表达增强子nbpsak2 3
′
)。如diamos等人(2016)的图4所示,与操作性地连接到其他截短
的psak表达增强子的相同核酸序列编码的相同蛋白质的生产相比,操作性地与nbpsak2 3
′
连接的核酸编码的目的蛋白质的生产导致蛋白质提高的蛋白质生产。
技术实现要素:
[0007]
本发明涉及在植物中有活性的表达增强子。本发明还涉及在植物中表达目的蛋白质,本发明还提供了在植物中生产目的蛋白质的方法和组合物。
[0008]
本发明的目的是提供在植物中有活性的改善表达增强子。
[0009]
根据本发明,提供了在植物中有活性的分离的表达增强子,该表达增强子选自:
[0010]
nbmt78(seq id no:1);
[0011]
nbatl75(seq id no:2);
[0012]
nbdj46(seq id no:3);
[0013]
nbchp79(seq id no:4);
[0014]
nben42(seq id no:5);
[0015]
athsp69(seq id no:6);
[0016]
atgrp62(seq id no:7);
[0017]
atpk65(seq id no:8);
[0018]
atrp46(seq id no:9);
[0019]
nb30s72(seq id no:10);
[0020]
nbgt61(seq id no:11);
[0021]
nbpv55(seq id no:12);
[0022]
nbppi43(seq id no:13);
[0023]
nbpm64(seq id no:14);
[0024]
nbh2a86(seq id no:15),以及
[0025]
与seq id no:1~15中任一个所述的核苷酸序列具有90~100%的序列一致性核酸。其中,当该表达增强子操作性地连接到目的核酸(例如目标异源核酸)时使得该目的核酸表达。此外,与未操作性地连接表达增强子或者例如操作性地连接到现有技术表达增强子cpmv 160(seq id no:16)的相同目标核酸或异源核酸的表达水平相比,当该表达增强子操作性地连接到目的核酸(例如目标异源核酸)时,可提高目标核酸或目标异源核酸的表达水平。
[0026]
本公开内容还提供了一种核酸序列,其包含如上所述的分离的表达增强子的一种,该表达增强子与编码目的蛋白质的异源核苷酸序列操作性地连接。该异源核苷酸序列可以编码病毒蛋白质或抗体,例如,不被认为其是限制性的,病毒蛋白质可以是流感蛋白质或诺如病毒蛋白质。如果目的蛋白质是流感蛋白质,那么它可以包括m2、血凝素蛋白质,其选自h1、h2、h3、h4、h5、h6、h7、h8、h9、h10、h11、h12、h13、h14、h15、h16、b型流感血凝素、或其组合。如果目的蛋白质是诺如病毒蛋白质,则其可以包括vp1蛋白质、vp2蛋白质或其组合,选自gi.1、gi.2、gi.3、gi.5、gi.7、gii.1、gii.2、gii.3、gii.4、gii.5、gii.6、gii.7、gii.12、gii.13、gii.14、gii.17和gii.21。
[0027]
本发明还提供了一种植物表达系统,该植物表达系统包含一个或多个上述核酸序列。该植物表达系统可以进一步包含豇豆花叶病毒的3’utr。
[0028]
本发明还提供了一种植物表达系统,该植物表达系统包含上述与异源核酸或核苷酸序列操作性地连接的一个或多个分离的核酸序列。该植物表达系统可以进一步包含豇豆花叶病毒的3’utr。
[0029]
本文还公开了在植物或植物的一部分中产生目的蛋白质的方法,该方法包括将如上所述的植物表达系统引入植物或植物的一部分中,并在允许每条编码目的蛋白质的异源核苷酸序列表达的条件下培养该植物,植物的一部分或植物细胞,所述的植物表达系统包含一条或多条核酸序列。例如,目的蛋白质可以是病毒蛋白质,例如流感蛋白质或诺如病毒蛋白质。如果目的蛋白质是流感蛋白质,那么它可以包括m2、血凝素蛋白质,其选自h1、h2、h3、h4、h5、h6、h7、h8、h9、h10、h11、h12、h13、h14、h15、h16、b型流感血凝素、及其组合。如果目的蛋白质是诺如病毒蛋白质,则其可以包括vp1蛋白质、vp2蛋白质或其组合,选自gi.1、gi.2、gi.3、gi.5、gii.1、gii.2、gii.3、gii.4、gii.5、gii.6、gii.7、gii.12、gii.13、gii.14、gii.17和gii.21。
[0030]
本文还描述了产生目的多聚体蛋白质的方法。该方法涉及以稳定或瞬时的方式在植物、植物的一部分或植物细胞中共表达两个或两个以上的上述核酸序列,其中所述两个或两个以上的每个核酸序列编码多聚体蛋白质的成分,并在允许表达编码目的多聚体蛋白质的每个异源核苷酸序列的条件下培育植物、植物的一部分或植物细胞。
[0031]
本文还提供了用上述植物表达系统瞬时转化或稳定转化的植物、植物的一部分或植物细胞。
[0032]
包含如本文所述的表达增强子的基于植物的表达系统导致目的核酸的表达。此外,包含如本文所述的表达增强子的基于植物的表达系统导致提高或增强编码与该表达增强子操作性地连接的异源开放阅读框的核苷酸序列的表达,该核苷酸是从编码分泌蛋白质(spee)核酸的核酸获得的表达增强子,或由编码胞质蛋白质(cpee)的核酸获得的或表达增强子。可通过比较使用本文所述的表达增强子获得的表达水平与编码异源开放阅读框但未与表达增强子操作性地连接或者例如与现有技术的表达增强子cpmv 160(seq id no:16)操作性地连接的相同核苷酸序列的表达水平来确定表达增加。
[0033]
包含一种或多种如本文所述的表达增强子的基于植物的表达系统、载体、构建体和核酸还可具有多种性质,例如包含用于目的基因或核苷酸序列的合适的克隆位点,它们可以用来以经济有效的方式容易地转化植物,它们可以引起接种植物的有效局部或系统转化。此外,植物的转化可提供有用蛋白质材料的良好产量。
[0034]
本发明的概述不必描述本发明的所有特征。
附图说明
[0035]
通过以下参考附图的描述,本发明的这些和其他特征将变得更加明确,其中:
[0036]
图1a是现有技术,并且显示了通过表达编码这些蛋白质的每一种的核酸而在植物中产生的流感h1加利福尼亚、h3维多利亚、h5印度尼西亚和b威斯康星的相对滴度,其中该核酸操作性地连接cpmv ht表达增强子(wo2009/087391中说明)或cpmv 160+表达增强子(wo2015/103704中说明)。图1b是现有技术,并且显示了通过表达编码这些蛋白质的每一种的核酸而在植物中产生的h1加利福尼亚、h3维多利亚、b布里斯班、b布里斯班+h1tm、b马萨诸塞、b马萨诸塞+h1tm、b威斯康星和b威斯康星+h1tm的相对效价,其中核酸操作性地连接
cpmv ht表达增强子(wo2009/087391中说明)或cpmv 160+表达增强子(wo2015/103704中说明)操作性地连接。图1c是现有技术,并且显示了通过表达编码gfp蛋白质的核酸而在植物中产生的gfp的相对产量,其中该核酸操作性地连接至以下表达增强子:nbpsak2 3
′
(在此称为nbpk74)、atpsak 3
′
(在此称为atpk41)、nbpsakl 3
′
、atpskk、atpsak 5
′
、tmv,nbpsak2和nbpsak1(diamos等人,frontiers in plant science,2016年,第7卷第1-15页)。
[0037]
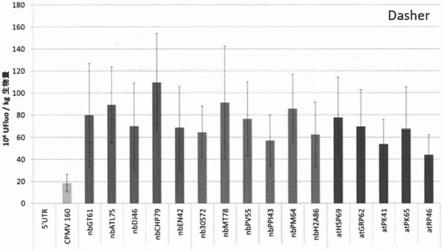
图2显示了通过表达编码dasher蛋白质的核酸而在植物中产生的dasher蛋白质(dasher gfp;fpb-27 269;来自atum)的荧光活性,其中编码dasher蛋白质的核酸与现有技术表达增强子操作性地连接cpmv 160(wo2015/103704中说明)或atpk41(描述于diamos等人,frontiers in plant science.2016,卷7,1~15页)或本发明的表达增强子:nbmt78(seq id no:1)、nbatl75(seq id no:2)、nbdj46(seq id no:3)、nbchp79(seq id no:4)、nben42(seq id no:5)、athsp69(seq id no:6)、atgrp62(seq id no:7)、atpk65(seq id no:8)、atrp46(seq id no:9)、nb30s72(seq id no:10)、nbgt61(seq id no:11)、nbpv55(seq id no:12)、nbppi43(seq id no:13)、nbpm64(seq id no:14)和nbh2a86(seq id no:15)。
[0038]
图3a显示了通过表达编码h1加利福尼亚蛋白质的核酸在植物中产生的h1加利福尼亚/7/09流感病毒的ha滴度,其中编码该蛋白质的核酸操作性地连接现有技术表达增强子cpmv 160(wo2015/103704中说明)或atpk41(描述于diamos等人,frontiers in plant science.2016,卷7,1-15页)中或本发明的表达增强子:nbmt78(seq id no:1)、nbatl75(seq id no:2)、nbdj46(seq id no:3)、nbchp79(seq id no:4)、nben42(seq id no:5)、athsp69(seq id no:6)、atgrp62(seq id no:7)、atpk65(seq id no:8)、atrp46(seq id no:9)、nb30s72(seq id no:10)、nbgt61(seq id no:11)、nbpv55(seq id no:12)、nbppi43(seq id no:13)、nbpm64(seq id no:14)和nbh2a86(seq id no:15)。图3b显示了通过表达编码所示ha蛋白质的核酸在植物中产生的h1 mich/45/15、h3 hk/4801/14、ha b bris/60/08和ha b phu/3073/13的ha效价,其中编码指定蛋白质的每种核酸均与现有技术的表达增强子cpmv 160(描述于wo 2015/103704)或本发明的表达增强子:nbmt78(seq id no:1)、nbatl75(seq id no:2)、nbchp79(seq id no:4)和athsp69(seq id no:6)操作性地连接。
[0039]
图4显示了诺如病毒gii.4/悉尼2012 vp1 vlp在梯度离心后的相对产量,通过表达编码vp1蛋白质的核酸在植物中产生的vlp,其中编码vp1蛋白质的每种核酸操作性地链接至:现有技术表达增强子cpmv 160(在wo 2015/103704中描述),现有技术表达增强子nbpsak2 3
′
(在本文中称为nbpk74;diamos等),或本发明的表达增强子:nbmt78(seq id no:1)、nbatl75(seq id no:2)、nbchp79(seq id no:4)和athsp69(seq id no:6)。
[0040]
图5显示了通过共表达编码利妥昔单抗抗体的轻链(lc)的第一核酸和编码利妥昔单抗抗体的重链(hc)的第二核酸而在植物中产生的利妥昔单抗多聚体蛋白质的相对产量,其与表达增强子的各种组合操作性地连接。关于hc核酸:c160:编码多聚体蛋白质的第一核酸和第二核酸均与现有技术表达增强子cpmv 160操作性地连接(在wo 2015/103704中描述);nbatl75:编码hc多聚体蛋白质的第二条核酸操作性地连接到nbatl75表达增强子,编码lc的第一条核酸操作性地连接到nbmt78(seq id no:1)、nbatl75(seq id no:2)、nbchp79(seq id no:4)和athsp69(seq id no:6)表达增强子中的一个);nbchp79:编码hc多聚体蛋白质的第二条核酸操作性地连接到nbchp79表达增强子,并且编码lc的第一条核
