用于构建检测染色体拷贝数变异的测序文库的方法和试剂盒与流程
1.本发明涉及快速构建高通量二代测序文库的方法,具体地,涉及用于构建检测染色体拷贝数变异的测序文库的方法。
背景技术:
2.染色体拷贝数变异(cnv)是人类遗传变异的一种重要形式,在人类基因组中广泛分布,其覆盖染色体范围广,突变频率高,可导致突变个体的表型发生严重改变甚至使突变个体死亡。
3.目前,检测cnv的技术包括传统核型分析技术(karyotyping)结合荧光原位杂交(fish)、染色体微列阵分析技术(chromosome microarray analysis, cma,如 acgh 和 snp-array)、荧光定量聚合酶链式反应(qpcr)、多重连接探针扩增技术(mlpa)、高通量测序技术(ngs)等(nord, et al, 2015;manning and hudgins, 2010;trask, 1991;)。近些年日益成熟的ngs因其通量高、准确性高、灵敏性高、自动化程度高和运行成本低等突出的优势,使其在临床研究中得到广泛的应用(xuan, et al, 2013)。
4.在ngs现有的建库技术中,建库的第一步是gdna片段化,最常见的实现方式是物理打断和酶打断。物理打断法主要包括超声或者声波共聚焦(covaris),需要特殊仪器,并且存在用时长,gdna需要量大,产物回收效率低等问题。酶打断,最常见的是neb的nebnext dna双链片段化酶和tn5。nebnext dna双链片段化酶中的t7核酸内切酶具有专利保护,且片段化后的dna片段需末端修复和加a过程;tn5建库成本相对较高,而且必须严格限制dna投入量和tn5的比例。
5.因此,寻找新型有效的片段化技术和快速的建库方法用于检测染色体拷贝数变异,意义重大。
技术实现要素:
6.通过基于切口平移法中聚合酶的不同形式提供两种随机打断gdna的快速建库方法以用于检测染色体拷贝数变异,可以有效解决上述问题。
7.根据本发明的第一方面,提供用于构建高通量测序文库的方法,包括以下步骤:1)提供基因组dna或rna/dna杂合双链样品;2)向上述样品中加入核酸内切酶和dna聚合酶,利用切口平移原理将dna双链或rna/dna杂合双链随机打断得到dna片段并在片段末端加a,以得到加a后的dna片段;3)将所述加a后的dna片段与测序接头连接获得连接产物;4)纯化所述连接产物,获得测序文库。
8.在一种优选实施方案中,所述核酸内切酶是源自弧菌的核酸内切酶,优选源自嗜盐弧菌(vibrio vulnificus)(vvn)的vvn核酸内切酶。
9.在一种优选实施方案中,所述dna聚合酶是聚合酶单酶或同种类型聚合酶的混合酶,其特点是所述酶具有5
´‑3´
聚合活性和5
´‑3´
外切活性但不具有3
´‑5´
外切活性;优选
地,所述dna聚合酶是taq dna polymerase;优选地,其中步骤2)的反应温度固定,温度范围优选40-65℃,更优选50-60℃。
10.在一种优选实施方案中,所述dna聚合酶是两种类型聚合酶的混合酶,其中一种类型的聚合酶是具有5
´‑3´
聚合活性以及3
´‑5´
和5
´‑3´
核酸外切活性;另一种聚合酶是具有5
´‑3´
聚合活性和5
´‑3´
核酸外切活性但不具有3
´‑5´
核酸外切活性的聚合酶;优选地,所述dna聚合酶是dna polymerase i和taq dna polymerase的混合酶;优选地,其中步骤2)的反应温度是可变的,先用较低温度反应,再用较高的反应温度反应,其中较低反应温度优选30-50℃,更优选32-37℃;较高反应温度优选60-75℃,更优选68-72℃。
11.在一种优选实施方案中,其中步骤2)和3)在单一反应管中完成,中间不需要dna纯化步骤。
12.在一种优选实施方案中,所述用于构建高通量测序文库的方法不包含pcr扩增步骤。
13.在一种优选实施方案中,其中所述文库用于检测染色体拷贝数变异。
14.根据本发明的第二方面,提供用于构建高通量测序文库的试剂盒,包括:1)随机打切口并进行切口平移和末端加a的试剂;2)将所述加a后的dna片段与测序接头连接的试剂;和3)用于纯化所述连接产物的试剂。
