孔蛋白单体的突变体、蛋白孔及其应用的制作方法
1.本发明属于靶分析物特性的表征技术领域,特别涉及一种孔蛋白单体的突变体、包含其的蛋白孔以及其检测靶分析物的应用。
背景技术:
2.随着对核酸结构和序列的研究,核酸测序技术不断发展,成为生命科学研究的核心领域,对生物、化学、电学、生命科学、医学等领域的技术发展起到巨大的推动作用。利用纳米孔研究出新型的快速、准确、低成本、高精度及高通量的核酸测序技术是后人类基因组计划的热点之一。
3.纳米孔(nanopore)测序技术,又被称为第四代测序技术,是一种以单链核酸分子作为测序单元,利用一个能够提供离子电流通道的纳米孔,使得单链核酸分子在电泳驱动下通过该纳米孔,当核酸通过纳米孔时,会减少纳米孔的电流,对产生的不同信号实时读取序列信息的基因测序技术。
4.纳米孔测序主要特点是:读长很长,准确率较高,错误区大都发生在均聚寡核苷酸区域。纳米孔测序不但可实现天然dna和rna测序还可直接获取dna和rna的碱基修饰信息,例如它能够直接读取出甲基化的胞嘧啶,而不必像二代测序方法那样需要事先对基因组进行重亚硫酸盐(bisulfite)处理,这对于在基因组水平直接研究表观遗传相关现象有极大推动。纳米孔检测技术作为一个新型平台,具有低成本、高通量、非标记等优势。
5.纳米孔分析技术起源于coulter计数器的发明以及单通道电流的记录技术。生理与医学诺贝尔奖获得者neher和sakamann在1976年利用膜片钳技术测量膜电势,研究膜蛋白及离子通道,推动了纳米孔测序技术的实际应用进程。1996年,kasianowicz等提出了利用α
‑
溶血素对dna测序的新设想,是生物纳米孔单分子测序的里程碑标志。随后,mspa孔蛋白、噬菌体phi29连接器等生物纳米孔的研究报道,丰富了纳米孔分析技术的研究。li等在2001年开启了固态纳米孔研究的新时代。受限于半导体和材料工业的发展,固态纳米孔测序进展缓慢。
6.纳米孔测序技术的关键点之一在于所设计的一种特殊生物纳米孔,孔内缢缩区形成的读取头结构可在当单链核酸(例如ssdna)分子通过纳米孔时,造成孔道电流的阻塞,从而短暂地影响流过纳米孔的电流强度(每种碱基所影响的电流变化幅度是不同的),最后高灵敏度的电子设备检测到这些变化从而鉴定所通过的碱基。目前采用蛋白孔作为纳米孔进行测序,孔蛋白主要以大肠杆菌为来源。
7.目前纳米孔蛋白单一,需要开发替代的纳米孔蛋白实现纳米孔测序技术。孔蛋白也与测序精度密切相关,而且孔蛋白还涉及与控速蛋白的相互作用的模式变化,进一步优化孔蛋白与控速蛋白相互作用界面的稳定性,对提高测序数据的一致性和稳定性有积极影响。纳米孔测序技术的准确率也有待改善,因此,需要开发改进的纳米孔蛋白,以进一步提高纳米孔测序的分辨率。
技术实现要素:
8.为解决上述问题,本发明实施例的目的在于提供一种替代的孔蛋白单体的突变体、包含其的蛋白孔、及其应用。
9.第一方面,本发明实施例提供了一种孔蛋白单体的突变体,其中所述孔蛋白单体的突变体的氨基酸包括seq id no:1所示的序列或与其具有至少99%、98%、97%、96%、95%、90%、80%、70%、60%或50%同一性的序列,或由其组成,并且所述孔蛋白单体的突变体的氨基酸包括在对应seq id no:1的t71、s75、f76中的一个或多个位置处的突变;
10.t71、s75、f76中的一个或多个具体为,t71、s75、f76、t71和s75、s75和f76、t71和s76、或t71和s75和f76。
11.优选地,所述孔蛋白单体的突变体的氨基酸包括在对应seq id no:1的62
‑
175、62
‑
104、68
‑
175、64
‑
79、71
‑
76、或69
‑
76的一个或多个位置处的突变。
12.优选地,所述孔蛋白单体的突变体的氨基酸包括:
13.(1)对应seq id no:1的k69、p70、t71、p72、a73、s74、s75、和f76的一个或多个位置处具有氨基酸的插入、缺失和/或替换;(2)对应seq id no:1的q64、t65、g66、q67、y68、k69、p70、t71、p72、a73、s74、s75、f76、s77、t78、和s79的一个或多个位置处具有氨基酸的插入、缺失和/或替换;(3)对应seq id no:1的r62、d63、y68、k69、t71、s75、f76、和e104的一个或多个位置处具有氨基酸的插入、缺失和/或替换;或者(4)对应seq id no:1的y68、k69、p70、t71、p72、a73、s74、s75、f76、e171和d175的一个或多个位置处具有氨基酸的插入、缺失和/或替换。
14.在一个实施例中,所述孔蛋白单体的突变体的氨基酸突变选自以下:
15.(a)对应seq id no:1的69
‑
76位的氨基酸kptpassf突变为m1m2m3m4m5m6m7m8,其中m1选自r、k、h中的0至3种;m2选自p中的0至1种;m3选自s、g、c、u、t、m、a、v、l、i中的0至10种;m4选自p中的0至1种;m5选自a、g、v、l、i中的0至5种;m6选自s、c、u、t、m中的0至5种;m7选自a、t、g、v、l、i、s、c、u、m中的0至10种;m8选自q、d、e、n、k、h、r中的0至7种;
16.(b)对应seq id no:1的64
‑
79位的氨基酸qtgqykptpassfsts突变为m9m
10
m
11
m
12
m
13
m
14
m
15
m
16
m
17
m
18
m
19
m
20
m
21
m
22
m
23
m
24
,其中m9选自l、g、a、v、i中的0至5种;m
10
选自t、s、c、u、m中的0至5种;m
11
选自g、a、v、l、i中的0至5种;m
12
选自q、d、e、n中的0至4种;m
13
选自y、f、w中的0至3种;m
14
选自r、h、k中的0至3种;m
15
选自p中的0至1种;m
16
选自s、c、u、t、m中的0至5种;m
17
选自p中的0至1种;m
18
选自a、g、v、l、i中的0至5种;m
19
选自s、c、u、t、m中的0至5种;m
20
选自a、g、v、l、i中的0至5种;m
21
选自n、d、e、q、l、g、a、v、i中的0至9种;m
22
选自s、c、u、t、m中的0至5种;m
23
选自t、s、c、u、m中的0至5种;m
24
选自a、g、v、l、i中的0至5种;
17.(c)对应seq id no:1的62位突变为s、c、u、t、m中的0至5种;63位突变为v、g、a、l、i中的0至5种;68位突变为f、w中的0至2种;69位突变为r、h中的0至2种;71位突变为s、c、u、m中的0至4种;75位突变为a、g、v、l、i中的0至5种;76位突变为q、d、e、n中的0至4种;104位突变为v、g、a、l、i中的0至5种;和
18.(d)对应seq id no:1的68
‑
76位的氨基酸ykptpassf突变为m
25
m
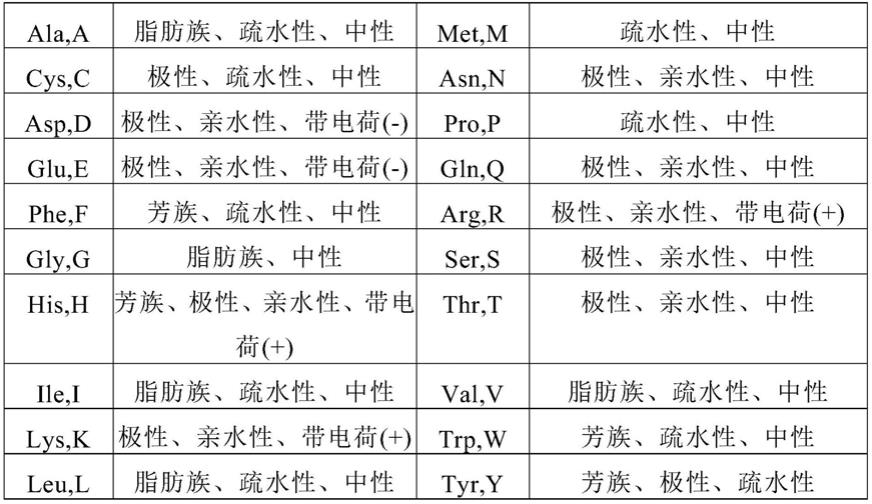
26
m
27
m
28
m
29
m
30
m
31
m
32
m
33
,并且171位突变为n、d、q中的0至3种;175位突变为n、e、q中的0至3种,其中m
25
选自f、y、w中的0至3种;m
26
选自r、h、k中的0至3种;m
27
选自p中的0至1种;m
28
选自s、c、u、t、m中的0至5种;m
29
选自p中的0至1种;m
30
选自a、g、v、l、i中的0至5种;m
31
选自s、c、u、
t、m中的0至5种;m
32
选自a、g、v、l、i中的0至5种;m
33
选自q、d、e、n中的0至4种。
19.在一个实施例中,孔蛋白单体的突变体的氨基酸突变选自以下:
20.(a)对应seq id no:1的69
‑
76位的氨基酸kptpassf突变为m1m2m3m4m5m6m7m8,其中m1选自r、k或h;m2选自p;m3选自s、g、c、u、t、m、a、v、l或i;m4选自p;m5选自a、g、v、l或i;m6选自s、c、u、t或m;m7选自a、t、g、v、l、i、s、c、u或m;m8选自q、d、e、n、k、h或r;
21.(b)对应seq id no:1的64
‑
79位的氨基酸qtgqykptpassfsts突变为m9m
10
m
11
m
12
m
13
m
14
m
15
m
16
m
17
m
18
m
19
m
20
m
21
m
22
m
23
m
24
,其中m9选自l、g、a、v或i;m
10
选自t、s、c、u或m;m
11
选自g、a、v、l或i;m
12
选自q、d、e或n;m
13
选自y、f或w;m
14
选自r、h或k;m
15
选自p;m
16
选自s、c、u、t或m;m
17
选自p;m
18
选自a、g、v、l或i;m
19
选自s、c、u、t或m;m
20
选自a、g、v、l或i;m
21
选自n、d、e、q、l、g、a、v或i;m
22
选自s、c、u、t或m;m
23
选自t、s、c、u或m;m
24
选自a、g、v、l或i;
22.(c)对应seq id no:1的r62突变为r62s、r62c、r62u、r62t或r62m;d63突变为d63v、d63g、d63a、d63l或d63i;y68突变为y68f或y68w;k69突变为k69r或k69h;t71突变为t71s、t71c、t71u或t71m;s75突变为s75a、s75g、s75v、s75l或s75i;f76突变为f76q、f76d、f76e或f76n;e104突变为e104v、e104g、e104a、e104l或e104i;和
23.(d)对应seq id no:1的68
‑
76位的氨基酸ykptpassf突变为m
25
m
26
m
27
m
28
m
29
m
30
m
31
m
32
m
33
,并且e171突变为e171n、e171d或e171q;d175突变为d175n、d175e或d175q,其中m
25
选自f、y或w;m
26
选自r、h或k;m
27
选自p;m
28
选自s、c、u、t或m;m
29
选自p;m
30
