酶酸α葡萄糖苷酶(GAA)的结合蛋白及其用途的制作方法
酶酸
α
葡萄糖苷酶(gaa)的结合蛋白及其用途
技术领域
1.本发明涉及蛋白质纯化领域,具体而言涉及特异性结合酸性α葡糖苷酶(gaa)的新型蛋白质。本发明还涉及包含特异性结合gaa的新蛋白质的融合蛋白。此外,本发明涉及包含本发明的gaa结合蛋白的亲和基质。本发明还涉及这些gaa结合蛋白或亲和基质用于亲和纯化gaa的用途以及使用本发明的gaa结合蛋白亲和纯化gaa的方法。进一步的用途涉及用于测定液体中gaa的分析方法。
背景技术:
2.溶酶体酶gaa(gaa)在糖原降解为葡萄糖的过程中是必不可少的。gaa缺陷会导致糖原在溶酶体中积累,并导致肌肉和神经细胞损伤,称为糖原贮积病ii(庞贝氏(pompe
′
s)病)。这种代谢疾病的治疗方法是更换gaa。因此,有必要的是提供酶纯化方法。本领域持续需要允许有效纯化gaa蛋白的先进工具。
3.本发明通过提供新的gaa结合多肽满足了这种需要。这些新gaa结合多肽作为gaa的亲和配体是特别有利的,因为它们允许在亲和色谱中精确捕获,从而为医疗用途提供高度纯化的gaa。
4.以上概述并不必然描述了本发明解决的所有问题。
技术实现要素:
5.本公开提供以下1-15条条目,但并非专门限于此:
6.1.包含一个或多个gaa结合结构域的酸性α葡糖苷酶(gaa)结合蛋白,其中至少一个结构域包含seq id no:1或seq id no:2或seq id no:16或seq id no:17或seq id no:18的氨基酸序列,或与其具有至少95%序列同一性的氨基酸序列。
7.2.根据第1条的所述gaa结合蛋白,其中该蛋白对gaa具有小于200nm的结合亲和力(正如本文所述通过表面等离子体共振测定)。
8.3.根据第1条的所述gaa结合蛋白,其中所述gaa结合蛋白包含2、3、4、5或6个相互连接的结构域。
9.4.根据第3条的所述gaa结合蛋白,其中所述gaa结合蛋白是同源多聚体。
10.5.根据第3条的所述gaa结合蛋白,其中所述gaa结合蛋白是异源多聚体。
11.6.根据第3条的所述gaa结合蛋白,其中一个或多个结构域彼此直接连接或与一个或多个肽连接子(linker,接头)连接。
12.7.一种包含根据第1-6条中任一条的所述蛋白的融合蛋白。
13.8.一种编码根据第1-6条中任一条的所述蛋白或根据第7条的所述融合蛋白的多核苷酸。
14.9.根据第1-6条中任一条的所述gaa结合蛋白,或根据第7条所述的所述融合蛋白,在gaa的亲和纯化中应用。
15.10.根据第1-6条中任一条的所述gaa结合蛋白,或根据第7条的所述融合蛋白,还
no:17或seq id no:18的多肽,或与seq id no:1或seq id no:2或seq id no:16或seq id no:17或seq id no:18具有至少95%同一性的氨基酸序列的多肽提供。
31.在下文更详细描述本发明之前,应该理解的是,本发明不限于本文所述的具体方法、方案和试剂,因为它们可以变化。还应该理解的是,本文使用的术语仅出于描述具体方面和实施方式的目的,而非旨在限制本发明的范围,本发明的范围由所附权利要求反映。除非另有定义,本文使用的所有技术和科学术语与本发明所属领域的普通技术人员通常理解的含义相同。这包括在蛋白质工程和纯化领域工作的技术人员,而且也包括开发新gaa特异性结合分子以用于诸如亲和色谱的技术应用以及治疗和诊断领域工作的技术人员.
