抗TIGIT抗体的制作方法
抗tigit抗体
技术领域
1.本发明属于基因工程领域,具体涉及特异性结合tigit的抗体或抗原结合片段。
背景技术:
2.tigit(t cell immunoglobulin and itim domain),具有ig和itim结构域的t细胞免疫受体,也称为vsig9,vstm3或wucam,属于免疫球蛋白超家族成员,由免疫球蛋白可变区(igv)、跨膜区和免疫受体酪氨酸抑制基序(immuno receptor tyrosine-based inhibitor motif,itim)组成。tigit是表达于nk细胞和t细胞表面的共抑制信号分子,与t细胞、nk细胞及树突状细胞dc等的功能调节密切相关(stengel kf,et a1.(2012)procnatlacad sci usa.109)。有研究发现,tigit在肿瘤浸润性treg细胞上高度富集。肿瘤组织中的tigit+treg细胞表现出高度活性和抑制性的treg细胞表型。
3.tigit是一种共抑制性受体蛋白,tigit与共刺激受体cd226竞争性结合配体cd155(脊髓灰质炎病毒受体pvr)和cd122(脊髓灰质炎病毒受体2)从而介导免疫抑制作用。配体cd155和cd112存在于树突细胞和巨噬细胞上,并且在一些癌细胞中高度表达,例如在黑色素瘤等其他肿瘤细胞上(inozume et al.(2014)j.invest,dermato1.134:s121-abstract 693)过表达。尽管cd155可与共活化受体cd226相互作用增强t细胞活化,增强肿瘤杀伤,但在tigit存在的情况下,高亲和力tigit/cd155相互作用会抑制t细胞应答,抑制nk细胞毒性,刺激并增加其分泌il-10,降低il-12分泌水平,减弱抗肿瘤反应。另外,tigit表达与其他共抑制分子(包括pd-1)的表达高度相关。这些表明肿瘤细胞通过上调tigit途径以及其他抑制性检查点网络以促进免疫抑制机制,进而保护肿瘤细胞逃避免疫系统攻击。
4.已有研究表明,特异性结合人tigit的单克隆抗体,在动物模型中显示了显著的抗肿瘤效果(martinet and smyth 2015)。在wo2006/124667专利中已经证实阻断人tigit的抗体可用于治疗癌症。也有研究表明,tigit可增强tregs稳定性及其对产生γ-干扰素(ifn-γ)的t细胞增殖的抑制功能,选择性抑制辅助性t细胞1(th1)和辅助性t细胞17(th17)反应——这是驱动自身免疫组织炎症的主要反应。此外,通过抑制nk细胞的细胞溶解活性,tigit减少nk细胞细胞因子ifn-γ的产生,降低其细胞毒性。因此,阻断tigit信号转导具有增强自身免疫反应的作用。此外,在wo2009126688、wo2014089113、wo2015009856、wo2015143343、wo2015174439、wo2017053748、wo2017030823、wo2016106302、us20160176963、us20130251720等专利中也报道了tigit的抗体及相关应用。
5.多个研究表明,tigit与癌症、自身免疫、感染等多种疾病相关,tigit是极具潜力的多种疾病治疗的新靶点,开发专门针对tigit的拮抗抗体将阻断它对t细胞的抑制作用并增强抗击癌症的免疫力。然而,目前国内外还没有针对tigit的特异性抗体药物上市,因此亟须研发新型高效特异性tigit抗体,尤其是特异性靶向tigit的cd155/cd112阻断型抗体,这将给癌症或感染疾病患者提供更多的用药选择。
技术实现要素:
6.本发明的目的是提供一种分离的抗体,该抗体能够阻断tigit/cd155的结合,在人源化小鼠肿瘤模型中,本发明的抗体具有抑制肿瘤生长的作用,这表明本发明的抗体对肿瘤有积极的治疗作用。
7.本发明第一方面,提供了结合人/猴tigit的抗体或抗原结合片段,所述抗体或抗原结合片段包括重链可变区和轻链可变区,所述重链可变区包含重链互补决定区hcdr1、hcdr2和hcdr3,所述轻链可变区包含轻链互补决定区lcdr1、lcdr2和lcdr3,其中所述的hcdr1、hcdr2、hcdr3、lcdr1、lcdr2和lcdr3包含选自以下群组:
8.(1)如seq id no:1、4、7、15、19所示的hcdr1;
9.(2)如seq id no:2、5、8、10、11、12、14、16、17、20所示的hcdr2;
10.(3)如seq id no:3、6、9、13、18、21所示的hcdr3;
11.(4)如seq id no:22、25所示的lcdr1;
12.(5)如seq id no:23、26、31所示的lcdr2;以及
13.(6)如seq id no:24、27、28、29、30、32所示的lcdr3;或者与所述的hcdr1、hcdr2、hcdr3、lcdr1、lcdr2、lcdr3序列相比具有一个或几个氨基酸的保守取代(例如1个,2个或3个氨基酸的保守取代)的序列。
14.进一步地,所述的hcdr1、hcdr2、hcdr3、lcdr1、lcdr2和lcdr3包含选自以下群组:
15.(1)如seq id no:1或7所示的hcdr1;如seq id no:2、8、11、12或17所示的hcdr2;如seq id no:3、9、13、或18所示的hcdr3;如seq id no:22所示的lcdr1;如seq id no:23所示的lcdr2;以及如seq id no:24或28所示的lcdr3;或者与所述的hcdr1、hcdr2、hcdr3、lcdr1、lcdr2、lcdr3序列相比具有一个或几个氨基酸的保守取代(例如1个,2个或3个氨基酸的保守取代)的序列;
16.(2)如seq id no:4、15、或19所示的hcdr1;如seq id no:5、10、14、16或20所示的hcdr2;如seq id no:6或21所示的hcdr3;如seq id no:25所示的lcdr1;如seq id no:26所示的lcdr2;以及如seq id no:27、29、30或32所示的lcdr3;或者与所述的hcdr1、hcdr2、hcdr3、lcdr1、lcdr2、lcdr3序列相比具有一个或几个氨基酸的保守取代(例如1个,2个或3个氨基酸的保守取代)的序列;
17.(3)氨基酸序列如seq id no:7所示的hcdr1,如seq id no:11所示的hcdr2,如seq id no:9所示的hcdr3,如seq id no:22所示的lcdr1,如seq id no:31所示的lcdr2,和如seq id no:28所示的lcdr3;或者与所述的hcdr1、hcdr2、hcdr3、lcdr1、lcdr2、lcdr3序列相比具有一个或几个氨基酸的保守取代(例如1个,2个或3个氨基酸的保守取代)的序列。
18.进一步地,其中所述的hcdr1、hcdr2、hcdr3、lcdr1、lcdr2和lcdr3包含选自以下群组:
19.(1)氨基酸序列如seq id no:1所示的hcdr1,如seq id no:2所示的hcdr2,如seq id no:3所示的hcdr3,如seq id no:22所示的lcdr1,如seq id no:23所示的lcdr2,和如seq id no:24所示的lcdr3;或者与所述的hcdr1、hcdr2、hcdr3、lcdr1、lcdr2、lcdr3序列相比具有一个或几个氨基酸的保守取代(例如1个,2个或3个氨基酸的保守取代)的序列;
20.(2)氨基酸序列如seq id no:4所示的hcdr1,如seq id no:5所示的hcdr2,如seq id no:6所示的hcdr3,如seq id no:25所示的lcdr1,如seq id no:26所示的lcdr2,和如
seq id no:27所示的lcdr3;或者与所述的hcdr1、hcdr2、hcdr3、lcdr1、lcdr2、lcdr3序列相比具有一个或几个氨基酸的保守取代(例如1个,2个或3个氨基酸的保守取代)的序列;
21.(3)氨基酸序列如seq id no:7所示的hcdr1,如seq id no:8所示的hcdr2,如seq id no:9所示的hcdr3,如seq id no:22所示的lcdr1,如seq id no:23所示的lcdr2,和如seq id no:28所示的lcdr3;或者与所述的hcdr1、hcdr2、hcdr3、lcdr1、lcdr2、lcdr3序列相比具有一个或几个氨基酸的保守取代(例如1个,2个或3个氨基酸的保守取代)的序列;
22.(4)氨基酸序列如seq id no:4所示的hcdr1,如seq id no:10所示的hcdr2,如seq id no:6所示的hcdr3,如seq id no:25所示的lcdr1,如seq id no:26所示的lcdr2,和如seq id no:29所示的lcdr3;或者与所述的hcdr1、hcdr2、hcdr3、lcdr1、lcdr2、lcdr3序列相比具有一个或几个氨基酸的保守取代(例如1个,2个或3个氨基酸的保守取代)的序列;
23.(5)氨基酸序列如seq id no:7所示的hcdr1,如seq id no:11所示的hcdr2,如seq id no:9所示的hcdr3,如seq id no:22所示的lcdr1,如seq id no:23所示的lcdr2,和如seq id no:28所示的lcdr3;或者与所述的hcdr1、hcdr2、hcdr3、lcdr1、lcdr2、lcdr3序列相比具有一个或几个氨基酸的保守取代(例如1个,2个或3个氨基酸的保守取代)的序列;
24.(6)氨基酸序列如seq id no:7所示的hcdr1,如seq id no:12所示的hcdr2,如seq id no:13所示的hcdr3,如seq id no:22所示的lcdr1,如seq id no:23所示的lcdr2,和如seq id no:28所示的lcdr3;或者与所述的hcdr1、hcdr2、hcdr3、lcdr1、lcdr2、lcdr3序列相比具有一个或几个氨基酸的保守取代(例如1个,2个或3个氨基酸的保守取代)的序列;
25.(7)氨基酸序列如seq id no:15所示的hcdr1,如seq id no:16所示的hcdr2,如seq id no:6所示的hcdr3,如seq id no:25所示的lcdr1,如seq id no:26所示的lcdr2,和如seq id no:27所示的lcdr3;或者与所述的hcdr1、hcdr2、hcdr3、lcdr1、lcdr2、lcdr3序列相比具有一个或几个氨基酸的保守取代(例如1个,2个或3个氨基酸的保守取代)的序列;
26.(8)氨基酸序列如seq id no:7所示的hcdr1,如seq id no:11所示的hcdr2,如seq id no:9所示的hcdr3,如seq id no:22所示的lcdr1,如seq id no:31所示的lcdr2,和如seq id no:28所示的lcdr3;或者与所述的hcdr1、hcdr2、hcdr3、lcdr1、lcdr2、lcdr3序列相比具有一个或几个氨基酸的保守取代(例如1个,2个或3个氨基酸的保守取代)的序列;
27.(9)氨基酸序列如seq id no:19所示的hcdr1,如seq id no:20所示的hcdr2,如seq id no:21所示的hcdr3,如seq id no:25所示的lcdr1,如seq id no:26所示的lcdr2,和如seq id no:32所示的lcdr3;或者与所述的hcdr1、hcdr2、hcdr3、lcdr1、lcdr2、lcdr3序列相比具有一个或几个氨基酸的保守取代(例如1个,2个或3个氨基酸的保守取代)的序列;
28.(10)氨基酸序列如seq id no:7所示的hcdr1,如seq id no:17所示的hcdr2,如seq id no:18所示的hcdr3,如seq id no:22所示的lcdr1,如seq id no:23所示的lcdr2,和如seq id no:28所示的lcdr3;或者与所述的hcdr1、hcdr2、hcdr3、lcdr1、lcdr2、lcdr3序列相比具有一个或几个氨基酸的保守取代(例如1个,2个或3个氨基酸的保守取代)的序列;
29.(11)氨基酸序列如seq id no:4所示的hcdr1,如seq id no:14所示的hcdr2,如seq id no:6所示的hcdr3,如seq id no:25所示的lcdr1,如seq id no:26所示的lcdr2,和如seq id no:30所示的lcdr3;或者与所述的hcdr1、hcdr2、hcdr3、lcdr1、lcdr2、lcdr3序列相比具有一个或几个氨基酸的保守取代(例如1个,2个或3个氨基酸的保守取代)的序列。