选自a、g、v、l或i;m
31
选自s、c、u、t或m;m
32
选自a、g、v、l或i;m
33
选自q、d、e、或n。
24.在一个实施例中,孔蛋白单体的突变体的氨基酸突变选自以下:
25.(a)对应seq id no:1的69
‑
76位的氨基酸kptpassf突变为rpspasaq;
26.(b)对应seq id no:1的69
‑
76位的氨基酸kptpassf突变为kpgpastk;
27.(c)对应seq id no:1的64
‑
79位的氨基酸qtgqykptpassfsts突变为ltgqyrpspasansta;
28.(d)对应seq id no:1的64
‑
79位的氨基酸qtgqykptpassfsts突变为ltgqyrpspasalsta;
29.(e)对应seq id no:1的r62s、d63v、y68f、k69r、t71s、s75a、f76q、和e104v;和
30.(f)对应seq id no:1的68
‑
76位的氨基酸ykptpassf突变为frpspasaq,以及对应seq id no:1的e171n和d175n。
31.第二方面,本发明实施例提供了一种蛋白孔,包括至少一个孔蛋白单体的突变体。
32.第三方面,本发明实施例提供了一种用于表征靶分析物的复合物,其特征在于:所述的蛋白孔及与其结合的控速蛋白。
33.第四方面,本发明实施例提供了编码孔蛋白单体的突变体、蛋白孔、或复合物的核酸。
34.第五方面,本发明实施例提供了包含所述核酸的载体或遗传工程化的宿主细胞。
35.第六方面,本发明实施例提供了孔蛋白单体的突变体、其蛋白孔、复合物、核酸、载体或宿主细胞在检测靶分析物存在、不存在或一个或多个特征或制备检测靶分析物存在、不存在或一个或多个特征的产品中的应用。
36.第七方面,本发明实施例提供了一种产生蛋白孔或其多肽的方法,包括用所述的载体转化所述的宿主细胞,诱导所述宿主细胞表达所述的蛋白孔或其多肽。
37.第八方面,本发明实施例提供了一种用于确定靶分析物存在、不存在或一个或多个特征的方法,包括:
38.a.使靶分析物与蛋白孔、复合物、或复合物中的蛋白孔接触,使得所述靶分析物相对于所述蛋白孔移动;以及
39.b.在所述靶分析物相对于所述蛋白孔移动时获取一个或多个测量值,从而确定所述靶分析物的存在、不存在或一个或多个特征。
40.在一个实施例中,所述方法包括:所述靶分析物与存在于膜中的所述蛋白孔相互作用从而使得所述靶分析物相对所述蛋白孔移动。
41.在一个实施例中,靶分析物是核酸分子。
42.在一个实施例中,用于确定靶分析物存在、不存在或一个或多个特征的方法包括将所述靶分析物偶联到膜上;和所述靶分析物与存在于所述膜中的所述蛋白孔相互作用从而使得所述靶分析物相对所述蛋白孔移动。
43.第九方面,本发明实施例提供了一种用于确定靶分析物存在、不存在或一个或多个特征的试剂盒,包括所述的孔蛋白单体的突变体、所述的蛋白孔、所述的复合物、所述的核酸、或所述的载体或宿主,和所述的膜的组分。
44.第十方面,本发明实施例提供了一种用于确定靶分析物存在、不存在或一个或多个特征的装置,包括所述的蛋白孔或所述复合物,和所述的膜。
45.在一个实施例中,所述靶分析物包括多糖、金属离子、无机盐、聚合物、氨基酸、肽、蛋白、核苷酸、寡核苷酸、多核苷酸、染料、药物、诊断剂、爆炸物或环境污染物;
46.优选地,所述靶分析物包括多核苷酸,
47.更优选地,所述多核苷酸包括dna或rna;和/或,所述一个或多个特征选自(i)所述多核苷酸的长度;(ii)所述多核苷酸的一致性;(iii)所述多核苷酸的序列;(iv)所述多核苷酸的二级结构和(v)所述多核苷酸是否经修饰;和/或,所述复合物中所述控速蛋白包括多核苷酸结合蛋白。
附图说明
48.所描述的附图仅是示意性的而非限制性的。
49.图1示出了根据一个实施例的纳米孔的基本工作原理。
50.图2示出了根据一个实施例的dna测序的示意图。
51.图3示出了根据一个实施例核苷酸穿过蛋白孔时相应的堵孔信号。
52.图4a、4b和4c示出了根据一个实施例的野生型蛋白孔通道表面结构和飘带图模型。图4a为表面结构模型侧视图,图4b为飘带结构模型俯视图,及图4c为飘带结构模型。
53.图5a和图5b示出了根据一个实施例的突变孔1的氨基酸模型图,图5a为顶视图,图5b为侧视图。
54.图6示出了根据一个实施例的突变孔1各部分尺寸信息。
55.图7示出了根据一个实施例的孔蛋白突变体1的单体氨基酸模型图,(b)是(a)放大显示的缢缩区(eye loop)的核心氨基酸组成。
56.图8示出了根据一个实施例的孔蛋白突变体1的负染色电镜结果。
57.图9a示出了根据一个实施例的孔蛋白突变体1的冷冻电镜照片图9b示出了2d分类
结果。
58.图10a和图10b示出了根据一个实施例的孔蛋白突变体1的局部精修傅里叶壳相关系数(fsc)结果,a:rin fsc未屏蔽图;b:rin fsc相位随机屏蔽图;c:rin fsc修正图;d:rin fsc屏蔽图。
59.图11示出了根据一个实施例的孔蛋白突变体1冷冻电镜三维重构分辨率的电子密度图。
60.图12示出了根据一个实施例的孔蛋白突变体1在下的电子密度映射图。
61.图13示出了根据一个实施例的dna构建体bs7
‑
4c3
‑
se1的结构。
62.图14示出了根据一个实施例的dna构建体bs7
‑
4c3
‑
plt的结构。
63.图15a示出了根据一个实施例的突变孔1在
±
180mv电压下开孔电流及其门控特征。
64.图15b示出了根据一个实施例的突变孔1在+180mv电压下的核酸过孔情况。
65.图16a和16b示出了根据一个实施例当解旋酶mph
‑
mp1
‑
e105c/a362c控制dna构建体bs7
‑
4c3
‑
plt穿过突变孔1移位时的示例电流轨迹。
66.图17是图16b实施例单独一条信号的区域放大显示图。
67.图18a示出了根据一个实施例的突变孔2在
±
180mv电压下开孔电流及其门控特征。
68.图18b示出了根据一个实施例的突变孔2在+180mv电压下的核酸过孔情况。
69.图19a和19b示出了根据一个实施例当解旋酶mph
‑
mp1
‑
e105c/a362c控制dna构建体bs7
‑
4c3
‑
plt穿过突变孔2移位时的示例电流轨迹。
70.图20是图19a和b实施例单独一条信号的区域放大显示图。
71.图21a示出了根据一个实施例的突变孔3在
±
180mv电压下开孔电流及其门控特征。
72.图21b示出了根据一个实施例的突变孔3在+180mv电压下的核酸过孔情况。
73.图22a和22b示出了根据一个实施例当解旋酶mph
‑
mp1
‑
e105c/a362c控制dna构建体bs7
‑
4c3
‑
plt穿过突变孔3移位时的示例电流轨迹。
74.图23是图22a实施例单独一条信号的区域放大显示图。
75.图24a示出了根据一个实施例的突变孔4在
±
180mv电压下开孔电流及其门控特征。
76.图24b示出了根据一个实施例的突变孔4在+180mv电压下的核酸过孔情况。
77.图25a和25b示出了了根据一个实施例当解旋酶mph
‑
mp1
‑
e105c/a362c控制dna构建体bs7
‑
4c3
‑
plt穿过突变孔4移位时的示例电流轨迹。
78.图26是图25a和25b实施例单独一条信号的区域放大显示图。
79.图27示出了根据一个实施例的突变孔5在
±
180mv电压下开孔电流及其门控特征。
80.图28示出了根据一个实施例当解旋酶mph
‑
mp1
‑
e105c/a362c控制dna构建体bs7
‑
4c3
‑
plt穿过突变孔5移位时的示例电流轨迹。
81.图29是图28实施例单独一条信号的区域放大显示图。
82.图30a示出了根据一个实施例的突变孔6在
±
180mv电压下开孔电流及其门控特征。
83.图30b示出了根据一个实施例的突变孔6在+180mv电压下的核酸过孔情况。
84.图31a和31b示出了了根据一个实施例当解旋酶mph
‑
mp1
‑
e105c/a362c控制dna构建体bs7
‑
4c3
‑
plt穿过突变孔6移位时的示例电流轨迹。
85.图32是图31a实施例单独一条信号的区域放大显示图。
86.图33示出了根据一个实施例突变体1的sds
‑
page电泳检测结果。
87.图34示出了根据一个实施例突变体1蛋白尺寸排阻色谱图。
具体实施方式
88.应理解,所公开的产品和方法的不用应用可根据所属领域的特定需要来调适。还应理解,本文所用的术语仅出于描述本发明的特定实施例的目的,并且不打算是限制性的。
89.另外除非上下文另外明确规定,否则如本说明书和权利要求书中所使用,单数形式“一”和“所述”包括多个。举例来说,提及“核苷酸”包括两个或更多个核苷酸,提及“一个解旋酶”包括两个或更多解旋酶。
90.如本文所使用的,术语“包括”是指必须包括任何所列举的要素,并且也可以任选地包括其他元素。“由...组成”是指不包括所有未列举的元素。由这些术语中的每一个定义的实施例在本发明的范围内。
91.如本文所用的“核苷酸序列”、“dna序列”或“核酸分子”是指任何长度的核苷酸(核糖核苷酸或脱氧核糖核苷酸)的聚合形式。该术语仅指分子的一级结构。因此,该术语包括双链和单链dna和rna。
92.本文所用的术语“核酸”是指单链或双链共价连接的核苷酸序列,其中每个核苷酸上的3'和5'末端通过磷酸二酯键连接。核苷酸可以由脱氧核糖核苷酸碱基或核糖核苷酸碱基组成。核酸可以包括dna和rna,并可以在体外合成制备或从自然资源中分离。核酸可以进一步包括修饰的dna或rna,例如甲基化的dna或rna,或经过翻译后修饰的rna,例如用7
‑
甲基鸟苷进行的5'
‑
盖帽,3'
‑
端加工,例如裂解和多腺苷化,以及拼接。核酸还可以包括合成核酸(xna),例如己糖醇核酸(hna),环己烯核酸(cena),苏糖核酸(tna),甘油核酸(gna),锁核酸(lna)和肽核酸(pna)。核酸(或多核苷酸)的大小通常用双链多核苷酸的碱基对(bp)数目表示,或在单链多核苷酸的情况下用核苷酸的数目(nt)表示。1千个bp或nt等于一个千碱基对(kb)。长度小于约40个核苷酸的多核苷酸通常称为“寡核苷酸”,并且可以包含用于dna操作(例如通过聚合酶链式反应(pcr))中的引物。