32.优选本文使用的术语如“a multilingual glossary of biotechnological terms:(lupac recommendations)”,leuenberger,h.g.w,nagel,b.and kolbl,h.eds.(1995),helvetica chimica acta,ch-4010basel,switzerland)中所述进行定义。
33.在整个本说明书和随附的权利要求书中,除非上下文另有要求,否则词语“包括”以及诸如“包含”和“含有”的变体将被理解为暗示包括所陈述的整数或步骤或整数或步骤的组,但并不排除任何其他整数或步骤或整数或步骤的组。术语“包括”或“包含”要是出于任何原因和在任何程度上需要这种限制,则可以涵盖对“由
…
组成”或“由
…
构成”的限制。
34.在整个本说明书中可以引述若干文件(例如:专利、专利申请、科学出版物、制造商的说明书、指导说明书、genbank登录号序列提交等)。本文中的任何内容均不应该解释为承认本发明无权因在先发明而早于此类公开。本文引用的一些文件可以特征性描述为“通过引用引入”。在这种引入参考文献的定义或教导与本说明书中引用的定义或教导之间发生冲突的情况下,以本说明书的文本为准。
35.本文提及的所有序列均在所附序列表中公开,以其全部内容和公开内容构成本说明书公开内容的一部分。
36.应用中使用的重要术语的通用定义
37.术语“gaa结合蛋白”或“酸性α葡糖苷酶结合多肽”或“酸性α葡糖苷酶结合蛋白”或“gaa结合多肽”在本文中可以互换使用,而描述能够结合酸性α葡糖苷酶(gaa;uniprot标识符p10253)的蛋白质。如本文所述,“gaa结合蛋白”是指与gaa具有可检测相互作用的蛋白质,例如,通过spr分析或本领域技术人员已知的其他适当技术进行确定。
38.术语“结合亲和力”和“结合活性”在本文中可以互换使用,它们是指本发明的多肽与另一种蛋白质、肽或其片段或结构域结合的能力。结合亲和力通常由平衡解离常数(kd)测量并报告,该常数用于评价和排序(rank)双分子相互作用的强度。结合亲和力和解离常数能够定量测量。用于确定结合亲和力的方法对于本领域技术人员是熟知的,并且可以选自,例如,本领域中公认的以下方法:表面等离子体共振(spr)、酶联免疫吸附测定(elisa)、动力学排阻分析(kinexa分析)、生物层干涉法(bli)、流式细胞术、荧光光谱技术、等温滴定量热法(itc)、分析超速离心法、放射免疫测定法(ria或irma)和增强化学发光法(ecl)。通常而言,解离常数kd在20-30℃的温度范围内确定。如果没有专门地另外说明,本文所述的kd值是在25℃下通过spr法测定。最广泛使用的spr-基系统是由biacore ab生产的biacore。在本发明的各种实施方式中,对gaa的结合亲和力可以由biacore spr系统测定。在各个实施方式中,分析物的浓度为1μm。在各个其他实施方式中,分析物的浓度为10μm。在本发明的各个其他实施方式中,本发明的多肽具有对gaa的结合亲和力,这通过spr测定,其
中spr测定中的分析物浓度为10μm,优选其中结合亲和力在25℃下测定。
39.术语“融合蛋白”涉及包含在遗传上与至少第二蛋白结合的至少第一蛋白的蛋白质。融合蛋白是通过连接两个或更多个最初编码单独蛋白质的基因而产生。因此,融合蛋白可以包含表达为单个线性多肽的相同或不同蛋白的多聚体。
40.如本文所用,术语“连接子(linker,接头)”以其最广泛的含义是指共价连接至少两个其他分子的分子。
41.术语“氨基酸序列同一性”是指定量比较两种或更多种蛋白质的氨基酸序列的同一性(或差异)。相对于参考多肽序列的“百分比(%)氨基酸序列同一性”定义为在比对序列和如有必要,引入空位(gap)以实现最大百分比序列同一性后,序列中与参考多肽序列中的氨基酸残基相同的氨基酸残基的百分比。为了测定序列同一性,将查询蛋白的序列与参考蛋白或多肽的序列,例如,与seq id no:1的多肽进行比对。序列比对的方法在本领域中是众所周知的。例如,为了确定任意多肽相对于例如seq id no:1的氨基酸序列的氨基酸序列同一性程度,优选使用sim局部相似性程序(sim local similarity program)(xiaoquin huang and webb miller(1991),advances in applied mathematics,vol.12:337-357),这能够免费使用。对于多重比对分析,优选使用clustalw(thompson et al.(1994)ucleic acids res.,22(22):4673-4680)。
42.术语“蛋白质”和“多肽”是指通过肽键连接的两个或更多个氨基酸的任何链,而不是指产物的具体长度。因此,“肽”、“蛋白质”、“氨基酸链”或用于指代两个或更多个氨基酸的链的任何其他术语都包括于“多肽”的定义内,并且术语“多肽”可以代替任何这些术语使用或与这些术语互换使用。术语“多肽”也意指多肽翻译后修饰如,例如,本领域熟知的糖基化的产物。