30.更进一步地,其中所述的hcdr1、hcdr2、hcdr3、lcdr1、lcdr2和lcdr3包含选自以下
id no:18所示的hcdr3,如seq id no:82所示的lcdr1,如seq id no:83所示的lcdr2,和如seq id no:28所示的lcdr3;
45.(4)氨基酸序列如seq id no:7所示的hcdr1,如seq id no:81所示的hcdr2,如seq id no:18所示的hcdr3,如seq id no:82所示的lcdr1,如seq id no:83所示的lcdr2,和如seq id no:84所示的lcdr3;
46.(5)氨基酸序列如seq id no:7所示的hcdr1,如seq id no:81所示的hcdr2,如seq id no:18所示的hcdr3,如seq id no:82所示的lcdr1,如seq id no:83所示的lcdr2,和如seq id no:88所示的lcdr3;
47.(6)氨基酸序列如seq id no:7所示的hcdr1,如seq id no:81所示的hcdr2,如seq id no:18所示的hcdr3,如seq id no:89所示的lcdr1,如seq id no:83所示的lcdr2,和如seq id no:90所示的lcdr3;
48.(7)氨基酸序列如seq id no:7所示的hcdr1,如seq id no:81所示的hcdr2,如seq id no:18所示的hcdr3,如seq id no:82所示的lcdr1,如seq id no:83所示的lcdr2,和如seq id no:91所示的lcdr3;
49.(8)氨基酸序列如seq id no:4所示的hcdr1,如seq id no:14所示的hcdr2,如seq id no:6所示的hcdr3,如seq id no:85所示的lcdr1,如seq id no:26所示的lcdr2,和如seq id no:30所示的lcdr3;
50.(9)氨基酸序列如seq id no:4所示的hcdr1,如seq id no:14所示的hcdr2,如seq id no:6所示的hcdr3,如seq id no:85所示的lcdr1,如seq id no:86所示的lcdr2,和如seq id no:30所示的lcdr3;
51.(10)氨基酸序列如seq id no:4所示的hcdr1,如seq id no:14所示的hcdr2,如seq id no:6所示的hcdr3,如seq id no:85所示的lcdr1,如seq id no:86所示的lcdr2,和如seq id no:87所示的lcdr3;
52.(11)氨基酸序列如seq id no:4所示的hcdr1,如seq id no:14所示的hcdr2,如seq id no:6所示的hcdr3,如seq id no:85所示的lcdr1,如seq id no:86所示的lcdr2,和如seq id no:92所示的lcdr3;
53.(12)氨基酸序列如seq id no:4所示的hcdr1,如seq id no:14所示的hcdr2,如seq id no:6所示的hcdr3,如seq id no:85所示的lcdr1,如seq id no:86所示的lcdr2,和如seq id no:93所示的lcdr3;
54.更优选地,人源化改造或经亲和力成熟后的抗体或抗原结合片段选自如下所示的hcdr1、hcdr2、hcdr3、lcdr1、lcdr2、lcdr3群组:
55.(1)氨基酸序列如seq id no:7所示的hcdr1,如seq id no:81所示的hcdr2,如seq id no:18所示的hcdr3,如seq id no:82所示的lcdr1,如seq id no:83所示的lcdr2,和如seq id no:28所示的lcdr3;
56.(2)氨基酸序列如seq id no:7所示的hcdr1,如seq id no:81所示的hcdr2,如seq id no:18所示的hcdr3,如seq id no:82所示的lcdr1,如seq id no:83所示的lcdr2,和如seq id no:84所示的lcdr3;
57.(3)氨基酸序列如seq id no:4所示的hcdr1,如seq id no:14所示的hcdr2,如seq id no:6所示的hcdr3,如seq id no:85所示的lcdr1,如seq id no:86所示的lcdr2,和如
seq id no:30所示的lcdr3;
58.(4)氨基酸序列如seq id no:4所示的hcdr1,如seq id no:14所示的hcdr2,如seq id no:6所示的hcdr3,如seq id no:85所示的lcdr1,如seq id no:86所示的lcdr2,和如seq id no:87所示的lcdr3。
59.本发明第二个方面,提供了结合人/猴tigit的抗体或抗原结合片段,所述抗体或抗原结合片段包括重链可变区和轻链可变区:
60.(1)其中所述的重链可变区包含与选自由seq id no:33-43构成的群组中的氨基酸序列,或者与seq id no:33-43构成的群组中的氨基酸序列相比具有一个或几个氨基酸的置换、缺失、或添加(例如1个,2,3个,4个或5个氨基酸的置换、缺失或添加)的序列;或者与选自由seq id no:33-43构成的群组中的氨基酸序列具有至少90%、91%、92%、93%、94%、95%、96%、97%、98%、99%同一性的氨基酸序列;并且
61.(2)其中所述的轻链可变区包含与选自由seq id no:44-51构成的群组中的氨基酸序列,或者与seq id no:44-51构成的群组中的氨基酸序列相比具有一个或几个氨基酸的置换、缺失、或添加(例如1个,2,3个,4个或5个氨基酸的置换、缺失或添加)的序列;或者与选自由seq id no:44-51构成的群组中的氨基酸序列具有至少90%、91%、92%、93%、94%、95%、96%、97%、98%、99%同一性的氨基酸序列。
62.优选地,所述的置换为保守置换。
63.优选地,其中所述的重链可变区和轻链可变区包含:
64.(1)重链可变区,其包含选自下列的氨基酸序列:
65.(a)如seq id no:33所示氨基酸序列;
66.(b)与seq id no:33所示氨基酸序列相比具有一个或几个氨基酸的置换、缺失、或添加(例如1个,2,3个,4个或5个氨基酸的置换、缺失或添加)的序列;
67.(c)与seq id no:33所示的氨基酸序列具有至少90%、91%、92%、93%、94%、95%、96%、97%、98%、99%同一性的氨基酸序列;并且
68.(2)轻链可变区,其包含选自下列的氨基酸序列:
69.(a)如seq id no:44所示的氨基酸序列;
70.(b)与seq id no:44所示氨基酸序列相比具有一个或几个氨基酸的置换、缺失、或添加(例如1个,2,3个,4个或5个氨基酸的置换、缺失或添加)的序列;
71.(c)与seq id no:44所示的氨基酸序列具有至少90%、91%、92%、93%、94%、95%、96%、97%、98%、99%同一性的氨基酸序列;
72.其中(b)中所述置换为保守置换。
73.优选地,其中所述的重链可变区和轻链可变区包含:
74.(1)重链可变区,其包含选自下列的氨基酸序列:
75.(a)如seq id no:34所示氨基酸序列;
76.(b)与seq id no:34所示氨基酸序列相比具有一个或几个氨基酸的置换、缺失、或添加(例如1个,2,3个,4个或5个氨基酸的置换、缺失或添加)的序列;
77.(c)与seq id no:34所示的氨基酸序列具有至少90%、91%、92%、93%、94%、95%、96%、97%、98%、99%同一性的氨基酸序列;并且
78.(2)轻链可变区,其包含选自下列的氨基酸序列:
79.(a)如seq id no:45所示的氨基酸序列;
80.(b)与seq id no:45所示氨基酸序列相比具有一个或几个氨基酸的置换、缺失、或添加(例如1个,2,3个,4个或5个氨基酸的置换、缺失或添加)的序列;
81.(c)与seq id no:45所示的氨基酸序列具有至少90%、91%、92%、93%、94%、95%、96%、97%、98%、99%同一性的氨基酸序列;
82.其中(b)中所述置换为保守置换。
83.优选地,其中所述的重链可变区和轻链可变区包含:
84.(1)重链可变区,其包含选自下列的氨基酸序列:
85.(a)如seq id no:35所示氨基酸序列;
86.(b)与seq id no:35所示氨基酸序列相比具有一个或几个氨基酸的置换、缺失、或添加(例如1个,2,3个,4个或5个氨基酸的置换、缺失或添加)的序列;
87.(c)与seq id no:35所示的氨基酸序列具有至少90%、91%、92%、93%、94%、95%、96%、97%、98%、99%同一性的氨基酸序列;并且
88.(2)轻链可变区,其包含选自下列的氨基酸序列:
89.(a)如seq id no:46所示的氨基酸序列;
90.(b)与seq id no:46所示氨基酸序列相比具有一个或几个氨基酸的置换、缺失、或添加(例如1个,2,3个,4个或5个氨基酸的置换、缺失或添加)的序列;
91.(c)与seq id no:46所示的氨基酸序列具有至少90%、91%、92%、93%、94%、95%、96%、97%、98%、99%同一性的氨基酸序列;
92.其中(b)中所述置换为保守置换。
93.优选地,其中所述的重链可变区和轻链可变区包含:
94.(1)重链可变区,其包含选自下列的氨基酸序列:
95.(a)如seq id no:36所示氨基酸序列;
96.(b)与seq id no:36所示氨基酸序列相比具有一个或几个氨基酸的置换、缺失、或添加(例如1个,2,3个,4个或5个氨基酸的置换、缺失或添加)的序列;
97.(c)与seq id no:36所示的氨基酸序列具有至少90%、91%、92%、93%、94%、95%、96%、97%、98%、99%同一性的氨基酸序列;并且
98.(2)轻链可变区,其包含选自下列的氨基酸序列:
99.(a)如seq id no:47所示的氨基酸序列;
100.(b)与seq id no:47所示氨基酸序列相比具有一个或几个氨基酸的置换、缺失、或添加(例如1个,2,3个,4个或5个氨基酸的置换、缺失或添加)的序列;
101.(c)与seq id no:47所示的氨基酸序列具有至少90%、91%、92%、93%、94%、95%、96%、97%、98%、99%同一性的氨基酸序列;
102.其中(b)中所述置换为保守置换。
103.优选地,其中所述的重链可变区和轻链可变区包含:
104.(1)重链可变区,其包含选自下列的氨基酸序列
105.(a)如seq id no:37所示氨基酸序列;
106.(b)与seq id no:37所示氨基酸序列相比具有一个或几个氨基酸的置换、缺失、或添加(例如1个,2,3个,4个或5个氨基酸的置换、缺失或添加)的序列;
107.(c)与seq id no:37所示的氨基酸序列具有至少90%、91%、92%、93%、94%、95%、96%、97%、98%、99%同一性的氨基酸序列;并且
108.(2)轻链可变区,其包含选自下列的氨基酸序列:
109.(a)如seq id no:48所示的氨基酸序列;
110.(b)与seq id no:48所示氨基酸序列相比具有一个或几个氨基酸的置换、缺失、或添加(例如1个,2,3个,4个或5个氨基酸的置换、缺失或添加)的序列;
111.(c)与seq id no:48所示的氨基酸序列具有至少90%、91%、92%、93%、94%、95%、96%、97%、98%、99%同一性的氨基酸序列;
112.其中(b)中所述置换为保守置换。
113.优选地,其中所述的重链可变区和轻链可变区包含:
114.(1)重链可变区,其包含选自下列的氨基酸序列:
115.(a)如seq id no:38所示氨基酸序列;
116.(b)与seq id no:38所示氨基酸序列相比具有一个或几个氨基酸的置换、缺失、或添加(例如1个,2,3个,4个或5个氨基酸的置换、缺失或添加)的序列;
117.(c)与seq id no:38所示的氨基酸序列具有至少90%、91%、92%、93%、94%、95%、96%、97%、98%、99%同一性的氨基酸序列;并且
118.(2)轻链可变区,其包含选自下列的氨基酸序列:
119.(a)如seq id no:46所示的氨基酸序列;