cal-7-09-cpmv 3’utr/nos);图7j显示了构建体4069(2
×
35s-5’utr nbppi43-sppdi-ha0 h1 a-cal-7-09-cpmv 3’utr/nos);图7k示出了构建体4070(2
×
35s-5’utr nbpm64-sppdi-ha0 h1 a-cal-7-09-cpmv 3’utr/nos);图7l显示了构建体4071(2
×
35s-5’utr nbh2a86-sppdi-ha0 h1 a-cal-7-09-cpmv 3’utr/nos);图7m显示了构建体4072(2
×
35s-5’utr athsp69-sppdi-ha0 h1a-cal-7-09-cpmv 3’utr/nos);图7n显示了构建体4073(2
×
35s-5’utr atgrp62-sppdi-ha0 h1 a-cal-7-09-cpmv 3’utr/nos);图7o显示了构建体4074(2
×
35s-5’utr atpk65-sppdi-ha0 h1 a-cal-7-09-cpmv 3’utr/nos的);图7p显示了构建体4075(2
×
35s-5’utr atrp46-sppdi-ha0 h1 a-cal-7-09-cpmv 3’utr/nos);sp:信号肽。
[0043]
图8示出了编码h1-a/密歇根/45/2015的构建体;图8a示出了构建体4013(2
×
35s-5’utr cpmv 160-sppdi-h1a-mich-45-2015-cpmv 3’utr/nos);图8b示出了构建体4701(2
×
35s-5’utr nbatl75-sppdi-h1a-mich-45-2015-cpmv 3’utr/nos);图8c示出了构建体4702(2
×
35s-5’utr nbchp79-sppdi-h1a-mich-45-2015-cpmv 3’utr/nos);图8d示出了构建体4703(2
×
35s-5’utr nbmt78-sppdi-h1a-mich-45-2015-cpmv 3’utr/nos);图8e示出了构建体4704(hsp69-sppdi-h1a-mich-45-2015-cpmv 3’utr/nos处的2
×
35s-5’utr);sp:信号肽。
[0044]
图9示出了编码h3-a/hong kong/4801/14的构建体;图9a示出了构建体4014(2
×
35s-5’utr cpmv 160-sppdi-h3 a-hk-4801-14-cpmv 3’utr/nos);图9b示出了构建体4711(2
×
35s-5’utr nbatl75-sppdi-h3 a-hk-4801-14-cpmv 3’utr/nos);图9c示出了构建体4712(2
×
35s-5’utr nbchp79-sppdi-h3a-hk-4801-14-cpmv 3’utr/nos);图9d显示了构建体4713(2
×
35s-5’utr nbmt78-sppdi-h3 a-hk-4801-14-cpmv 3’utr/nos);图9e示出了构建体4714(2
×
35s-5’utr athsp69-sppdi-h3 a-hk-4801-14-cpmv 3’utr/nos);sp:信号肽。
[0045]
图10示出了编码ha-b/布里斯班/60/08的构建体;图10a示出了构建体4015(2
×
35s-5’utr cpmv 160-sppdi-ha b/bri/60/08-cpmv 3’utr/nos);图10b显示了构建体4721(2
×
35s-5’utr nbatl75-sppdi-ha b/bri/60/08-cpmv 3’utr/nos);图10c显示了构建体4722(2
×
35s-5’utr nbchp79-sppdi-ha b/bri/60/08-cpmv 3’utr/nos);图10d显示了构建体4723(2
×
35s-5’utr nbmt78-sppdi-ha b/bri/60/08-cpmv 3’utr/nos);图10e示出了构建体4724(2
×
35s-5’utr athsp69-sppdi-ha b/bri/60/08-cpmv 3’utr/nos);sp:信号肽。
[0046]
图11示出了编码hab/phu/3073/13的构建体;图11a示出了构建体4016(2
×
35s-5’utr cpmv 160-sppdi-ha0ha b/phu/3073/13-cpmv 3’utr/nos);图11b显示了构建体4731(2
×
35s-5’utr nbatl75-sppdi-ha0 ha b/phu/3073/13-cpmv 3’utr/nos);图11c示出了构建体4732(2
×
35s-5’utr nbchp79-sppdi-ha0 ha b/phu/3073/13-cpmv 3’utr/nos);图11d显示了构建体4733(2
×
35s-5’utr nbmt78-sppdi-ha0 ha b/phu/3073/13-cpmv 3’utr/nos);图11e示出了构建体4734(hsp69-sppdi-ha0 ha b/phu/3073/13-cpmv 3’utr/nos处的2
×
35s-5’utr);sp:信号肽。
[0047]
图12示出了编码vp1-gii.4 sydney 12的构建体;图12a示出了构建体4133(2
×
35s-5’utr cpmv 160-vp1(gii.4syd12)-cpmv 3’utr/nos);图12b示出了构建体4161(2
×
35s-5’utr nbatl75-vp1(gii.4 syd12)-cpmv 3’utr/nos);图12c示出了构建体4162(2
×
35s-5’utr nbchp79-vp1(gii.4 syd12)-cpmv 3’utr/nos);图12d示出了构建体4163(2
×
35s-5’utr nbmt78-vp1(gii.4 syd12)-cpmv 3’utr/nos);图12e示出了构建体4164(在hsp69-vp1(gii.4 syd12)-cpmv 3’utr/nos的2
×
35s-5’utr);
[0048]
图13显示了编码hc igg1的构建体;图13a显示了构建体3191(2
×
35s-5’utr cpmv 160-sppdi-hc igg1-cpmv 3’utr/nos);图13b显示了构建体4643(2
×
35s-5’utr nbatl75-sppdi-hc igg1-cpmv 3’utr/nos);图13c显示了构建体4644(2
×
35s-5’utr nbchp79-sppdi-hc igg1-cpmv 3’utr/nos);图13d显示了构建体4645(2
×
35s-5’utr nbmt78-sppdi-hc igg1-cpmv 3’utr/nos);图13e显示了构建体4646(2
×
35s-5’utr athsp69-sppdi-hc igg1-cpmv 3’utr/nos);sp:信号肽。
[0049]
图14显示了编码lc igg1的构建体;图14a显示了构建体3192(2
×
35s-5’utr cpmv 160-sppdi-lc igg1-cpmv 3’utr/nos);图14b显示了构建体4653(2
×
35s-5’utr nbatl75-sppdi-lc igg1-cpmv 3’utr/nos);图14c显示了构建体4654(2
×
35s-5’utr nbchp79-sppdi-lc igg1-cpmv 3’utr/nos);图14d显示了构建体4655(2
×
35s-5’utr nbmt78-sppdi-lc igg1-cpmv 3’utr/nos);图14e显示了构建体4656(2
×
35s-5’utr athsp69-sppdi-lc igg1-cpmv 3’utr/nos);sp:信号肽。
[0050]
图15a显示了nbmt78的核酸序列(seq id no:1);图15b显示了nbatl75的核酸序列(seq id no:2);图15c显示了nbdj46的核酸序列(seq id no:3);图15d显示了nbchp79的核酸序列(seq id no:4);图15e显示了nben42的核酸序列(seq id no:5);图15f显示了athsp69的核酸序列(seq id no:6);图15g显示了atgrp62的核酸序列(seq id no:7);图15h显示了atpk65的核酸序列(seq id no:8);图15i显示了atrp46的核酸序列(seq id no:9);图15j显示了nb30s72的核酸序列(seq id no:10);图15k显示了nbgt61的核酸序列(seq id no:11);图15l显示了nbpv55的核酸序列(seq id no:12);图15m显示了nbppi43的核酸序列(seq id no:13);图15n显示了nbpm64的核酸序列(seq id no:14);图15o显示了nbh2a86的核酸序列(seq id no:15);图15p显示了cpmv 160的核酸序列(seq id no:16)(现有技术)。
[0051]
图16a显示了用于制备dasher构建体的引物的核酸序列。图16b显示了cpmv 160 5
′
utr-dasher的核酸序列(seq id no:20);图16c显示了dasher的核酸序列(seq id no:78);图16d显示了dasher的氨基酸序列(seq id no:21);图16e显示了从2
×
35s启动子到nos终止子的构建体4467(dasher)的核酸序列(seq id no:75);图16f在t-dna上从左到右显示了dasher构建体1666的克隆载体的核酸序列(seq id no:22)。
[0052]
图17a显示了用于制备h1a cal-7-09、h1a-mich-45-15和h3hk-4801-14、hab-bris-60-08、ha b_phu-3073-13构建体的引物的核酸序列;图17b显示了cpmv 160 5’utr-pdi+h1 cal的核酸序列(seq id no:79);图17c显示了cpmv 160 5’utr-pdi+h1 cal核酸序列的核酸序列(seq id no:80);图17d显示了pdi+h1 cal的氨基酸序列(seq id no:81);图17e在t-dna上从左至右显示了构建体4160的核酸序列,该克隆载体用于制备h3和ha b构建体(seq id no:76)。
[0053]
图18a显示了cpmv 160 5’utr-pdi+h1 mich的核酸序列(seq id no:82);图18b显示了pdi+h1 mich的核酸序列(seq id no:83);图18c显示了pdi+h1 mich的氨基酸序列(seq id no:84);图18d在t-dna上从左至右示出了构建体4170的核酸序列,该克隆载体是
用于制备vp1 gii.4构建体(seq id no:77)。
[0054]
图19a显示了cpmv 160 5
′
utr-pdi+h3hk的核酸序列(seq id no:85);图19b显示了pdi+h3hk的核酸序列(seq id no:86);图19c显示了pdi+h3hk的氨基酸序列(seq id no:87)。
[0055]
图20a显示了cpmv 160 5’utr-pdi+ha b bri的核酸序列(seq id no:88);图20b显示了pdi+ha b bri的核酸序列(seq id no:89);图20c显示了pdi+ha b bri氨基酸序列的氨基酸序列(seq id no:90)。