43.术语“碱稳定的”或“碱稳定性”或“苛性稳定的”或“苛性稳定性”是指本发明的gaa结合蛋白耐受碱性条件而不显著丧失与gaa结合能力的能力。本领域技术人员可以通过将gaa结合蛋白与氢氧化钠溶液一起培养,例如,正如实施例中所述,随后通过本领域技术人员已知的常规实验测定对gaa的结合活性,例如,通过色谱法,就很容易测试碱稳定性。
44.术语“色谱法”是指使用流动相和固定相将样品中的一种分子(例如,gaa)与其他分子(例如,污染物)分离开的分离技术。液体流动相包含分子混合物,并将这些分子传输穿过或通过固定相(如固体基质)。由于流动相中的不同分子与固定相的相互作用不同,能够分离流动相中的分子。
45.术语“亲和色谱”是指一种具体的色谱模式,其中与固定相偶联的配体与流动相(样品)中的分子(即gaa)相互作用,即该配体对要纯化的分子具有特异性结合亲和力。正如在本发明的上下文中所理解的那样,亲和色谱法涉及将含有gaa的样品加入到包含色谱配体(例如本发明的gaa结合蛋白)的固定相中。
46.对于固定相,术语“固体载体”或“固体基质”可以互换使用。
47.正如本文可互换使用的术语“亲和基质”或“亲和纯化基质”或“亲和色谱基质”是指亲和配体,例如,本发明gaa结合蛋白,连接到其上的基质,例如,色谱基质。配体(例如,gaa结合蛋白)能够特异性结合到要从混合物中纯化或去除的目标分子(例如,含vh3的蛋白)。
48.正如本文所用,术语“亲和纯化”是指通过将gaa结合到固定于基质上的gaa结合蛋
白而从液体中纯化gaa的方法。因此,混合物中除了gaa之外的其他组分被去除。在进一步的步骤中,能够以纯化形式洗脱所结合的gaa。
49.本发明实施方式的详述
50.现在将进一步描述本发明。在以下段落中更详细地定义了本发明的不同方面。下文定义的每个方面除非明确相反指出,可以与任何其他方面或多个方面组合。具体而言,所指示为优选或有利的任何特征可以与指示为优选或有利的任何其他一个或多个特征组合。
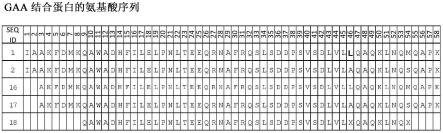
51.本发明的新多肽(包括seq id no:1、2、16、17、18、22、23)表现出对gaa的结合亲和力(本文中由spr测定)。酸性α葡糖苷酶的新结合蛋白包含与选自seq id no:1-9、14-20、22-23的组的任何一个具有至少95%同一性的氨基酸序列。新gaa结合蛋白包含一个或多个gaa结合结构域,其中至少一个gaa结合结构域包含seq id no:1或seq id no:2或seq id no:16或seq id no:17或seq id no:18的氨基酸序列或与其具有至少95%序列同一性的氨基酸,基本上由其或由其构成。gaa结合蛋白seq id no:1和seq id no:2和seq id no:16和seq id no:17和seq id no:18的氨基酸序列如图1中和此处所示:
52.seq id no:1(192403)
[0053][0054]
seq id no:2(192402)
[0055][0056]
seq id no:16(192403del2n)
[0057][0058]
seq id no:17(192402del2n)
[0059][0060]
新gaa结合蛋白包含一个或多个gaa结合结构域,其中至少一个gaa结合结构域包含seq id no:18的氨基酸序列或与其具有至少95%序列同一性的氨基酸:
[0061][0062]
x1在一些实施方式中能够是选自丙氨酸(a)或亮氨酸(l)的任何氨基酸。x1对应于seq id no:1或seq id no:2中的第46位。
[0063]
x2在一些实施方式中能够是选自丝氨酸(s)或甲硫氨酸(m)的任何氨基酸。x2对应于seq id no:1或seq id no:2中的第54位。
[0064]
在一些实施方式中,gaa结合多肽与seq id no:1的氨基序列具有至少95%的序列同一性。在一些实施方式中,gaa结合多肽与seq id no:2的氨基序列具有至少95%的序列同一性。在一些实施方式中,gaa结合多肽与seq id no:16的氨基序列具有至少95%的序列同一性。在一些实施方式中,gaa结合多肽与seq id no:17或seq id no:18的氨基序列具有至少95%的序列同一性。在一些实施方式中,gaa结合多肽与seq id no:22或seq id no:23的氨基序列具有至少95%的序列同一性。在其他实施方式中,gaa结合多肽与seq id no:1或seq id no:2或seq id no:16或seq id no:17或seq id no:18或seq id no:22或seq id no:23的氨基酸序列具有至少95%、98%或100%的序列同一性。例如,“与seq id no:1的氨基酸至少95%同一性”是指与氨基酸seq id no:1相比有1或2个取代;而“与seq id no:1的氨基酸至少98%同一性”是指与氨基酸seq id no:1相比有1个取代。例如,seq id no:2和seq id no:1有两个氨基酸不同,即氨基酸46和氨基酸54是不同的,并且是96%同一的。例