120.(b)与seq id no:46所示氨基酸序列相比具有一个或几个氨基酸的置换、缺失、或添加(例如1个,2,3个,4个或5个氨基酸的置换、缺失或添加)的序列;
121.(c)与seq id no:46所示的氨基酸序列具有至少90%、91%、92%、93%、94%、95%、96%、97%、98%、99%同一性的氨基酸序列;
122.其中(b)中所述置换为保守置换。
123.优选地,其中所述的重链可变区和轻链可变区包含:
124.(1)重链可变区,其包含选自下列的氨基酸序列:
125.(a)如seq id no:40所示氨基酸序列;
126.(b)与seq id no:40所示氨基酸序列相比具有一个或几个氨基酸的置换、缺失、或添加(例如1个,2,3个,4个或5个氨基酸的置换、缺失或添加)的序列;
127.(c)与seq id no:40所示的氨基酸序列具有至少90%、91%、92%、93%、94%、95%、96%、97%、98%、99%同一性的氨基酸序列;并且
128.(2)轻链可变区,其包含选自下列的氨基酸序列:
129.(a)如seq id no:45所示的氨基酸序列;
130.(b)与seq id no:45所示氨基酸序列相比具有一个或几个氨基酸的置换、缺失、或添加(例如1个,2,3个,4个或5个氨基酸的置换、缺失或添加)的序列;
131.(c)与seq id no:45所示的氨基酸序列具有至少90%、91%、92%、93%、94%、95%、96%、97%、98%、99%同一性的氨基酸序列;
132.其中(b)中所述置换为保守置换。
133.优选地,其中所述的重链可变区和轻链可变区包含:
134.(1)重链可变区,其包含选自下列的氨基酸序列:
135.(a)如seq id no:42所示氨基酸序列;
136.(b)与seq id no:42所示氨基酸序列相比具有一个或几个氨基酸的置换、缺失、或添加(例如1个,2,3个,4个或5个氨基酸的置换、缺失或添加)的序列;
137.(c)与seq id no:42所示的氨基酸序列具有至少90%、91%、92%、93%、94%、95%、96%、97%、98%、99%同一性的氨基酸序列;并且
138.(2)轻链可变区,其包含选自下列的氨基酸序列:
139.(a)如seq id no:50所示的氨基酸序列;
140.(b)与seq id no:50所示氨基酸序列相比具有一个或几个氨基酸的置换、缺失、或添加(例如1个,2,3个,4个或5个氨基酸的置换、缺失或添加)的序列;
141.(c)与seq id no:50所示的氨基酸序列具有至少90%、91%、92%、93%、94%、95%、96%、97%、98%、99%同一性的氨基酸序列;
142.其中(b)中所述置换为保守置换。
143.优选地,其中所述的重链可变区和轻链可变区包含:
144.(1)重链可变区,其包含选自下列的氨基酸序列:
145.(a)如seq id no:43所示氨基酸序列;
146.(b)与seq id no:43所示氨基酸序列相比具有一个或几个氨基酸的置换、缺失、或添加(例如1个,2,3个,4个或5个氨基酸的置换、缺失或添加)的序列;
147.(c)与seq id no:43所示的氨基酸序列具有至少90%、91%、92%、93%、94%、95%、96%、97%、98%、99%同一性的氨基酸序列;并且
148.(2)轻链可变区,其包含选自下列的氨基酸序列:
149.(a)如seq id no:51所示的氨基酸序列;
150.(b)与seq id no:51所示氨基酸序列相比具有一个或几个氨基酸的置换、缺失、或添加(例如1个,2,3个,4个或5个氨基酸的置换、缺失或添加)的序列;
151.(c)与seq id no:51所示的氨基酸序列具有至少90%、91%、92%、93%、94%、95%、96%、97%、98%、99%同一性的氨基酸序列;
152.其中(b)中所述置换为保守置换。
153.优选地,其中所述的重链可变区和轻链可变区包含:
154.(1)重链可变区,其包含选自下列的氨基酸序列:
155.(a)如seq id no:41所示氨基酸序列;
156.(b)与seq id no:41所示氨基酸序列相比具有一个或几个氨基酸的置换、缺失、或添加(例如1个,2,3个,4个或5个氨基酸的置换、缺失或添加)的序列;
157.(c)与seq id no:41所示的氨基酸序列具有至少90%、91%、92%、93%、94%、95%、96%、97%、98%、99%同一性的氨基酸序列;并且
158.(2)轻链可变区,其包含选自下列的氨基酸序列:
159.(a)如seq id no:46所示的氨基酸序列;
160.(b)与seq id no:46所示氨基酸序列相比具有一个或几个氨基酸的置换、缺失、或添加(例如1个,2,3个,4个或5个氨基酸的置换、缺失或添加)的序列;
161.(c)与seq id no:46所示的氨基酸序列具有至少90%、91%、92%、93%、94%、95%、96%、97%、98%、99%同一性的氨基酸序列;
162.其中(b)中所述置换为保守置换。
163.优选地,其中所述的重链可变区和轻链可变区包含:
164.(1)重链可变区,其包含选自下列的氨基酸序列:
165.(a)如seq id no:39所示氨基酸序列;
166.(b)与seq id no:39所示氨基酸序列相比具有一个或几个氨基酸的置换、缺失、或添加(例如1个,2,3个,4个或5个氨基酸的置换、缺失或添加)的序列;
167.(c)与seq id no:39所示的氨基酸序列具有至少90%、91%、92%、93%、94%、95%、96%、97%、98%、99%同一性的氨基酸序列;并且
168.(2)轻链可变区,其包含选自下列的氨基酸序列:
169.(a)如seq id no:49所示的氨基酸序列;
170.(b)与seq id no:49所示氨基酸序列相比具有一个或几个氨基酸的置换、缺失、或添加(例如1个,2,3个,4个或5个氨基酸的置换、缺失或添加)的序列;
171.(c)与seq id no:49所示的氨基酸序列具有至少90%、91%、92%、93%、94%、95%、96%、97%、98%、99%同一性的氨基酸序列;
172.其中(b)中所述置换为保守置换。
173.更优选地,其中所述的重链可变区和轻链可变区选自以下群组:
174.(1)所述重链可变区具有如seq id no:34所示氨基酸序列,并且所述轻链可变区具有如seq id no:45所示的氨基酸序列;
175.(2)所述重链可变区具有如seq id no:37所示氨基酸序列,并且所述轻链可变区具有如seq id no:48所示的氨基酸序列;
176.(3)所述重链可变区具有如seq id no:38所示氨基酸序列,并且所述轻链可变区具有如seq id no:46所示的氨基酸序列;
177.(4)所述重链可变区具有如seq id no:42所示氨基酸序列,并且所述轻链可变区具有如seq id no:50所示的氨基酸序列;
178.(5)所述重链可变区具有如seq id no:43所示氨基酸序列,并且所述轻链可变区具有如seq id no:51所示的氨基酸序列;
179.(6)所述重链可变区具有如seq id no:41所示氨基酸序列,并且所述轻链可变区具有如seq id no:46所示的氨基酸序列;
180.(7)所述重链可变区具有如seq id no:39所示氨基酸序列,并且所述轻链可变区具有如seq id no:49所示的氨基酸序列。
181.在一些实施方案中,所述抗体或抗原结合片段经人源化改造或经亲和力成熟筛选,所述的抗体或抗原结合片段还包含如seq id no:54-59所示的重链可变区;或者与所示seq id no:54-59具有至少90%、91%、92%、93%、94%、95%、96%、97%、98%、99%同一性的氨基酸序列;并且所述的抗体或抗原结合片段还包含如seq id no:60-72所示的轻链可变区;或者与所示seq id no:60-72具有至少90%、91%、92%、93%、94%、95%、96%、97%、98%、99%同一性的氨基酸序列。
182.优选地,其中所述的重链可变区和轻链可变区可选自以下群组:
183.(1)所述重链可变区具有如seq id no:54所示氨基酸序列,并且所述轻链可变区具有如seq id no:60所示氨基酸序列,或者与所述轻重链可变区氨基酸序列具有至少
90%、91%、92%、93%、94%、95%、96%、97%、98%、99%同一性的氨基酸序列;
184.(2)所述重链可变区具有如seq id no:55所示氨基酸序列,并且所述轻链可变区具有如seq id no:61所示氨基酸序列,或者与所述轻重链可变区氨基酸序列具有至少90%、91%、92%、93%、94%、95%、96%、97%、98%、99%同一性的氨基酸序列;
185.(3)所述重链可变区具有如seq id no:56所示氨基酸序列,并且所述轻链可变区具有如seq id no:62所示氨基酸序列,或者与所述轻重链可变区氨基酸序列具有至少90%、91%、92%、93%、94%、95%、96%、97%、98%、99%同一性的氨基酸序列;
186.(4)所述重链可变区具有如seq id no:55所示氨基酸序列,并且所述轻链可变区具有如seq id no:62所示氨基酸序列,或者与所述轻重链可变区氨基酸序列具有至少90%、91%、92%、93%、94%、95%、96%、97%、98%、99%同一性的氨基酸序列;
187.(5)所述重链可变区具有如seq id no:56所示氨基酸序列,并且所述轻链可变区具有如seq id no:61所示氨基酸序列,或者与所述轻重链可变区氨基酸序列具有至少90%、91%、92%、93%、94%、95%、96%、97%、98%、99%同一性的氨基酸序列;
188.(6)所述重链可变区具有如seq id no:55所示氨基酸序列,并且所述轻链可变区具有如seq id no:66所示氨基酸序列,或者与所述轻重链可变区氨基酸序列具有至少90%、91%、92%、93%、94%、95%、96%、97%、98%、99%同一性的氨基酸序列;
189.(7)所述重链可变区具有如seq id no:55所示氨基酸序列,并且所述轻链可变区具有如seq id no:67所示氨基酸序列,或者与所述轻重链可变区氨基酸序列具有至少90%、91%、92%、93%、94%、95%、96%、97%、98%、99%同一性的氨基酸序列;
190.(8)所述重链可变区具有如seq id no:55所示氨基酸序列,并且所述轻链可变区具有如seq id no:68所示氨基酸序列,或者与所述轻重链可变区氨基酸序列具有至少90%、91%、92%、93%、94%、95%、96%、97%、98%、99%同一性的氨基酸序列;
191.(9)所述重链可变区具有如seq id no:57所示氨基酸序列,并且所述轻链可变区具有如seq id no:63所示氨基酸序列,或者与所述轻重链可变区氨基酸序列具有至少90%、91%、92%、93%、94%、95%、96%、97%、98%、99%同一性的氨基酸序列;
192.(10)所述重链可变区具有如seq id no:58所示氨基酸序列,并且所述轻链可变区具有如seq id no:64所示氨基酸序列,或者与所述轻重链可变区氨基酸序列具有至少90%、91%、92%、93%、94%、95%、96%、97%、98%、99%同一性的氨基酸序列;
193.(11)所述重链可变区具有如seq id no:59所示氨基酸序列,并且所述轻链可变区具有如seq id no:65所示氨基酸序列,或者与所述轻重链可变区氨基酸序列具有至少90%、91%、92%、93%、94%、95%、96%、97%、98%、99%同一性的氨基酸序列;
194.(12)所述重链可变区具有如seq id no:59所示氨基酸序列,并且所述轻链可变区具有如seq id no:69所示氨基酸序列,或者与所述轻重链可变区氨基酸序列具有至少90%、91%、92%、93%、94%、95%、96%、97%、98%、99%同一性的氨基酸序列;
195.(13)所述重链可变区具有如seq id no:59所示氨基酸序列,并且所述轻链可变区具有如seq id no:70所示氨基酸序列,或者与所述轻重链可变区氨基酸序列具有至少90%、91%、92%、93%、94%、95%、96%、97%、98%、99%同一性的氨基酸序列;
196.(14)所述重链可变区具有如seq id no:59所示氨基酸序列,并且所述轻链可变区具有如seq id no:71所示氨基酸序列,或者与所述轻重链可变区氨基酸序列具有至少
90%、91%、92%、93%、94%、95%、96%、97%、98%、99%同一性的氨基酸序列;