[0056]
图21a显示了cpmv 160 5’utr-pdi+ha b phu的核酸序列(seq id no:91);图21b显示了pdi+ha b phu的核酸序列(seq id no:92);图21c显示了pdi+ha b phu的氨基酸序列(seq id no:93)。
[0057]
图22a显示了用于制备gii.4 vp1构建体的引物的核酸序列;图22b显示了cpmv 160 5’utr-vp1(gii.4)的核酸序列(seq id no:94);图22c显示了vp1(gii.4)的核酸序列(seq id no:95);图22d显示了vp1(gii.4)的氨基酸序列(seq id no:96)。
[0058]
图23a显示了用于制备利妥昔单抗构建体的引物的核酸序列。图23b显示了cpmv 160 5’utr-pdi+利妥昔单抗hc的核酸序列(seq id no:97);图23c显示了pdi+利妥昔单抗hc的核酸序列(seq id no:98);图23d显示了pdi+利妥昔单抗hc的氨基酸序列(seq id no:99);图23e显示了cpmv 160 5’utr-pdi+利妥昔单抗lc的核酸序列(seq id no:100);图23f显示了pdi+利妥昔单抗lc的核酸序列(seq id no:101);图23g显示了pdi+利妥昔单抗lc的氨基酸序列(seq id no:102)。
具体实施方式
[0059]
以下描述是优选实施方案。
[0060]
如本文中所使用,术语“包括”、“具有”、“包括”和“包含”及其语法变型是包括性的或开放式的,并且不排除另外的、未叙述的要素和/或方法脚步。当在本文中与用途或方法结合使用时,术语“基本上由......组成”表示可以存在另外的要素和/或方法步骤,但是这些添加实质上不影响所列举的方法或用途的功能方式。当在本文中结合用途或方法使用时,术语“由...组成”排除了附加元件和/或方法步骤的存在。在某些实施例中,本文描述为包括某些要素和/或步骤的用途或方法也可以基本上由那些要素和/或步骤组成,而在其他实施例中,由这些要素和/或步骤组成,无论这些实施例是否被具体提及。另外,除非另有说明,单数的使用包括复数,并且“或”表示“和/或”。如本文所用,术语“多个”是指不止一个,例如,两个或更多个、三个或更多个、四个或更多个等。除非本文另外定义,否则本文使用的所有技术和科学术语具有与本领域普通技术人员通常理解的相同含义。如本文所用,术语“约”是指距给定值约+/-10%的变化。应当理解,无论是否特别提及,这种变化总是包含在本文提供的任何给定值中。当在本文中与术语“包含”结合使用时,词语“一”或“一个”的使用可以表示“一个”,但是它也与“一个或多个”、“至少一个”和“一个或多个”的含义一致。
[0061]
如本文所用,术语“植物”、“植物的一部分”、“植物部分”,“植物物质”、“植物生物质”、“植物材料”、“植物提取物”或“植物叶子”可以包含能够提供用于表达本文所述的一种或一种以上核酸的转录、翻译和翻译后修饰机构以及/或者可从中提取和纯化表达的目的蛋白质或vlp的整个植物、组织、细胞或其任何部分,细胞内植物成分、细胞外植物成分、植
物的液体或固体提取物或其组合。植物可以包括但不限于农作物,包括例如油菜籽,芸苔属,玉米,烟草属,(烟草)例如本氏烟(nicotiana benthamiana)、黄花烟草(nicotiana rustica)、普通烟草(nicotiana tabacum)、具翼烟草(nicotiana alata)、拟南芥、紫花苜蓿、马铃薯,地瓜(ipomoea batatus)、人参、豌豆、燕麦、大米、大豆、小麦、大麦、向日葵、棉花、玉米、黑麦(secale graine)、高粱(sorghum bicolor,sorghum vulgare)、红花(carthamus tinctorius)。
[0062]
如本文所用,术语“植物部分”是指植物的任何部分,包括但不限于叶、茎、根、花、果实、愈伤组织或细胞培养的植物组织,植物细胞簇,从叶、茎、根、花、果实中获得的植物细胞,例如植物细胞、植物细胞簇或愈伤组织或培养的植物组织,从叶、茎、根、花、果实中获得的植物提取物或其组合。术语植物细胞是指被质膜限制并且可以包含或可以不包含细胞壁的植物细胞。植物细胞包括原生质体(或原生质球),其包含酶消化的细胞,并且可以使用本领域众所周知的技术获得(例如davey mr等人,2005,biotechnology advances 23:131-171;其通过引用并入本文)。可以使用本领域众所周知的方法产生愈伤组织植物组织或培养的植物组织(例如,mk razdan第二版,science publishers,2003;通过引用并入本文)。本文所用的术语“植物提取物”是指在物理上(例如冷冻,然后在合适的缓冲液中提取),机械地(例如通过研磨或均质化植物或植物的一部分,然后在合适的缓冲液中提取)酶促地(例如使用细胞壁降解酶)、化学地(例如使用一种或多种螯合剂或缓冲剂)或其组合处理植物、植物的一部分、植物细胞或其组合后获得的植物来源的产品。可以进一步处理植物提取物以去除不希望的植物成分,例如细胞壁碎片。可获得植物提取物以帮助从植物、植物的一部分或植物细胞中回收一种或多种组分,例如蛋白质(包括蛋白质复合物、蛋白质超结构和/或vlp)、核酸,来自植物、植物的一部分或植物细胞的脂质、碳水化合物或其组合。如果植物提取物包含蛋白质,则其可以被称为蛋白质提取物。蛋白质提取物可以是粗植物提取物,部分纯化的植物或蛋白质提取物或纯化产物,其包含来自植物组织的一种或多种蛋白质、蛋白质复合物、蛋白质超结构和/或vlp。如果需要,可以使用本领域技术人员已知的技术部分纯化蛋白质提取物或植物提取物,例如,可以对提取物进行盐或ph沉淀、离心、梯度密度离心、过滤、层析,例如尺寸排阻色谱法、离子交换色谱法、亲和色谱法或其组合。也可以使用本领域技术人员已知的技术来纯化蛋白质提取物。
[0063]“目的核苷酸(或核酸)序列”或“目的编码区”是指在植物、植物的一部分或植物细胞中表达以产生目标蛋白质的任何核苷酸序列或编码区(这些术语可互换使用)。这样的目的核苷酸序列可以编码但不限于用于饲料、食品或同时用于饲料和食品的天然或修饰的蛋白质、工业酶或修饰的工业酶、农业蛋白质或修饰的农业蛋白质、辅助蛋白质、蛋白质补充剂、药学活性蛋白质、营养保健品、增值产品或其片段。
[0064]
目的蛋白质可以包含天然或非天然信号肽;非天然信号肽可以是植物来源的。例如,认为是非限制性的,非天然信号肽可获自苜蓿蛋白质二硫键异构酶(pdi sp;登录号z11499的核苷酸32-103)、马铃薯糖蛋白质(pata sp;genbank登录号a08215的位点1738~1806的核苷酸)、猕猴桃碱(act)、烟草半胱氨酸蛋白质酶3前体(cp23)、玉米δzein(δzein)、木瓜蛋白质酶i(papain;pap)和阿拉伯芥(thale cress)半胱氨酸蛋白质酶rd21a(rd21)。天然信号肽可以对应于所表达的目的蛋白质的信号肽。
[0065]
目的核苷酸序列或目的编码区还可以包括编码药学活性蛋白质的核苷酸序列,该
蛋白质譬如生长因子、生长调节剂、抗体、抗原及其片段,或其可用于免疫或预防接种的衍生物等。这样的蛋白质包括但不限于是人类病原体的蛋白质、病毒蛋白质,例如但不限于形成病毒样颗粒(vlp)的抗原,来自诺如病毒、呼吸道合胞病毒(rsv)、轮状病毒、流感病毒、人免疫缺陷病毒(hiv)、狂犬病病毒、人乳头瘤病毒(hpv)、肠病毒71(ev71)或白介素的一种或多种蛋白质,例如il-1至il-24、il-26和il 27、细胞因子、促红细胞生成素(epo)、胰岛素、g-csf、gm-csf、hpg-csf、m-csf或其组合的一种或多种,例如干扰素α、干扰素β、干扰素γ、凝血因子,例如,因子viii、因子ix或tpa hgh、受体、受体激动剂、抗体(例如但不限于利妥昔单抗)、神经多肽、胰岛素、疫苗、生长因子(例如但不限于表皮生长因子、角质形成细胞生长因子、转化生长因子、生长调节剂)、抗原、自身抗原、其片段或其组合。
[0066]
目的蛋白质可以包括流感血凝素(ha;参见wo2009/009876、wo2009/076778、wo2010/003225,其通过引用并入本文)。ha是同型三聚体膜i型糖蛋白质,通常包含信号肽、ha1结构域和ha2结构域,该ha2结构域在c末端具有跨膜的锚定位点和小的胞质尾。编码ha的核苷酸序列是众所周知的并且是可获得的(参见例如biodefense和public health database(流感研究数据库squires等人,2008,nucleic acids research 36:d497-d503)url:biohealthbase-org/gsearch/home.do?decorator=influenza或由国家生物技术信息中心维护的数据库(请参阅url:ncbi.nlm.nih.gov),两者均通过引用并入本文)。
[0067]
ha蛋白质可以是a型流感、b型流感,或是选自h1、h2、h3、h4、h5、h6、h7、h8、h9、h10、h11、h12、h13、h14、h15、h16、h17和h18的a型流感ha的亚型。在本发明的一些方面、ha可以来自a型流感、其选自h1、h2、h3、h5、h6、h7和h9。上面列出的ha的片段也可以视为目标蛋白质。此外、可以将来自以上列出的ha类型或亚型的结构域组合以产生嵌合ha(参见例如wo2009/076778、其通过引用并入本文)。
[0068]
包含ha蛋白质的亚型的实例包括a/新喀里多尼亚/20/99(h1n1)、a/印度尼西亚/5/2006(h5n1)、a/波多黎各/8/34(h1n1)、a/布里斯班/59/2007(h1n1)、a/所罗门群岛3/2006(h1n1)、a/加利福尼亚/04/2009(h1n1)、a/加利福尼亚/07/2009(h1n1)、a/鸡/纽约/1995、a/新加坡/1/57(h2n2)、a/鲱鸥/de/677/88(h2n8)、a/texas/32/2003、a/mallard/mn/33/00、a/鸭/上海/1/2000、a/针尾鸭/tx/828189/02、a/布里斯班10/2007(h3n2)、a/威斯康星/67/2005(h3n2)、a/维多利亚/361/2011(h3n2)、a/德克萨斯/50/2012(h3n2)、a/夏威夷/22/2012(h3n2)、a/纽约/39/2012(h3n2)、a/perth/16/2009(h3n2)、c/约翰内斯堡/66、a/安徽/1/2005(h5n1)、a/越南/1194/2004(h5n1)、a/teal/香港/w312/97(h6n1)、a/equine/布拉格/56(h7n7)、a/土耳其/安大略/6118/68(h8n4)、h7a/杭州/1/2013、a/安徽/1/2013(h7n9)、a/上海/2/2013(h7n9)、a/琵嘴鸭/伊朗/g54/03、a/香港/1073/99(h9n2)、a/鸡/德国/n/1949(h10n7)、a/鸭/英格兰/56(h11n6)、a/鸭/艾伯塔/60/76(h12n5)、a/鸭/马里兰/704/77(h13n6)、a/绿头鸭/gurjev/263/82、a/鸭/澳大利亚/341/83(h15n8)、a/黑头鸥/瑞典/5/99(h16n3)、b/马来西亚/2506/2004、b/佛罗里达/4/2006、b/布里斯班/60/08、b/马萨诸塞/2/2012-类病毒(山形血统)、b/威斯康星/1/2010(山形血统)或b/李/40。
[0069]
该ha也可以是修饰的或嵌合的ha,例如,该ha的天然跨膜结构域可以被异源跨膜结构域取代(其通过引用并入本文的wo2010/148511),该ha可以包括嵌合的胞外域(通过引用并入本文的wo2012/083445),或ha可以包含蛋白质水解环缺失(通过引用并入本文wo2014/153647)。
