一种可以提升Hi-C文库数据质量的小片段DNA文库构建方法与流程
本发明涉及基因测序技术领域,具体为一种可以提升hi-c文库数据质量的小片段dna文库构建方法。
背景技术:
高通量测序技术又称为下一代测序技术、以能一次并行对几十万到几百万条dna分子进行序列测定和读长较短等为标志,第二代高通量illumina测序平台具有测序通量高、准确度高和成本低等优点,并广泛应用于多个领域。
染色体构象捕获(chromosomeconformationcapture,3c)技术是一种研究染色体和蛋白互作和染色体构象的技术,可以提供遥远的基因位点之间的关联性的详细信息,此关联性可以从甲醛固定的细胞核中捕获,并且可以从染色体的三维折叠方式被推断。近年来,在第二代测序技术的迅速发展下,由3c技术衍生出来的hi-c则是以整个细胞核为研究对象,研究整个基因组范围内基因位点之间的关联性。在hi-c技术中,以整个细胞系为研究对象,利用高通量测序技术,结合生物信息学方法,研究全基因组范围内整个染色质dna在空间位置上的关系;通过对染色质内全部dna相互作用模式进行捕获,获得高分辨率的染色质三维结构信息。将通过第二代测序得到的dna序列对映射到参考基因组后,如果一对序列对应于不同的n段酶切片段,那么就认为这两个片段之间有n次相互作用,从而能够构建一个全基因组中所有酶切片段之间接合频率的矩阵。利用这个频率矩阵,将基因组组装过程中形成的contig、scaffold进行染色体定位、方向没定位,延长拼接结果,辅助基因组组装,尤其对于获得群体困难无法构建遗传图谱的物种意义重大。
hi-c互作分析应用方向广泛但不局限于以下研究:(1)构建全基因组互作图谱,寻找线性距离远而空间邻近的调控元件,研究基因组空间结构(compartment、tad、loop结构)可揭示基因组空间结构调控基因表达的机制;(2)研究病理细胞或组织的基因组三维结构,与wgs、rna-seq、atac-seq、chip-seq等多组学联合分析,可深度解析疾病和癌症的发生机理;(3)比较细胞生长发育或分化阶段的染色质空间结构变化,可揭示环境变化或生长发育过程中基因组三维结构的适应性变化。
基于高通量进行染色体构象捕获的hi-c技术,是染色体相互作用研究领域的一个巨大的飞跃。但是距离研究普遍揭示生物学功能的目标还很遥远,hi-c交互数据包含相当高的随机噪声。同时,实验发现,现有hi-c高通量测序文库的构建也存在着信息丢失、捕获方法存在一定偏好性造成的获得的有效数据率不高的问题。这些问题其中一个重要的表现在danglingends率过高影响有效数据率,danglingends是指标记上生物素的末端未能正常连接形成嵌合片段而进入测序步骤的dna片段,danglingends的高低直接影响有效数据率的高低。
技术实现要素:
(一)解决的技术问题
针对现有技术的不足,本发明提供了一种可以提升hi-c文库数据质量的小片段dna文库构建方法,该方法包含生物素捕获步骤,可用于hi-c的小片段文库构建;同时该方法使用qiagen的回收柱纯化连接产物,能明显改善dna纯度,对杂质较多的材料明显可提升其建库成功率。
(二)技术方案
为实现以上目的,本发明通过以下技术方案予以实现:一种可以提升hi-c文库数据质量的小片段dna文库构建方法,具体包括以下步骤:
s1、首先使用dneasyblood&tissuekit回收hi-c连接产物细胞核或者对已有hi-c连接产物dna进行纯化;
s2、对回收片段进行片段化、末端修复与加a获得末端修复后dna;
s3、对所述末端修复后的dna进行index连接获得连接物料;
s4、再对所述连接物料进行纯化获得dna纯化物料;
s5、最后将dna纯化物料进行pcr扩增获得dna测序文库。
优选的,所述步骤s1中dneasyblood&tissuekit回收hi-c连接产物dna的操作为:
t1、取hi-c连接产物,按照dneasyblood&tissuekit操作说明加蛋白酶k进行解交联;