93.多核苷酸,例如核酸,是包含两个或多个核苷酸的大分子。所述多核苷酸或核酸可以包含任意核苷酸的任意组合。所述核苷酸可以是天然存在的或人工合成的。所述多核苷酸中的一个或多个核苷酸可以被氧化或甲基化。所述多核苷酸中的一个或多个核苷酸可以被损伤。例如,所述多核苷酸可以包含嘧啶二聚体。这种二聚体通常与由紫外线造成的损伤有关并且是皮肤黑色素瘤的主要成因。所述多核苷酸中的一个或多个核苷酸可以被修饰,例如用常规的标记或标签。所述多核苷酸可以包含一个或多个无碱基的(即缺少核碱基)、或缺少核碱基和糖(即为c3)的核苷酸。
94.所述多核苷酸中的核苷酸可以任意方式相互连接。所述核苷酸通常通过其糖基和磷酸基团连接,如在核酸中一样。所述核苷酸可以通过其核碱基连接,如在啼啶二聚体中一样。
95.多核苷酸可以是单链或双链的。多核苷酸的至少一部分优选是双链的。多核苷酸可以是核酸,例如脱氧核糖核酸(dna)或核糖核酸(rna)。多核苷酸可以包含一条rna链,所述rna链杂合到一条dna链。多核苷酸可以是任意现有技术已知的合成核酸,例如肽核酸(pna),甘油核酸(gna),苏糖核酸(tna),锁核酸(lna)或具有核苷酸侧链的其他合成聚合物。所述pna骨架是由通过肽键连接的重复的n
‑
(2
‑
氨基乙基)
‑
甘氨酸单元组成。所述gna骨架是由通过磷酸二酯键连接的重复乙二醇单元组成。所述tna骨架是由通过磷酸二酯键连接在一起的重复苏糖基组成。lna由上述核糖核酸形成,具有连接核糖部分中2’氧和4’碳的额外桥连结构。桥连的核酸(bna)是修饰的rna核苷酸。它们也可以称为限制的或不可接近的rna13bna单体可以含有5元,6元或甚至7元桥连结构并带有“固定的”c3
’‑
内糖折叠结构(c3
’‑
endo sugar puckering)。所述桥连结构被合成引入核糖的2’,4’_位,以产生2’,4
’‑
bna单体。
96.多核苷酸最优选核糖核酸(rna)或脱氧核糖核酸(dna)。多核苷酸可以为任意长度。例如,多核苷酸的长度可以是至少10,至少50,至少100,至少150,至少200,至少250,至少300,至少400或至少500个核苷酸或核苷酸对。所述多核苷酸的长度可以为1000个或更多个核苷酸或核苷酸对,5000个或更多个核苷酸或核苷酸对或100000个或更多个核苷酸或核苷酸对。
97.任意数量的多核苷酸可以被研究。例如实施例的方法可以涉及表征2、3、4、5、6、7、8、9、10、20、30、50、100个或更多个多核苷酸。如果两个或更多个多核苷酸被表征,它们可以是不同的多核苷酸或相同多核苷酸的情形。
98.多核苷酸可以是天然存在的或人工合成的。例如,所述方法可用于验证所制备的寡核苷酸的序列。所述方法通常在体外进行。
99.在本公开的上下文中,术语“氨基酸”以其最广义的意义使用,并且意指包括含有胺(nh2)和羧基(cooh)官能团以及每种氨基酸所特有的侧链(例如r基团)的有机化合物。在一些实施方案中,氨基酸是指天然存在的lα
‑
氨基酸或残基。本文使用天然存在的氨基酸的常用单字母和三字母缩写:a=ala;c=cys;d=asp;e=glu;f=phe;g=gly;h=his;i=ile;k=lys;l=leu;m=met;n=asn;p=pro;q=gln;r=arg;s=ser;t=thr;v=val;w=trp;和y=tyr(lehning e r,a.l.,(1 975)biochemis try,第2版,第71
‑
92页,worth publishers,new york)。通用术语“氨基酸”还包括d
‑
氨基酸、逆
‑
反氨基酸以及经化学修饰的氨基酸(诸如氨基酸类似物),通常不并入蛋白质中的天然存在的氨基酸(诸如正亮氨酸)及具有本领域已知是氨基酸特征的性质的化学合成化合物(诸如β
‑
氨基酸)。例如,在氨基酸的定义中包括苯丙氨酸或脯氨酸的类似物或模拟物,这些类似物或模拟物允许如同天然phe或pro一样对肽化合物进行相同的构象限制。此类类似物和模拟物在本文中称为相应氨基酸的“功能等效物”。roberts和vellaccio,the peptides:analysis,synthesis,biology,gross和meiehofer编辑,第5卷第341页,academic press,inc.,n.y.1983列出了氨基酸的其他实例,其通过引用并入本文。
100.术语“蛋白质”、“多肽”和“肽”在本文中进一步可互换使用,是指氨基酸残基的聚合物以及氨基酸残基的变体和合成类似物。因此,这些术语适用于其中一个或多个氨基酸残基是合成的非天然存在的氨基酸,诸如相应天然存在的氨基酸的化学类似物的氨基酸聚合物,以及适用于天然存在的氨基酸聚合物。多肽还可经历成熟或翻译后修饰过程,这些过
程可以包括但不限于:糖基化、蛋白水解裂解、脂化、信号肽裂解、前肽裂解、磷酸化等。
101.蛋白质的“同源物”涵盖相对于所讨论的未修饰的或野生型蛋白质具有氨基酸取代、缺失和/或插入并且具有与它们所来源的未修饰的蛋白质相似的生物和功能活性的肽、寡肽、多肽、蛋白质和酶。如本文所用,术语“氨基酸同一性”是指在比较窗口中,在氨基酸
‑
氨基酸的基础上,序列相同的程度。因此,通过以下方式计算“序列同一性百分比”:在比较窗口中比较两个最佳比对的序列,确定两个序列中出现相同氨基酸残基(例如,ala、pro、ser、thr、gly、val、leu、ile、phe、tyr、trp、lys、arg、his、asp、glu、asn、gln、cys和met)的位置数量以得到匹配位置数量,将匹配位置数量除以比较窗口中的位置总数(即窗口大小),并将结果乘以100得到序列同一性百分比。
102.序列同一性也可以是全长多核苷酸或多肽的片段或部分。因此,序列可与全长参考序列仅有50%的整体序列同一性,但是特定区、结构域或亚基的序列可与参考序列具有80%、90%或高达99%的序列同一性。
103.术语“野生型”是指从天然存在的来源分离的基因或基因产物。野生型基因是在群体中最常观测到的基因,因此任意地设计为该基因的“正常”或“野生型”形式。相反,术语“经修饰的”、“突变”或“变体”是指与野生型基因或基因产物相比,显示出序列修饰(例如,取代、截短或插入)、翻译后修饰和/或功能性质(例如,特性改变)的基因或基因产物。注意,可以分离天然存在的突变体;这些突变体是通过与野生型基因或基因产物相比,它们具有改变的特征这一事实来鉴定的。引入或取代天然存在的氨基酸的方法是本领域众所周知的。例如,可以通过在编码突变的单体的多核苷酸中的相关位置用精氨酸的密码子(cgt)置换蛋氨酸的密码子(atg),用精氨酸(r)取代蛋氨酸(m)。引入或取代非天然存在的氨基酸的方法也是本领域众所周知的。例如,可以通过在用于表达突变的单体的ivtt系统中包括合成的氨酰基
‑
trna来引入非天然存在的氨基酸。可替代地,可以通过在绦虫假单胞菌(pseudomonas taeanensis ms
‑
3)中表达突变的单体来引入非天然存在的氨基酸,绦虫假单胞菌在那些特定氨基酸的合成(即非天然存在的)类似物的存在下对于特定氨基酸而言为营养缺陷型。如果突变的单体是使用部分肽合成法产生的,则它们也可以通过裸连接产生。保守性取代将氨基酸置换为具有相似化学结构、相似化学性质或相似侧链体积的其他氨基酸。引入的氨基酸可以具有与它们所置换的氨基酸相似的极性、亲水性、疏水性、碱性、酸性、中性或电荷。可替代地,保守性取代可以引入另一种芳族或脂肪族氨基酸代替预先存在的芳族或脂肪族氨基酸。保守性氨基酸变化是本领域众所周知的,并且可以根据下表1中定义的20种主要氨基酸的性质进行选择。在氨基酸具有相似极性的情况下,这也可以参考表2中氨基酸侧链的亲水性量表来确定。
104.表1
‑
氨基酸的化学性质
[0105][0106]
表2
‑
亲水性量表
[0107]
侧链亲水性ile,i4.5val,v4.2leu,l3.8phe,f2.8cys,c2.5met,m1.9ala,a1.8gly,g
‑
0.4thr,t
‑
0.7ser,s
‑
0.8trp,w
‑
0.9tyr,y
‑
1.3pro,p
‑
1.6his,h
‑
3.2glu,e
‑
3.5gln,q
‑
3.5asp,d
‑
3.5asn,n
‑
3.5lys,k
‑
3.9arg,r
‑
4.5
[0108]
众所周知,性质相似氨基酸彼此之间保守性替换通常不会影响肽序列的活性,保守性替换如表3。
[0109]
表3保守氨基酸替换
[0110][0111]
突变或经修饰的蛋白质、单体或肽也可以任何方式在任何位点进行化学修饰。突变或经修饰的单体或肽优选通过分子与一个或多个半胱氨酸的附接(半胱氨酸连接),分子与一个或多个赖氨酸的附接,分子与一个或多个非天然氨基酸的附接,表位的酶修饰或末端的修饰来进行化学修饰。进行此类修饰的合适方法是本领域众所周知的。经修饰的蛋白质、单体或肽的突变体可以通过任何分子的附接进行化学修饰。例如,经修饰的蛋白质、单体或肽的突变体可以通过染料或荧光团的附接进行化学修饰。在一些实施方案中,用促进包含单体或肽的孔与靶核苷酸或靶多核苷酸序列之间的相互作用的分子衔接子化学修饰突变或经修饰的单体或肽。分子衔接子优选为环状分子、环糊精、能够杂交的物质、dna结合剂或嵌入剂、肽或肽类似物、合成聚合物、芳族平面分子、带正电荷的小分子或能够氢键键合的小分子。
[0112]
衔接子的存在改善了孔和核苷酸或多核苷酸序列的主
‑
客体化学,从而改善了由突变的单体形成的孔的测序能力。主
‑
客体化学的原理是本领域众所周知的。衔接子对孔的物理或化学性质有影响,这种影响改善了孔与核苷酸或多核苷酸序列的相互作用。衔接子可以改变孔的桶或通道的电荷,或与核苷酸或多核苷酸序列特异性相互作用或结合,从而促进其与孔的相互作用。
[0113]“蛋白孔”是跨膜蛋白结构,其限定了允许分子和离子从膜的一侧易位到另一侧的通道或孔。离子物质通过孔的易位可以由施加到孔任一侧的电位差驱动。“纳米孔”是一种蛋白孔,其中分子或离子所通过的通道的最小直径为纳米级(10