[0070]
目的蛋白质还可以包括如美国临时申请62/475,660(2017年3月23日提交;通过引用并入本文)或美国临时申请62/593,006(11月11日提交;通过引用并入本文)中所述的诺如病毒蛋白质或修饰的诺如病毒蛋白质。诺如病毒是杯状病毒科的诺如病毒属的无包膜病毒株,其特征在于具有单链的正义链rna。诺如病毒株可以包括任何已知的诺如病毒株,还可以包括随着时间而定期地产生的对已知的诺如病毒株的修饰。例如,诺如病毒株可以包括gi.1、gi.2、gi.3、gi.5、gi.7、gii.1、gii.2、gii.3、gii.4、gii.5、gii.6、gii.7、gii.12、gii.13、gii.14、gii.17和gii.21,例如但不限于hu/gi.1/美国/norwalk/1968、hu/gi.2/鲁汶/2003/bel、hu/gi.3/s29/2008/lilla edet/瑞典、hu/gi.5/siklos/hun5407/2013/hun、hu/gii.1/ascension208/2010/美国、hu/gii.2/cgmh47/2011/tw、hu/gii.3/荆州/2013402/中国、hu/gii.4/悉尼/nsw0514/2012/澳大利亚、us96/gii.4/dresden174/1997/de_ay741811、fh02/gii.4/farmingtonhills/2002/us_ay502023、hnt04:gii.4/hunter-nsw504d/2004/au_dq078814、2006b:gii.4/shellharbour-nsw696t/2006/au_ef684915、no09:gii.4/orange-nsw001p/2008/au_gq845367、hu/gii.5/albertaei390/2013/ca、hu/gii.6/俄亥俄/490/2012/usa、gii.7/musa/2010/all73774、hu/gii.12/hs206/2010/美国、gii.13/va173/2010/h9awu4、gii.14_saga_2008_jpn_ade28701原生vp1、hu/gii.17/kawasaki323/2014/日本和hu/gii.21/salisbury150/2011/usa。诺如病毒株还包括与任何上述诺如病毒株具有与vp1蛋白质、vp2蛋白质或vp1和vp2蛋白质两者具有约30~100%或之间的任何氨基酸序列一致性的菌株。
[0071]
当提及特定序列时,使用术语“相似度百分比”、“序列相似度”、“一致性百分比”或“序列一致性”,例如在威斯康星大学gcg软件程序中阐述的,或通过手动比对和目视检查(参见,例如current protocols in molecular biology,ausubel等人,eds.1995增刊)。用于比较的序列比对方法是本领域众所周知的。可以使用例如smith&waterman(1981,adv.appl.math.2:482)的算法、needleman&wunsch,(1970,j.mol.biol.48:443)的比对算法,通过搜索pearson&lipman(1988,proc。natl.acad.sci.usa 85:2444)的相似性方法,通过这些算法的计算机化实现(例如:gap,bestfit,fasta和威斯康星遗传学软件包中tfasta,位于威斯康星州麦迪逊市575 science dr.遗传学计算机组(gcg)),进行用于比较的序列的最佳比对。
[0072]
适用于确定百分比序列一致性和序列相似性的算法的例子是blast和blast 2.0算法,其分别描述于altschul等人(1977,nuc.acids res。25:3389-3402)和altschul等人(1990,j.mol.biol.215:403-410)。具有本文所述参数的blast和blast 2.0用于确定本发明核酸和蛋白质的序列一致性百分比。例如,blastn程序(用于核苷酸序列)可以默认使用字长(w)为11,期望(e)为10,m=5,n=-4以及两条链的比较作为默认值。对于氨基酸序列,blastp程序可以使用默认值,单词长度3和期望值(e)10以及blosum62评分矩阵作为默认值(请参见henikoff&henikoff,1989,proc.natl.acad.sci.usa 89:10915)的比对(b)为50,预期(e)为10,m=5,n=-4,以及两条链的比较。可通过国家生物技术信息中心(网址:ncbi.nlm.nih.gov/)公开获得进行blast分析的软件。
[0073]
如本文所用,术语“核酸区段”是指编码目的蛋白质的核酸序列。除核酸序列外,核酸片段还包含与核酸序列可操作连接的调节区和终止子。调节区可包含启动子和与启动子可操作连接的增强子元件(表达增强子)。
[0074]
如本文所用,术语“核酸复合物”是指两个或两个以上核酸区段的组合。单个核酸中可以存在两个或两个以上的核酸片段,从而核酸复合物包含两个或两个以上的核酸片段,每个核酸片段都在调节区和终止子的控制下。备选地,核酸复合物可以包含两个或更多个分离的核酸,每个核酸包含一个或多个一个核酸片段,其中每个核酸片段在调节区和终止子的控制下。例如,核酸复合物可以包含一个包含两个核酸片段的核酸,核酸复合物可以包含两个核酸,每个核酸包含一个核酸片段,或者核酸复合物可以包含两个或两个以上核酸,每个核酸包含一个或多个核酸片段。
[0075]
如本文所用,术语“载体”或“表达载体”是指用于将外源核酸序列转移到宿主细胞(例如植物细胞)中并指导宿主细胞中外源核酸序列表达的重组核酸。可以将载体直接引入植物、植物的一部分或植物细胞中,或者可以将载体中作为植物表达系统的一部分引入植物、植物的一部分或植物细胞。该构建体或表达构建体包含核苷酸序列,该核苷酸序列包含在合适的启动子、表达增强子或用于调控目的核酸的在宿主细胞中转录的其他元件的控制下以及与其可操作(或操作性地)连接的目的核酸。如本领域技术人员将理解的,构建体或表达框架可包含终止序列(终止子),其是在植物宿主中有活性的任何序列。例如,终止序列可以衍生自二重(bipartite)rna病毒的rna-2基因组区段,例如豇豆黄花叶病毒。终止序列可以是nos终止子,该终止子序列可以从苜蓿质体蓝素蛋白质基因的3’utr或其组合中获得。
[0076]
本公开的构建体可以进一步包含3’非翻译区(utr)。3’非翻译区含有聚腺苷酸化信号和任何其他能够影响mrna加工或基因表达的调节信号。聚腺苷酸化信号的特征通常是通过在mrna前体的3’末端添加聚腺苷酸径迹(tracks)来实现的。聚腺苷酸化信号通常是通过与5’aataaa-3’的规范形式存在同源性来识别的,尽管变体并不罕见。合适的3’区域的非限制性实例是包含农杆菌肿瘤诱导(ti)质粒基因的多腺苷酸化信号的3’转录的非翻译区域,该基因例如胭脂碱合酶(nos基因)和植物基因例如大豆贮藏蛋白质、核糖1,5-二磷酸羧化酶基因的小亚基(ssrubisco;us4,962,028;通过引用并入本文),用于调节质体蓝素蛋白质表达的启动子和/或终止子。
[0077]
例如,不被认为是限制性的,cpmv 3’utr+nos终止子可以用作3’utr序列,其操作性地连接至编码目的蛋白质的核酸序列的3’端。
[0078]“调节区”、调节元件”或“启动子”是指核酸的一部分,通常但并非总是在基因的蛋白质编码区的上游,其可以由dna或rna组成,或是dna和rna组成。当调节区有活性,并且与目的核苷酸序列操作性地关联或操作性地连接时,这可导致目的核苷酸序列的表达。调节元件可能能够介导器官特异性,或控制发育或时间基因激活。“调节区”包括启动子元件、表现出基础启动子活性的核心启动子元件、响应于外部刺激而可诱导的元件、介导启动子活性的元件、例如负调控元件或转录增强子。如本文所用,“调节区”还包括在转录后有活性的元件,例如调节基因表达的调节元件,例如翻译和转录增强子、翻译和转录阻遏物、上游激活序列和mrna不稳定性决定簇。这些后面的元件中的几个可以位于编码区域的近端。
[0079]
在本公开的上下文中,术语“调控元件”或“调控区”通常是指dna序列,通常但不总是在结构基因的编码序列的上游(5’),通过提供对rna聚合酶和/或转录从特定位点开始所需的其他因子的识别,来控制编码区的表达。然而,应理解,位于内含子内或该序列的3’的其他核苷酸序列也可有助于调节目的编码区的表达。提供对rna聚合酶或其他转录因子的
识别以确保在特定位点起始的调节元件的实例是启动子元件。大多数但不是全部的真核启动子元件都含有tata盒,这是一个保守的核酸序列,该核酸序列由腺苷和胸苷核苷酸碱基对组成,通常位于转录起始位点上游约25个碱基对。启动子元件可包括负责转录起始的基础启动子元件,以及修饰基因表达的其他调节元件。
[0080]
有几种类型的调节区,包括发育调节的、可诱导的或组成型的。在器官或组织的某些发育过程中的特定时间,在某些器官或器官的组织内激活了发育调节或控制受其控制的基因的差异表达的调控区。然而,一些发育受到调节的调节区域可能在特定发育阶段优先在某些器官或组织内有活性,它们也可能以发育受调节的方式或在植物内其他器官或组织的基础水平上有活性。组织特异性调控区,例如种子特异性调控区的实例包括napin启动子和十字花科素启动子(rask等,1998,j.plant physiol.152:595-599;bilodeau等,1994,plant cell 14:125-130)。叶特异性启动子的实例包括质体蓝素蛋白质启动子(参见us7,125,978,其通过引用并入本文)。
[0081]
诱导型调控区是能够响应于诱导剂而直接或间接激活一个或多个dna序列或基因的转录区域。在没有诱导物的情况下,dna序列或基因将不会被转录。通常,特异性结合可诱导的调节区以激活转录的蛋白质因子可以以无活性形式存在,然后通过诱导剂直接或间接转化为活性形式。然而,蛋白质因子也可能不存在。诱导剂可以是化学试剂,例如蛋白质、代谢产物、生长调节剂、除草剂或酚类化合物,也可以是由热、冷、盐或有毒元素直接施加或通过病原体或疾病因子(例如病毒)激活的生理胁迫。通过将诱导物从外部施加到细胞或植物上,例如通过喷雾、浇水、加热或类似方法,可将含有诱导性调控区的植物细胞暴露于诱导物。诱导型调控元件可源自植物或非植物基因(例如,gatz,c.和lenk,i.r.p.,1998,trends plant sci.3,352-358)。潜在的诱导型启动子的实例包括但不限于四环素诱导型启动子(gatz,c.,1997,ann.rev.plant physiol.plant mol.biol.48,89-108),类固醇诱导型启动子(aoyama,t.and chua,nh,1997,plant j.2,397-404)和乙醇诱导型启动子(salter,m.g.等,1998,plant journal 16,127-132;caddick,mx等,1998,nature biotech.16,177-180)细胞分裂素诱导性ib6和cki1基因(brandstatter,i.and kieber,jj,1998,plant cell 10,1009-1019;kakimoto,t.,1996,science 274,982-985)和生长素诱导元件dr5(ulmasov,t。等,1997,plant cell 9,1963-1971)。
[0082]