t2、解交联完成后,按照操作说明加入无水乙醇沉淀dna;
t3、按照操作说明将dna过柱并清洗,回收纯化好的连接产物dna。
优选的,所述步骤s2中片段化、末端修复与加a反应体系包括以下用量的各组分:dna26μl、nebnextultraiifsenzymemix2μl和nebnextultraiifsreactionbuffer7.0μl,且反应体系为37℃孵育10min,65℃灭活30min,4℃保温。
优选的,所述步骤s3中index连接反应体系包括以下用量的各组分:片段化、末端修复与加a后的dna35μl、nebnextultraiiligationmastermix30μl、nebnextligationenhancer1μl和nebnextadaptorforillumina2.5μl,且反应体系混匀,20℃孵育15min后,加入3μluser酶,37℃孵育15min。
优选的,所述步骤s5中pcr扩增体系包括以下用量的各组分:dna纯化物料20μl、nebnextultraiiq5mastermix25μl、indexprimer/i7primer2.5μl、universalpcrprimer/i5primer2.5μl,且pcr程序为:98℃,30s、98℃,10s、65℃,75s、6-12cycle、65℃,5min和降至4℃保存。
本发明还公开了一种小片段dna文库,该文库由上述任一项所述的方法构建。
(三)有益效果
本发明提供了一种可以提升hi-c文库数据质量的小片段dna文库构建方法。与现有技术相比具备以下有益效果:
(1)、该可以提升hi-c文库数据质量的小片段dna文库构建方法,对现有dna小片段文库构建实验技术进行了多项优化,使得文库构建成功率大大提升,成本显著降低,本发明的技术适用于绝大数物种,该方法操作流程简单,可以复制到其他具备分子生物学基础的其它实验室。
(2)、该可以提升hi-c文库数据质量的小片段dna文库构建方法,通过在现有dna小片段文库构建的基础上,增加生物素捕获步骤,使该方法可用于hi-c小片段文库构建。
(3)、该可以提升hi-c文库数据质量的小片段dna文库构建方法,通过在建库前增加qiagen柱纯化步骤,纯化了dna,对杂质较多的材料可显著提升其建库存成功率,对于物种的适应性大大增加,利用
(4)、该可以提升hi-c文库数据质量的小片段dna文库构建方法,通过在pcr扩增文库前进行磁珠分选,缩小目标片段范围至300-500bp,可显著减少非特异性扩增,有效提高有效数据率。
附图说明
图1为本发明实施例1构建的小鼠胚胎干细胞hi-c的小片段dna文库的agilent2100大小检测图;
图2为本发明实施例2构建的斑马鱼肝脏细胞hi-c的小片段dna文库的agilent2100大小检测图;
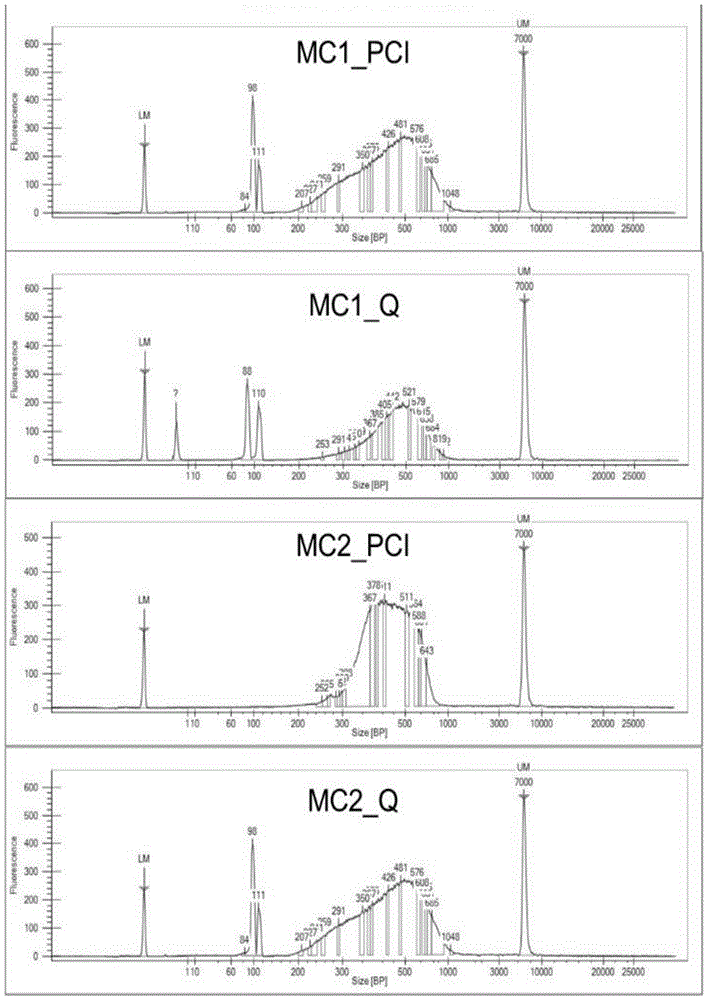
图3为本发明斑马鱼与小鼠样本dna小片段文库数据分析结果说明示意图;
图4为本发明hi-c建库过程个步骤质控琼脂糖凝胶电泳图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
请参阅图1-4,本发明实施例提供两种技术方案:一种可以提升hi-c文库数据质量的小片段dna文库构建方法,具体包括以下实施例:
实施例1
本实施例以hi-c连接产物为起始物料,需提供现有技术制备小鼠胚胎干细胞hi-c连接产物的方法。
本实施例提供小鼠胚胎干细胞hi-c的小片段dna文库构建方法,其方法具体包括以下步骤:
1.目的片段回收
1)参考dneasyblood&tissuekit操作说明修改了部分步骤进行;
2)hi-c连接产物离心弃上清加入180μlatl和20μlproteinasek至样品管中,56℃解交联2h,过程中颠倒离心管2-3次,混合样品;
3)加入200μl缓冲液al充分混匀,56℃孵育10min,过程中颠倒离心管2-3次,混合样品;
4)加入200μl96-100%乙醇,充分混匀;