如,seq id no:16和seq id no:1有两个氨基酸不同,即seq id no:16中缺失了氨基酸1和氨基酸2。例如,seq id no:17和seq id no:2有两个氨基酸不同,即在seq id no:17中缺失氨基酸1和氨基酸2。
[0065]
所公开的gaa结合结构域和包含所述结构域的蛋白质的一个优点是它们与gaa特异性结合的功能特性。这是在gaa纯化中用作亲和配体的特定优点。本发明的gaa结合蛋白在功能上具有的特征在于对gaa的结合亲和力小于200nm。正如实施例3中所示,本发明的gaa结合蛋白以低于200nm、优选低于100nm或更优选低于50nm的解离常数kd与gaa结合。
[0066]
多聚体。在本发明的一个实施方式中,该gaa结合蛋白包含1、2、3、4、5或6个彼此连接的gaa结合蛋白。在一些实施方式中,该gaa结合蛋白可以是,例如,单体、二聚体、三聚体、四聚体、五聚体或六聚体。优选的gaa结合蛋白是单体或二聚体。本发明蛋白的多聚体是通常通过技术人员熟知的重组dna技术而人工产生的融合蛋白。在一些实施方式中,该多聚体是同源多聚体(homo-multimer),例如,gaa结合蛋白的氨基酸序列是相同的,例如,正如seq id no:7(seq id no:1的二聚体)所示。在其他实施方式中,该多聚体是异源多聚体(hetero-multimer),例如,gaa结合蛋白的氨基酸序列是不同的。
[0067]
融合蛋白。根据一个实施方式,本文提供了一种融合蛋白,其包含一种或多种,例如,两种如本说明书通篇所公开的gaa结合多肽。更具体而言,该融合蛋白包含一种或多种如本文所公开的gaa结合多肽和不同于所公开的多肽的进一步的多肽。在各种实施方式中,不同于本文公开的gaa结合多肽的所述进一步的多肽可以是非ig结合蛋白,例如,但不限于,不与免疫球蛋白的fc部分结合的蛋白。在一些实施方式中,非ig结合蛋白与seq id no:10或seq id no:11或seq id no:21具有至少80%同一性。在一些实施方式中,非ig结合蛋白与seq id no:10或seq id no:11或seq id no:21具有至少89.5%同一性。示例性非ig结合蛋白如seq id no:10或seq id no:11或seq id no:21的氨基酸序列中所示。因此,一些实施方式涵盖了包含一种或两种如本文所公开的gaa结合多肽和一种或两种非ig结合多肽的融合蛋白。
[0068]
在一些实施方式中,该融合蛋白可以包含以下组合(从n端到c端):
[0069]
(a)gaa结合蛋白—非ig结合蛋白;
[0070]
(b)非ig结合蛋白
–
gaa结合蛋白;
[0071]
(c)非ig结合蛋白—gaa结合蛋白—非ig结合蛋白(例如,参见seq id no:9);
[0072]
(d)gaa结合蛋白—非ig结合蛋白—非ig结合蛋白(例如,参见seq id no:14,seq id no:19,seq id no:20)。
[0073]
(e)gaa结合蛋白—gaa结合蛋白—非ig结合蛋白—非ig结合蛋白(例如,参见seq id no:15);
[0074]
(f)非ig结合蛋白—非ig结合蛋白—gaa结合蛋白
[0075]
非ig结合蛋白和gaa结合蛋白结构域的其他组合对于本领域技术人员也是可行的。
[0076]
在一些实施方式中,该融合蛋白包含seq id no:1的gaa结合蛋白,或与其具有至少95%氨基酸同一性的gaa结合蛋白。在一些实施方式中,该融合蛋白包含seq id no:1的gaa结合蛋白,或与其具有至少95%氨基酸同一性的gaa结合蛋白。在一些实施方式中,该融合蛋白包含seq id no:2的gaa结合蛋白,或与其具有至少95%氨基酸同一性的gaa结合蛋
白。在一些实施方式中,该融合蛋白包含seq id no:16的gaa结合蛋白,或与其具有至少95%氨基酸同一性的gaa结合蛋白。在一些实施方式中,该融合蛋白包含seq id no:17的gaa结合蛋白,或与其具有至少95%氨基酸同一性的gaa结合蛋白。在一些实施方式中,该融合蛋白包含seq id no:18的gaa结合蛋白,或与其具有至少95%氨基酸同一性的gaa结合蛋白。在一些实施方式中,该融合蛋白包含seq id no:22或seq id no:23的gaa结合蛋白,或与其具有至少95%氨基酸同一性的gaa结合蛋白。在一些优选实施方式中,该融合蛋白包含seq id no:1的gaa结合蛋白。在其他优选实施方式中,该融合蛋白包含seq id no:2的gaa结合蛋白。在其他优选实施方式中,该融合蛋白包含包含seq id no:16的gaa结合蛋白。在其他优选实施方式中,该融合蛋白包含seq id no:17的gaa结合蛋白。在其他优选实施方式中,该融合蛋白包含seq id no:18的gaa结合蛋白。