组成型调节区调节基因在植物的各个部分中表达以及在整个植物发育中连续地表达。已知的组成性调控元件的实例包括与camv 35s转录物相关的启动子(p35s;odell等,1985,nature,313:810-812;通过引用并入本文)、水稻肌动蛋白质1(zhang等,1991,plant cell,3:1155-1165)、肌动蛋白质2(an等,1996,plant j.,10:107-121)或tms 2(us 5,428,147)和磷酸三糖异构酶1(xu等,1994,plant physiol.106:459-467)基因、玉米泛素1基因(cornejo等,1993,plant mol.biol.29:637-646)、拟南芥泛素1和6基因(holtorf等,1995,plant mol.biol.29:637-646)、烟草翻译起始因子4a基因(mandel等,1995 plant mol.biol.29:995-1004)、木薯花叶病毒启动子pcas(verdaguer等,1996)、核糖二磷酸羧化酶小亚基的启动子prbcs:(outchkourov等,2003)、pubi(用于单子叶植物和双子叶植物)。
[0083]
本文所用的术语“组成型”不一定指示在所有细胞类型中组成性调节区控制下的核苷酸序列均以相同水平表达,而是该序列在多种细胞类型中表达,尽管经常观察到丰度的变化。
[0084]
如上所述的构建体或表达构建体可以存在于载体(或表达载体)中。载体可以包含边界序列,其允许表达框架转移和整合到生物体或宿主的基因组中。该构建体可以是植物二元载体,例如基于ppzp的二元转化载体(hajdukiewicz等,1994)。构建体的其他实例包括pbin19(参见frisch,d.a.,l.w.harris-haller等,1995,plant molecular biology 27:405-409)。
[0085]
编码蛋白质的目的核苷酸序列需要存在位于要表达的基因上游的“翻译起始位点”或“起始位点”或“翻译开始位点”或“开始位点”或“起始密码子”。这样的起始位点可以作为增强子序列的一部分或作为编码目的蛋白质的核苷酸序列的一部分。
[0086]
如本文所用,术语“天然”、“天然蛋白质”或“天然结构域”是指具有与野生型相同的一级氨基酸序列的蛋白质或结构域。天然蛋白质或结构域可以由与野生型序列具有100%序列相似性的核苷酸序列编码。与野生型核苷酸序列相比,天然氨基酸序列还可以由人类密码子(hcod)优化的核苷酸序列或包含增加的gc含量的核苷酸序列编码,条件是由hcod核苷酸序列编码的氨基酸序列具有与天然氨基酸序列100%的序列一致性。
[0087]
通过“人类密码子优化的”或“hcod”核苷酸序列的核苷酸序列,是指选择合适的dna核苷酸以合成寡核苷酸序列或其片段,该寡核苷酸序列或其片段邻近通常在人核苷酸序列的寡核苷酸序列发现使用的密码子。“增加的gc含量”是指选择合适的dna核苷酸用于合成寡核苷酸序列或其片段,以便接近密码子使用,当与相应的天然寡核苷酸序列相比时,该密码子使用包括gc含量的增加,例如在寡核苷酸序列的编码部分的长度上为约1%至约30%,或它们之间的任何量。例如,在寡核苷酸序列的编码部分的长度上,从大约1、2、4、6、8、10、12、14、16、18、20、22、24、26、28、30%或它们之间的任何数量开始寡核苷酸序列的序列。如下所述,人密码子优化的核苷酸序列或包含增加的gc含量的核苷酸序列(当与野生型核苷酸序列相比时)与非人类优化(或较低的gc含量)核苷酸序列的表达相比,在植物、植物的一部分或植物细胞内表现出增加的表达。
[0088]
如本文所用,术语“单个构建体”或“单构建体”是指包含单个核酸序列的核酸。如本文所用,术语“双构建体”或“双重构建体”是指包含两个核酸序列的核酸。
[0089]
共表达是指两个或多个核苷酸序列的引入和表达,两个或多个核苷酸序列中的每一个编码植物中、植物的一部分或植物细胞中的目的蛋白质或目的蛋白质的片段。可以在一个载体内将两个或更多个核苷酸序列引入植物、植物的一部分或植物细胞中,使得两个或更多个核苷酸序列中的每一个都在单独的调节区的控制下(例如包含双重构建体)。或者,可在单独的载体(例如包含单个构建体)内将两个或多个核苷酸序列引入到植物、植物的一部分或植物细胞中,并且每个载体包含用于表达相应核酸的合适的调控区。例如在真空渗透之前,可以通过将每种根癌农杆菌宿主的悬浮液以期望的体积(例如相等的体积或比例的比例)混合来共表达两个核苷酸序列,每个核苷酸序列在单独的载体上并被引入单独的根癌土壤杆菌宿主中。以这种方式,多个根癌农杆菌悬浮液的共渗入允许多个转基因的共表达。
[0090]
如本文所述,编码目的蛋白质的核酸可进一步包含增强目的蛋白质在植物、植物的一部分或植物细胞中表达的序列。本文描述了增强表达的序列,并且例如可以包括一种或多种从编码分泌蛋白质(spee)的核酸获得的表达增强元件或从编码胞质蛋白质(cpee)的核酸获得的表达增强元件,与编码目标蛋白质的核酸有效结合。如本文所述使用表达增
强剂表达分泌蛋白质的非限制性实例包括任何目标蛋白质,其包括将目标蛋白质靶向细胞外隔室的信号肽或信号序列,例如抗体(参见图5),或已知从质膜上萌发的病毒样颗粒(vlp),例如ha流感(请参见图3a和3b)。胞质产生的蛋白质的非限制性实例包括不包含分泌肽或信号序列(参见例如图2)的任何目的蛋白质,或已知在胞质溶胶中产生并保留在其内的vlp,例如诺如病毒(请参见图4)。
[0091]
还可以针对人类密码子使用、增加的gc含量或其组合来优化编码目的蛋白质的序列。共表达编码第二种目的蛋白质的核酸可导致功能性多聚体蛋白质,例如包含重链和轻链成分的抗体,或增加蛋白质的产量。如果目的蛋白质导致产生vlp,则两种或更多种蛋白质的共表达可导致包含目的蛋白质的vlp的产量增加、密度增加、完整性提高或其组合。可以通过将使用本文所述的表达增强子获得的产量、密度、完整性或其组合与编码异源开放阅读框但不与表达增强子操作性地连接或者例如当与现有技术表达增强子cpmv 160操作性地连接时(seq id no:16)的相同核苷酸序列的产量、密度、完整性或其组合进行比较来确定产量、密度、完整性或其组合的增加。
[0092]
还提供了一种植物表达系统,其包含核酸,该核酸包含与本文所述的一个或多个表达增强子操作性地连接的调节区以及目的核苷酸序列。该植物表达系统可以包含一种或多种载体,一种或多种构建体或一种或多种核酸,其包含与一种或多种本文所述的表达增强子和核苷酸序列或目的核酸可操作连接的调节区,以及可引入植物、植物的一部分或植物细胞的其他成分。感兴趣的核酸或目标核酸。例如,植物表达系统还可以包含其他载体、构建体或核酸,包含用于共表达的载体、构建体或核酸的其他农杆菌,一种或多种改变转化效率的化合物,其他成分,或其组合。
[0093]
此外,描述了包含与包括本文所述的表达增强子的表达增强子操作性地连接的启动子(调节区)序列的核酸,以及感兴趣的核苷酸序列。核酸可以进一步包含编码3’utr(例如豇豆花叶病毒3’utr或质体蓝素蛋白质3’utr)的序列和终止子序列(例如nos终止子),以便将目的核苷酸序列插入上游从3’utr的上游。
[0094]
当本文中所指的“表达增强剂”、“增强子序列”或“增强子元件”与目的核酸,例如目的异源核酸操作性地连接时,导致目的核酸的表达。表达增强子还可增强或增加它们所连接的下游异源开放阅读框(orf)的表达。表达增强子可以在增强子序列的5’末端与在植物中有活性的调节区操作性地连接,并在表达增强子的3’末端与目的核苷酸序列操作性地连接,以驱动目的核苷酸序列在宿主,例如植物、植物的一部分或植物细胞内的表达。本文所述的表达增强子包括衍生自以下序列、与以下核苷酸序列具有序列相似性的序列以及选自以下序列的核苷酸序列:nbmt78(seq id no:1)、nbatl75(seq id no:2)、nbdj46(seq id no:3)、nbchp79(seq id no:4)、nben42(seq id no:5)、athsp69(seq id no:6)、atgrp62(seq id no:7)、atpk65(seq id no:8)、atrp46(seq id no:9)、nb30s72(seq id no:10)、nbgt61(seq id no:11)、nbpv55(seq id no:12)、nbppi43(seq id no:13)、nbpm64(seq id no:14)、和nbh2a86(seq id no:15)。
[0095]“操作性地连接”是指特定序列直接或间接相互作用以实现预期的功能,例如介导或调节核酸序列的表达。操作性地连接的序列的相互作用可以例如由与操作性地连接的序列相互作用的蛋白质介导。
[0096]
术语“5’utr”或“5’非翻译区”或“5’前导序列”是指未翻译的mrna区域。5’utr通常
在转录起始位点开始,并在翻译起始位点或编码区的起始密码子(通常是mrna中的aug,dna序列中是atg)前结束。5’utr可能会调节mrna转录物的稳定性和/或翻译。如果需要,可以通过突变(例如5’utr的取代、缺失或插入)来改变5’utr的长度。
[0097]
表达增强子可以进一步包含一个或多个“一个或多个限制位点”或“一个或多个限制识别位点”、“多个克隆位点”、“mcs”、“一个或多个克隆位点”、“多接头序列”或“多接头”以促进目的核苷酸插入植物表达系统。限制位点是被限制酶识别的特定序列基序,并且是本领域众所周知的。表达增强子可以包含一个或多个位于5’utr下游(3’)的限制位点或克隆位点。多接头序列(多个克隆位点)可以包含可用于向5’utr的3’末端添加和去除核酸序列的任何核酸序列,包括编码目的蛋白质的核苷酸序列。多接头序列可包含4至约100个或其间的任何数量的核酸。如对本领域技术人员显而易见,可以使用任何多克隆位点(mcs)或不同长度(较短或更长)的mcs。
[0098]
还提供了使用一种或多种本文所述的表达增强子在植物中产生一种或多种目的蛋白质的表达系统或载体。本文所述的表达系统包括一种表达盒,该表达盒包含一种或多种表达增强子,或一种序列,该序列具有与一种或多种表达增强子80~100%或它们之间的任何量的序列相似性。包含表达增强子的表达盒可以进一步包含在植物中有活性的调控区域,该调控区域操作性地连接到表达增强子的5’末端。目的核苷酸序列可以操作性地连接至表达框架的3’末端,使得当引入植物、植物的一部分或植物细胞内时,可以实现目的核苷酸序列在植物内的表达。
[0099]
本发明还提供了植物、植物的一部分、植物细胞、植物组织、整株植物、接种物、核酸、包含编码目的蛋白质的目的核苷酸序列的构建体,包含一种或多种如上所述的表达增强子的表达框架或表达系统,在植物、植物的一部分或植物细胞中表达目的蛋白质的方法。
[0100]
可以使用ti质粒、ri质粒、植物病毒载体、直接dna转化,显微注射、电穿孔、浸润等以稳定或瞬时的方式将本发明的构建体引入植物细胞。对于这种技术的综述,参见例如weissbach和weissbach,methods for plant molecular biology,academy press,纽约viii,第421-463页(1988);geierson和corey,plant molecular biology,第二版(1988);以及miki和iyer,fundamentals of gene transfer in plants;in plant metabolism,第二版,dt.dennis,dh turpin,dd lefebrve,db layzell(eds),addison-wesley,langmans ltd.伦敦,第561~579页(1997)。其他方法包括直接摄取dna、使用脂质体、电穿孔(例如使用原生质体)、显微注射、微粒或晶须以及真空浸润。参见例如bilang等,(gene 100:247-250(1991),scheid等(mol.gen.genet.228:104-112,1991),guerche等(plant science 52:111-116,1987);neuhause等,(theor.appl genet.75:30-36,1987);klein等人,nature 327:70-73(1987);howell等人(science 208:1265,1980);horsch等人(science 227:1229-1231,1985);deblock等,plant physiology,91:694-701,1989),methods for plant molecular biology(weissbach和weissbach,编辑,academic press inc.,1988);methods in plant molecular biology(schuler and zielinski eds,academic press inc.,1989),liu and lomonossoff(j.virol meth,105:343-348,2002);美国专利第4,945,050号;5,036,006、5,100,792、6,403,865、5,625,136(通过引用将其全部结合在此)。