5)移取650μl混合液至过滤柱dneasyminispincolumn中,置于一新的2ml离心收集管上;
6)6000g,离心1min,弃掉离心液体;
7)将过滤柱放置在一新的2ml离心收集管上,加入500μlaw1,6000g,离心1min,弃掉离心液体和收集管;
8)将过滤柱放置在一新的2ml离心收集管上,加入500μlaw2,20000g,离心3min,弃掉离心液体;
9)20000g离心1min,弃掉离心液体和收集管;
10)将过滤柱置于一新的1.5ml或2ml离心收集管上;
11)加入50μlbufferae洗脱dna,室温孵育1min,6000g,离心1min;
12)为增加dna回收量,再次加入50μlbufferae洗脱dna,室温孵育1min,6000g,离心1min;
13)qubti测定浓度。
2.末端去生物素
1)取1μg样品用于末端去生物素(若不足1μg则全部取用86.67μl),如表1所示;
表1去末端体系数据表
2)关闭热盖,12℃反应4h,2μl0.5medta终止反应;
3)提前半小时取出vahtsdnacleanbeads,平衡至室温;
4)将100μl去末端体系用1×beads回收dna;
5)吸取100μlvahtsdnacleanbeads(1×beads)至上述100μl产物中,涡旋振荡或使用移液器轻轻吹打10次充分混匀,旋转混匀仪上室温孵育5min;
6)将离心管短暂离心并置于磁力架中分离磁珠和液体,待溶液澄清后(约3min),小心移除上清,保留磁珠;
7)保持1.5ml离心管始终置于磁力架中,加入200μl新鲜配制的80%乙醇漂洗磁珠,室温孵育30sec,小心移除上清;
8)重复上一步步骤,总计漂洗两次;
9)保持1.5ml离心管始终置于磁力架中,开盖空气干燥磁珠1min至无乙醇残留;
10)加入15μl水洗脱,充分混匀,旋转混匀仪上室温孵育5min,将1.5ml离心管短暂离心并置于磁力架中静置,待溶液澄清后(约3min),小心移取15μl上清至新1.5ml离心管中,切勿触碰磁珠;
11)使用qubit定量;
3.目的片段的片段化、末端修复与接头连接
1)dna片段化、末端修复与加a,参照如表2体系依次加入试剂,
表2试剂信息表
反应体系37℃孵育10min,65℃灭活30min,4℃保温;
2)接头连接,参照如表3体系依次加入试剂,
表3试剂信息表
混匀,20℃孵育15min后,加入3μluser酶,37℃孵育15min。
4.ampurexpbeads片段分选
1)加入28.5μl0.1×te补足体系至100μl;
2)加dna连接产物的0.25倍体积磁珠溶液(25μl)到上一步100μldna连接产物中,振荡数秒混匀,室温孵育5min;
3)瞬时离心,将离心管放在磁力架上静置2min,将上清转移至一新的1.5ml离心管中,丢弃磁珠;
4)加dna连接产物的0.1倍体积磁珠溶液(10μl)到上一步上清中,振荡数秒混匀,室温孵育5min;
5)瞬时离心,将离心管放在磁力架上静置2min,吸弃上清,保留磁珠;
6)离心管保持在磁力架上,加入1ml的75%乙醇清洗磁珠,弃乙醇,
7)重复上一步乙醇清洗磁珠步骤一次;
8)打开管盖,室温风干30s;加入52μl去离子水,振荡将磁珠重新混悬,室温孵育5min;
9)瞬时离心,将离心管放到磁力架上静置1min,吸取50μl上清转移至新离心管中,若感觉吸到磁珠,可再用磁力架吸附一次,保证磁珠完全去除,文库可进行下步操作或保存于-20℃冰箱。
5.目标片段富集
1)配置streptaridinbeads结合液及洗涤液,如表4所示;
表4结合液及洗涤液信息表
2)涡旋磁珠,取10μl加入1.5mllobind离心管中;使用100μl1×twb(tweenwashingbuffer)清洗,室温震荡3min;磁力架吸附磁珠,弃上清;
3)再次使用100μl1×twb清洗磁珠,室温震荡3min;磁力架吸附磁珠,弃上清;
4)50μl2×bb(bindingbuffer)和50μlhi-cdna重悬磁珠,室温震荡15min;磁力架吸附磁珠2-3min,弃上清;