‑9米)。在一些实施方案中,蛋白孔可以是跨膜蛋白孔。蛋白孔的跨膜蛋白结构本质上可以是单体或寡聚体。通常,孔包含多个围绕中心轴排列的多肽亚基,从而形成基本上垂直于纳米孔所驻留的膜延伸的蛋白内衬通道。多肽亚基的数量没有限制。通常,亚基的数量为5至30,合适地亚基的数量为6至10。可替代地,亚基的数量不像在产气荚膜梭菌溶素(perfringolysin)或相关大膜孔的情况下那样定义。纳米孔内形成蛋白内衬通道的蛋白亚基部分通常包含可包括一个或多个跨膜β
‑
桶和/或α
‑
螺旋部分的二级结构基序。
[0114]
在一个实施例中,蛋白孔包含一个或多个孔蛋白单体。每个孔蛋白单体可以来自绦虫假单胞菌。在一个实施例中,蛋白孔包括一个或多个孔蛋白单体的突变体(即一个或多个孔蛋白突变的单体)。
[0115]
在一个实施例中,孔蛋白来自生物界野生型蛋白、野生型同源物、或其突变体。突变体可以成为修饰的孔蛋白或孔蛋白突变体。突变体中的修饰包括但不限于本文公开的任何一种或多种修饰或所述修饰的组合。在一个实施例中,生物界野生型蛋白是来自绦虫假单胞菌的蛋白。
[0116]
在一个实施例中,孔蛋白同源物是指与seq id no:1所示的蛋白具有至少99%、98%、97%、96%、95%、94%、93%、92%、91%、90%、85%、80%、75%、70%、65%、60%、55%、50%的完整序列同一性的多肽。
[0117]
在一个实施例中,孔蛋白同源物是指与seq id no:2所示的蛋白的编码多核苷酸具有至少99%、98%、97%、96%、95%、94%、93%、92%、91%、90%、85%、80%、75%、70%、65%、60%、55%、50%的完整序列同一性的多核苷酸。所述多核苷酸序列可以包含基于遗传密码的简并性而与seq id no:2不同的序列。
[0118]
多核苷酸序列可以采用本领域的标准方法进行衍生和复制。编码野生型孔蛋白的染色体dna可以从产生孔的生物体如绦虫假单胞菌中提取。编码所述孔亚基的基因可以使用包括特异性引物的pcr进行扩增。所述扩增的序列随后可以进行定点突变。定点突变的合适方法是本领域已知的并且包括,例如,组合链式反应。编码实施例的构建的多核苷酸可以采用本领域公知的技术制备,例如在sambrook,j.and russell,d.(2001).molecular cloning a laboratory manual,3rd edition.cold spring harbor laboratory press,cold spring harbor,ny中描述的那些。
[0119]
所得到的多核苷酸序列随后可以被整合到重组可复制载体上,例如克隆载体。所述载体可以用于在相容的宿主细胞中复制所述多核苷酸。因此多核苷酸序列可以通过将多核苷酸引入到可复制载体中,将载体引入相容的宿主细胞中,并在引起载体复制的条件下使宿主细胞生长而进行制备。所述载体可以从所述宿主细胞中回收。
[0120]
纳米孔或蛋白孔的基本工作原理
[0121]
在一个实施例中,在充满电解液的腔100内,带有纳米级小孔的绝缘膜102将腔体分成2个小室,如图1所示,当电压作用于电解液室,离子或其他小分子物质在电场力作用下穿过小孔,形成稳定的可检测的离子电流。掌握纳米孔的尺寸和表面特性、施加的电压及溶液条件,可检测不同类型的生物分子。
[0122]
由于组成dna的四种碱基腺嘌呤(a)、鸟嘌呤(g)、胞嘧啶(c)和胸腺嘧啶(t)的分子结构及体积大小均不同,单链dna(ssdna)在控速酶和电场驱使下通过纳米级的小孔时,不同碱基的化学性质差异导致穿越纳米孔或蛋白孔时引起的电流的变化幅度不同,从而得到所测核酸例如dna的序列信息。
[0123]
图2示出了dna测序的示意图200。如图2所示,在一个典型的纳米孔/蛋白孔测序实验中,纳米孔是磷脂膜两侧离子通过的唯一通道。控速蛋白例如多核苷酸结合蛋白充当核酸分子例如dna的马达蛋白,拉动dna链使其以单个核苷酸的步长依次通过纳米孔/蛋白孔。每当一个核苷酸穿过纳米孔/蛋白孔,相应的堵孔信号会被记录下来(图3)。通过相应算法分析这些序列相关的电流信号,可以反推出核酸分子例如dna的序列信息。
[0124]
在实施例中,孔蛋白通过生物信息学手段和进化角度,从自然界不同物种(主要是细菌和古细菌)进行筛选。在一个实施例中,孔蛋白来自于任何生物体,优选来自于绦虫假单胞菌。通过序列分析,孔蛋白具有完整功能结构域。利用结构生物学手段预测分析孔蛋白3d结构模型,选择具有合适读取头架构形式的通道蛋白。之后利用基因工程、蛋白质工程、蛋白质定向进化和计算机辅助蛋白质设计等手段,对候选通道蛋白(或孔蛋白)进行改造、测试和优化,经过几轮迭代,得到同源蛋白突变体多个,优选六个(不同同源蛋白骨架),有不同的信号特征和信号分布模式。
[0125]
实施例中的孔蛋白可应用于第四代测序技术。在一个实施例中,孔蛋白是纳米孔蛋白。在一个实施例中,孔蛋白可应用于固态孔进行测序。
[0126]
在一个实施例中,采用新的蛋白骨架,形成新的缢缩区(读取头区域)结构,从而在测序过程中提供全新的作用模式。实施例的孔蛋白具有良好的跳边分布和与磷脂膜重组的效率。
[0127]
在一个实施例中,对野生型孔蛋白单体进行基因突变改造形成孔蛋白单体的突变体。在一个实施例中,孔蛋白单体的突变体的氨基酸包括seq id no:1所示的序列或包括与其具有至少99%、98%、97%、96%、95%、94%、93%、92%、91%、90%、85%、80%、75%、70%、65%、60%、55%、或50%同一性的序列,并且所述孔蛋白单体的突变体的氨基酸对应seq id no:1的62
‑
79、104、170和175位的一个或多个位置处具有突变。
[0128]
在一个实施例中,突变包括氨基酸的插入、缺失和/或替换。在一个实施例中,seq id no:1的62
‑
79、104、170和175位的一个或多个位置处具有突变,是seq id no:1的62
‑
79、104、170和175位中的一个或多个位置处具有氨基酸插入、缺失和/或替换。
[0129]
在一个实施例中,所述孔蛋白单体的突变体的氨基酸对应seq id no:1的(1)69
‑
76位、(2)64
‑
79位、(3)62、63、68、69、71、75、76、和104位、或(4)68
‑
76位和171和175位的一个或多个位置处具有突变。
[0130]
在一个实施例中,所述孔蛋白单体的突变体的氨基酸对应seq id no:1的(1)69
‑
76位、(2)64
‑
79位、(3)62、63、68、69、71、75、76、和104位、或(4)68
‑
76位和171和175位的一个或多个位置处具有氨基酸的插入、缺失和/或替换。
[0131]
在一个实施例中,所述孔蛋白单体的突变体的氨基酸仅在对应seq id no:1的69
‑
76位(即k69、p70、t71、p72、a73、s74、s75、f76)具有突变,或在一个或多个位置处具有氨基酸的插入、缺失和/或替换。
[0132]
在一个实施例中,所述孔蛋白单体的突变体的氨基酸仅在对应seq id no:1的64
‑
79位(即q64、t65、g66、q67、y68、k69、p70、t71、p72、a73、s74、s75、f76、s77、t78和s79)具有突变,或在一个或多个位置处具有氨基酸的插入、缺失和/或替换。
[0133]
在一个实施例中,所述孔蛋白单体的突变体的氨基酸仅在对应seq id no:1的r62、d63、y68、k69、t71、s75、f76q、和e104位具有突变,或在一个或多个位置处具有氨基酸的插入、缺失和/或替换。
[0134]
在一个实施例中,所述孔蛋白单体的突变体的氨基酸仅在对应seq id no:1的68
‑
76位(即y68、k69、p70、t71、p72、a73、s74、s75和f76)、e171和d175具有突变,或在一个或多个位置处具有氨基酸的插入、缺失和/或替换。
[0135]
在一个实施例中,对应seq id no:1的位置是指无论是否通过氨基酸插入或缺失
或采用同一性序列从而使得序列编号发生变化时,相对位置不变,依然可采用seq id no:1序列的编号。例如,对应seq id no:1的q64可突变为q64l,即使seq id no:1序列编号变化或采用与seq id no:1具有本文限定的同一性的序列,相对应于seq id no:1的64位的氨基酸q(即使在另一序列中并非为64位)也可突变为l,仍在本发明的保护范围内。
[0136]
在一个实施例中,孔蛋白单体的突变体的氨基酸由seq id no:1所示的序列组成,或由与其具有至少99%、98%、97%、96%、95%、94%、93%、92%、91%、90%、85%、80%、75%或70%、65%、60%、55%、或50%同一性的序列组成,并且所述孔蛋白单体的突变体的氨基酸对应seq id no:1的62
‑
79、104、170和175位的一个或多个位置处具有突变。
[0137]
在一个实施例中,孔蛋白单体的seq id no:1序列来自绦虫假单胞菌。编码seq id no:1氨基酸的核苷酸序列为seq id no:2。
[0138]
在一个实施例中,69
‑
76位的氨基酸kptpassf突变为m1m2m3m4m5m6m7m8,其中m1选自r、k或h;m2选自p;m3选自s、g、c、u、t、m、a、v、l或i;m4选自p;m5选自a、g、v、l或i;m6选自s、c、u、t或m;m7选自a、t、g、v、l、i、s、c、u或m;m8选自q、d、e、n、k、h或r。
[0139]
在一个实施例中,对应seq id no:1的的64
‑
79位的氨基酸qtgqykptpassfsts突变为m9m
10
m
11
m
12
m
13
m
14
m
15
m
16
m
17
m
18
m
19
m
20
m
21
m
22
m
23
m
24
,其中m9选自l、g、a、v或i;m
10
选自t、s、c、u或m;m
11
选自g、a、v、l或i;m
12