15.在一种优选实施方案中,所述随机打切口并进行切口平移和末端加a的试剂包括核酸内切酶,dna聚合酶和dntp。
16.在一种优选实施方案中,所述核酸内切酶是源自弧菌的核酸内切酶,优选源自嗜盐弧菌(vibrio vulnificus)(vvn)的vvn核酸内切酶。
17.在一种优选实施方案中,所述dna聚合酶是聚合酶单酶或同种类型聚合酶的混合酶,其特点是所述酶具有5
´‑3´
聚合活性和5
´‑3´
外切活性但不具有3
´‑5´
外切活性;优选地,所述dna聚合酶是taq dna polymerase。
18.在一种优选实施方案中,所述dna聚合酶是两种类型聚合酶的混合酶,其中一种类型的聚合酶是具有5
´‑3´
聚合活性以及3
´‑5´
和5
´‑3´
核酸外切活性;另一种聚合酶是具有5
´‑3´
聚合活性和5
´‑3´
核酸外切活性但不具有3
´‑5´
核酸外切活性的聚合酶;优选地,所述dna聚合酶是dna polymerase i 和taq dna polymerase的混合酶。
19.在一种优选实施方案中,将所述加a后的dna片段与测序接头连接的试剂包括连接酶。
20.在一种优选实施方案中,所述连接酶是t4 dna连接酶或者t7 dna连接酶。
21.在一种优选实施方案中,所述用于纯化所述连接产物的试剂选自纯化柱、qiagen柱、纯化磁珠或者beckman ampure xp beads应当理解,本部分所描述的内容并非旨在标识本发明的实施例的关键或重要特征,也不用于限制本发明的范围。本发明的其它特征将通过以下的说明书而变得容易理解。
附图说明
22.图1:本发明所述方法的原理示意图。
23.图2:本发明所述文库构建方法的示意图。
24.图3:确定vvn核酸内切酶用量胶图,其中gdna:基因组对照,未进行打断反应;vvn-阴:阴性对照,反应体系中除vvn外,其余反应物均加入进行打断反应;vvn-100、10-1
、10-2
、10-3
、10-4
:代表体系中分别加入vvn的原液、稀释10倍、稀释100倍、稀释1000倍、稀释10000倍各1.0ul,与其余反应物的反应产物。m:marker。
25.图4:确定taq dna polymerase用量胶图,其中0.25、0.5、1.0、2.0:代表反应体系中taq dna polymerase加入的体积分别是0.25ul、0.5ul、1.0ul、2.0ul,其余反应物均加入的反应产物;m:marker。
26.图5a-5k:采用本发明的方法构建文库后对不同染色体非整倍体样本进行测序的结果图。
27.图6:采用本发明的方法构建文库后对不同染色体微缺失综合征样本进行测序的结果图,其中纵坐标是指检测区域的拷贝数,横坐标代表整条染色体区域。其中整条染色体被均匀地分成若干个区域,每个点代表一个区域的拷贝数,然后根据所有点的分布得到趋势线(蓝色实线)。图中红色框列出了每一个样本染色体微缺失的区域。
具体实施方式
28.下面将更详细地描述本发明的实施例。然而,应当理解的是,本发明可以通过各种形式来实现,而且不应该被解释为限于这里阐述的实施例,相反提供这些实施例是为了更加透彻和完整地理解本发明。还应当理解的是,本发明的附图及实施例仅用于示例性作用,并非用于限制本发明的保护范围。
29.除非另有限定,本文使用的所有技术以及科学术语具有与本发明所属领域普通技术人员通常理解的相同的含义。当存在矛盾时,以本说明书中的定义为准。
30.本文中所用的术语“包含”、“包括”、“具有”、“含有”或其任何其它变形,意在覆盖非排它性的包括。
31.当量、浓度、或其它值或参数以范围、优选范围、或一系列上限优选值和下限优选值限定的范围表示时,这应当被理解为具体公开了由任何范围上限或优选值与任何范围下限或优选值的任一配对所形成的所有范围,而不论该范围是否单独公开了。例如,当公开了范围“1至5”时,所描述的范围应被解释为包括范围“1至4”、“1至3”、“1-2”、“1-2和4-5”、“1-3和5”等。当数值范围在本文中被描述时,除非另外说明,否则该范围意图包括其端值和在该范围内的所有整数和分数。