197.(15)所述重链可变区具有如seq id no:59所示氨基酸序列,并且所述轻链可变区具有如seq id no:72所示氨基酸序列,或者与所述轻重链可变区氨基酸序列具有至少90%、91%、92%、93%、94%、95%、96%、97%、98%、99%同一性的氨基酸序列;
198.更优选地,其中所述的重链可变区和轻链可变区选自以下群组:
199.(1)所述重链可变区具有如seq id no:55所示氨基酸序列,并且所述轻链可变区具有如seq id no:62所示的氨基酸序列;
200.(2)所述重链可变区具有如seq id no:55所示氨基酸序列,并且所述轻链可变区具有如seq id no:66所示的氨基酸序列;
201.(3)所述重链可变区具有如seq id no:59所示氨基酸序列,并且所述轻链可变区具有如seq id no:65所示的氨基酸序列;
202.(4)所述重链可变区具有如seq id no:59所示氨基酸序列,并且所述轻链可变区具有如seq id no:69所示的氨基酸序列。
203.本发明第三方面,提供了结合人/猴tigit的抗体或抗原结合片段,所述抗体或抗原结合片段是鼠源的、嵌合的、人源化的、亲和力成熟的;其中所述的人源化抗体轻链和重链可变区上的fr区序列分别来源于人种系轻链和重链或其突变序列;本发明抗体还包括重链恒定区和轻链恒定区。
204.优选地,所述抗体包含人igg1、igg2、igg3、igg4的重链恒定结构域和人κ或λ类型的轻链恒定结构域或其变体,其中所述变体包括一个或几个氨基酸的取代。
205.优选地,所述抗体包含人igg1恒定结构域或其变体,和κ恒定结构域或其变体,其中所述变体包括一个或几个氨基酸的取代。
206.更优选地,所述抗体包含如seq id no:52所示的重链恒定区和包含如seq id no:53所示的轻链恒定区。
207.更优选地,本发明抗体包含具有两条轻链和两条重链的完整结构,所述抗体选自以下群组:
208.(1)重链包含氨基酸序列如seq id no:34所示的重链可变区,氨基酸序列如seq id no:52所示的重链恒定区,并且轻链包含氨基酸序列如seq id no:45所示的轻链可变区,氨基酸序列如seq id no:53所示的轻链恒定区;
209.(2)重链包含氨基酸序列如seq id no:37所示的重链可变区,氨基酸序列如seq id no:52所示的重链恒定区,并且轻链包含氨基酸序列如seq id no:48所示的轻链可变区,氨基酸序列如seq id no:53所示的轻链恒定区;
210.(3)重链包含氨基酸序列如seq id no:38所示的重链可变区,氨基酸序列如seq id no:52所示的重链恒定区,并且轻链包含氨基酸序列如seq id no:46所示的轻链可变区,氨基酸序列如seq id no:53所示的轻链恒定区;
211.(4)重链包含氨基酸序列如seq id no:42所示的重链可变区,氨基酸序列如seq id no:52所示的重链恒定区,并且轻链包含氨基酸序列如seq id no:50所示的轻链可变区,氨基酸序列如seq id no:53所示的轻链恒定区;
212.(5)重链包含氨基酸序列如seq id no:43所示的重链可变区,氨基酸序列如seq id no:52所示的重链恒定区,并且轻链包含氨基酸序列如seq id no:51所示的轻链可变
区,氨基酸序列如seq id no:53所示的轻链恒定区;
213.(6)重链包含氨基酸序列如seq id no:41所示的重链可变区,氨基酸序列如seq id no:52所示的重链恒定区,并且轻链包含氨基酸序列如seq id no:46所示的轻链可变区,氨基酸序列如seq id no:53所示的轻链恒定区;
214.(7)重链包含氨基酸序列如seq id no:39所示的重链可变区,氨基酸序列如seq id no:52所示的重链恒定区,并且轻链包含氨基酸序列如seq id no:49所示的轻链可变区,氨基酸序列如seq id no:53所示的轻链恒定区;
215.(8)重链包含氨基酸序列如seq id no:55所示的重链可变区,氨基酸序列如seq id no:52所示的重链恒定区,并且轻链包含氨基酸序列如seq id no:66所示的轻链可变区,氨基酸序列如seq id no:53所示的轻链恒定区;
216.(9)重链包含氨基酸序列如seq id no:55所示的重链可变区,氨基酸序列如seq id no:52所示的重链恒定区,并且轻链包含氨基酸序列如seq id no:62所示的轻链可变区,氨基酸序列如seq id no:53所示的轻链恒定区;
217.(10)重链包含氨基酸序列如seq id no:59所示的重链可变区,氨基酸序列如seq id no:52所示的重链恒定区,并且轻链包含氨基酸序列如seq id no:65所示的可变区,氨基酸序列如seq id no:53所示的轻链恒定区;
218.(11)重链包含氨基酸序列如seq id no:59所示的重链可变区,氨基酸序列如seq id no:52所示的重链恒定区,并且轻链包含氨基酸序列如seq id no:69所示的轻链可变区,氨基酸序列如seq id no:53所示的轻链恒定区。
219.更优选地,本发明抗体包含具有两条轻链和两条重链的完整结构,所述抗体选自以下群组:
220.(1)重链包含氨基酸序列如seq id no:55所示的重链可变区,氨基酸序列如seq id no:52所示的重链恒定区,并且轻链包含氨基酸序列如seq id no:66所示的轻链可变区,氨基酸序列如seq id no:53所示的轻链恒定区;
221.(2)重链包含氨基酸序列如seq id no:55所示的重链可变区,氨基酸序列如seq id no:52所示的重链恒定区,并且轻链包含氨基酸序列如seq id no:62所示的轻链可变区,氨基酸序列如seq id no:53所示的轻链恒定区;
222.(3)重链包含氨基酸序列如seq id no:59所示的重链可变区,氨基酸序列如seq id no:52所示的重链恒定区,并且轻链包含氨基酸序列如seq id no:65所示的轻链可变区,氨基酸序列如seq id no:53所示的轻链恒定区;
223.(4)重链包含氨基酸序列如seq id no:59所示的重链可变区,氨基酸序列如seq id no:52所示的重链恒定区,并且轻链包含氨基酸序列如seq id no:69所示的轻链可变区,氨基酸序列如seq id no:53所示的轻链恒定区。
224.本发明第四方面,提供了一种分离的核酸分子,其编码本发明所述的抗体或抗原结合片段。编码本发明的抗体的重链和/或轻链的核酸在本发明的范围内,根据重链和/或轻链的氨基酸序列,本领域技术人员能够很容易得到相应的核酸序列。
225.本发明第五方面,提供了一种组合物,该组合物含有治疗有效量的本发明所述抗体或抗原结合片段,以及药学上可接受的载体、稀释剂、缓冲剂或赋形剂。
226.本发明第六方面,提供一种疫苗,其包含本发明抗体或抗原结合片段。
227.本发明第七方面,提供本发明所述抗体在制备用于检测样品中tigit的试剂中的用途。
228.本发明第八方面,提供本发明所述抗体或抗原结合片段、所述组合物、所述疫苗在制备用于预防和/或治疗肿瘤相关药物中的用途。其中所述肿瘤选自食管癌、胃肠癌、胰腺癌、甲状腺癌、结直肠癌、肾癌、肺癌(例如非小细胞肺癌)、肝癌、胃癌、头颈癌、膀胱癌、乳腺癌、子宫癌、宫颈癌、卵巢癌、前列腺癌、睾丸癌、生殖细胞癌、骨癌、皮肤癌、胸腺癌、胆管癌、黑素瘤、间皮瘤、淋巴瘤、骨髓瘤、肉瘤、成胶质细胞瘤、神经胶质母细胞瘤、白血病或癌症的转移性、难治性或复发性病灶。
229.本发明取得的有益效果:
230.本发明提供了高效结合人tigit的抗体或抗原结合片段,本发明抗体能特异性阻断tigit与cd155的相互作用,抑制肿瘤的生长,具有抗肿瘤活性。
231.术语
232.为容易地理解本发明,首先定义本文中使用的某些术语。
233.术语“tigit”是一种i型跨膜蛋白,具有ig样结构域。该术语包括变体、异体、同源物、直向同源物和平行同源物。例如,对人tigit特异的抗体可以在某些情况下与另一物种例如猴的tigit蛋白交叉反应。在其他实施方式中,对人tigit蛋白特异的抗体可以完全地对人tigit蛋白特异而不与其他物种或其他类型的蛋白交叉反应,或者可以与一些其他物种而非所有其他物种的tigit蛋白交叉反应。
234.术语“交叉反应”是指本文所述的抗体结合来自不同物种的tigit的能力。例如,本文所述的结合人tigit的抗体还可结合来自其它物种的tigit(例如,食蟹猴tigit)。交叉反应性可通过检测在结合测定法(例如,spr、elisa)中与纯化抗原的特定反应性,或与生理表达tigit的细胞的结合或以其它方式与生理表达tigit的细胞功能相互作用来测量。测定交叉反应性的方法包括本文所述的方法以及本领域已知的标准结合测定法,例如通过使用2000spr仪器(biacore ab,uppsala,sweden)的表面等离子体共振(spr)分析,或流式细胞术技术。
235.本文中的术语“抗体”意在包括全长抗体及其任何抗原结合片段(即,抗原结合部分)或单链。全长抗体是包含至少两条重(h)链和两条轻(l)链的糖蛋白,重链和轻链由二硫键连接。各重链由重链可变区(简称vh)和重链恒定区构成。重链恒定区由三个结构域构成,即ch1、ch2和ch3。各轻链由轻链可变区(简称vl)和轻链恒定区构成。轻链恒定区由一个结构域cl构成。vh和vl区还可以划分为称作互补决定区(cdr)的高变区,其由较为保守的框架区(fr)区分隔开。各vh和vl由三个cdr以及四个fr构成,从氨基端到羧基端以fr1、cdr1、fr2、cdr2、fr3、cdr3、fr4的顺序排布。重链和轻链的可变区包含与抗原相互作用的结合域。抗体的恒定区可以介导免疫球蛋白与宿主组织或因子的结合,包括多种免疫系统细胞(例如,效应细胞)和传统补体系统的第一组分(c1q)。
236.本领域技术人员公知,互补决定区(cdr,通常有cdr1、cdr2及cdr3)是可变区中对抗体的亲和力和特异性影响最大的区域。vh或vl的cdr序列有两种常见的定义方式,即kabat定义和chothia定义,例如参见见kabat etal,“seq uen ces ofpro teins ofimmunological interest”,national institutes of health,bethesda,md.(1991);al-lazikanietal.,jmolbiol273:927-948(1997);以及martinetal.,
proc.natl.acad.sci.usa 86:9268-9272(1989)。对于给定抗体的可变区序列,可以根据kabat定义或者chothia定义来确定vh和vl序列中的cdr区序列。在本技术的实施方案中,利用kabat定义cdr序列。在本文中,重链可变区的cdr1、cdr2及cdr3分别简称为hcdr1、hcdr2及hcdr3;轻链可变区的cdr1、cdr2及cdr3分别简称为lcdr1、lcdr2及lcdr3。
[0237]“特异性结合”是指两个分子之间的非随机结合反应,例如抗体与抗原表位的结合,例如抗体以比其对非特异性抗原的亲和性大至少两倍的亲和性结合于特异性抗原的能力。然而应了解,抗体能够特异性结合于两种或更多其序列相关的抗原。例如,本发明的抗体可特异性结合于人类与非人类(例如小鼠或非人类灵长动物)的tigit。
[0238]
本文所用的术语“分离的抗体”是指基本不含具有不同抗原特异性的其他抗体的抗体。例如,与tigit蛋白特异结合的分离抗体基本不含特异结合tigit蛋白之外抗原的抗体。但是,特异结合人tigit蛋白的分离抗体可能对其他抗原例如其他物种的tigit蛋白具有交叉结合性。此外,分离的抗体基本不含其他细胞材料和/或化学物质。
[0239]
术语“单克隆抗体”或“单抗”或“单克隆抗体组成”是指单一分子组成的抗体分子制品。单克隆抗体组成呈现出对于特定表位的单一结合特异性和亲和力。
[0240]
术语“小鼠源抗体”是指可变区框架和cdr区得自小鼠种系免疫球蛋白序列的抗体。此外,如果抗体包含恒定区,其也得自小鼠种系免疫球蛋白序列。本发明的鼠源抗体可以包含不由小鼠种系免疫球蛋白序列编码的氨基酸残基,例如通过体外随机突变或点突变或通过体内体细胞突变而导入的突变。然而,术语“鼠源抗体”不包括在小鼠框架序列中插入得自其他哺乳动物物种的cdr序列的抗体。
[0241]
术语“嵌合抗体”是指其中可变区源自一个物种和恒定区源自另一个物种的抗体,例如其中可变区源自小鼠抗体和恒定区源自人抗体的抗体。