[0077]
该融合蛋白的部分可以彼此直连接头对尾连接或可以通过连接子(linker,接头)连接,其中连接子优选是肽连接子。在各种实施方式中,该肽连接子可以被认为是在空间上分隔融合蛋白的两个部分的氨基酸序列。通常而言,这种连接子由1-10个氨基酸组成。该融合蛋白可以表征为通过遗传融合或组合编码本发明的gaa结合多肽的基因与编码不同于本文上述多肽的多肽的基因而形成的蛋白质。因此,该融合蛋白可以被认为是两个或更多个基因一起翻译的产物(之间没有终止密码子)。
[0078]
用于纯化或检测的分子。在一些实施方式中,gaa结合蛋白或包含gaa结合蛋白的融合蛋白还可以在n端和/或c端包含其他氨基酸残基,例如,n-端和/或c-端的其他序列。其他序列可以包括,例如,引入例如用于纯化或检测的序列。此类序列的典型实例包括,但不限于,strep-标签(参见,例如,seq id no:12)、寡组氨酸标签、谷胱甘肽s-转移酶、麦芽糖结合蛋白、内含肽、内含肽片段或蛋白g的白蛋白结合结构域等。在一个实施方式中,其他氨基酸序列包括一种或多种赋予某些色谱柱材料亲和性的肽序列。该gaa结合蛋白或包含gaa结合蛋白的融合蛋白可以包括用于连接至固体载体的特异性连接位点,优选在c-端,如半胱氨酸或赖氨酸。具有c-端半胱氨酸的gaa结合蛋白的实例如seq id no:3、4、5、6、8中所示。本发明具有n-端其他氨基酸的gaa结合蛋白的实例如seq id no:5和seq id no:6中所示。
[0079]
gaa结合蛋白的产生方法。本发明进一步提供了一种用于产生本文公开的对gaa具有结合亲和力的新的gaa结合多肽的方法,该方法包括以下步骤:(i)提供多肽群;(ii)将(i)的多肽群与gaa接触;(iii)识别出包含与gaa结合的gaa结合多肽的复合物;和(iv)获得能够结合gaa的gaa结合多肽。
[0080]
产生对gaa具有结合亲和力的新gaa结合多肽的方法可以包括测定该多肽对gaa的结合亲和力的进一步的步骤。该结合亲和力可以如本文别处所述进行测定。
[0081]
新gaa结合多肽在技术应用中的用途。本文还提供了本发明的任何新gaa结合多肽,包括融合蛋白,在技术应用中,优选用作亲和色谱法中的亲和配体的用途。
[0082]
如本文所述,亲和色谱(也称为亲和纯化)利用了分子之间的特异性结合相互作用。用于固定蛋白的方法和用于亲和色谱的方法在蛋白质纯化领域是众所周知的,并且可以由本领域技术人员使用标准技术和设备很容易进行。
[0083]
在各种实施方式中,亲和纯化方法可以还包括在足以从亲和纯化基质中除去与其非特异性结合的一些或所有分子的条件下进行的一个或多个洗涤步骤。适用于所公开用途
和方法的亲和纯化基质对于本领域技术人员是已知的。
[0084]
与固体载体结合。在本发明的各个方面和/或实施方式中,包括通过上述任何方法产生或获得的新多肽的本文公开的新多肽与固体载体结合。在本发明的一些实施方式中,该多肽包含用于将多肽与固体载体进行位点特异性共价偶联的附连位点。特异性附连位点包括,但不限于,天然氨基酸,如半胱氨酸或赖氨酸,其能够与固相的反应性基团或固相与蛋白质之间的连接子发生特异性化学反应。
[0085]
亲和纯化基质。在另一个实施方式中,提供了一种包含gaa结合多肽的亲和纯化基质,包括通过上述任何方法确定出的多肽。
[0086]
在优选的实施方式中,亲和纯化基质是固体载体。亲和纯化基质包含至少一种本发明提供的gaa结合多肽。因此,本文公开的新gaa结合蛋白涵盖通过亲和基质进行gaa纯化的用途。
[0087]
用于亲和色谱的固体支持基质在本领域中是已知的,并且包括,例如,但不限于,琼脂糖和琼脂糖的稳定衍生物、纤维素或纤维素衍生物、可控孔径玻璃、整料(monolith)、氧化硅、氧化锆、氧化钛或合成聚合物以及各种组合物的水凝胶及前述的组合。
[0088]
固体载体基质的形式能够是任何合适的众所周知的类型。用于偶联本发明的新蛋白质或多肽的此类固体载体基质可以包括,例如,以下之一,但不限于:柱子、毛细管、颗粒、膜、过滤器、整料、纤维、垫、凝胶、载玻片、板、盒或色谱中常用且本领域技术人员已知的任何其他形式。
[0089]
在一个实施方式中,该基质由基本上球形颗粒,也称为珠,例如琼脂糖(sepharose)或琼脂糖(agarose)珠构成。该颗粒形式的基质能够用作填充床或悬浮形式,包括膨胀床。在本发明的其他实施方式中,固体载体基质是膜,例如,水凝胶膜。在一些实施方式中,亲和纯化可以涉及作为基质的膜,本发明的gaa结合蛋白与其共价结合。固体载体也能够是卡座(cartridge)中的膜的形式。
[0090]
在一些实施方式中,该亲和纯化涉及含有固体载体基质的色谱柱,本发明的新蛋白与该基质共价结合。本发明的新蛋白质或多肽可以通过常规偶联技术连接到合适的固体载体基质上。蛋白质配体固定于固体载体上的方法在蛋白质工程和纯化领域是众所周知的,并且由本领域技术人员使用标准技术和设备可以很容易进行。