32.此外,本文中要素或组分前的不定冠词“一种”和“一个”对要素或组分的数量要求(即出现次数)无限制性。因此“一个”或“一种”应被解读为包括一个或至少一个,并且单数形式的要素或组分也包括复数形式,除非所述数量明显旨在限定单数形式。
33.进一步地,在以下说明书中将提及大量的表述,这些表述被定义为具有下列含义。
[0034]“测序”是指测定在核酸样品例如dna或rna中的核苷酸(碱基序列)的顺序。
[0035]“高通量测序”又称为“下一代测序技术(next generation sequencing)”,简称ngs。是指一次对几十万到几百万条dna分子进行序列测定。
[0036]“切口平移”是指一个具有切口的dna分子在dna聚合酶(具有5
´‑3´
外切酶活性和5
´‑3´
聚合酶活性)的作用下,5
´‑3´
外切酶活性能从切口的5
´
端水解dna链,同时其聚合活性在切口处向3
´
端延伸dna链,结果导致切口位置从5
´
端向3
´
端平移。该方法通常用于向dna
分子引入放射性标记核苷酸。
[0037]
如前文所描述,现有技术中缺乏可以用于检测染色体拷贝数变异的新型有效的片段化技术和快速的建库方法。
[0038]
用于构建高通量测序文库的方法为了至少部分地解决上述问题以及其他潜在问题中的一个或者多个,参见图1(原理示意)和图2(总体方法示意),本发明的第一示例实施方案提出用于构建高通量测序文库的方法,包括以下步骤:1)提供基因组dna或rna/dna杂合双链样品;2)向上述样品中加入核酸内切酶和dna聚合酶,利用切口平移原理将dna双链或rna/dna杂合双链随机打断得到dna片段并在片段末端加a,以得到加a后的dna片段;3)将所述加a后的dna片段与测序接头连接获得连接产物;4)纯化所述连接产物,获得测序文库。
[0039]
关于样品中起始dna的含量,并无特别限制,可以为本领域中常规使用的那些,例如可以为3.5ng-1000ng。
[0040]
关于核酸内切酶,并无特别限制,可以为本领域中常规使用的那些。但是,优选地,所述核酸内切酶是源自弧菌的核酸内切酶,更优选源自嗜盐弧菌(vibrio vulnificus)(vvn)的vvn核酸内切酶。进一步地,所述核酸内切酶还可以是vvn核酸内切酶的野生型或其突变体。
[0041]
关于dna聚合酶,并无特别限制,可以为本领域中常规使用的那些。但是,优选地,所述dna聚合酶可以采用下述两种方式之一使用。
[0042]
在第一种方式中,所述dna聚合酶是聚合酶单酶或同种类型聚合酶的混合酶,其特点是所述酶具有5
´‑3´
聚合活性和5
´‑3´
外切活性但不具有3
´‑5´
外切活性。优选地,在该第一种方式中使用的dna聚合酶是taq dna polymerase。优选地,在该第一种方式中,步骤2)的反应温度固定,温度范围优选40-65℃,更优选50-60℃。例如,可以具体选择40℃、41℃、42℃、43℃、44℃、45℃、46℃、47℃、48℃、49℃、50℃、51℃、52℃、53℃、54℃、55℃、56℃、57℃、58℃、59℃、60℃或这些数值之间的任何数值。进一步优选地,使用上述vvn核酸内切酶和taq dna polymerase的组合来进行上述步骤2),使得所述vvn核酸内切酶随机在双链dna上产生单链切口,taq dna polymerase以此切口从5
´
端向3
´
端平移,实现dna 的随机片段化并加a。使用此组合时,典型地,所述步骤(2)的vvn的使用量是0.11ug-1.1ug,优选为0.33ug-1.1ug,进一步优选为0.88ug。