选自q、d、e或n;m
13
选自y、f或w;m
14
选自r、h或k;m
15
选自p;m
16
选自s、c、u、t或m;m
17
选自p;m
18
选自a、g、v、l或i;m
19
选自s、c、u、t或m;m
20
选自a、g、v、l或i;m
21
选自n、d、e、q、l、g、a、v或i;m
22
选自s、c、u、t或m;m
23
选自t、s、c、u或m;m
24
选自a、g、v、l或i。
[0140]
在一个实施例中,对应seq id no:1的r62突变为r62s、r62c、r62u、r62t或r62m;d63突变为d63v、d63g、d63a、d63l或d63i;y68突变为y68f或y68w;k69突变为k69r或k69h;t71突变为t71s、t71c、t71u或t71m;s75突变为s75a、s75g、s75v、s75l或s75i;f76突变为f76q、f76d、f76e或f76n;e104突变为e104v、e104g、e104a、e104l或e104i。
[0141]
在一个实施例中,对应seq id no:1的68
‑
76位的氨基酸ykptpassf突变为m
25
m
26
m
27
m
28
m
29
m
30
m
31
m
32
m
33
,并且e171突变为e171n、e171d或e171q;d175突变为d175n、d175e或d175q,其中m
25
选自f、y或w;m
26
选自r、h或k;m
27
选自p;m
28
选自s、c、u、t或m;m
29
选自p;m
30
选自a、g、v、l或i;m
31
选自s、c、u、t或m;m
32
选自a、g、v、l或i;m
33
选自q、d、e、或n。
[0142]
在一个实施例中,孔蛋白单体的突变体,其中氨基酸突变选自以下:
[0143]
(a)对应seq id no:1的69
‑
76位的氨基酸kptpassf突变为rpspasaq;
[0144]
(b)对应seq id no:1的69
‑
76位的氨基酸kptpassf突变为kpgpastk;
[0145]
(c)对应seq id no:1的64
‑
79位的氨基酸qtgqykptpassfsts突变为ltgqyrpspasansta;
[0146]
(d)对应seq id no:1的64
‑
79位的氨基酸qtgqykptpassfsts突变为ltgqyrpspasalsta;
[0147]
(e)对应seq id no:1的r62s、d63v、y68f、k69r、t71s、s75a、f76q、和e104v;和
[0148]
(f)对应seq id no:1的68
‑
76位的氨基酸ykptpassf突变为frpspasaq,以及对应seq id no:1的e171n和d175n。
[0149]
在一个实施例中,所述孔蛋白单体的突变体的氨基酸序列包括seq id no:24、seq id no:26、seq id no:27、seq id no:28、seq id no:29或seq id no:30,或由其组成。
[0150]
在一个实施例中,蛋白孔包括至少一个孔蛋白单体的突变体(或孔蛋白突变的单
体)。在一个实施例中,蛋白孔包括至少两个、三个、四个、五个、六个、七个、八个、九个或十个或更多孔蛋白单体的突变体。在一个实施例中,蛋白孔包括至少两个孔蛋白单体的突变体,所述孔蛋白单体的突变体可以是相同的或不同的。在一个实施例中,蛋白孔包括两个或多个孔蛋白单体的突变体,优选为两个或多个单体的突变体相同。在一个实施例中,蛋白孔的缢缩区孔道直径为0.7nm
‑
2.2nm、0.9nm
‑
1.6nm、1.4
‑
1.6nm或
[0151]
孔蛋白单体的突变体或包括其的蛋白孔用于检测靶分析物存在、不存在或一个或多个特征中的应用。在一个实施例中,孔蛋白单体的突变体或蛋白孔用于检测核酸分子的序列,或表征多核苷酸序列,例如测序多核苷酸序列,因为它们可以高灵敏度区分不同的核苷酸。孔蛋白单体的突变体或包括其的蛋白孔可以区分dna和rna中的四种核苷酸,甚至可以区分甲基化和未甲基化的核苷酸,并且分辨率出人预料的高。孔蛋白单体的突变体或蛋白孔显示对全部四种dna/rna核苷酸的几乎完全分离。基于在蛋白孔中的停留时间和流过蛋白孔的电流,进一步区分脱氧胞嘧啶单磷酸(dcmp)和甲基
‑
dcmp。
[0152]
孔蛋白单体的突变体或蛋白孔还可以在一系列条件下区分不同核苷酸。特别地,所述孔蛋白单体的突变体或蛋白孔在有利于核酸表征如测序的条件下区分核苷酸。通过改变施加的电势,盐浓度,缓冲液,温度和添加剂如脲,甜菜碱和dtt的存在,可以控制孔蛋白单体的突变体或蛋白孔区分不同核苷酸的程度。这允许孔蛋白单体的突变体或蛋白孔的功能被精细调控,特别是在测序时。孔蛋白单体的突变体或蛋白孔也可以用于通过与一种或多种单体的相互作用而不是在以核苷酸为基础的核苷酸上,来鉴定多核苷酸聚合物。
[0153]
孔蛋白单体的突变体或蛋白孔可以是分离的,基本上分离的,纯化的或基本纯化的。如果完全不含任何其它组分,例如脂质体或其它蛋白孔/孔蛋白,则实施例的孔蛋白单体的突变体或蛋白孔被分离或纯化。如果孔蛋白单体的突变体或蛋白孔与不会干扰其预期用途的载体或稀释剂混合,则该孔蛋白单体的突变体或蛋白孔基本上被分离。例如,如果孔蛋白单体的突变体或蛋白孔以包含小于10%,小于5%,小于2%或小于1%的其它组分如三嵌段共聚物,脂质体或其它蛋白孔/孔蛋白的形式存在,则所述孔蛋白单体的突变体或蛋白孔基本上被分离或基本上被纯化。替代地,孔蛋白单体的突变体或蛋白孔可以存在于膜中。
[0154]
例如,膜优选为两亲层。两亲层是由两亲分子形成的层,例如,磷脂,其具有亲水性和亲油性。两亲分子可以是合成的或天然存在的。两亲层可以是单层或双层。两亲层通常是平面的。两亲层可以是弯曲的。可以对两亲层进行支撑。膜可以为脂质双层。脂质双层是由脂质的两个相对的层形成的。脂质的两层被排列为使得它们的疏水性尾部基团面向彼此以形成疏水性内部。脂质的亲水性头部基团面向外朝向该双层的每一侧上的含水环境。膜包括固态层。固态层可以由有机和无机材料形成。如果膜包括固态层,则孔通常存在于两亲膜中或固态层内包括的层中,例如,固态层内的孔洞、阱、间隙、通道、沟槽或狭缝中。
[0155]
分析物的表征
[0156]
实施例提供一种确定靶分析物的存在、不存在或一种或多种特性的方法。该方法涉及将所述靶分析物与孔蛋白单体的突变体或蛋白孔接触,使得所述靶分析物相对于,例如穿过,所述孔蛋白单体的突变体或蛋白孔移动,并且当所述靶分析物相对于所述孔蛋白单体的突变体或蛋白孔移动时获取一个或多个测量值,从而确定所述靶分析物的存在、不存在或一种或多种特性。所述靶分析物也可以被称为模板分析物或感兴趣的分析物。
[0157]
靶分析物优选为多糖、金属离子,无机盐,聚合物,氨基酸,肽,多肽,蛋白,核苷酸,
寡核苷酸,多核苷酸,染料,药物,诊断剂,爆炸物或环境污染物。所述方法可以涉及确定两种或更多种相同类别的靶分析物的存在、不存在或一种或多种特性,例如,两种以上蛋白,两种以上核苷酸或两种以上药物。或者,所述方法可以涉及确定两种或更多种不同类别的靶分析物的存在、不存在或一种或多种特性,例如,一种或多种蛋白,一种或多种核苷酸和一种或多种药物。
[0158]
所述方法包括将所述靶分析物与孔蛋白单体的突变体或蛋白孔接触,使得所述靶分析物移动穿过所述孔蛋白单体的突变体或蛋白孔。所述蛋白孔一般包含至少1个,至少2个,至少3个,至少4个,至少5个,至少6个,至少7,至少8,至少9或至少10个孔蛋白突变的单体,例如,7,8,9或10个单体。所述蛋白孔包括相同的单体或不同的孔蛋白单体,优选包含8或9个相同的单体。所述单体中的一个或多个,例如2、3、4、5、6、7、8、9或10个,优选如上述讨论的被化学修饰。在一个实施例中,每个单体的氨基酸包括seq id no:1及其上述突变体。在一个实施例中,每个单体的氨基酸由seq id no:1及其上述突变体组成。
[0159]
实施例的方法可以测量多核苷酸的两个、三个、四个或五个或更多个特征。所述一个或多个特征优选选自(i)多核苷酸的长度,(ii)多核苷酸的身份,(iii)多核苷酸的序列,(iv)多核苷酸的二级结构,以及(v)多核苷酸是否被修饰。在一个实施例中,可以测量(i)至(v)的任意组合。
[0160]
对于(i),可以例如通过确定多核苷酸和蛋白单体的突变体/蛋白孔之间相互作用的数量或多核苷酸和蛋白单体的突变体/蛋白孔之间相互作用的持续时间对多核苷酸的长度进行测量。
[0161]
对于(ii),可以以多种方式测量多核苷酸的身份,多核苷酸的身份可以结合多核苷酸序列的测量或不结合多核苷酸序列的测量进行测量。前者较为简单;对多核苷酸进行测序进而进行识别。后者可以通过几种不同方式完成。例如,可以测量多核苷酸中特定基序的存在(无需测量多核苷酸的其余序列)。或者,所述方法中特定的电和/或光信号的测量可以识别出所述多核苷酸来自特定来源。
[0162]
对于(iii),多核苷酸的序列可以如先前所述进行测定。合适的测序方法,特别是使用电学测量方法的测序方法,描述在stoddart d et al.,proc natl acad sci,12;106(19)7702
‑
7,lieberman kr et al,j am chem soc.2010;132(50)17961
‑
72,以及国际申请w02000/28312中。
[0163]
对于(iv),二级结构可以采用多种方法测量。例如,如果所述方法涉及电学测量方法,则可以使用停留时间的变化或流过孔的电流的变化来测量所述二级结构。这允许区分单链和双链多核苷酸的区域。
[0164]
对于(v),可以测量是否存在任何修饰。所述方法优选包括,测定多核苷酸是否通过甲基化,氧化,损伤,用一种或多种蛋白或用一种或多种标记,标签或进行无碱基或缺少核碱基和糖的修饰。特定的修饰将导致与所述孔的特异性相互作用,其可以使用下述方法进行测量。例如,甲基胞嘧啶可以基于其与每个核苷酸相互作用期间流过所述孔的电流而与胞嘧啶区分开来。
[0165]