[0091]
gaa制备方法。进一步的实施方式涉及一种制备其gaa或包含gaa的蛋白质的方法,该方法包括至少一个使用具有特异性结合gaa蛋白的亲和性的亲和色谱基质的色谱步骤,其中如上所述的gaa亲和配体(结合蛋白)偶联至所述亲和色谱基质。
[0092]
确定存在gaa的方法。此外,在一些实施方式中,本文所述的gaa结合蛋白或本文所述的融合蛋白用于确定存在gaa的方法。一些实施方式涉及分析液体样品中存在gaa的方法,该方法包括以下步骤:(a)提供含有gaa的液体,(b)提供gaa结合蛋白(或融合蛋白),(c)在允许gaa与至少一种gaa结合蛋白(或融合蛋白)结合的条件下使含有gaa的液体与本文所述的gaa结合蛋白(或融合蛋白)接触,(d)分离出gaa和gaa结合蛋白(或融合蛋白)的复合物,和(e)测定gaa结合蛋白(或融合蛋白)的量,其指示(a)的液体中gaa的量。
[0093]
gaa的定量方法。进一步的实施方式涉及gaa的定量方法,该方法包括:(a)提供含有gaa的液体;(b)提供一种如本文所述的gaa结合蛋白(或融合蛋白)已与之共价偶联的基质;(c)在允许gaa与至少一种gaa结合蛋白(或融合蛋白)结合的条件下使所述亲和纯化基
质与所述液体接触;(d)洗脱所述gaa;和可选地,(e)定量所洗脱的gaa的量。确定液体样品中存在gaa的方法可能是定量的或定性的。此类方法对于本领域技术人员而言是熟知的,并且可以选自,例如,但不限于,以下本领域公认的方法:酶联免疫吸附测定法(elisa)、酶促反应、表面等离子体共振(spr)或色谱法。
[0094]
多核苷酸、载体、宿主细胞。一个实施方式涵盖编码如本文公开的gaa结合多肽的(分离的)多核苷酸或核酸分子。另一个实施方式还涵盖由本文公开的多核苷酸编码的多肽。进一步提供了一种载体,具体而言是表达载体,其包含本发明的分离的多核苷酸或核酸分子,以及包含所述分离的多核苷酸或表达载体的宿主细胞。例如,编码本文公开的多肽的一种或多种多核苷酸可以表达于合适的宿主中,并且所产生的蛋白质能够被分离出来。载体是指能够用于将蛋白质编码信息转移到宿主细胞中的任何分子或实体(例如,核酸、质粒、噬菌体或病毒)。可以用于本发明的合适载体在本领域内是已知的。
[0095]
此外,提供了包含本文公开的多核苷酸或核酸或载体的分离细胞。合适的宿主细胞包括原核生物或真核生物,例如,细菌宿主细胞、酵母宿主细胞或携带载体的非人类宿主细胞。合适的细菌表达宿主细胞或体系在本领域内是已知的。本领域已知的各种哺乳动物或昆虫细胞培养系统也能够用于表达重组蛋白。
[0096]
本发明蛋白质的生产方法。在一个进一步的实施方式中,提供了生产如所述的gaa结合多肽的方法,该方法包括以下步骤:(a)在适合表达gaa结合多肽的条件下培养(合适的)宿主细胞,以获得所述gaa结合多肽;和(b)可选地分离所述gaa结合多肽。培养原核或真核宿主的合适条件对于本领域技术人员而言是熟知的。
[0097]
gaa结合多肽可以通过任何常规和众所周知的技术,如普通有机合成策略、固相辅助合成技术,或通过商业上可获得的自动合成仪进行制备。它们也可以通过常规重组技术单独或与常规合成技术组合而制备。
[0098]
在一个实施方式中,提供了一种制备gaa结合蛋白的方法,如上所述,所述方法包括以下步骤:(a)提供编码gaa结合多肽的核酸分子;(b)将所述核酸分子引入表达载体;(c)将所述表达载体引入宿主细胞中;(d)在培养基中培养所述宿主细胞;(e)使所述宿主细胞经受适合表达gaa结合多肽的培养条件,从而产生gaa结合多肽;可选地(f)分离出步骤(e)中产生的蛋白质或多肽;(g)可选地将所述蛋白质或多肽缀合于如上所述的固体基质上。在本发明的各种实施方式中,gaa结合多肽的生产通过无细胞体外转录和翻译而完成。
[0099]
提供以下实施例用于进一步举例说明本发明。然而,本发明并不限于此,以下实施例仅基于以上描述而显示本发明的实用性。
[0100]
实施例
[0101]
提供以下实施例用于进一步举例说明本发明。然而,本发明并不限于此,以下实施例仅基于上述描述而显示本发明的实用性。对于本发明的完整公开,还要参考本技术中引用的文献,该文献通过引用完整结合于本技术中。
[0102]
实施例1.本发明的gaa结合蛋白的选择
[0103]
库构建和库克隆
[0104]
基于具有如seq id no:10所示的包含随机氨基酸位置的蛋白a样结构的稳定非免疫球蛋白结合蛋白的库,通过由合成的三核苷酸亚磷酰胺(trinucleotide phosphoramidite)产生的随机寡核苷酸(ella biotech)进行内部合成,以实现充分均衡的
氨基酸分布,而同时排除随机位置的半胱氨酸和其他氨基酸残基。seq id no:10至少在氨基酸位置7、8、10、11、14、15、18、20、42、43、46、47、49、50、53和54上进行随机化。