5)使用100μl1×twb清洗磁珠并转移至一新lobind离心管中,磁力架吸附磁珠,弃上清;
6)重复2次1×twb清洗磁珠;
7)加入25μl水,70℃温浴5min洗脱dna,磁力架吸附,回收上清;
8)加入20μl水,70℃温浴5min洗脱dna,磁力架吸附,回收上清;
9)总体积45μl,4μl用于跑圈,20μl用于pcr扩增切胶,剩余2μl文库可于-20℃长期保存。
6.扩增嵌合片段
1)将pcr仪设置如表5参数,并预热pcr仪;
表5pcr仪设置数据表
2)参照如表6体系依次加入试剂;
表6体系信息表
3)将各个循环数分别取2.5μl电泳检测确定最佳循环数(推荐6,8,10,12个循环),使用最佳循环数重新pcr50μl体系;
4)回收产物使用agilent2100对文库大小分布进行检测,文库大小合适分布均匀,可以进行高通量测序,测序结果如图1所示,结果表明各个文库主峰都在500bp左右,是良好的文库大小分布峰图。
实施例2
本实施例以hi-c连接产物dna为起始物料,需提供现有技术制备斑马鱼肝脏细胞hi-c连接产物dna的方法。
本实施例以斑马鱼肝脏细胞hi-c连接产物dna为研究对象,对连接产物进行qiagen柱纯化,然后进行文库构建,构建文库的中间步骤增加一步生物素捕获步骤,即可获得含有生物素标记的片段,再进行文库的pcr扩增,即可获得可上机测序的文库,在上机测序前进行agilent2100对文库大小分布进行检测,文库大小合适分布均匀,可以进行高通量测序,测序结果如图2所示,结果表明各个文库主峰都在500bp左右,是良好的文库大小分布峰图。
测序完成后,对质控得到的cleandata,使用ice3软件对数据进行迭代比对,并进行噪音reads过滤,分析结果如图3所示,结果显示:相对于普通纯化方式纯化hi-c连接产物后构建的文库(zf_pci,mc1_pci,mc2_pci),hi-c连接产物经过qiagen柱纯化后构建的文库(zf_q,mc1_q,mc2_q),danglingends率可以降低至少7.97%-16.84%,有效数据率可以提升至少6.62%-18.15%,经过qiagen柱纯化后建库的文库可以有效提升文库数据质量。
数据分析验证内容:
如图4所示为qiagen柱纯化电泳胶图,结合凝胶电泳图谱和qubit定量结果(未列出),hi-c连接产物使用常规提取方法可以获得更多量的dna(zf_pci,mc1_pci,mc2_pci),qiagen柱回收的连接产物小片段更少(zf_q,mc1_q,mc2_q),对数据进行插入片段大小分析结果发现,danglingends片段会明显偏小,正常测序片段大小应该在300-500bp,而danglingends片段大小集中在200bp甚至更小。
综合电泳、文库数据分析结果和danglingends大小分布结果可以得出结论,qiagen柱纯化试剂盒可以提升hi-c文库数据质量的原因可能有几下几个方面:
1)qiagen柱纯化试剂盒在核酸提取纯化领域是金标准的存在,大多数样本使用qiagen柱纯化试剂盒都可以获得纯度最好的dna,包括hi-c连接产物;
2)qiagen柱纯化试剂盒纯化样本时会倾向于将小片段去除,由于danglingends都是偏小的片段,所以可以提升hi-c文库数据质量。
需要说明的是,在本文中,诸如第一和第二等之类的关系术语仅仅用来将一个实体或者操作与另一个实体或操作区分开来,而不一定要求或者暗示这些实体或操作之间存在任何这种实际的关系或者顺序。而且,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者设备所固有的要素。
尽管已经示出和描述了本发明的实施例,对于本领域的普通技术人员而言,可以理解在不脱离本发明的原理和精神的情况下可以对这些实施例进行多种变化、修改、替换和变型,本发明的范围由所附权利要求及其等同物限定。
- 还没有人留言评论。精彩留言会获得点赞!