例如,可以具体选择0.11ug、0.12ug、0.13ug、0.14ug、0.15ug、0.16ug、0.17ug、0.18ug、0.19ug、0.20ug、0.21ug、0.22ug、0.23ug、0.24ug、0.25ug、0.26ug、0.27ug、0.28ug、0.29ug、0.30ug、0.31ug、0.32ug、0.33ug、0.34ug、0.35ug、0.36ug、0.37ug、0.38ug、0.39ug、0.40ug、0.41ug、0.42ug、0.43ug、0.44ug、0.45ug、0.46ug、0.47ug、0.48ug、0.49ug、0.50ug、0.51ug、0.52ug、0.53ug、0.54ug、0.55ug、0.56ug、0.57ug、0.58ug、0.59ug、0.60ug、0.61ug、0.62ug、0.63ug、0.64ug、0.65ug、0.66ug、0.67ug、0.68ug、0.69ug、0.70ug、0.71ug、0.72ug、0.73ug、0.74ug、0.75ug、0.76ug、0.77ug、0.78ug、0.79ug、0.80ug、0.81ug、0.82ug、0.83ug、0.84ug、0.85ug、0.86ug、0.87ug、0.88ug、0.89ug、0.90ug、0.91ug、0.92ug、0.93ug、0.94ug、0.95ug、0.96ug、0.97ug、0.98ug、0.99ug、1.00ug、1.01ug、1.02ug、1.03ug、1.04ug、1.05ug、1.06ug、1.07ug、1.08ug、1.09ug、1.1 ug或这些数值之间的任何数
值。使用此组合时,典型地,所述步骤(2)的taq dna polymerase的使用活性单位量是1.25u~5u,优选为1.25u~2.5u,进一步优选为1.25u。例如,可以具体选择1.25u、1.30u、1.35u、1.40u、1.45u、1.50u、1.55u、1.60u、1.65u、1.70u、1.75u、1.80u、1.85u、1.90u、1.95u、2.0u、2.05u、2.10u、2.15u、2.20u、2.25u、2.30u、2.35u、2.40u、2.45u、2.50u、2.55u、2.60u、2.65u、2.70u、2.75u、2.80u、2.85u、2.90u、2.95u、3.0u、3.05u、3.10u、3.15u、3.20u、3.25u、3.30u、3.35u、3.40u、3.45u、3.50u、3.55u、3.60u、3.65u、3.70u、3.75u、3.80u、3.85u、3.90u、3.95u、4.0u、4.05u、4.10u、4.15u、4.20u、4.25u、4.30u、4.35u、4.40u、4.45u、4.50u、4.55u、4.60u、4.65u、4.70u、4.75u、4.80u、4.85u、4.90u、4.95u、5.0u或这些数值之间的任何数值。使用此组合时,典型地,所述步骤(1)的反应条件可为:45℃-68℃,20分钟,优选反应温度为50℃-62℃,进一步优选为50℃或60℃。例如,可以具体选择45℃、46℃、47℃、48℃、49℃、50℃、51℃、52℃、53℃、54℃、55℃、56℃、57℃、58℃、59℃、60℃、61℃、62℃、63℃、64℃、65℃、66℃、67℃、68℃或这些数值之间的任何数值。
[0043]
在第二种方式中,所述dna聚合酶是两种类型聚合酶的混合酶,其中一种类型的聚合酶是具有5
´‑3´
聚合活性以及3
´‑5´
和5
´‑3´
核酸外切活性;另一种聚合酶是具有5
´‑3´
聚合活性和5
´‑3´
核酸外切活性但不具有3
´‑5´
核酸外切活性的聚合酶。优选地,在该第二种方式中使用的dna聚合酶是dna polymerase i和taq dna polymerase的混合酶。优选地,在该第二种方式中,步骤2)的反应温度是可变的,先用较低温度反应,再用较高的反应温度反应,其中较低反应温度优选30-50℃,更优选32-37℃,例如可以为30℃、31℃、32℃、33℃、34℃、35℃、36℃、37℃、38℃、39℃、40℃、41℃、42℃、43℃、44℃、45℃、46℃、47℃、48℃、49℃、50℃或这些数值之间的任何数值;较高反应温度优选60-75℃,更优选68-72℃,例如可以为60℃、61℃、62℃、63℃、64℃、65℃、66℃、67℃、68℃、69℃、70℃、71℃、72℃、73℃、74℃、75℃或这些数值之间的任何数值。