[0101]
瞬时表达方法可用于表达本发明的构建体(参见liu和lomonossoff,2002,journal of virological methods,105:343-348;通过引用并入本文)。可选择地,可以使
用基于真空的瞬时表达方法(如kapila等人所述,1997,以引用方式并入本文)。这些方法可以包括例如但不限于农杆菌接种或农杆菌渗入的方法,但是如上所述,也可以使用其他瞬时方法。通过农杆菌接种或农杆菌浸润,包含所需核酸的农杆菌混合物进入组织的细胞间空间,例如叶子、植物的空中部分(包括茎、叶和花),植物的其他部分(茎、根、花)或整个植物。穿过表皮后,土壤杆菌感染并将t-dna拷贝转移到细胞中。t-dna被游离转录,mrna被翻译,从而在感染的细胞中产生目的蛋白质,但是t-dna在细胞核内的传递是短暂的。
[0102]
如果目的核苷酸序列编码对植物有直接或间接毒性的产物,那么通过使用本发明的方法,可以通过在植物中选择性表达目的核苷酸序列来在所需的组织或植物发育的所需阶段降低整个植物的这种毒性。另外,由瞬时表达导致的有限表达时间可减小在植物中产生有毒产物时的作用。诱导型启动子、组织特异性启动子或细胞特异性启动子可用于选择性地指引(direct)目的序列的表达。
[0103]
可以使用多种方法将目的核苷酸序列与包含植物调控区的增强子序列融合(操作性地连接)。例如,不被认为是限制性的,可以将编码目的蛋白质的目的核苷酸序列融合到紧邻5’utr序列后面的表达增强子的3’末端。
[0104]
本文所述的表达增强子的实例包括:
[0105]
nbmt78(seq id no:1);
[0106][0107]
nbatl75(seq id no:2);
[0108][0109]
nbdj46(seq id no:3);
[0110][0111]
nbchp79(seq id no:4);
[0112][0113]
nben42(seq id no:5);
[0114][0115]
athsp69(seq id no:6);
[0116][0117]
atgrp62(seq id no:7);
[0118][0119]
atpk65(seq id no:8);
no:2)、nbdj46(seq id no:3)、nbchp79(seq id no:4)、nben42(seq id no:5)、athsp69(seq id no:6)、atgrp62(seq id no:7)、atpk65(seq id no:8)、atrp46(seq id no:9)、nb30s72(seq id no:10)、nbgt61(seq id no:11)、nbpv55(seq id no:12)、nbppi43(seq id no:13)、nbpm64(seq id no:14)和nbh2a86(seq id no:15)与编码目的蛋白质的核酸序列可操作连接时,观察到导致类似或增加的蛋白质表达,dasher(dasher gfp;fpob-27e-269;atum.bio),图2),流感血凝素h1 a(图3a)、h1 mich/45/15、h3 hk/4801/14+cystm、ha b bris/60/08或ha b phu/3073/13(图3b),当与现有技术的表达增强子序列cmpv 160(seq id no:16;wo 2015/103704)的活性进行比较时,操作性地连接至编码相同目的蛋白质的相同核酸序列在相似条件下或指定的位置表达,与现有技术中操作性地连接至编码目的蛋白质的相同核酸序列并在相似的条件下表达的表达增强子序列atpk41的活性相比(称为atpsak 3’,diamos等人,frontiers in plant science.2016,卷7,1~15页)。
[0138]
图1a和1b显示了与编码目的蛋白质的核酸序列可操作连接的现有技术表达增强剂cpmv 160(seq id no:16)相对于现有技术表达增强剂cpmv-ht的活性。cpmv ht增强子元件是指编码调节豇豆花叶病毒(cpmv)rna2多肽或修饰的cpmv序列的5’utr的核苷酸序列,如wo2009/087391中所述;sainsbury f.和lomonossoff g.p.(2008年,plant physiol.148:1212-1218页)。cpmv 160表达增强剂是指包含来自cpmv rna2的截短的5’utr的核苷酸序列,如wo2015/103704中所述。cpmv 160+和cpmv 160+表达增强子均包含cmpv rna2的5’utr的前160个核酸,但是cpmv 160+表达增强子在3’末端还包含多克隆位点和植物kozak序列。
[0139]
因此,本文描述的表达增强子可以在植物表达系统中使用,该植物表达系统包括与表达增强子序列和目的核苷酸序列可操作连接的调节区。
[0140]
例如,本发明提供了产生目的蛋白质或增加目的蛋白质产量的方法,该目的蛋白质例如但不限于植物中的流感ha蛋白质、修饰的流感ha蛋白质,诺如病毒蛋白质或经修饰的诺如病毒蛋白质。该方法包括将包含本文所述的表达增强子的核酸操作性地连接至编码目的蛋白质例如流感ha蛋白质、修饰的流感ha蛋白质、诺如病毒蛋白质或经修饰的诺如病毒蛋白质的核苷酸序列引入植物、植物的一部分或植物细胞,并以瞬时或稳定的方式在植物、植物的一部分或植物细胞中表达蛋白质。其中,可通过比较操作性地连接至表达增强子的核苷酸序列的表达水平与未可操作性连接至表达增强子或者例如当与现有技术的表达增强子cpmv 160(seq id no:6)操作性地连接时的相同核苷酸序列的表达水平来确定表达的增加。或者该方法可以包括提供植物、该植物的一部分或植物细胞,其包含与编码目的蛋白质例如流感ha蛋白质、修饰的流感ha蛋白质、诺如病毒蛋白质、修饰的诺如病毒蛋白质或多聚体蛋白质的核苷酸序列操作性地连接的本文所述的表达增强子,并以瞬时或稳定的方式在植物、植物的一部分或植物细胞中表达编码该蛋白质的核酸。
[0141]
此外,本发明提供了包含目的蛋白质例如流感ha蛋白质、修饰的流感ha蛋白质、诺如病毒蛋白质或经修饰的诺如病毒蛋白质的植物物质、植物提取物或蛋白质提取物。植物物质、植物提取物或蛋白质提取物可用于诱导例如针对受试者的流感或诺如病毒感染的免疫。或者,可以纯化或部分纯化目的蛋白质,例如流感ha蛋白质、修饰的流感ha蛋白质、诺如病毒蛋白质或修饰的诺如病毒蛋白质,并且纯化或部分纯化的制剂可用于诱导免疫力,例如针对受试者中的流感或诺如病毒感染,或目标蛋白质,例如流感ha蛋白质、修饰的流感ha
蛋白质、诺如病毒蛋白质或修饰的诺如病毒蛋白质,可以用于诱导免疫应答的组合物和药学上可接受的载体、佐剂、载剂或赋形剂。
[0142]
本文所述的表达增强子可以用于产生任何目的蛋白质或用于产生病毒样颗粒(vlp)。例如,参考图4,显示了本文所述的几种表达增强剂对于产生诺如病毒vlp是有效的。
[0143]
因此,本发明还提供了在植物中产生或增加包含流感ha蛋白质、修饰的流感ha蛋白质、诺如病毒蛋白质或经修饰的诺如病毒蛋白质的vlp的方法。例如,该方法可以包括以瞬时或稳定的方式将包含操作性地连接编码流感ha蛋白质、修饰的流感ha蛋白质、诺如病毒蛋白质或修饰的诺如病毒蛋白质的核苷酸序列的本文所述的表达增强子的核酸引入植物、植物的一部分或植物细胞中,并在植物、植物一部分或植物细胞的中表达该蛋白质,以产生包含流感ha蛋白质、修饰的流感ha蛋白质、诺如病毒蛋白质或修饰的诺如病毒蛋白质的vlp。可通过比较操作性地连接至表达增强子的核苷酸序列的表达水平与未可操作性连接至表达增强子或者例如操作性地与现有技术的表达增强剂cpmv 160(seq id no:16)连接的相同核苷酸序列的表达水平来确定表达的增加。或者该方法可包括提供一种植物、该植物的一部分或植物细胞,其包含与编码流感ha蛋白质、修饰的流感ha蛋白质、诺如病毒蛋白质或修饰的诺如病毒蛋白质的核苷酸序列操作性地连接的本文所述的表达增强子,并表达编码该蛋白质的核酸以产生包含流感ha蛋白质、修饰的流感ha蛋白质、诺如病毒蛋白质或经修饰的诺如病毒蛋白质的vlp。
[0144]
此外,本发明提供包含vlp的植物物质、植物提取物或蛋白质提取物,该vlp包含流感ha蛋白质、修饰的流感ha蛋白质、诺如病毒蛋白质或经修饰的诺如病毒蛋白质。植物物质、植物提取物或蛋白质提取物可用于在受试者中诱导对诺如病毒感染的免疫。或者,可纯化或部分纯化包含流感ha蛋白质、修饰的流感ha蛋白质、诺如病毒蛋白质或修饰的诺如病毒蛋白质的vlp,并且纯化或部分纯化的制剂可用于在受试者中诱导对诺如病毒感染的免疫力,或者包含流感ha蛋白质、修饰的流感ha蛋白质、诺如病毒蛋白质或经修饰的诺如病毒蛋白质的vlp可在用于诱导免疫应答的组合物中以及药学上可接受的载体、佐剂、载剂或赋形剂中。
[0145]
本文所述的表达增强子也可以用于产生目的蛋白质的多聚体,例如抗体。如参考图5所示,当每条核酸序列与本文所述的相同或不同的表达增强子操作性地连接时,可以在植物中共表达编码抗体的轻链(lc)和重链(hc)的两条核酸,例如利妥昔单抗。例如,共表达与表达增强子nbatlk75操作性地连接的编码利妥昔单抗的hc的第一核酸以及可操作连接相同表达增强子nbatlk75、或不同的表达增强子nbchp79、nbmt78或athsp69的编码利妥昔单抗的lc的第二核酸时,导致与共表达编码相同hc和lc序列的第一核酸和第二核酸相比(第一核酸和第二核酸的每条操作性地与现有技术表达增强子cpmv 160(seq id no:16)连接),多聚体蛋白质表达或多聚体蛋白质表达增加。如图5所示,当使用本文所述的表达增强子的其他组合共表达第一和第二核酸时,观察到相似的结果。
[0146]
因此,本发明还提供了在植物中产生或增加多聚体蛋白质产生的方法。例如,该方法可以涉及以瞬时或稳定的方式将包含与编码第一蛋白质组分的核苷酸序列操作性地连接的本文所述的表达增强子的第一核酸和包含操作性地与编码第二种蛋白质成分的核苷酸序列连接的本文所述的表达增强子的第二核酸引入植物、植物的一部分或植物细胞中,并在植物、植物的一部分或植物细胞中共表达第一核酸和第二核酸,从而产生多聚体蛋白
质。可通过将各自操作性地连接至表达增强子的第一核酸和第二核酸的表达水平与相同的第一和第二核酸的表达水平进行比较来确定表达的提高,该相同的第一核酸和第二核酸的每个不与表达增强子操作性地连接,或者例如当与现有技术表达增强子cpmv 160(seq id no:16)操作性地连接。或者,该方法可以包括提供植物、植物的一部分或植物细胞,其包含与编码第一蛋白质组分的核苷酸序列操作性地连接的包含如本文所述的表达增强子的第一核酸,和包含与编码第二蛋白质组分的核苷酸序列操作性地连接的包含如本文所述的表达增强子的第二核酸,并共表达第一核酸和第二核酸序列以产生多聚体蛋白质。
[0147]
此外,本发明提供了包含多聚体蛋白质的植物物质、植物提取物或蛋白质提取物,或者该多聚体蛋白质可以被纯化或部分纯化。