所述靶多核苷酸与蛋白单体的突变体/蛋白孔接触,例如如实施例的蛋白单体的突变体/蛋白孔。所述蛋白单体的突变体/蛋白孔通常存在于膜中。合适的膜如前文所述。所述方法可以使用适合于研究膜/蛋白孔或孔蛋白单体的突变体系统—其中蛋白单体的突变
体/蛋白孔存在于膜中的任何装置进行。所述方法可以使用适合用于跨膜孔感侧的任何装置进行。例如,所述装置包括包含水性溶液的腔室和将腔室分成两个部分的屏障。所述屏障通常具有孔洞,在孔洞中形成包含孔的膜。或者所述屏障形成膜,所述膜中存在蛋白单体的突变体/蛋白孔。该方法可以使用描述于国际申请号pct/gb08/000562(wo 2008/102120)中的装置进行。
[0166]
可以进行各种不同类型的测量。这包括但不限于电学测量和光学测量。电学测量包括电压测量、电容测量、电流测量,阻抗测量,隧道测量(tunnelling measurement)(ivanov ap et al.,nano lett.2011jan 12;11(i):279
‑
85)以及fet测量(国际申请to 2005/124888)。光学测量可以与电学测量结合(soni gv et al.,rev sci instrum.2010jan;81(1)014301)。所述测量可以是跨膜电流测量,例如流过所述孔的离子电流的测量。在一个实施例中,电学测量或光学测量可采用常规的电学或光学测量。
[0167]
电学测量可以使用描述在stoddart d et al
·
,proc natl acad sci,12;106(19)7702
‑
7,lieberman kr et al,j am chem soc.2010;132(50)17961
‑
72和国际申请wo 2000/28312中的标准单通道记录设备进行。替代地,电学测量可以使用多通道系统进行,例如如国际申请w02009/077734和国际申请wo 2011/067559中描述的。
[0168]
所述方法优选采用跨膜施加的电势进行。所述施加的电势可以是电压电势。替代地,所施加的电势可以是化学电势。其一实例为采用跨膜,例如双亲性分子层的盐梯度进行。盐梯度被公开在holden et al.,j am chem soc.2007jul 11;129(27):8650
‑
5中。在一些情况下,多核苷酸相对所述蛋白单体的突变体/蛋白孔移动时流过所述蛋白单体的突变体/蛋白孔的电流用于估算或确定所述多核苷酸的序列。这就是链测序。
[0169]
所述方法可以包括测量多核苷酸相对所述孔移动时流过所述孔的电流。因此用于所述方法的设备也可以包括能够施加电势并测量穿过膜和孔的电信号的电路。所述方法可以采用膜片钳或电压钳进行。
[0170]
可以包括测量多核苷酸相对所述孔移动时流过所述孔的电流。测量通过跨膜蛋白孔的离子流的合适条件是本领域已知的并且在实施例中公开。所述方法通常通过施加在所述膜和所述孔上的电压进行。所使用的电压通常为从+5v至
‑
5v,例如从从+4v至
‑
4v,从+3v至
‑
3v或从+2v至
‑
2v。所使用的电压通常为从
‑
600mv至+600v或
‑
400mv至+400mv。所使用的电压优选在具有选自
‑
400mv,
‑
300mv,
‑
200mv,
‑
150mv,
‑
100mv,
‑
50mv,
‑
20mv和0mv的下限和独立地选自+10mv,+20mv,+50mv,+100mv,+150mv,+200mv,+300na^p+400mv的上限的范围内。所使用的电压更优选在100mv至240mv的范围内并且最优选在120mv至220mv的范围内。通过使用增加的施加电势,可以增加孔对不同核苷酸的识别。
[0171]
所述方法通常在存在任何电荷载体的情况下进行,例如金属盐例如碱金属盐,卤化物盐例如氯化物盐,例如碱金属氯化物盐。电荷载体可以包括离子液体或有机盐,例如四甲基氯化铵,三甲基苯基氯化铵,苯基三甲基氯化铵或1
‑
乙基
‑3‑
甲基咪唑鑰氯化物。在上述示例性装置中,盐存在于所述腔室中的水性溶液中。通常使用氯化钾(kcl),氯化钠(nacl),氯化铯(cscl)或亚铁氰化钾和铁氰化钾的混合物。kcl,nacl和亚铁氰化钾和铁氰化钾的混合物是优选的。电荷载体在所述膜上可以是不对称的。例如,电荷载体的类型和/或浓度可以在所述膜的每一侧上不同。
[0172]
所述盐的浓度可以是饱和的。所述盐的浓度可以为3m或更低,并且通常为0.1至
2.5m,0.3至1.9m,0.5至1.8m,0.7至1.7m,0.9至1.6m或1m至1.4m。所述盐的浓度优选为150mm至1m。所述方法优选使用至少0.3m,例如至少0.4m,至少0.5m,至少0.6m,至少0.8m,至少1.0m,至少1.5m,至少2.0m,至少2.5m或至少3.0m的盐浓度进行。高盐浓度提供高的信噪比,并允许通过电流指示在正常电流波动背景下待识别的核苷酸的存在。
[0173]
所述方法通常在存在缓冲液的情况下进行。在上述示例性装置中,所述缓冲液存在于所述腔室中的水性溶液中。任意缓冲液可以用于本发明的方法。通常地,所述缓冲液为磷酸缓冲液。其他合适的缓冲液为hepes或tris
‑
hcl缓冲液。所述方法通常在ph为4.0至12.0、4.5至10.0、5.0至9.0、5.5至8.8、6.0至8.7、7.0至8.8、或7.5至8.5下进行。使用的ph值优选约7.5。
[0174]
所述方法可以在0℃至100℃,15℃至95℃,16℃至90℃,17℃至85℃,18℃至80℃,19℃至70℃或20℃至60℃温度下进行。所述方法通常在室温下进行。所述方法任选的在支持酶功能的温度下进行,例如约37℃。
[0175]
在一个实施例中,用于确定靶分析物(例如多核苷酸)存在、不存在或一个或多个特征的方法包括将所述靶分析物偶联到膜上;和所述靶分析物与存在于所述膜中的所述蛋白孔相互作用(例如接触)从而使得所述靶分析物相对所述蛋白孔移动(例如穿过所述蛋白孔)。在一个实施例中,测量所述靶分析物相对于所述蛋白孔移动时通过所述蛋白孔的电流,从而确定所述靶分析物的存在、不存在或一个或多个特征(例如为多核苷酸的序列)。
[0176]
多核苷酸结合蛋白
[0177]
实施例的表征方法优选包括使多核苷酸与多核苷酸结合蛋白接触,使得所述蛋白控制多核苷酸相对于蛋白单体的突变体/蛋白孔的移动,例如,通过所述蛋白单体的突变体/蛋白孔。
[0178]
更优选地,所述方法包括(a)使多核苷酸与蛋白单体的突变体/蛋白孔和多核苷酸结合蛋白接触,使得所述蛋白控制多核苷酸相对于蛋白单体的突变体/蛋白孔的移动,例如,通过蛋白单体的突变体/蛋白孔,和(b)当多核苷酸相对于蛋白单体的突变体/蛋白孔移动时获取一个或多个测量值,其中,所述测量值指示多核苷酸的一个或多个特征,从而表征多核苷酸。
[0179]
更优选地,所述方法包括(a)使多核苷酸与蛋白单体的突变体/蛋白孔和多核苷酸结合蛋白接触,使得所述蛋白控制多核苷酸相对于蛋白单体的突变体/蛋白孔的移动,例如,通过蛋白单体的突变体/蛋白孔,和(b)当多核苷酸相对于蛋白单体的突变体/蛋白孔移动时测量通过蛋白单体的突变体/蛋白孔的电流,其中,所述电流指示多核苷酸的一个或多个特征,从而表征多核苷酸。
[0180]
多核苷酸结合蛋白可以是能够结合多核苷酸并控制其移动通过孔的任何蛋白。多核苷酸结合蛋白通常与多核苷酸相互作用并改性多核苷酸的至少一种性质。蛋白可以通过裂解多核苷酸以形成各单个核苷酸或核苷酸的短链(例如,二核苷酸或三核苷酸)来对其进行改性。蛋白可以通过使多核苷酸定向或将其移动到特定位置来对其进行改性,即,控制它的移动。
[0181]
多核苷酸结合蛋白优选衍生自多核苷酸处理酶。多核苷酸处理酶是能够与多核苷酸相互作用并改性多核苷酸的至少一种性质的多肽。所述酶可以通过裂解多核苷酸以形成各单个核苷酸或核苷酸的短链(例如,二核苷酸或三核苷酸)来对其进行改性。所述酶可以
通过使多核苷酸定向或将其移动到特定位置来对其进行改性。多核苷酸处理酶不需要显示酶活性,只要其能够结合多核苷酸并控制其通过孔的移动即可。例如,可以对所述酶进行改性以去除其酶活性,或者可以在防止其用作酶的条件下进行使用。
[0182]
多核苷酸处理酶优选为聚合酶、外切核酸酶、解旋酶和拓扑异构酶,例如,促旋酶。在一个实施例中,所述酶优选为解旋酶,例如hel308mbu、hel308csy、hel308tga、hel308mhu、tral eco、xpd mbu、dda或其变体。实施例中可以使用任何解旋酶。
[0183]
在一个实施例中,可以使用任何数量的解旋酶。例如,可以使用i,2,3,4,5,6,7,8,9,10或更多个解旋酶。在一些实施例中,可以使用不同数目的解旋酶。
[0184]
实施例的方法优选包括使多核苷酸与两个或更多个解旋酶接触。所述两个或更多个解旋酶通常是相同的解旋酶。所述两个或更多个解旋酶可以是不同的解旋酶。
[0185]
所述两个或更多个解旋酶可以是上述解旋酶的任意组合。所述两个或更多个解旋酶可以是两个或更多个dda解旋酶。所述两个或更多个解旋酶可以是一种或多种dda解旋酶和一种或多种trwc解旋酶。所述两个或更多个解旋酶可以是相同解旋酶的不同变体。
[0186]
所述两个或更多个解旋酶优选地彼此连接。所述两个或更多个解旋酶更优选地彼此共价连接。解旋酶可以以任何顺序并使用任何方法连接。
[0187]
试剂盒
[0188]
本发明还提供一种用于表征靶分析物(例如靶多核苷酸)的试剂盒。试剂盒包含实施例的孔和膜的组分。膜优选地由组分形成。孔优选地存在于膜中。试剂盒可包含上文所公开的任一个膜(如两亲层或三嵌段共聚物膜)的组分。试剂盒可进一步包含多核苷酸结合蛋白。可使用上文所论述的任一个多核苷酸结合蛋白。
[0189]
在一个实施例中,膜为两亲层、固态层、或脂双层。
[0190]
试剂盒可进一步包含用于使多核苷酸与膜偶联的一或多个锚。
[0191]
试剂盒优选地是用于表征双链多核苷酸,并优选地包含y衔接子和发夹环衔接子。
[0192]
y衔接子优选地具有所连接的一或多个解螺旋酶,且发夹环衔接子优选地具有所连接的一或多个分子制动器。y衔接子优选地包含用于使多核苷酸与膜偶联的一或多个第一锚,发夹环衔接子优选地包含用于使多核苷酸与膜偶联的一或多个第二锚,且发夹环衔接子与膜偶联的强度优选地大于y衔接子与膜偶联的强度。