典型地,所述步骤2)的反应条件可为:37℃ 5min-20min;68℃ 10min,优选反应条件为37℃ 5min-10min;68℃ 10min,进一步优选为37℃ 10min;68℃ 10min。进一步地,使用上述vvn核酸内切酶+dna polymerase i +taq dna polymerase的组合来进行上述步骤2),所述vvn随机在双链dna上产生单链切口,dna polymerase i以此切口从5’端向3’端平移,实现dna的随机片段化,taq dna polymerase实现片段化dna加a。使用此组合时,典型地,所述步骤(2)的vvn的使用量是0.011ug-0.11ug,优选为0.033ug-0.11ug,进一步优选为0.088ug。例如,可以具体选择0.011ug、0.012ug、0.013ug、0.014ug、0.015ug、0.016ug、0.017ug、0.018ug、0.019ug、0.020ug、0.021ug、0.022ug、0.023ug、0.024ug、0.025ug、0.026ug、0.027ug、0.028ug、0.029ug、0.030ug、0.031ug、0.032ug、0.033ug、0.034ug、0.035ug、0.036ug、0.037ug、0.038ug、0.039ug、0.040ug、0.041ug、0.042ug、0.043ug、0.044ug、0.045ug、0.046ug、0.047ug、0.048ug、0.049ug、0.050ug、0.051ug、0.052ug、0.053ug、0.054ug、0.055ug、0.056ug、0.057ug、0.058ug、0.059ug、0.060ug、0.061ug、0.062ug、0.063ug、0.064ug、0.065ug、0.066ug、0.067ug、0.068ug、0.069ug、0.070ug、0.071ug、0.072ug、0.073ug、0.074ug、0.075ug、0.076ug、0.077ug、0.078ug、0.079ug、0.080ug、0.081ug、0.082ug、0.083ug、0.084ug、0.085ug、0.086ug、0.087ug、0.088ug、0.089ug、0.090ug、0.091ug、0.092ug、0.093ug、0.094ug、0.095ug、0.096ug、0.097ug、0.098ug、0.099ug、0.100ug、0.101ug、0.102ug、0.103ug、0.104ug、0.105ug、0.106ug、0.107ug、0.108ug、0.109ug、0.11ug或这些数值之间
的任何数值。使用此组合时,典型地,所述步骤(2)的dna polymerase i的使用量是3.2u~10u,优选为3.2u~10u,进一步优选3.2u,例如,可以具体选择3.20u、3.25u、3.30u、3.35u、3.40u、3.45u、3.50u、3.55u、3.60u、3.65u、3.70u、3.75u、3.80u、3.85u、3.90u、3.95u、4.0u、4.05u、4.10u、4.15u、4.20u、4.25u、4.30u、4.35u、4.40u、4.45u、4.50u、4.55u、4.60u、4.65u、4.70u、4.75u、4.80u、4.85u、4.90u、4.95u、5.0u、5.20u、5.25u、5.30u、5.35u、5.40u、5.45u、5.50u、5.55u、5.60u、5.65u、5.70u、5.75u、5.80u、5.85u、5.90u、5.95u、6.0u、6.05u、6.10u、6.15u、6.20u、6.25u、6.30u、6.35u、6.40u、6.45u、6.50u、6.55u、6.60u、6.65u、6.70u、6.75u、6.80u、6.85u、6.90u、6.95u、7.0u、7.05u、7.10u、7.15u、7.20u、7.25u、7.30u、7.35u、7.40u、7.45u、7.50u、7.55u