[0148]
如本文所述,提供了核酸构建体,其包含与编码目的蛋白质的目的核苷酸序列操作性地连接的表达增强子序列。还提供了植物表达系统和载体,其包含构建体或一种或多种包含本文所述增强子序列的核酸。还提供了一种植物表达系统、载体、构建体或核酸,其包含与可操纵地连接至目的核苷酸序列的增强子序列操作性地结合的植物调控区,该目的核苷酸序列编码目的蛋白质。该增强子序列可以选自seq id no:1~15中的任一个,或表现出与seq id no:1至15中任一项所述的序列100%、99%、98%、97%、96%、95%或90%或它们之间的任何量的序列一致性的核苷酸序列,其中当与目的核酸操作性地连接时,与未操作性地连接表达增强子或例如与现有技术表达增强子cpmv 160(seq id no:16)操作性地连接的相同目的核酸表达水平相比,表达增强子导致目的核酸的表达或目的核酸的表达水平提高。
[0149]
可以使用本领域技术人员已知的方法修饰seq id no:1~15中任一项的增强子序列,包括缺失、插入和/或取代增强子序列的一个或多个核苷酸序列,以产生表达增强子,其导致相似或提高的增强子活性,或导致表达增强子的另一种有益特性。例如,有益特性可以包括改善的转录起始、改善的mrna稳定性、改善的mrna翻译或其组合。
[0150]
本发明的增强子序列可以用于在宿主生物例如植物中表达目的蛋白质。在这种情况下,目的蛋白质对于所述的宿主生物也可以是异源的,并使用本领域已知的转化技术引入植物细胞。生物体中的异源基因可以替代内源等效基因,即通常执行相同或相似功能的基因,或者插入的序列可以是内源基因或其他序列的补充。
[0151]
本发明还提供了一种表达盒,其包含串联连接的启动子或植物调节区,该启动子或植物调节区与本文所述的表达增强子序列操作性地连接,该表达增强子序列与目标核苷酸序列、3’utr序列和终止子融合序列。增强子序列可以限定为seq id no:1~15中的任何一个或表现出与seq id no:1~15中的任何一条序列100%、99%、98%、97%、96%、95%或90%或其间的任何数量的序列一致性的核苷酸序列。也可以使用本领域技术人员已知的技术修饰增强子序列,条件是增强子序列导致目的核酸的表达或提高目的核苷酸序列的表达水平,例如通过比较操作性地连接至表达增强子的核苷酸序列的表达水平与未可操作性连接至表达增强子或例如当操作性地与现有技术表达增强子cpmv 160(seq id no:16)相连接时的相同核苷酸序列的表达水平来确定。
[0152]
表1列出了本申请所述的序列。
[0153]
表1:核酸和氨基酸序列列表:
[0154]
[0155]
[0156][0157]
在以下实施例中将进一步说明本发明。
[0158]
实施例1:使用多核糖体/cage分析法选择植物5’utr序列
[0159]
使用标准的苯酚-氯仿方案从不同的胁迫下未渗透和渗透的生物质或细胞培养物中提取mrna,并通过蔗糖梯度通过标准离心分离处于低翻译和高翻译状态的mrna。使用标准的苯酚-氯仿提取方案提取每个非多态性和多态性部分的mrna。使用基因表达的cap分析(cage)方法,对每个多聚核糖体和非多聚核糖体中每个mrna的5’utr的起点进行测序。去除不需要的序列标签(核糖体rna、叶绿体rna和无盖(uncapped)标签)后,将已测序的标签与参考基因组数据库进行比较,例如拟南芥的tair(参见url:arabidopsis.org/)或本氏烟的基因组网络(请参阅url:solgenomics.net/)进行基因鉴定。分析并归一化每个给定基因的测序标签数量。通过将多聚核糖体部分中发现的标准化标签数除以每个给定基因的标签总数,建立多聚核糖体比率(pr比)来评估翻译状态。在浸润条件下具有高翻译状态的基因
mrna被用来鉴定潜在的5’utr候选基因。
[0160]
作为该分析的结果,鉴定出15个候选5’utr并进一步表征:
[0161]
1.nbmt78(seq id no:1):78bp 5’utr是位于niben101scf38767g00006.1基因座的基因的一部分,该基因编码金属硫蛋白质样蛋白质1。
[0162]
2.nbatl75(seq id no:2):75bp 5’utr是位于基因位点niben101scf08015g04003.1中的基因的一部分,该基因编码at4g36060样蛋白质(碱性螺旋-环-螺旋(bhlh)dna结合超家族蛋白质;tair:at3g19860.1)。
[0163]
3.nbdj46(seq id no:3):46bp的5’utr是位于基因niben101scf16258g02004.1中的基因的一部分,该基因编码防御素j1-2蛋白质。
[0164]
4.nbchp79(seq id no:4):79bp的5’utr是位于基因niben101scf02509g07005.1位点的基因的一部分,该基因编码保守的假设蛋白质(蓖麻,genbank,eef49157.1,68aa)蛋白质)功能未知。
[0165]
5.nben42(seq id no:5):42bp 5’utr是位于基因位点niben101scf06633g02009.1中的基因的一部分,该基因编码早期的调节蛋白质样蛋白质2。在拟南芥中(at3g20570.1),该蛋白质可具有电子载体活性和铜离子结合膜蛋白质。
[0166]
6.athsp69(seq id no:6):69bp 5’utr从编码线虫抗性蛋白质样hspro2的核苷酸序列(at2g40000.1_00069)获得,该蛋白质在植物防御病原体中响应氧化胁迫和水杨酸,起着基础抗性的正调控作用。
[0167]
7.atgrp62(seq id no:7):62bp的5’utr是从编码未知功能的富含甘氨酸的蛋白质的核苷酸序列(at5g61660.1_00062)获得的。
[0168]
8.atpk65(seq id no:8):65bp 5’utr从编码植物光系统i超复合物(psi)家族的叶绿体多遍膜蛋白质成员的核苷酸序列(at1g30380.1_00065)获得)。该蛋白质参与叶绿素结合和光合作用。
[0169]
9.atrp46(seq id no:9);46bp 5’utr从编码叶绿体atrp1,ppdk调节蛋白质rp1的核苷酸序列(at4g21210.1_00046)获得。
[0170]
10.nb30s72(seq id no:10):72bp 5’utr是位于niben101scf04081g02005.1基因座的基因的一部分,该基因编码30s核糖体蛋白质s19。位于叶绿体中的小s19蛋白质(92aa)与s13形成复合物,该复合物与16s核糖体rna牢固结合。
[0171]
11.nbgt61(seq id no:11):61bp的5’utr是位于基因位点niben101scf17164g00027.1基因座中的基因的一部分,该基因编码谷胱甘肽毒素(grx),grx是使用谷胱甘肽作为辅助因子的小氧化还原酶家族。
[0172]
12.nbpv55(seq id no:12):55bp 5’utr是位于基因座niben101scf03733g03018.1中的基因的一部分,该基因编码功能未知的光系统i反应中心亚基v叶绿体蛋白质。
[0173]
13.nbppi43(seq id no:13):143bp 5’utr是位于基因座niben101scf01847g03004.1中的基因的一部分,该基因编码肽基-脯氨酰基顺反异构酶a(ppi)。
[0174]
14.nbpm64(seq id no:14):64bp 5’utr是位于基因座niben101scf05678g02004.1中的基因的一部分,该基因编码蛋白质酶体成熟蛋白质同系
物。
[0175]
15.nbh2a86(seq id no:15):86bp 5’utr是位于基因座niben101scf00369g03018.1的基因的一部分,该基因编码组蛋白质2a蛋白质。
[0176]
如下制备包含上述鉴定的增强子的以下构建体:
[0177]2×
35s/nbmt78 5’utr/dasher/cpmv 3’utr/nos术语(构建体编号4467;seq id no:75)
[0178]
使用以下基于pcr的方法,将与nbmt78 5’utr融合的编码dasher荧光蛋白质(atum,目录号fpb-27-609)的序列克隆到2
×
35s启动子+cpmv 3’utr/nos表达系统中。在第一轮pcr中,使用dasher基因序列(seq id no:20;图16b)作为模板,使用引物nbmt78_dasher.c(seq id no:17)和if-dasher(27-609).r(seq id no:18)扩增包含dasher荧光蛋白质的片段。将第一轮扩增的pcr产物(表2中的f1)用作模板,使用if-nbmt78.c(seq id no:19)和if-dasher(27-609).r(seq id no:18)添加atmt78 5’utr序列作为引物。使用in-fusion克隆系统(clontech,mountain view,ca),将最终的pcr产物(表2中的f2)克隆到2
×
35s启动子+cpmv 3’utr/nos表达系统中。用aatii和stui限制酶消化1666号构建体(图6a),并将线性化的质粒用于融合装配反应。1666号构建体是一个受体质粒,旨在“融合”克隆2
×
35s启动子+cpmv 3’utr/nos基表达盒中的目标基因。它还整合了一个基因构建体,用于在苜蓿质体蓝素基因启动子和终止子下共表达沉默的tbsv p19抑制子。骨架是pcambia二元质粒,并且从t-dna左边界至右边界的序列如seq id no:22所示。所得的构建体编号为4467(seq id no:75;seq id no:图16e)。dasher荧光蛋白质的氨基酸序列示于seq id no:21。在图6b示出了构建体4467。
[0179]
表2给出了本文所述的所有构建体的引物、模板以及核酸和蛋白质序列。
[0180]
对于流感h3和ha b构建体,除了基于2
×
35s启动子+基于cpmv 3’utr/nos的表达试剂盒外,所用的克隆载体还整合了苜蓿质体蓝素启动子和终止子控制下的流感m2离子通道基因。用aatii和stui限制酶酶解质粒4160号(seq id no:76;图6c;17e),并用于融合反应。
[0181]
对于诺如病毒vp1构建体,使用的克隆载体除了基于2
×
35s启动子+基于cpmv 3’utr/nos的表达试剂盒外,还整合了来自自烟草rb7基因的nos终止子后面的基质附着区(mar)调控元件。用aatii和stui限制酶酶解质粒编号4170(seq id no:77;图6d;18d),并用于融合反应。
[0182]
表2:构建体制备所需的引物、模板和目标序列
[0183]
[0184]
[0185]
[0186][0187]
*soa:目标序列;引物1:primer 1(用于融合克隆);引物2:引物2(构建片段1以用引物3扩增goi);引物3:引物3(用于融合克隆)
[0188]
实施例2:方法
[0189]
根癌土壤杆菌转染
[0190]
使用d’aoust等,2008(plant biotech。j.6:930-40)描述的方法,通过电穿孔用不同的表达载体转染(转化)根癌土壤杆菌菌株agl1。将转染的土壤杆菌在添加10mm 2-(n-吗啉代)乙烷磺酸(mes)和50μg/ml卡那霉素ph 5.6的lb培养基中生长,使其od600在0.6至1.6之间,并以100μl等分试样冷冻。
[0191]
植物生物量、接种物和土壤浸润的制备
[0192]
在填充有商业泥炭藓基质的公寓中平面上种植本氏烟。使植物在16/8光周期和白天25℃日/夜晚20℃的温度条件下在温室中生长。播种后三周,挑选出单独的小植株,移植到花盆中,并在相同的环境条件下在温室中生长三周。
[0193]