[0105]
通过pcr扩增相应的cdna库并与pcd33-ompa噬菌粒连接。连接混合物的等分试样用于对大肠杆菌er2738(lucigen)进行电穿孔。除非另有说明,否则都使用已建立的重组遗传方法。
[0106]
通过tat噬菌体展示的初步选择。使用噬菌体展示作为选择系统,针对生物素化的gaa(也称为美而赞(myozyme)或阿糖苷酶α;)富集了天然库。在用携带库的噬菌粒pcd33-ompa转化感受态细菌er2738细胞(lucigene)后,使用技术人员已知的标准方法进行噬菌体扩增和纯化。溶液内选择(sis)方法用于允许在溶液中生物素化gaa与噬菌体库之间的结合。gaa-噬菌体复合物被链霉亲和素/中性抗生物素磁珠捕获。噬菌体培养期间的gaa浓度从200nm(第一轮)降低到100nm(第二轮),降低到50nm(第三轮)和25nm(第四轮)。在每一轮中都进行了空磁珠预选。在每一轮选择之后,gaa结合噬菌体通过胰蛋白酶进行洗脱。为了识别出靶特异性噬菌体池,通过噬菌体池elisa分析每轮选择的洗脱和再扩增的噬菌体。培养基结合微量滴定板(greiner bio-one)的孔用链霉亲和素(10μg/ml)预涂覆,然后用生物素化gaa(2.5μg/ml)涂覆。使用α-m13 hrp缀合抗体(ge healthcare)检测所结合的噬菌体。
[0107]
靶结合噬菌体池克隆到表达载体中。显示噬菌体池elisa中特异性结合至gaa的选择库根据本领域已知的方法通过pcr进行扩增,用适当的限制性核酸酶切割并连接到包含由脯氨酸、丝氨酸和丙氨酸组成的10个氨基酸连接子(linker,接头)和sfgfp的表达载体pet-28a的衍生物(merck,德国)中。
[0108]
实施例2.gaa结合蛋白的表达和纯化
[0109]
通过如实施例1中所述的选择而识别出的命中结果(hit)在筛选后进行鉴定,并且蛋白质以μ-规模(phynexus)生产。
[0110]
在t7启动子的调控下,使用低拷贝质粒系统在大肠杆菌bl21(de3)中表达构建体。在被包含于培养基(自诱导培养基)中的乳糖诱导后,蛋白质以可溶形式产生。bl21(de3)感受态细胞用表达质粒转化,铺展到选择性琼脂平板(卡那霉素)上并在37℃下培养过夜。将预培养物从单菌落接种于3ml 2
×
yt培养基中,该培养基中补充了50μg/ml卡那霉素,并在常规轨道摇床中于培养管内以200rpm在37℃下培养6小时。主要培养物在以1l erlenmeyer烧瓶内补充50μg/ml卡那霉素的300ml zym-5052(0.5%甘油、0.2%乳糖、0.05%葡萄糖、0.5%酵母提取物、1.0%酪蛋白氨基酸、25mm na2hpo4、25mm kh2po4、5mm na2so4、2mm mgso4和微量元素)内用3ml预培养物接种。将培养物转移到轨道振荡器(orbital shaker)中并在30℃和200rpm下进行培养。通过代谢葡萄糖并随后允许乳糖进入细胞而诱导重组蛋白表达。细胞过夜生长约17小时而达到约2-4的最终od600。在收获前,测量od600,将调整到0.6/od600的样品取出,造粒并在-20℃下冷冻。为了收集生物质,将细胞在22℃下以12000
×
g离心15分钟。对颗粒称重(湿重)。处理前将细胞储存于-20℃下。
[0111]
具有亲和标签的蛋白质通过亲和色谱和尺寸排阻进行纯化。亲和色谱纯化后,使用系统和superdex
tm 200 hiload 16/600柱(ge healthcare)进行尺寸排阻色谱(se hplc或sec)。sec柱的体积为120ml,并用2cv平衡。样品以1ml/min的流量施加。当信号强度达到10mau时开始收集级分。在sds-page分析之后,将阳性级分合并并测量其蛋白浓度。进
一步的分析包括sds-page、se-hplc和rp-hplc。使用摩尔吸收系数通过在280nm下吸光度测量而测定蛋白浓度。反相色谱(rp-hplc)使用dionex hplc系统和plrp-s(5μm,)色谱柱(agilent)进行。
[0112]
gaa结合蛋白和非ig结合蛋白的融合蛋白(seq id no:14、15、19、20)通过以下策略纯化:q-sepharose ff275 ml(ph 6)(缓冲液a:20mm bistris,1mm edta ph 6;缓冲液b:20mm bistris、1mm edta、1m nacl ph 6)、phenyl sepharose hp 236ml(缓冲液a:20mm bistris、1mm edta、1m(nh4)2so
4 ph 6;缓冲液b:20mm bistris,1mm edta,ph 6),脱盐560ml。例如,seq id no:14(cid204870)以1g蛋白质/升细胞培养体积的产量成功纯化。seq id no:19以10g蛋白质/升细胞培养体积的产量成功纯化。
[0113]