、7.60u、7.65u、7.70u、7.75u、7.80u、7.85u、7.90u、7.95u、8.0u、8.05u、8.10u、8.15u、8.20u、8.25u、8.30u、8.35u、8.40u、8.45u、8.50u、8.55u、8.60u、8.65u、8.70u、8.75u、8.80u、8.85u、8.90u、8.95u、9.0u、9.05u、9.10u、9.15u、9.20u、9.25u、9.30u、9.35u、9.40u、9.45u、9.50u、9.55u、9.60u、9.65u、9.70u、9.75u、9.80u、9.85u、9.90u、9.95u、10.0u或这些数值之间的任何数值。使用此组合时,典型地,所述步骤(2)的taq dna polymerase的使用活性单位量是1.25u~5u,优选为1.25u~2.5u,进一步优选为1.25u,例如,可以具体选择1.25u、1.30u、1.35u、1.40u、1.45u、1.50u、1.55u、1.60u、1.65u、1.70u、1.75u、1.80u、1.85u、1.90u、1.95u、2.0u、2.05u、2.10u、2.15u、2.20u、2.25u、2.30u、2.35u、2.40u、2.45u、2.50u、2.55u、2.60u、2.65u、2.70u、2.75u、2.80u、2.85u、2.90u、2.95u、3.0u、3.05u、3.10u、3.15u、3.20u、3.25u、3.30u、3.35u、3.40u、3.45u、3.50u、3.55u、3.60u、3.65u、3.70u、3.75u、3.80u、3.85u、3.90u、3.95u、4.0u、4.05u、4.10u、4.15u、4.20u、4.25u、4.30u、4.35u、4.40u、4.45u、4.50u、4.55u、4.60u、4.65u、4.70u、4.75u、4.80u、4.85u、4.90u、4.95u、5.0u或这些数值之间的任何数值。
[0044]
关于本发明的第一示例实施方案的方法中的步骤2)和3),其可以在单一反应管中完成,中间不需要dna纯化步骤。
[0045]
关于本发明的第一示例实施方案的方法,其可以不包含pcr扩增步骤。
[0046]
关于本发明的第一示例实施方案的方法,其中所述文库用于检测染色体拷贝数变异。
[0047]
用于构建高通量测序文库的试剂盒为了至少部分地解决上述问题以及其他潜在问题中的一个或者多个,本发明的第二示例实施方案提出用于构建高通量测序文库的试剂盒,包括:1)随机打切口并进行切口平移和末端加a的试剂;2)将所述加a后的dna片段与测序接头连接的试剂;和3)用于纯化所述连接产物的试剂。
[0048]
关于所述随机打切口并进行切口平移和末端加a的试剂,并无特别限制,可以为本领域中常规使用的那些,但优选地,其包括核酸内切酶,dna聚合酶和dntp。
[0049]
关于核酸内切酶,并无特别限制,可以为本领域中常规使用的那些。但是,优选地,所述核酸内切酶是源自弧菌的核酸内切酶,更优选源自嗜盐弧菌(vibrio vulnificus)(vvn)的vvn核酸内切酶。进一步地,所述核酸内切酶还可以是vvn核酸内切酶的野生型或其突变体。
[0050]
关于dna聚合酶,并无特别限制,可以为本领域中常规使用的那些。但是,优选地,
所述dna聚合酶可以采用下述两种方式之一使用。
[0051]
在第一种方式中,所述dna聚合酶是聚合酶单酶或同种类型聚合酶的混合酶,其特点是所述酶具有5
´‑3´
聚合活性和5
´‑3´
外切活性但不具有3
´‑5´
外切活性。优选地,在该第一种方式中使用的dna聚合酶是taq dna polymerase。
[0052]
在第二种方式中,所述dna聚合酶是两种类型聚合酶的混合酶,其中一种类型的聚合酶是具有5
´‑3´
聚合活性以及3
´‑5´
和5
´‑3´
核酸外切活性;另一种聚合酶是具有5
´‑3´
聚合活性和5
´‑3´
核酸外切活性但不具有3
´‑5´