[0242]
术语“人源化抗体”是指利用重组dna技术,将来自一个物种(如小鼠)的单克隆抗体的恒定区和可变区的非cdr(fv骨架区(fr))氨基酸序列全部替换为来自另一个物种(如人)的抗体的恒定区和可变区的非cdr氨基酸序列而获得的重组抗体。也即,一个抗体的恒定区被人源化时称为嵌合抗体,而恒定区和可变区的非cdr氨基酸序列全部人源化后称为人源化抗体。人源化的方法可以参照常规的抗体工程技术进行,在此不再赘述。
[0243]
术语“kassoc”或“ka”是指特定抗体-抗原相互作用的结合速率,而术语“kdis”或“kd”是指特定抗体-抗原相互作用的离解速率。术语“kd”是指平衡解离常数,由kd与ka比(kd/ka)得到,并以摩尔浓度(m)表示。抗体的kd值可以通过领域内已知的方法确定。确定抗体kd的方法包括使用表面等离子共振仪(spr)测得的,优选使用生物传感系统例如biacoretm系统测得;生物层干涉(bli)分析,优选地使用fortebio octet red装置;或流式细胞术和scatchard分析。
[0244]
术语“ec50”,又叫半最大效应浓度,是指引起反应的抗体或其抗原结合片段的浓度,所述反应是最大反应的50%,即最大反应和基线之间的一半。
[0245]
半数最大抑制浓度(ic50)是物质(例如抗体)抑制特定生物或生物化学功能的有效性的量度。它表明需要多少特定药物或其它物质(抑制剂,例如抗体)来抑制特定的生物过程(例如,tigit与cd155,或过程的组分即酶、细胞、细胞受体或微生物之间的结合)达一半。ic50或ec50可以通过生物测定来测量,例如通过facs分析(竞争结合测定)配体结合的抑制、基于细胞的细胞因子释放测定或扩增的发光邻近均相测定(alphalisa)。
[0246]
术语“受试者”是指接受预防性或治疗性的任何人或非人动物。术语“非人动物”包括所有脊椎动物,例如哺乳类和非哺乳类,例如非人灵长类、羊、狗、猫、牛、马、鸡、两栖类、和爬行类,尽管优选哺乳动物,例如非人灵长类、羊、狗、猫、牛和马。
[0247]
术语“治疗有效量”是指足以防止或减缓与疾病或病症(例如癌症)相关的症状和/或减轻疾病严重程度的本发明抗体量。治疗有效量与被治疗的疾病相关,其中本领域技术人员可以方便地判别出实际的有效量。
[0248]
术语“识别抗原的抗体”以及“对抗原特异的抗体”在本文中可以与术语“特异结合抗原的抗体”互换使用。
[0249]“亲和力成熟的”抗体是在其一个或多个cdr中具有一个或多个改变的一种抗体,所述一个或多个改变导致与不拥有一个或多个那些改变的亲本抗体相比抗体对抗原的亲和力得到改善。在一些实施方案中,亲和力成熟的抗体对靶抗原具有纳摩尔或甚至皮摩尔的亲和力。亲和力成熟的抗体通过本领域已知的程序产生。例如,marks等人,bio/technology10:779-783(1992)描述了通过vh-和vl-结构域改组的亲和力成熟。cdr和/或框架残基的随机诱变被例如以下参考文献所描述:barbas等人proc nat’l.acad.sci.usa91:3809-3813(1994);schier等人gene 169:147-155(1995);yelton等人j.immunol.155:1994-2004(1995);jackson等人,j.immunol.154(7):3310-9(1995);和hawkins等人,j.mol.biol.226:889-896(1992)。
附图说明
[0250]
图1hutigit-cho、cynotigit-cho细胞株构建成功验证实验
[0251]
图2嵌合抗体与hutigit-cho结合活性检测-1
[0252]
图3嵌合抗体与hutigit-cho结合活性检测-2
[0253]
图4嵌合抗体与hutigit-cho结合活性检测-3
[0254]
图5嵌合抗体与cynotigit-cho结合活性检测-1
[0255]
图6嵌合抗体与cynotigit-cho结合活性检测-2
[0256]
图7嵌合抗体与cynotigit-cho结合活性检测-3
[0257]
图8候选抗体阻断tigit与cd155的结合活性检测-1
[0258]
图9候选抗体阻断tigit与cd155的结合活性检测-2
[0259]
图10人源化抗体与hutigit-cho结合活性检测-1
[0260]
图11人源化抗体与hutigit-cho结合活性检测-2
[0261]
图12人源化抗体与hutigit-cho结合活性检测-3
[0262]
图13人源化抗体与hutigit-cho结合活性检测-4
[0263]
图14人源化抗体与hutigit-cho结合活性检测-5
[0264]
图15人源化抗体与cynotigit-cho结合活性检测-1
[0265]
图16人源化抗体与cynotigit-cho结合活性检测-2
[0266]
图17人源化抗体阻断tigit与cd155的结合活性检测-1
[0267]
图18人源化抗体阻断tigit与cd155的结合活性检测-2
[0268]
图19人源化抗体阻断tigit与cd155的结合活性检测-3
[0269]
图20亲和力成熟抗体与hutigit-cho结合活性检测-1
[0270]
图21亲和力成熟抗体与cynotigit-cho结合活性检测-1
[0271]
图22亲和力成熟抗体与hutigit-cho结合活性检测-2
[0272]
图23亲和力成熟抗体与cynotigit-cho结合活性检测-2
[0273]
图24亲和力成熟抗体阻断tigit与cd155的结合活性检测-1
[0274]
图25亲和力成熟抗体阻断tigit与cd155的结合活性检测-2
[0275]
图26亲和力成熟抗体阻断tigit与cd155的结合活性检测-3
[0276]
图27亲和力成熟抗体阻断tigit与cd155的结合活性检测-4
[0277]
图28 p2-2
nd-001抗体功能检测
[0278]
图29 sy15-84-231抗体功能检测
[0279]
图30 sy15-84-231和p2-2
nd-001给药后肿瘤体积变化图
[0280]
图31 sy15-84-231和p2-2
nd-001抑瘤率柱形图
具体实施方式
[0281]
实施例1原材料的制备
[0282]
在本实施例中,tigit抗原及其配体均购自acro biosystems,同时,根据专利(cn108290946a)制备了genentech公司的阳性抗体tiragolumab。
[0283]
1.1抗原的准备
[0284]
本技术中用到的抗原如下:human-tigit-mfc、cyno-tigit-fc、human-tigit-his和cyno-tigit-his,均购买于acro biosystems,货号分别为tit-h5253、tit-c5254、tit-h52h3和tit-c5223。
[0285]
1.2配体的准备
[0286]
本技术中使用的配体为human-cd155-fc,购买于acro biosystems,货号为cd5-h5251。
[0287]
1.3阳性对照抗体的制备
[0288]
本技术中,阳性对照抗体tiragolumab采用瞬转系统(expicho)进行表达,其中,用到的主要材料包括:gibco培养基,gibco转染试剂盒。首先,根据专利cn108290946a披露的序列合成tiragolumab的轻链序列和重链序列,通过分子克隆方法构建出包含完整tiragolumab抗体轻链和重链基因的质粒。将含有tiragolumab抗体轻链的质粒和重链的质粒按照2:1的质量比进行混合,在25ml表达体系内,按照标准流程将上述质粒混合物(25μg)与转染试剂进行混合并滴加入25ml的expicho细胞表达体系中。充分混匀后,于37℃细胞培养箱内表达18-22h。随后,向上述转染混合物中添加补料培养基并置于32℃细胞培养箱内继续培养。转染后第5天,添加第二次补料,并将细胞置于32℃细胞培养箱内继续培养10-12天。接着,将表达好的细胞混悬液进行高速离心并取上清,所得上清经0.22μm滤膜过滤后,采用protein a亲和层析柱亲和法进行纯化。纯化后,用100mm甘氨酸盐(ph3.0)洗脱目的蛋白,浓缩,置换,分装,经sds-page鉴定和活性鉴定后入库冻存。tiragolumab重轻链氨基酸序列如seq idno:94、95所示。
[0289]
实施例2细胞株的制备
[0290]
在本实施例中,分别构建了过表达人tigit的hutigit-cho细胞株和过表达猴tigit的cynotigit-cho细胞株。
[0291]
(1)hutigit-cho和cynotigit-cho细胞株的制备
[0292]
a、表达人和猴tigit全长的质粒的构建
[0293]
根据人和猴的氨基酸序列,通过基因合成技术分别合成含有人和食蟹猴的tigit全长蛋白的dna片段,并将其克隆至表达载体。通过转化的方法导入大肠杆菌,挑取大肠杆菌单克隆后测序得到正确的质粒克隆,进行质粒抽提并再次测序确认。其中,人的tigit的氨基酸序列如seq id no:96所示,食蟹猴的tigit的氨基酸序列如seq id no:97所示。
[0294]
b、电转
[0295]
使用gibco的cd-cho无血清培养基培养cho-s细胞。电转前一天,将细胞传代至5
×
106/ml,次日使用invitrogen的电转试剂盒和电转仪将构建好的质粒导入cho-s细胞中。将电转后的细胞移至cd-cho培养基中,放置于37℃细胞培养箱中培养48h。
[0296]
c、电转后细胞铺板
[0297]
将电转后的cho-s细胞按2000个细胞/孔铺到96孔板中,加入终浓度30μm msx和gs supplement,放置于37℃二氧化碳培养箱中培养,10天后补充加入含30μm msx和1
×
gssupplement的培养基。
[0298]
d、克隆挑选、细胞扩培和facs鉴定
[0299]
挑取96孔板中长出的单细胞克隆,转移至24孔培养板中继续扩大培养,之后通过facs方法,利用对照抗体tiragolumab分别鉴定人和猴tigit稳转成功的细胞株。图1为facs鉴定结果,结果显示,hutigit-cho和cynotigit-cho分别高表达人和猴tigit蛋白,图中的hu-igg为同种型对照抗体。
[0300]
实施例3动物免疫
[0301]
在本实施例中,动物免疫包括数种方案且同时进行,在免疫过程中,取小鼠血清进行效价检测并评估免疫的效果,最终根据血清效价决定建库的小鼠编号。
[0302]
(1)动物免疫
[0303]
通过皮下注射和腹腔注射的方式免疫balb/c小鼠(雌性,6-8周),材料包括上述提到的hutigit-mfc和cynotigit-fc抗原蛋白(acro biosystems),采用交叉免疫的方式。首次免疫剂量为100μg/只,并辅以cfa(完全弗氏佐剂),之后免疫剂量降至50μg/只,并辅以ifa(弗式不完全佐剂),均为两周一交叉免疫。并对小鼠进行编号。
[0304]
(2)血清效价elisa检测
[0305]
a、抗原包被和封闭:在elisa板上,提前一天分别包被hutigit-his和cynotigit-his抗原,包被浓度为2μg/ml,30μl/孔,4℃过夜。在免疫效价测定当日,用pbst洗板三次,并用5%的脱脂牛奶室温封闭2h,再用pbst洗板三次。
[0306]
b、一抗和二抗孵育:各个血清样本在原液的基础上先稀释500倍,再进行3倍梯度稀释后,作为一抗加到elisa板中,室温下孵育1h,pbst洗板三次后,加入二抗,室温下孵育1h。
[0307]
c、显色、终止和读板:孵育完成后,pbst洗板六次,加tmb显色,根据显色结果,加入2m hcl终止反应,通过酶标仪在od450下读板。
[0308]
d、选择对人tigit蛋白和猴tigit蛋白的效价均很高的免疫小鼠作为备用小鼠,用于下一步的抗体库构建。
[0309]
实施例4候选抗体产生
[0310]
(1)噬菌体展示抗体基因文库构建
[0311]
在免疫结束后,按安乐死标准流程处理小鼠。取备用小鼠脾脏,经研磨和过滤后,收集脾细胞,加入1ml的trizol
tm reagent裂解脾细胞,通过酚氯仿法提取总rna,通过反转录试剂盒将提取的rna反转录成cdna。之后,以cdna为pcr模板,采用鼠源抗体序列扩增的特异性引物,分别扩增抗体的轻链和重链可变区和ch1基因。最后,通过ncoi+noti双酶切和t4连接酶连接,将抗体基因片段插入至噬菌体展示用载体上,连接产物通过dna回收试剂盒回收,最后通过电转仪转化至感受态大肠杆菌ss320中,并涂布于含有氨苄青霉素和四环素的2xyt固体平板,扩增正确转化的抗体质粒的ss320菌,最终构建成含fab段抗体序列的文库。