[0193]
试剂盒可另外包含使得能够进行上文提到的任一个实施例的一或多个其它试剂或仪器。此类试剂或仪器包括以下中的一或多个:合适缓冲液(水性溶液)、从个体获得样本的装置(如包含针的容器或仪器)、用于扩增和/或表达多核苷酸的装置,或电压或贴片钳设备。试剂可以干态形式存在于试剂盒中,使得流体样本再悬浮试剂。试剂盒还可任选地包含使得能够用本发明的方法使用试剂盒的说明书或关于何种生物体可使用所述方法的详情。
[0194]
设备(或装置)
[0195]
本发明还提供了一种用于表征靶分析物(例如,靶多核苷酸)的设备。所述设备包括单个或多个蛋白单体的突变体/蛋白孔、和单个或多个膜。所述蛋白单体的突变体/蛋白孔优选存在于所述膜中。孔和膜的数量优选相等。优选地,每个膜中存在单个孔。
[0196]
所述设备优选地还包括用于实施实施例中方法的指令。所述设备可以是任一用于分析物分析的常规设备,例如,阵列或芯片。结合实施例的所述方法所讨论的任一实施例同样适用于所述设备。所述设备还可以包括本述试剂盒中存在的任何特征。用于实施例的设
备具体可为齐碳科技基因测序仪qnome
‑
9604。
[0197]
上述提及的现有技术以全文引用的方式并入本文。
[0198]
以下实施例用以阐述本发明,但不具有限制作用。
[0199]
实施例1
[0200]
在实施例中,野生型孔蛋白来自绦虫假单胞菌,并且该野生型孔蛋白的氨基酸序列是seq id no:1,编码此氨基酸序列的核苷酸序列由seq id no:2所示。孔蛋白单体的突变体1是野生型孔蛋白在对应seq id no:1的69
‑
76位处具有突变,具体为69
‑
76位的kptpassf替换为rpspasaq。包括孔蛋白单体的突变体1的蛋白孔为突变孔1。蛋白单体的突变体1的氨基酸序列如seq id no:24所示,核酸序列如seq id no:25所示。
[0201]
实施例2
[0202]
在实施例中,野生型孔蛋白来自绦虫假单胞菌,并且该野生型孔蛋白的氨基酸序列是seq id no:1,编码此氨基酸的序列的核苷酸序列由seq id no:2所示。孔蛋白单体的突变体2是野生型孔蛋白在对应seq id no:1的69
‑
76位处具有突变,具体为69
‑
76位的kptpassf被替换为kpgpastk。包括孔蛋白单体的突变体2的蛋白孔为突变孔2。蛋白单体的突变体2的氨基酸序列如seq id no:26所示。
[0203]
实施例3
[0204]
在实施例中,野生型孔蛋白来自绦虫假单胞菌,并且该野生型孔蛋白的氨基酸序列是seq id no:1,编码此氨基酸的序列的核苷酸序列由seq id no:2所示。孔蛋白单体的突变体3是野生型孔蛋白在对应seq id no:1的64
‑
79位处具有突变,具体为64
‑
79位的qtgqykptpassfsts替换为ltgqyrpspasansta。包括孔蛋白单体的突变体3的蛋白孔为突变孔3。蛋白单体的突变体3的氨基酸序列如seq id no:27所示。
[0205]
实施例4
[0206]
在实施例中,野生型孔蛋白来自绦虫假单胞菌,并且该野生型孔蛋白的氨基酸序列是seq id no:1,编码此氨基酸的序列的核苷酸序列由seq id no:2所示。孔蛋白单体的突变体4是野生型孔蛋白在对应seq id no:1的64
‑
79位处具有突变,具体为64
‑
79位的qtgqykptpassfsts替换为ltgqyrpspasalsta。包括孔蛋白单体的突变体4的蛋白孔为突变孔4。蛋白单体的突变体4的氨基酸序列如seq id no:28所示。
[0207]
实施例5
[0208]
在实施例中,野生型孔蛋白来自绦虫假单胞菌,并且该野生型孔蛋白的氨基酸序列是seq id no:1,编码此氨基酸的序列的核苷酸序列由seq id no:2所示。孔蛋白单体的突变体5是野生型孔蛋白在对应seq id no:1的以下位置突变:r62s、d63v、y68f、k69r、t71s、s75a、f76q、和e104v。包括孔蛋白单体的突变体5的蛋白孔为突变孔5。蛋白单体的突变体5的氨基酸序列如seq id no:29所示。
[0209]
实施例6
[0210]
在实施例中,野生型孔蛋白来自绦虫假单胞菌,并且该野生型孔蛋白的氨基酸序列是seq id no:1,编码此氨基酸的序列的核苷酸序列由seq id no:2所示。孔蛋白单体的突变体6是野生型孔蛋白在对应seq id no:1的68
‑
76、171和175位处具有突变,具体为68
‑
76位的ykptpassf替换为frpspasaq、171位的e替换为n和175位的d替换为n。包括孔蛋白单体的突变体6的蛋白孔为突变孔6。蛋白单体的突变体6的氨基酸序列如seq id no:30所示。
[0211]
实施例7
[0212]
采用swiss model对野生型孔蛋白进行同源建模,野生型孔蛋白单体的氨基酸由seq id no:1所示。图4a是预测蛋白结构模型的侧视图400,其中颜色较深的部分显示的为一个蛋白单体402。图4b是飘带结构模型俯视图404,其中颜色较深的部分显示的为一个蛋白单体406。图4c为飘带结构模型图408,颜色较深部分为蛋白单体410。
[0213]
采用swiss model对突变孔1进行同源建模。图5a和图5b显示的是突变孔1的氨基酸模型图,其中加号“+”表示水分子。
[0214]
图6显示了孔蛋白单体的突变体1的各部分尺寸,两个孔蛋白单体的突变体(即两个突变的孔蛋白单体)602和604中间的缢缩区孔道直径最大为其次为最小直径为两个突变的孔蛋白单体头尾相距分别为和突变的孔蛋白单体全长单体全长突变的孔蛋白单体头距缢缩区孔道高为缢缩区孔道部分高度如图6所示为和
[0215]
图7显示了孔蛋白的突变体1的单体氨基酸模型,放大显示的是缢缩区结构的氨基酸组成,即gln76、ser74和ser71。
[0216]
实施例8
[0217]
孔蛋白的突变体1的负染色电镜结果如图8所示,由负染色em结果可见:突变体1颗粒均匀,聚集少,可见很多明显正确的蛋白颗粒。
[0218]
孔蛋白的突变体1的冷冻电镜照片和2d分类结果如图9a和9b所示,其中2d结果只展示了较好分类部分。
[0219]
图10a和10b显示了局部精修傅里叶壳层相关系数(fsc)结果,可见,孔蛋白的突变体1不同区域分辨率结果及其最终冷冻电镜单颗粒重构分辨率为重构分辨率是基于黄金标准fsc 0.143标准和高分辨率噪音替代确定的。图11显示了孔蛋白的突变体1冷冻电镜三维重构分辨率的电子密度图。图12显示了孔蛋白的突变体1在下的电子密度映射图。映射图显示了通道eye
‑
loop区域,并且被覆盖在最终细化的模型上。
[0220]
孔蛋白的突变体1的冷冻电镜数据如表4所示。
[0221]
表4孔蛋白的突变体1的冷冻电镜数据
[0222]
[0223][0224]
实施例9
‑
制备dna构建体
[0225]
制备两个dna构建体,分别为bs7
‑
4c3
‑
se1和bs7
‑
4c3
‑
plt。bs7
‑
4c3
‑
se1的结构如图13所示,序列信息如下所示:
[0226]
a:30*c3
[0227]
b:5
’‑
ttttt ttttt
‑3’
(即seq id no:3)
[0228]
c:控速蛋白
[0229]
d:4*c18
[0230]
e:5
’‑
aatgt acttc gttca gttac gtatt gct
‑3’
(即seq id no:4)
[0231]
f:5’p
‑
gc aatac gtaac tgaac gaagt
‑3’
(即seq id no:5)
[0232]
g:胆固醇标签
[0233]
h:5
’‑‑3’
(即seq id no:6)
[0234]
i:5
’‑
aaaaa aaaaa aaaaa aaaaa aaaaa aaaaa aaaaa aaaaa aagca atacg taact gaacg aagta catta aaaaa aaaaa aaaaa aaaa
‑3’
(即seq id no:7)
[0235]
j:5
’‑
atcct ttttt ttttt ttttt tttt
‑3’
(即seq id no:8)
[0236]
k:5
’‑
aatgt acttc gttca gttac gtatt gcttt ttttt ttttt ttttt ttt
‑3’
(即seq id no:9)
[0237]
l:dspacer
[0238]
m:5
’‑
ttttt ttttt ttttt ttttt
‑3’
(即seq id no:10)
[0239]
bs7
‑
4c3
‑
plt的结构如图14所示,序列信息如下所示:
[0240]
a:30*c3
[0241]
b:5
’‑
ttttt ttttt
‑3’
(即seq id no:11)
[0242]
c:控速蛋白
[0243]
d:4*c18
[0244]
e:5
’‑
aatgt acttc gttca gttac gtatt gct
‑3’
(即seq id no:12)
[0245]
f:5’p
‑
gc aatac gtaac tgaac gaagt tcactatcgcattctcatga
‑3’
(即seq id no:13)
[0246]
g:胆固醇标签
[0247]
h:5'
‑
tcatg agaat gcgat agtga
‑3’
(即seq id no:14)
[0248]
i:5
’‑
aaaaaaaaaaaaaaaaaaaaaaaaaaaa(即seq id no:15)/dspacer/aaaaaaaaaaaa(即seq id no:16)/dspacer/aaaaaaaaaaaaaatctctgaatctctgaatctctgaatctctaaaaaaaaaaaagaaaaaaaaaaaacaaaaaaaaaaaataaaaaaaaaaaaagcaatacgtaactgaacgaagtacattaaaaaaaaaa(即seq id no:17)
‑3’
[0249]