用每种表达载体转染(转化)的农杆菌在添加10mm 2-(n-吗啉代)乙磺酸(mes)和50μg/ml卡那霉素ph 5.6的lb培养基中生长,直到它们达到0.6和1.6之间的od600。使用前将农杆菌悬浮液离心,然后重悬于渗透培养基(10mm mgcl2和10mm mes ph 5.6)中,并在4
℃下保存过夜。在渗透当天,将培养批次稀释至2.5个培养体积,并在使用前加热。将本氏烟草的整株植物倒置放在不透气的不锈钢罐中的细菌悬浮液中,真空度为20~40托,持续2分钟。将植物放回温室中温育6或9天,直到收获。
[0194]
收获叶和提取总蛋白质
[0195]
温育后,收获植物的地上部分,在-80℃下冷冻并压碎成碎片。通过在2倍体积的冷的50mm tris缓冲液ph 8.0+500mm nacl、0.4μg/ml的偏亚硫酸氢盐和1mm的苯基甲磺酰氟中均化(polytron)冷冻破碎的植物材料的每个样品来提取总可溶性蛋白质。均质化后,将浆液在4℃下以10,000g离心10分钟,并将这些澄清的粗提物(上清液)保留下来进行分析。
[0196]
使用牛血清白蛋白质作为参考标准,通过bradford测定法(加利福尼亚赫拉克勒斯,bio-rad)测定澄清的粗提物的总蛋白质含量。使用criterion
tm
tgx stain-free
tm
预制凝胶(加利福尼亚赫拉克勒斯,bio-rad laboratories)在还原条件下通过sds-page分离蛋白质。通过用考马斯亮蓝对凝胶染色使蛋白质可视化。或者可以使用gel doc
tm
ez成像系统(加利福尼亚hercules的bio-rad实验室)将蛋白质可视化,然后将其电转移到聚偏二氟乙烯(pvdf)膜(印第安纳州印第安纳波利斯,roche diagnostics corporation)上进行免疫检测。免疫印迹之前,将膜用在tris缓冲盐水(tbs-t)中用5%脱脂奶粉和0.1%tween-20在4℃下封闭16~18小时。
[0197]
通过直接荧光测定粗提取物中的dasher表达
[0198]
通过直接测量粗提取物中的荧光定量dasher表达。使用50mm tris+150mm nacl ph 7.4提取缓冲液通过机械提取法提取冷冻的生物质,并在10000g下于4℃离心10分钟以去除不溶性碎片。将澄清的粗提取物在pbs中稀释1/16、1/48和1/144,并使用fluoroskan(ascent)仪器使用485nm作为激发滤光片和518nm作为发射滤光片测量荧光。
[0199]
使用血凝试验(ha滴度)确定的ha表达
[0200]
血凝测定法基于nayak和reichl(2004,j.virol。methods 122:9-15)所述的方法。在含有100μl pbs的v型底96孔微量滴定板中对测试样品进行连续的双重稀释(100μl),每孔保留100μl稀释样品。将100微升的0.25%的火鸡红细胞悬液(纽约雪城,bio link inc.;对于所有b株,h1、h5和h7)或0.5%的豚鼠红细胞悬液(对于h3)添加到孔板,并在室温下孵育2小时。记录显示出完全血凝的最高稀释度的倒数为ha活性。
[0201]
凝胶密度法测定的利妥昔单抗表达
[0202]
为了进行利妥昔单抗表达分析,通过在150mm tris、具有150mm nacl的ph 7.4缓冲液中进行机械提取而从叶中产生粗蛋白质提取物(2g生物量/eu),并在非还原条件下在sds-page上对提取物进行电泳,用于凝胶内光密度测定法定量对应于抗体的完全组装的h2l2形式的条带。在bio-rad的无污凝胶中进行蛋白质电泳,并使用gel doc xr+系统(包括用于图像分析和凝胶内定量的image lab软件)进行凝胶成像系统。
[0203]
vlp形成/碘克沙醇梯度的分析
[0204]
通过在具有2倍体积的提取缓冲液(100mm磷酸盐缓冲液ph 7.2+150mm nacl)的混合器中进行机械提取,从冷冻的生物质中提取蛋白质。将浆液通过大孔尼龙过滤器过滤以除去大的碎屑,并在4℃下以5000g离心5分钟。收集上清液,并在5000g下再次离心30分钟(4℃)以除去其他碎屑。然后将上清液加载在不连续的碘克沙醇密度梯度上。如下进行分析密度梯度离心:38ml试管,制备在乙酸盐缓冲液中含有不连续的碘克沙醇密度梯度(1ml浓度
为45%,2ml浓度为35%,2ml浓度为33%,2ml浓度为31%,2ml浓度为29%以及5ml的25%的碘克沙醇),并用25ml含有病毒样颗粒的提取物覆盖。将梯度以175000g离心4小时(4℃)。离心后,从底部到顶部收集1ml馏分,并通过sds-page结合蛋白质染色或蛋白质印迹分析馏分。
[0205]
实施例3:在植物中生产蛋白质
[0206]
如实施例2中所述,本氏烟草的叶子真空浸润根癌农杆菌,该根癌农杆菌包含编码目的蛋白质的表达载体,该表达载体操作性地连接至限定的表达增强子,使得目的蛋白质表达,并检查了叶子用于生产目的蛋白质。渗透后(dpi)9天后,从叶片匀浆中制备总粗蛋白质提取物,并如上所述测定血凝素滴度。
[0207]
参考图2,观察到与编码dasher的核酸序列可操作连接的每个表达增强子nbmt78(seq id no:1)、nbatl75(seq id no:2)、nbdj46(seq id no:3)、nbchp79(seq id no:4)、nben42(seq id no:5)、athsp69(seq id no:6)、atgrp62(seq id no:7)、atpk65(seq id no:8)、atrp46(seq id no:9)、nb30s72(seq id no:10)、nbgt61(seq id no:11)、nbpv55(seq id no:12)、nbppi43(seq id no:13)、nbpm64(seq id no:14)和nbh2a86(seq id no:15)与现有技术表达增强子序列cmpv 160(wo2015/103704)或操作性地连接至编码相同目的蛋白质的相同核酸序列的现有技术的表达增强子序列atpk41(在diamos等人中称为atpsak 3
′
,frontiers in plant science。2016,卷7,1-15页),并表达在类似条件下表达的活性相比,导致蛋白质表达增加。
[0208]
如图3a所示,观察到与编码流感血凝素h1a/加利福尼亚/7/09(图3a)的核酸序列可操作连接的每个表达增强子nbmt78(seq id no:1)、nbatl75(seq id no:2)、nbdj46(seq id no:3)、nbchp79(seq id no:4)、nben42(seq id no:5)、athsp69(seq id no:6)、atgrp62(seq id no:7)、atpk65(seq id no:8)、atrp46(seq id no:9)、nb30s72(seq id no:10)、nbgt61(seq id no:11)、nbpv55(seq id no:12)、nbppi43(seq id no:13)、nbpm64(seq id no:14)和nbh2a86(seq id no:15)与现有技术表达增强子序列cmpv 160(wo2015/103704)或操作性地连接至编码相同目的蛋白质的相同核酸序列的现有技术的表达增强子序列atpk41(在diamos等人中称为atpsak 3
′
,frontiers in plant science。2016,卷7,1-15页),并表达在类似条件下表达的活性相比,导致蛋白质表达相似或稍微增加。
[0209]
参考图3b,观测到与编码修饰的h1 michigan/45/15、修饰的h3香港/与4801/14和修饰的ha b/phuket bris/60/08或修饰的ha b/phuket/3073/13操作性地连接的每个表达增强子nbmt78(seq id no:1)、nbatl75(seq id no:2)、nbchp79(seq id no:4)、athsp69(seq id no:6)与操作性地连接到编码相同目的蛋白质的相同核酸序列的现有技术表达增强子序列cmpv 160(wo2015/103704),并在相似条件下表达相比,该蛋白质的表达相似或略有增加。
[0210]
这些结果证明本文所述的表达增强子序列可用于在植物、植物的一部分或植物细胞中表达与表达增强子可操作连接的目的蛋白质。
[0211]
实施例4:在植物中产生诺如病毒vp1蛋白质和的vlp
[0212]
如实施例2所述,用包含编码来自gii.4基因型的诺如病毒vp1的表达载体的根癌农杆菌真空浸润本氏烟的叶子,并检查其叶的vlp产生。渗透后(dpi)9天后,通过sds-page分离总粗蛋白质提取物,并用考马斯染色(vp1生产),或使用上述实施例2中所述的不连续
碘克沙醇密度梯度分离(vlp生产)。使用考马斯染色的sds-page检查密度梯度的馏分。诺如病毒vp1蛋白质出现在大约55~60kda的条带上。vp1蛋白质在部分密度梯度中的出现指示了在密度梯度离心过程中vlp平衡到的部分。还确定了密度梯度离心后从峰馏分获得的vlp产量。
[0213]
观察到与编码修饰的诺如病毒gii.4/sydney/2012 vp1的核酸序列可操作连接的每个表达增强子nbmt78(seq id no:1)、nbatl75(seq id no:2)、nbchp79(seq id no:4)和athsp69(seq id no:6)导致诺如病毒蛋白质表达。此外,使用上述表达增强子的诺如病毒gii.4vp1 vlp的产量与使用现有技术cpmv 160表达增强子(wo2015/103704)或现有技术表达增强剂nbpk74(称为nbpsak2 3’,diamos等人,frontiers in plant science.2016年,第7卷第1-15页)获得的产量相似。这些结果证明本文所述的表达增强子可用于产生病毒样颗粒(vlp)。
[0214]
实施例5:在植物中产生多聚体蛋白质
[0215]
本文所述的表达增强子也可以用于产生目的多聚体蛋白质,例如抗体。如实施例2所述,用根癌农杆菌真空浸润本氏烟草的叶片,该根癌农杆菌包含编码目的蛋白质的表达载体,该表达载体操作性地连接至限定的表达增强子,以允许目的蛋白质表达,并检查叶片中是否产生目的蛋白质。渗透(dpi)后9天后,如上所述,从叶匀浆中制备总粗蛋白质提取物,并通过sds-page分离,然后通过凝胶内密度法测定完整igg的表达水平。
[0216]
如图5所示,两种核酸的共表达,编码利妥昔单抗轻链(lc)的第一核酸操作性地连接至以下表达增强子的一种:nbmt78(seq id no:1)、nbatl75(seq id no:2)、nbchp79(seq id no:4)和athsp69(seq id no:6),并且编码利妥昔单抗重链(hc)的第二种核酸操作性地连接至以下表达增强子的一种:nbmt78(seq id no:1)、nbatl75(seq id no:2)、nbchp79(seq id no:4)和athsp69(seq id no:6),与共表达编码相同的hc和lc利妥昔单抗序列的第一核酸和第二核酸(其中第一核酸和第二核酸各自操作性地连接至现有技术表达增强剂cpmv 160)相比,,导致植物中多聚体蛋白质的产量相同或略有提高。
[0217]
这些结果证明,本文所述的表达增强子可用于产生多聚体蛋白质,例如抗体,并且与本文所述相同或不同的表达增强子可操作性地连接至用于编码多聚体蛋白质的成分的每种核酸序列。
[0218]
所有引文均通过引用并入本文。
[0219]
已经参照一个或多个实施例描述了本发明。然而,对于本领域技术人员将显而易见的是,在不脱离权利要求书所限定的本发明的范围的情况下,可以进行多种改变和修改。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1