[0312]
(2)噬菌体展示抗体基因文库筛选
[0313]
a、磁珠法筛选噬菌体展示抗体基因文库
[0314]
磁珠法筛选是基于将biotin标记的抗原蛋白和偶联有avidin的磁珠结合,通过将结合抗原的磁珠和文库进行孵育、洗涤和洗脱的海选过程,经历2-4轮的海选,最终将针对抗原的特异性单克隆抗体富集下来的过程。本实施例中利用biotin标记的人tigit抗原和猴tigit抗原交叉海选的原则,其中第一和第三轮采用人tigit海选,第二轮采用猴tigit海选,一共海选3轮,然后将富集的抗体序列混合物,进行人和猴抗原的单克隆初筛。
[0315]
具体实施方法如下:
[0316]
首先用biotin标记的人tigit-mfc蛋白与avidin偶联的磁珠孵育,使得人tigit-mfc蛋白结合到磁珠上。将结合有tigit-fc-biotin抗原的磁珠和构建的噬菌体库室温下孵育2h。经pbst洗涤6-8次后,去除非特异性吸附的噬菌体,加入trypsin轻轻混匀并反应20min,以洗脱特异性结合的抗体展示噬菌体。随后,用洗脱下来的噬菌体侵染对数期的ss320菌体并静置30min,然后在220rpm条件下培养1h,再加入vscm13辅助噬菌体并静置30min,继续在220rpm条件下培养1h,最后离心并置换至氨苄青霉素和四环素的2
×
yt培养基中,最终得到的噬菌体继续用于下一轮的海选,二轮海选使用猴tigit-fc-biotin蛋白,三轮海选继续使用人tigit-mfc-biotin,三轮海选结束则海选完成。
[0317]
b、免疫管法筛选噬菌体展示抗体基因文库
[0318]
免疫管筛选的原理是将人和猴tigit蛋白包被在具有高吸附力的免疫管表面,通过将噬菌体展示抗体文库加入免疫管中并和吸附于免疫管表面的抗原蛋白进行孵育、洗涤和洗脱的海选过程,经历2-4轮海选,最终将针对抗原的特异性单克隆抗体富集下来的过程。免疫管法和磁珠法的目的均为富集针对抗原的特异性抗体,为两个互补的实验方法。本实施例中以人tigit-his抗原和猴tigit-his抗原交叉海选的原则,其中第一和第三轮采用人抗原海选,第二轮采用猴抗原海选,一共海选3轮,然后将富集的抗体序列混合物,进行人和猴tigit-his的单克隆初筛。具体实施方法与磁珠法筛选类同。
[0319]
(3)单克隆的挑选
[0320]
在三轮筛选后,从第三轮的pool中挑选部分单克隆进行elisa检测,包括与人和猴tigit的结合。最终,在960个克隆中共挑到22个能够与人和猴tigit都结合的阳性克隆,经测序分析及与人和猴tigit亲和力排序结果分析后,最终选取了sy15-4、sy15-20、sy15-25、sy15-39、sy15-47、sy15-61、sy15-84、sy15-96以及sy15-p2-001、sy15-p2-003和sy15-p5-001共11个克隆,根据kabat编码,抗体cdrs氨基酸序列信息见表1(seq id no:1-seq id no:32),轻重链可变区序列如表2(seq id no:33-seq id no:51)所示。
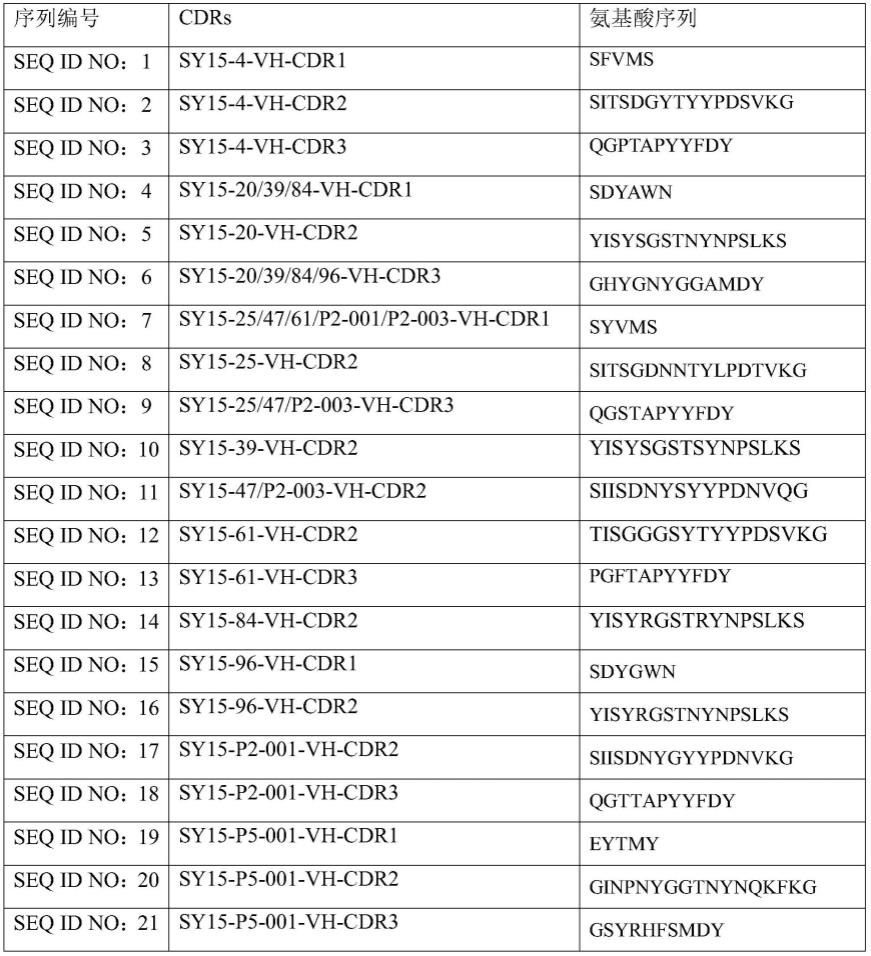
[0321]
表1抗体cdrs氨基酸序列
[0322]
[0323][0324]
表2抗体轻重链可变区氨基酸序列
[0325]
[0326]
[0327][0328]
实施例5嵌合抗体构建、表达与纯化
[0329]
5.1质粒的构建
[0330]
将获得的11个鼠源抗体的重链与轻链可变区基因分别与人igg1的重链恒定区及κ轻链恒定区基因连接而成的。将得到的重链与轻链嵌合基因分别插入载体pcdna3.4(invitrogen,美国),用以表达嵌合抗体。重链和轻链恒定区氨基酸分别对应seq id no:52和seq id no:53。
[0331]
seq id no:52:
[0332]
astkgpsvfplapsskstsggtaalgclvkdyfpepvtvswnsgaltsgvhtfpavlqssglyslssvvtvpssslgtqtyicnvnhkpsntkvdkkvepkscdkthtcppcpapellggpsvflfppkpkdtlmisrtpevtcvvvdvshedpevkfnwyvdgvevhnaktkpreeqynstyrvvsvltvlhqdwlngkeykckvsnkalpapiektiskakgqprepqvytlppsreemtknqvsltclvkgfypsdiavewesngqpennykttppvldsdgsfflyskltvdksrwqqgnvfscsvmhealhnhytqkslslspgk
[0333]
seq id no:53:
[0334]
rtvaapsvfifppsdeqlksgtasvvcllnnfypreakvqwkvdnalqsgnsqesvteqds
[0335]
kdstyslsstltlskadyekhkvyacevthqglsspvtksfnrgec
[0336]
5.2抗体的表达纯化
[0337]
本技术中,抗体采用的是expicho瞬转表达系统。具体方法如下:转染前一天将expicho细胞进行传代,在25ml体系内,将构建好的质粒25μg与转染试剂混合之后滴加入25ml expicho细胞中,充分混匀后,于37℃细胞培养箱内表达18-22h。随后,向上述转染混
合物中添加补料培养基并置于32℃细胞培养箱内继续培养。转染后第5天,添加第二次补料,并将细胞置于32℃细胞培养箱内继续培养10-12天。接着,将表达好的细胞混悬液进行高速离心并取上清,所得上清经0.22μm滤膜过滤后,采用proteina亲和层析柱亲和法进行纯化。纯化后,用100mm甘氨酸(ph3.0)洗脱目的蛋白,浓缩,置换,分装,经sds-page鉴定、sec纯度检测、活性鉴定后入库冻存。
[0338]
上述鼠源抗体的轻重链可变区与人源抗体的轻重链恒定区连接后形成的嵌合抗体,将鼠源sy15-4抗体对应的嵌合抗体命名为chsy15-4,其他抗体类推。以上嵌合抗体将作为进行人源化的候选抗体,并进行相关活性检测。
[0339]
实施例6候选抗体与人/猴tigit过表达细胞株的亲和活性检测
[0340]
在本实施例中,基于facs方法验证候选抗体对表达人和猴tigit细胞的亲和活性。
[0341]
6.1基于facs检测候选抗体对hutigit-cho细胞的亲和效果
[0342]
收集指数生长期的hutigit-cho细胞,300g离心去上清,将细胞用配制好的facs缓冲液重悬,计数并将细胞悬液密度调整为2
×
106/ml。随后,将tigit-cho细胞以每孔100μl加入96孔圆底板中,300g离心去上清。向对应孔中加入梯度稀释的候选抗体和阳性对照抗体tiragolumab以及阴性对照抗体hu-igg稀释液,用排枪将细胞吹匀并放置于4℃下孵育30min。将孵育后的细胞混合液300g离心去上清,向对应孔中加入200μl的facs缓冲液并使用排枪重悬细胞;重复两次,300g离心去上清;加入pe标记的anti-human-igg-fc流式抗体,用排枪将细胞吹匀并放置于4℃下孵育30min,300g离心去上清。随后,加入facs缓冲液并重悬细胞,重复两次后向孔中加入facs缓冲液,每孔200μl,重悬细胞。最后,通过流式细胞仪(beckman,cytoflex)上机检测收集数据,利用graphpadprism软件分析数据。本实施例中,结果显示在图2、图3、图4中,ec50列于表3中;结果表明,多数候选抗体对于人tigit-cho细胞的亲和效果都优于阳性对照抗体tiragolumab,尤其是chsy15-84、chsy15-96、chsy15-p2-001和chsy15-p5-001结合人tigit活性明显优于阳性对照抗体tiragolumab;chsy15-20、chsy15-39、chsy15-47、chsy15-61和chsy15-p2-003次之,chsy15-4和chsy15-25稍弱。
[0343]
表3候选抗体与hutigit-cho结合的ec50值
[0344]
absec50(μg/ml)chsy15-40.1814chsy15-200.09698chsy15-250.1736chsy15-470.1185chsy15-390.1051chsy15-610.1097chsy15-840.04698chsy15-960.06088chsy15-p2-0010.04656chsy15-p2-0030.09082chsy15-p5-0010.07835tiragolumab0.1382hu-igg/
[0345]
6.2基于facs检测候选抗体对猴tigit-cho细胞的亲和效果
[0346]
本实施例中,操作流程与6.1完全一致,与之不同的是,细胞为猴tigit-cho细胞,其结果显示在表4、图5、图6、图7中,结果表明抗体chsy15-20、chsy15-47、chsy15-61、chsy15-84、chsy15-p2-001、chsy15-p2-003、chsy15-p5-001与猴tigit-cho细胞交叉结合力明显强于阳性对照抗体tiragolumab,chsy15-4、chsy15-25次之,chsy15-39和chsy15-96与猴tigit-cho细胞的结合能力较差。
[0347]
表4候选抗体与cynotigit-cho结合的ec50值
[0348][0349][0350]
综合以上抗体对人/猴tigit-cho细胞的亲和效果可见,sy15-84,sy15-p2-001、sy15-p5-001、sy15-61、sy15-47、sy15-p2-003、sy15-20结合人/猴tigit-cho都很好,其中sy15-84,sy15-p2-001最优,其他次之。
[0351]
实施例7候选抗体阻断效应检测
[0352]
在本实施例中,利用检测抗体在人tigit-cho细胞上阻断cd155蛋白结合tigit抗原的方法体系对候选抗体的阻断效应进行了相应检测,基本原理为通过facs检测在有无候选抗体存在的情况下配体受体的结合,通过检测配体信号从而间接反映出候选抗体对cd155-tigit结合的阻断活性。
[0353]
具体检测方法如下:收集指数生长期的人tigit-cho细胞,300g离心去上清,将细胞用配制好的facs缓冲液重悬,计数并将细胞悬液密度调整为2
×
106/ml。随后,将tigit-cho细胞以每孔100μl加入96孔圆底板中,300g离心去上清。向对应孔中加入cd155-mfc蛋白稀释液,与细胞混合后于4℃下孵育30min。后将细胞离心去掉上清,再向细胞中加入梯度稀释的候选抗体和阳性对照抗体、阴性对照稀释液,用排枪将细胞吹匀并放置于4℃下孵育30min。将孵育后的细胞混合液300g离心去上清,向对应孔中加入200μl的facs缓冲液并使
用排枪重悬细胞;300g离心去上清;重复操作两次。加入pe标记的anti-human-igg-fc流式抗体,用排枪将细胞吹匀并放置于4℃下孵育30min,300g离心去上清。随后,加入facs缓冲液并重悬细胞,离心去上清,重复洗涤两次。后向细胞中加入facs缓冲液,每孔200μl,重悬细胞。最后,通过流式细胞仪(beckman,cytoflex)上机检测。收集检测结果,利用graphpadprism软件分析数据。
[0354]
在本实施例中,结果显示在表5、图8、图9中,结果表明,多数候选抗体的阻断效果优于阳性对照抗体tiragolumab,其中chsy15-84和chsy15-p2-001的阻断效果显著优于阳性对照抗体tiragolumab,其次为chsy15-20、chsy15-p2-003、chsy15-47和chsy15-61。
[0355]
表5候选抗体阻断tigit与cd155的结合ic50值
[0356][0357][0358]
实施例8抗体人源化改造
[0359]
为了降低分子在体内的免疫原性,并根据结合/阻断实验数据以及抗体序列综合分析,选择sy15-p2-001和sy15-84两个抗体分子进行人源化改造。使用discovery studio,采用同源建模方法建模,选取5-10个最优结构解,loop区域一般使用同源建模方法建模,如cdr氨基酸序列比对结果显示低于50%同一性,则使用从头建模方法搭建cdr3结构模型。使用pdb blast调取序列最接近的10个抗体晶体结构模型(结构分辨率高于2.5埃),对比自动建模模型,对包埋残基、与cdr区有直接相互作用的残基,以及对vh和vl的构象有重要影响的残基进行回复突变,选取最优的结构模型。人源化改造的候选抗体包括克隆sy15-p2-001和sy15-84号克隆,分别对抗体的轻重链可变区进行人源化,设计3条人源化序列(人源化程度依次增加),其中人源化后的重链可变区分别为huvh1/huvh2/huvh3,人源化后的轻链可变区分别为huvl1/huvl2/huvl3,并以此命名得到的抗体,如sy15-84经人源化后得到重链可变区huvh1与轻链可变区huvl1,那么抗体sy15-84可变区经此人源化重组得到的抗体可命名为sy15-84-huvh1+huvl1,其他以此类推。抗体人源化后可变区氨基酸序列见表6中seq id no:54-seq id no:66,组合后采用expi-cho瞬转体系进行表达,瞬转表达具体方法详见实施例5。