j:5
’‑
atccttttttttttaatgtacttcgttcagttacgtattgct
‑3’
(即seq id no:18)
[0250]
k:5’p
‑
ttttttttttttattttttttttttgttttttttttttcttttttttttttagagattcagagattcagagattcagagatttttttttttttt(即seq id no:19)/dspacer/tttttttttttt(即seq id no:20)/ispc3/tttttttttttttttttttttttttttt(即seq id no:21)
‑3’
[0251]
c3、c18、dspacer及ispc3是指示孔测序分辨率特征而引入的标记(marker)序列。
[0252]
在本实施例中,图13和图14中的c控速蛋白为解旋酶mph
‑
mp1
‑
e105c/a362c(具有突变e105c/a362c),氨基酸序列为seq id no:22,核酸序列为seq id no:23。
[0253]
实施例10
[0254]
突变孔1作为蛋白孔,采用单孔测序的技术方法进行检测。在将氨基酸序列为突变体1的单个孔蛋白插入磷脂双分子层之后,使缓冲液(625mm kcl,10mm hepes ph 8.0,50mm mgcl2)流经该系统,以除去任何过量的突变体1纳米孔。将dna构建体bs7
‑
4c3
‑
se1(数据未显示)或bs7
‑
4c3
‑
plt(1~2nm终浓度)加入所述突变体1纳米孔实验系统中,混匀后,使缓冲液(625mm kcl,10mm hepes ph 8.0,50mm mgcl2)流经该系统,以除去任何过量的dna构建体bs7
‑
4c3
‑
se1或bs7
‑
4c3
‑
plt。然后将解旋酶(mph
‑
mp1
‑
e105c/a362c,15nm终浓度)、燃料(atp 3mm终浓度)预混物加入所述单个突变体1纳米孔实验系统中,并在+180mv电压下监测突变体1孔蛋白的测序情况。
[0255]
突变孔1在
±
180mv电压下开孔。图15a显示突变孔1在
±
180mv电压下开孔电流及其门控特征。图15b显示突变孔1在+180mv电压下的单链核酸过孔情况。核酸可以过孔。加入单链核酸后,向下的线显示的核酸过孔信号。
[0256]
采用单孔测序技术方法,通过突变孔1对dna构建体bs7
‑
4c3
‑
plt进行测序,完成嵌孔后添加测序体系出现的核酸测序信号。图16a和16b示出了当解旋酶mph
‑
mp1
‑
e105c/a362c控制dna构建体bs7
‑
4c3
‑
plt穿过突变孔1移位时的示例电流轨迹。根据该信号特征,突变孔1可以用来核酸测序。
[0257]
图17是将图16b的部分显示出电流轨迹的放大结果。具有虚线框和箭头的图(中间图)为原始信号滤波处理后的结果(两条轨迹的y轴坐标=电流(pa),x轴坐标=时间(s))。虚线箭头指示部分显示了电流轨迹的放大结果。此单独一条信号的区域放大显示图,进一步证明突变孔1可以用来核酸测序。
[0258]
实施例11
[0259]
与实施例10类似,实施例11采用突变孔2进行空测和过孔检测。
[0260]
图18a显示突变孔2在
±
180mv电压下开孔电流及其门控特征。图18b显示突变孔2在+180mv电压下的单链核酸过孔情况。核酸可以过孔。加入单链核酸后,向下的线显示的核酸过孔信号。
[0261]
采用单孔测序技术方法,通过突变孔2对dna构建体bs7
‑
4c3
‑
plt进行测序,完成嵌
孔后添加测序体系出现的核酸测序信号。图19a和19b示出了当解旋酶mph
‑
mp1
‑
e105c/a362c控制dna构建体bs7
‑
4c3
‑
plt穿过突变孔2移位时的示例电流轨迹。根据该信号特征可以得出突变孔2测序分辨率,稳定性,信号一致性等相关特征。该孔台阶清晰,跳变分布明显,具备高精度测序能力。从信号特征来看,测序信号一致性较高。
[0262]
图20显示出部分电流轨迹的放大结果。具有虚线框和箭头的图为原始信号滤波处理后的结果(两条轨迹的y轴坐标=电流(pa),x轴坐标=时间(s))。虚线箭头指示部分显示了电流轨迹的放大结果。此单独一条信号的区域放大显示图,表明该突变孔对核酸测序具备高分辨率。
[0263]
实施例12
[0264]
与实施例10类似,实施例12采用突变孔3进行空测和过孔检测。
[0265]
图21a显示突变孔3在
±
180mv电压下开孔电流及其门控特征。图21b显示突变孔3在+180mv电压下的单链核酸过孔情况。核酸可以过孔。加入单链核酸后,向下的线显示的核酸过孔信号。
[0266]
采用单孔测序技术方法,通过突变孔3对dna构建体bs7
‑
4c3
‑
plt进行测序,完成嵌孔后添加测序体系出现的核酸测序信号。图22a和22b示出了当解旋酶mph
‑
mp1
‑
e105c/a362c控制dna构建体bs7
‑
4c3
‑
plt穿过突变孔3移位时的示例电流轨迹。根据该信号特征,突变孔3可以用来核酸测序。
[0267]
图23是将图22a部分显示出电流轨迹的放大结果。具有虚线框和箭头的图为原始信号滤波处理后的结果(两条轨迹的y轴坐标=电流(pa),x轴坐标=时间(s))。虚线箭头指示部分显示了电流轨迹的放大结果。此单独一条信号的区域放大显示图,进一步证明突变孔3可以用来核酸测序。
[0268]
实施例13
[0269]
与实施例10类似,实施例13采用突变孔4进行空测和过孔检测。
[0270]
图24a显示突变孔4在
±
180mv电压下开孔电流及其门控特征。图24b显示突变孔4在+180mv电压下的单链核酸过孔情况。核酸可以过孔。
[0271]
采用单孔测序技术方法,通过突变孔4对dna构建体bs7
‑
4c3
‑
plt进行测序,完成嵌孔后添加测序体系出现的核酸测序信号。图25a和25b示出了当解旋酶mph
‑
mp1
‑
e105c/a362c控制dna构建体bs7
‑
4c3
‑
plt穿过突变孔4移位时的示例电流轨迹。根据该信号特征,突变孔4可以用来核酸测序。
[0272]
图26是将图25a和25b实施例部分显示出电流轨迹的放大结果。具有虚线框和箭头的图为原始信号滤波处理后的结果(两条轨迹的y轴坐标=电流(pa),x轴坐标=时间(s))。虚线箭头指示部分显示了电流轨迹的放大结果。此单独一条信号的区域放大显示图,进一步证明突变孔4可以用来核酸测序。
[0273]
实施例14
[0274]
与实施例10类似,实施例14采用突变孔5进行空测和过孔检测。
[0275]
图27显示突变孔5在
±
180mv电压下开孔电流及其门控特征。
[0276]
采用单孔测序技术方法,通过突变孔5对dna构建体bs7
‑
4c3
‑
plt进行测序,完成嵌孔后添加测序体系出现的核酸测序信号。图28示出了当解旋酶mph
‑
mp1
‑
e105c/a362c控制dna构建体bs7
‑
4c3
‑
plt穿过突变孔5移位时的示例电流轨迹。根据该信号特征,突变孔5可
以用来核酸测序。
[0277]
图29是将图28实施例部分显示出电流轨迹的放大结果。具有虚线框和箭头的图为原始信号滤波处理后的结果(两条轨迹的y轴坐标=电流(pa),x轴坐标=时间(s))。虚线箭头指示部分显示了电流轨迹的放大结果。此单独一条信号的区域放大显示图,进一步证明突变孔5可以用来核酸测序。
[0278]
实施例15
[0279]
与实施例10类似,实施例15采用突变孔6进行空测和过孔检测。
[0280]
图30a显示突变孔6在
±
180mv电压下开孔电流及其门控特征。图30b显示突变孔6在+180mv电压下的单链核酸过孔情况。核酸可以过孔。加入单链核酸后,向下的线显示的核酸过孔信号。
[0281]
采用单孔测序技术方法,通过突变孔6对dna构建体bs7
‑
4c3
‑
plt进行测序,完成嵌孔后添加测序体系出现的核酸测序信号。图31a和31b示出了当解旋酶mph
‑
mp1
‑
e105c/a362c控制dna构建体bs7
‑
4c3
‑
plt穿过突变孔6移位时的示例电流轨迹。根据该信号特征可以得出突变孔6测序分辨率,稳定性,信号一致性等相关特征。该孔台阶清晰,跳变分布明显,具备高精度测序能力。从信号特征来看,测序信号一致性较高。
[0282]
图32是将图31a部分显示出电流轨迹的放大结果。具有虚线框和箭头的图为原始信号滤波处理后的结果(两条轨迹的y轴坐标=电流(pa),x轴坐标=时间(s))。虚线箭头指示部分显示了电流轨迹的放大结果。此单独一条信号的区域放大显示图,表明该突变孔对核酸测序具备高分辨率。
[0283]
实施例16
[0284]
将含有孔蛋白单体的突变体1核酸序列(seq id no:25)的重组质粒通过热击法转化到bl21(de3)感受态细胞,加入0.5ml lb培养基经30℃培养1h后取适量菌液涂布于氨苄抗性固体lb平板,37℃过夜培养,次日挑取单克隆菌落,接种至50ml含有氨苄抗性的液体lb培养基中37℃培养过夜。按1%的接种量转接至氨苄抗性的tb液体培养基中进行扩大培养,37℃、220rpm条件下培养,并连续不断的测量其od600值。当od600=2.0
‑
2.2时,将tb培养基中的培养液冷却至16℃,并添加异丙基硫代半乳糖苷(isopropylβ
‑
d
‑
thiogalactoside,iptg)诱导表达,使得终浓度达到0.015mm。诱导表达20
‑
24h后,离心收集菌体。菌体用破碎缓冲液重悬后高压破碎,通过ni
‑
nta亲和层析方法进行纯化,收集目的洗脱样品。孔蛋白单体的突变体2
‑
6按如上方法纯化得到。
[0285]
示例性的,图33示出了突变体1的蛋白纯化结果,1
‑
4泳道显示的是分离的不同组分的sds
‑
page电泳检测结果。图34示出了突变体1蛋白尺寸排阻色谱(sec)的示例(25ml superose
‑
6ge healthcare,x轴标记=洗脱体积(ml),y轴标记=吸光度(mau))。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1