实施例3.通过表面等离子体共振(spr)的蛋白质分析
[0114]
500-1500 rugaa(on-ligand)固定于cm-5传感器芯片(ge healthcare)上;芯片用spr运行缓冲液平衡。用磺基-nhs-生物素标准试剂对gaa进行生物素化,并通过尺寸排阻色谱法(superdex 200)进行纯化。通过在链霉亲和素涂覆传感器芯片上注射生物素化靶标而固定靶标蛋白。一旦配体结合,蛋白分析物会聚集于表面上,从而提高折射率。实时测量折射率的这种变化,并将其绘制为响应或共振单位相对于时间的关系图。分析物按照30μl/min的流量以连续稀释的形式施加于芯片上。关联进行120秒,解离进行360秒。每次运行后,用30μl再生缓冲液(10mm甘氨酸)进行芯片表面再生,并用运行缓冲液平衡。使用biacore 3000(ge healthcare)进行结合研究;数据评价通过制造商提供的biaevaluation 3.0软件使用langmuir 1:1模型(ri=0)进行操作。评价的解离常数(kd)针对gaa标准化并指示。所显示的是实时测量的折射率变化并绘制为响应或共振单位[ru]相对于时间[sec]的关系图。结果:如本文公开的gaa结合蛋白显示出与固定化gaa的强特异性结合,亲和力小于100nm(见表1)。本发明的gaa结合蛋白不结合higg。seq id no:19的融合蛋白不结合higg;该亲和力对亲和力小于100nm的gaa具有特异性。
[0115]
表1.gaa亲和配体相对于gaa的特异性亲和性
[0116][0117]
实施例4.本发明的gaa结合蛋白作为用于纯化gaa的亲和配体
[0118]
偶联效率:根据制造商的说明书,每毫升praesto
tm epoxy 85固定20mg纯化的gaa结合蛋白(具有c端半胱氨酸)(偶联缓冲液:50mm na2hpo4、150mm nacl、5mm tcep、2.05m na2so4(或175mg na2so4/ml树脂),ph 9.5,偶联条件:35℃下3小时)。结果如表2所示。
[0119]
表2.gaa亲和配体的偶联效率
[0120]
gaa亲和配体偶联效率seq id no:117.0mg/ml树脂seq id no:1(n-端帽)17.4mg/ml树脂
seq id no:1(二聚体)19.0mg/ml树脂seq id no:217.4mg/ml树脂seq id no:2(n-端帽)16.5mg/ml树脂
[0121]
dbc10%:运行缓冲液:20mm柠檬酸盐、150mm nacl、1mm edta,ph 6,2。第一洗脱缓冲液:100mm柠檬酸盐缓冲液,20%(v/v)己二醇,ph 3.5;第二洗脱缓冲液:0.1m柠檬酸盐,ph 2.0(洗脱比率的确定)。动态结合容量(dbc)由在6分钟停留时间时在10%突破(breakthrough)下所注入gaa的质量确定。结果:偶联树脂对亲和配体(具有c-端cys)表现出良好的动态结合能力(dbc10%):
[0122]
·
seq id no:1,dbc10%至少为27mg/ml
[0123]
·
seq id no:1二聚体,dbc10%至少为24mg/ml
[0124]
·
seq id no:1融合蛋白(seq id no:19)至少22.7mg/ml
[0125]
·
seq id no:2,dbc 10%至少为16mg/ml。
[0126]
碱稳定性(循环研究)。与praesto
tm epoxy 85偶联的样品(偶联条件:20mg/ml,3小时,35℃,2.05m na2so
4 ph 8.5)在室温下用0.1m naoh处理至少10小时(610min)ph 3.5时的总洗脱率为100%。
[0127]
结果:亲和配体(通过与c-端cys偶联)在循环研究中表现出良好的碱稳定性:
[0128]
·
seq id no:1(n端延伸),具有95%剩余容量
[0129]
·
seq id no:1二聚体
[0130]
ο610分钟(约10小时)后具有94.4%剩余容量
[0131]
ο1515分钟(25小时)后具有84.4%剩余容量(等于101个循环)。
[0132]
图2显示了对praesto
tm epoxy 85树脂的循环研究。图2a显示了在praesto
tm epoxy 85上sed id no:1(具有n端延伸)在6分钟停留时间之时的dbc10%。该结合容量为19.5mg/ml。图2b显示了与praesto
tm epoxy 85树脂偶联并负载2mg/ml gaa的gaa结合蛋白(seq id no:1,具有n-端延伸)的dbc10%和碱稳定性。在50
×
上样、洗脱和0.1m naoh再生循环后的剩余容量至少为90%。
[0133]
表3显示了以填充柱形式在naoh中培养的固定亲和配体的结果。
[0134]
表3.碱稳定性
[0135]
[0136]
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1