[0360]
表6人源化抗体轻重链可变区氨基酸序列
[0361]
[0362][0363]
sy15-p2-001人源化后得到三种重链可变区,根据kabat编码,其hcdrs氨基酸序列如下两组所示:
[0364]
(1)人源化分子sy15-p2-001-huvh1和sy15-p2-001-huvh2:
[0365]
seq id no:7
ꢀꢀꢀ
hcdr1:
ꢀꢀꢀ
syvms
[0366]
seq id no:17
ꢀꢀ
hcdr2:
ꢀꢀꢀ
qgttapyyfdy
[0367]
seq id no:18
ꢀꢀ
hcdr3:
ꢀꢀꢀ
qgttapyyfdy
[0368]
(2)人源化分子sy15-p2-001-huvh3:
[0369]
seq id no:7
ꢀꢀꢀ
hcdr1:
ꢀꢀꢀ
syvms
[0370]
seq id no:81
ꢀꢀ
hcdr2:
ꢀꢀꢀ
siisdnygyypdsvkg
[0371]
seq id no:18
ꢀꢀ
hcdr3:
ꢀꢀꢀ
qgttapyyfdy
[0372]
sy15-p2-001人源化后得到三种轻链可变区,根据kabat编码,其lcdrs氨基酸序列如下两组所示:
[0373]
(1)人源化分子sy15-p2-001-huvl1:
[0374]
seq id no:82
ꢀꢀ
lcdr1:
ꢀꢀꢀ
rasssvsymh
[0375]
seq id no:23
ꢀꢀ
lcdr2:
ꢀꢀꢀ
dtsklas
[0376]
seq id no:28
ꢀꢀ
lcdr3:
ꢀꢀꢀ
qqwssnpft
[0377]
(2)人源化分子sy15-p2-001-huvl2和sy15-p2-001-huvl3:
[0378]
seq id no:82
ꢀꢀ
lcdr1:
ꢀꢀꢀ
rasssvsymh
[0379]
seq id no:83
ꢀꢀ
lcdr2:
ꢀꢀꢀ
dtsklat
[0380]
seq id no:28
ꢀꢀ
lcdr3:
ꢀꢀꢀ
qqwssnpftsy15-84人源化后得到三种重链可变区,根据kabat编码,其hcdrs氨基酸序列相同,如下所示:
[0381]
(1)人源化分子sy15-84-huvh1、sy15-84-huvh2和sy15-84-huvh3:
[0382]
seq id no:4
ꢀꢀꢀ
hcdr1:
ꢀꢀꢀ
sdyawn
[0383]
seq id no:14
ꢀꢀ
hcdr2:
ꢀꢀꢀ
yisyrgstrynpslks
[0384]
seq id no:6
ꢀꢀꢀ
hcdr3:
ꢀꢀꢀ
ghygnyggamdy
[0385]
sy15-84人源化后得到三种轻链可变区,根据kabat编码,其lcdrs氨基酸序列如下两组所示:
[0386]
(1)人源化分子sy15-84-huvl1和sy15-84-huvl2:
[0387]
seq id no:85
ꢀꢀ
lcdr1:
ꢀꢀꢀ
rasqdvstava
[0388]
seq id no:26
ꢀꢀ
lcdr2:
ꢀꢀꢀ
sasyryt
[0389]
seq id no:30
ꢀꢀ
lcdr3:
ꢀꢀꢀ
qqhystpft
[0390]
(2)人源化分子sy15-84-huvl3:
[0391]
seq id no:85
ꢀꢀ
lcdr1:
ꢀꢀꢀ
rasqdvstava
[0392]
seq id no:86
ꢀꢀ
lcdr2:
ꢀꢀꢀ
sasyrys
[0393]
seq id no:30
ꢀꢀ
lcdr3:
ꢀꢀꢀ
qqhystpft
[0394]
实施例9人源化抗体功能验证
[0395]
9.1基于facs检测候选抗体对人tigit-cho细胞的结合效果
[0396]
具体操作参见实施例6,实验结果见图10、图11、图12、图13、图14、表7,结果表明,候选抗体人源化改造后与人tigit-cho细胞结合效果均优于tiragolumab,其中sy15-84-huvh2+huvl3和sy15-p2-001-huvh3+huvl3与人tigit-cho细胞结合效果最佳,显著优于阳性对照抗体tiragolumab,其他次之。
[0397]
表7人源化抗体与hutigit-cho结合的ec50值
[0398]
absec50(μg/ml)chsy15-840.04647sy15-84-huvh1+huvl10.04119sy15-84-huvh2+huvl20.04449sy15-84-huvh3+huvl30.04981
sy15-84-huvh2+huvl30.02358sy15-84-huvh3+huvl20.02927chsy15-p2-0010.04609sy15-p2-001-huvh1+huvl10.06755sy15-p2-001-huvh2+huvl20.05593sy15-p2-001-huvh3+huvl30.02567tiragolumab0.1385hu-igg/
[0399]
9.2基于facs检测候选抗体对猴tigit-cho细胞的亲和效果
[0400]
具体操作参见实施例6,结果见图15、图16、表8,结果表明,人源化后抗体sy15-84-huvh1+huvl1、sy15-84-huvh2+huvl2和sy15-84-huvh3+huvl3与猴tigit-cho细胞结合能力弱于chsy15-84;sy15-84-huvh2+huvl3和sy15-84-huvh3+huvl2好于对照,sy15-84-huvh2+huvl3结合效果最佳。
[0401]
sy15-p2-001人源化改造后的三种抗体与猴tigit-cho细胞结合效果均好于chsy15-p2-001,且均优于阳性对照抗体tiragolumab。
[0402]
综合与人/猴tigit-cho细胞结合结果,可以看出人源化后的sy15-84-huvh2+huvl3和sy15-p2-001-huvh3+huvl3与人/猴tigit-cho细胞结合效果最佳。
[0403]
表8 sy15-84人源化后抗体与cynotigit-cho结合的ec50值
[0404]
absec50(μg/ml)chsy15-840.1440sy15-84-huvh1+huvl1/sy15-84-huvh2+huvl22.791sy15-84-huvh3+huvl36.117sy15-84-huvh2+huvl30.1295sy15-84-huvh3+huvl20.1755chsy15-p2-0010.1478sy15-p2-001-huvh1+huvl10.1119sy15-p2-001-huvh2+huvl20.1035sy15-p2-001-huvh3+huvl30.0829tiragolumab0.2403hu-igg/
[0405]
9.3基于facs检测候选抗体对cd155结合tigit的阻断效果
[0406]
具体操作参见实施例7,结果见表9、表10、图17、图18和图19。如表9和图17所示,sy15-84-huvh2+huvl2、sy15-84-huvh2+huvl3、sy15-84-huvh3+huvl3阻断效果均优于chsy15-84和tiragolumab,其中sy15-84-huvh2+huvl3阻断tigit与cd155结合的效果最佳,其他次之。
[0407]
表9人源化抗体阻断tigit结合cd155的ic50值
[0408]
absic50(μg/ml)chsy15-840.04682
his-bio抗原,进行了多轮液相筛选,淘筛到的克隆用原核表达的可溶性抗体elisa判定相对亲和力。对亲和力高于sy15-84-23的优选克隆进行序列分析,从而获得每个cdr区对亲和力提高或者维持有意义的突变序列信息,并以上述筛选到的克隆作为模板,分别扩增相应的cdr-l1+cdr-l2,cdr-l3,与sy15-84-23的vh,进行体外重组,获得轻链cdr突变体与vh组成的二级抗体库。针对二级库使用更低浓度的抗原进行了多轮液相筛选和富集,淘筛到的克隆用原核表达的可溶性抗体elisa判定相对亲和力,得到若干亲和力提高的多cdr突变的scfv抗体。获得了3个可能优于sy15-84-23的克隆,抗体重链可变区和轻链可变区分别与重链和轻链恒定区连接后构建全长抗体,分别命名为sy15-84-231、sy15-84-232和sy15-84-233,转入真核表达系统,质粒构建以及抗体表达与纯化方法参见实施例5。
[0419]
利用同样方法对sy15-p2-001-33进行亲和力成熟改造筛选,获得了4个可能优于母本的克隆,分别命名为p2-2
nd-001、p2-2
nd-002、p2-2
nd-003、p2-2
nd-004。
[0420]
所有构建均进行测序鉴定,sy15-84-231、sy15-84-232和sy15-84-233的重链可变区同sy15-84-23的重链可变区序列,如seq id no:55所示,轻链可变区分别如seq id no:66-seq id no:68所示;p2-2
nd-001、p2-2
nd-002、p2-2
nd-003和p2-2
nd-004的重链可变区同sy15-p2-001-33的重链可变区序列,如seq id no:59所示,轻链可变区分别如seq id no:69-seq id no:72所示,具体序列如表12所示。
[0421]
表12亲和力成熟抗体轻链可变区氨基酸序列
[0422]
[0423][0424]
根据kabat编码,sy15-p2-001-huvh3+huvl3(sy15-p2-001-33)经亲和力成熟筛选后具有如下所示氨基酸序列:
[0425]
sy15-p2-001-33经亲和力成熟筛选后得到的四种重链可变区的hcdrs氨基酸序列相同,具体如下所示:
[0426]
seq id no:7
ꢀꢀꢀ
hcdr1:
ꢀꢀꢀ
syvms
[0427]
seq id no:81
ꢀꢀ
hcdr2:
ꢀꢀꢀ
siisdnygyypdsvkg
[0428]
seq id no:18
ꢀꢀ
hcdr3:
ꢀꢀꢀ
qgttapyyfdy
[0429]
sy15-p2-001-33经亲和力成熟筛选后得到的四种轻链可变区的lcdrs氨基酸序列具体如下所示:
[0430]
亲和力成熟分子p2-2
nd-001-vl
[0431]
seq id no:82
ꢀꢀ
lcdr1:
ꢀꢀꢀ
rasssvsymh
[0432]
seq id no:83
ꢀꢀ
lcdr2:
ꢀꢀꢀ
dtsklat
[0433]
seq id no:84
ꢀꢀ
lcdr3:
ꢀꢀꢀ
qqwsgnpft
[0434]
亲和力成熟分子p2-2
nd-002-vl
[0435]
seq id no:82
ꢀꢀ
lcdr1:
ꢀꢀꢀ
rasssvsymh
[0436]
seq id no:83
ꢀꢀ
lcdr2:
ꢀꢀꢀ
dtsklat
[0437]
seq id no:88
ꢀꢀ
lcdr3:
ꢀꢀꢀ
gqwssnpft
[0438]
亲和力成熟分子p2-2
nd-003-vl
[0439]
seq id no:89
ꢀꢀ
lcdr1:
ꢀꢀꢀ
rasasvsymh
[0440]
seq id no:83
ꢀꢀ
lcdr2:
ꢀꢀꢀ
dtsklat
[0441]
seq id no:90
ꢀꢀ
lcdr3:
ꢀꢀꢀ
qqwtgnpft
[0442]
亲和力成熟分子p2-2
nd-004-vl
[0443]
seq id no:82
ꢀꢀ
lcdr1:
ꢀꢀꢀ
rasssvsymh
[0444]
seq id no:83
ꢀꢀ
lcdr2:
ꢀꢀꢀ
dtsklat
[0445]
seq id no:91
ꢀꢀ
lcdr3:
ꢀꢀꢀ
qewssnpft
[0446]
根据kabat编码,sy15-84-huvh2+huvl3(sy15-84-23)经亲和力成熟筛选后具有如下所示氨基酸序列:
[0447]
sy15-84-23经亲和力成熟筛选后得到的三种重链可变区的hcdrs氨基酸序列相同,具体如下所示:
[0448]
seq id no:4
ꢀꢀꢀ
hcdr1:
ꢀꢀꢀ
sdyawn
[0449]
seq id no:14hcdr2:
ꢀꢀꢀ
yisyrgstrynpslks
[0450]
seq id no:6
ꢀꢀꢀ
hcdr3:
ꢀꢀꢀ
ghygnyggamdy
[0451]
sy15-84-23经亲和力成熟筛选后得到的三种轻链可变区的lcdrs氨基酸序列具体如下所示:亲和力成熟分子84-23-vl
[0452]
seq id no:85
ꢀꢀ
lcdr1:
ꢀꢀꢀ
rasqdvstava
[0453]
seq id no:86
ꢀꢀꢀ
lcdr2:
ꢀꢀꢀ
sasyrys
[0454]
seq id no:87
ꢀꢀꢀ
lcdr2:
ꢀꢀꢀ
qqhystywt
[0455]
亲和力成熟分子84-24-vl
[0456]
seq id no:85
ꢀꢀꢀ
lcdr1:
ꢀꢀꢀ
rasqdvstava
[0457]
seq id no:86
ꢀꢀꢀ
lcdr2:
ꢀꢀꢀ
sasyrys
[0458]
seq id no:92
ꢀꢀꢀ
lcdr3:
ꢀꢀꢀ
qqhystvwt
[0459]
亲和力成熟分子84-25-vl
[0460]
seq id no:85
ꢀꢀꢀ
lcdr1:
ꢀꢀꢀ
rasqdvstava
[0461]
seq id no:86
ꢀꢀꢀ
lcdr2:
ꢀꢀꢀ
sasyrys
[0462]
seq id no:93
ꢀꢀꢀ
lcdr3:
ꢀꢀꢀ
qqhystnwt
[0463]
利用facs实验对上述获得的真核表达的单抗进行与表达人或猴tigit的cho细胞结合活性和阻断效果检测,具体参照实施例6和7进行。sy15-84-231、sy15-84-232和sy15-84-233与hu/cynotigit-cho的结合活性分别如表13、图20和图21所示;由结果可见sy15-84-23分子进行亲和力成熟后与cynotigit-cho的结合活性显著提高,结合强度远高于亲和力成熟之前,其中sy15-84-231与人/猴-tigit的结合效果与sy15-84-23相比显著提高。
[0464]
p2-2
nd-001、p2-2
nd-002、p2-2
nd-003、p2-2
nd-004与hu/cynotigit-cho的结合活性分别如表13、图22和图23所示;结果显示,与sy15-p2-001-33相比,亲和力成熟后的p2-2
nd-001与人/猴-tigit的结合效果显著提高。
[0465]
表14、图24、图25、图26、图27显示了亲和力成熟后抗体sy15-84-231、sy15-84-232、sy15-84-233、p2-2
nd-001、p2-2
nd-002、p2-2
nd-003和p2-2
nd-004阻断cd155与表达于cho细胞表面的人tigit的结合效果。结果显示,sy15-84-231和p2-2
nd-001阻断效果比亲和力成熟前显著提高。
[0466]
表13亲和力成熟后抗体与人/猴-tigit结合的ec50值
[0467]
absec50(hutigit-cho)ec50(cynotigit-cho)sy15-84-230.027220.1412sy15-84-2310.024180.07553sy15-84-2320.027000.1009sy15-84-2330.025370.1059sy15-p2-001-330.026160.08332p2-2
nd-0010.018920.06254p2-2
nd-0020.023350.08514p2-2
nd-0030.025490.08325p2-2
nd-0040.026140.09510tiragolumab0.10220.2341hu-igg//
[0468]
表14亲和力成熟后抗体阻断tigit结合cd155的ic50值
[0469]
absic50(μg/ml)sy15-84-230.02218sy15-84-2310.01634
sy15-84-2320.02220sy15-84-2330.02162sy15-p2-001-330.04068p2-2
nd-0010.02624p2-2
nd-0020.03484p2-2
nd-0030.03988p2-2
nd-0040.03390tiragolumab0.1312hu-igg/
[0470]
实施例11亲和力成熟后候选抗体功能活性检测
[0471]
在本实施例中,检测了sy15-84-231(见seq id no:55、seq id no:52、seq id no:66、seq id no:53,即重链氨基酸序列为seq id no:73,轻链序列为seq id no:74所示;重轻链核苷酸序列分别如seq id no:77、78)和p2-2
nd-001(见seq id no:59、seq id no:52、seq id no:69、seq id no:53,即重轻链氨基酸序列分别如seq id no:75、76所示;重轻链核苷酸序列分别如seq id no:79、80)抗体以及阳性对照抗体打破免疫耐受,激活免疫细胞的活性。通过稳定转染t细胞受体(tcr)激活剂,将cho-k1细胞工程化为人工抗原递呈细胞(apc)。cho-k1 apc细胞上过量表达cd155即cd155-cho-k1apc细胞系。用nfat诱导型luciferase报告基因构建体稳定转染jurkat细胞系,以生成jurkat/nfat报告基因细胞系。然后,jurkat/nfat报告基因细胞系构建过量表达有人tigit和cd226即tigit/cd226/nfat-luc-jurkat细胞系。分别培养tigit/cd226/nfat-luc-jurkat细胞和cd155-cho-k1 apc细胞,将tigit/cd226/nfat-luc-jurkat细胞以1
×
105/孔铺板入96-孔平底细胞培养板,后将cd155-cho-k1 apc细胞以7
×
104/孔铺板,与tigit/cd226/nfat-luc-jurkat混合后共培养;提前将sy15-84-231和p2-2
nd-001抗体、阳性对照抗体的系列稀释液与细胞混合,使用排枪轻轻吹匀,将细胞放置于37℃co2培养箱培养18h。18h后取出细胞并加入萤光素酶试剂bright-lite luciferase assay substrate(vazyme,7e472e0)30μl/孔,反应5-10分钟后检测荧光信号。
[0472]
通过萤光素酶信号的强度来评价jurkat/nfat报告基因/tigit/cd226细胞的激活。在两种细胞之间cd155对tigit的结合抑制了jurkat/nfat报告基因/tigit/cd226细胞激活。抗人tigit单克隆抗体阻断了cd155与tigit之间的相互作用,然后中和了cd155对tigit的抑制。添加的抗体越多,激活的jurkat/nfat报告基因/tigit/cd226细胞越多,萤光素酶信号越多。通过prismtm(graphpad软件,san diego,ca)使用非线性回归来分析数据,并且对归一化的萤光素酶信号计算ec50值。
[0473]
结果见表15、图28、图29,结果显示亲和力成熟后的人源化后抗体sy15-84-231和p2-2
nd-001活性优于对照抗体。
[0474]
表15亲和力成熟抗体活性检测
[0475]
absec50(μg/ml)p2-2
nd-0010.01758sy15-84-2310.01180tiragolumab0.04196
[0476]
sy15-84-231重链氨基酸序列(seq id no:73)
[0477]
qvqlqesgpglvkpsqtlsltctvsgysitsdyawnwirqppgkglewmgyisyrgstrynpslksritisrdtsknqfslklssvtaadtavyycvgghygnyggamdywgqgttvtvssastkgpsvfplapsskstsggtaalgclvkdyfpepvtvswnsgaltsgvhtfpavlqssglyslssvvtvpssslgtqtyicnvnhkpsntkvdkkvepkscdkthtcppcpapellggpsvflfppkpkdtlmisrtpevtcvvvdvshedpevkfnwyvdgvevhnaktkpreeqynstyrvvsvltvlhqdwlngkeykckvsnkalpapiektiskakgqprepqvytlppsreemtknqvsltclvkgfypsdiavewesngqpennykttppvldsdgsfflyskltvdksrwqqgnvfscsvmhealhnhytqkslslspgk
[0478]
sy15-84-231轻链氨基酸序列(seq id no:74)
[0479]
diqmtqspsslsasvgdrvtitcrasqdvstavawyqqkpgkapklliysasyrysgvpsrfsgsgsgtdftftissvqpedfatyycqqhystywtfgqgtkleikrtvaapsvfifppsdeqlksgtasvvcllnnfypreakvqwkvdnalqsgnsqesvteqdskdstyslsstltlskadyekhkvyacevthqglsspvtksfnrgec
[0480]
p2-2nd-001重链氨基酸(seq id no:75)
[0481]
evqlvesggglvkpggslrlscaasgftfnsyvmswvrqapgkglewvasiisdnygyypdsvkgrftisrdnaknslylqinslraedtavyycarqgttapyyfdywgqgttvtvssastkgpsvfplapsskstsggtaalgclvkdyfpepvtvswnsgaltsgvhtfpavlqssglyslssvvtvpssslgtqtyicnvnhkpsntkvdkkvepkscdkthtcppcpapellggpsvflfppkpkdtlmisrtpevtcvvvdvshedpevkfnwyvdgvevhnaktkpreeqynstyrvvsvltvlhqdwlngkeykckvsnkalpapiektiskakgqprepqvytlppsreemtknqvsltclvkgfypsdiavewesngqpennykttppvldsdgsfflyskltvdksrwqqgnvfscsvmhealhnhytqkslslspgk
[0482]
p2-2nd-001轻链氨基酸(seq id no:76)
[0483]
eivltqspatlslspgeratmscrasssvsymhwyqqkpgqaprrliydtsklatgiparfsgsgsgtdytltisslepedfavyycqqwsgnpftfgqgtkleikrtvaapsvfifppsdeqlksgtasvvcllnnfypreakvqwkvdnalqsgnsqesvteqdskdstyslsstltlskadyekhkvyacevthqglsspvtksfnrgec
[0484]
实施例12 p2-2
nd-001、sy15-84-231在balb/c-hpd1/htigit小鼠ct26.wt荷瘤模型中的药效学评价
[0485]
选取7~8周龄的雌性balb/c-hpd1/htigit小鼠,收集对数生长期的ct26.wt细胞,接种于小鼠右后肢,接种量为5
×
105/100μl/只。接种后第8天,平均肿瘤体积达到50mm3时,根据肿瘤体积随机分成四组(g1:溶媒10mpk、g2:p2-2
nd-00110mpk、g3:sy15-84-23110mpk、g4:tiragulomab 10mpk),每组6只。分组当天定义为d0天,并于d0天开始给药。溶媒对照组腹腔注射10ml/kg的pbs,p2-2
nd-001、sy15-84-231和tiragulomab组分别腹腔注射10mpk的相应药物,每周给药两次,连续给药三周。每周用电子游标卡尺测量肿瘤的最大直径(d)和最小直径(d),使用以下公式计算肿瘤体积(mm3)=[d
×
d2]/2,并根据公式计算各给药组的肿瘤生长抑制率tgi(%)=(1-给药组相对肿瘤体积/对照组相对肿瘤体积)
×
100%,相对肿瘤体积=检测日的肿瘤体积-给药首日的肿瘤体积,结果如图30、图31所示。
[0486]
p2-2
nd-001和sy15-84-231能够明显抑制肿瘤的生长,p2-2
nd-001组tgi为80.71%;sy15-84-231组的tgi为86.97%;对照抗体tiragulomab组的tgi为64.66%;与溶媒对照组相比,sy15-84-231和p2-2
nd-001组均具有显著的抗肿瘤作用(p《0.05)。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1