核酸外切活性的聚合酶。优选地,在该第二种方式中使用的dna聚合酶是dna polymerase i和taq dna polymerase的混合酶。
[0053]
关于将所述加a后的dna片段与测序接头连接的试剂,并无特别限制,可以为本领域中常规使用的那些。但是,优选地,将所述加a后的dna片段与测序接头连接的试剂包括连接酶。
[0054]
关于连接酶,并无特别限制,可以为本领域中常规使用的那些。但是,优选地,所述连接酶是t4 dna连接酶或者t7 dna连接酶。
[0055]
关于用于纯化所述连接产物的试剂,并无特别限制,可以为本领域中常规使用的那些。但是,优选地,所述用于纯化所述连接产物的试剂选自纯化柱、qiagen柱、纯化磁珠或者beckman ampure xp beads。
优选实施例
[0056]
下面结合说明书附图,进一步对本发明的优选实施例进行详细描述,以下的描述为示例性的,并非对本发明的限制,任何的其他类似情形也都落入本发明的保护范围之中。
[0057]
实施例1:确定vvn核酸内切酶的投入量。
[0058]
(1)将vvn按10-1
/10-2
/10-3
/10-4
分别稀释备用。
[0059]
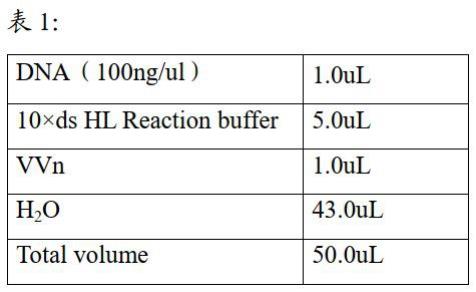
(2) 取100ng细胞系基因组dna作为起始样本,按照表1在反应体系中依次加入43ul ddh2o,5ul 10
×
ds hl reaction buffer,1ul dna,1ul vvn至50ul。其中vvn包括不加入(阴性对照)、原液( 10
0 )、10-1
、10-2
、10-3
、10-4 6种梯度。
[0060]
(3)pcr仪反应程序设定为37℃ 20min;4℃ forever。
[0061]
(4)反应完成后加入loading buffer,使用1.2%琼脂糖凝胶电泳检测打断片段的大小,电泳仪设定电压为120v,时间40min。图3展示出了上述电泳结果,图3上方给出了不同泳道中vvn的投入量,根据图3显示的结果可以知道,不同vvn的投入量对dna的打断效果不同,当vvn稀释成10-1
时,dna的打断大小为100-200bp为较优选择。
[0062]
实施例2:确定taq dna polymerase的投入量。
[0063]
(1)为了确定taq dna polymerase的投入量,分别设置反应体系中加入0.25、0.5、1.0、2.0ul不同的taq dna polymerase。按表2依次加入ddh2o,5ul 10x pcr reaction buffer,1.0ul10 mm dntps,1.0ul dna,1.0ul vvn(稀释10倍),0.25/0.5/1/2.0ul taq dna polymerase至50ul。
[0064]
(2)pcr仪反应程序设定为37℃ 20min;68℃ 20min;4℃ forever。
[0065]
(3)将反应产物按照表3依次加入14.0ul连接缓冲液、5.0ul连接酶、4.0ul adapter进行二代建库,获得连接产物。
[0066]
(4)1x xp磁珠纯化去除未连接的片段以及多余接头,获得测序文库。
[0067]
(5)qpcr扩增确定文库的浓度。同时将qpcr产物加入loading buffer,使用1.2%琼脂糖凝胶电泳检测文库的大小,电泳仪设定电压为120v,时间30min。图4展示出了上述电泳结果,图4上方给出了不同泳道中taq dna polymerase的投入量,根据图4显示的结果可以知道,taq dna polymerase的投入量是0.25ul(即1.25u)和0.5ul(即2.5u)时,文库的大小是300bp,弥散较小;当taq dna polymerase的投入量是1.0ul和2.0ul时,文库弥散严重,且有大片段未被打断。
[0068]
实施例3:确定vvn核酸内切酶和taq dna polymerase的反应温度。
[0069]
(1)按照表4依次加入反应试剂,其中vvn稀释10倍,taq dna polymerase的投入量是0.25ul。
[0070]
(2)pcr仪反应程序设定为45℃~68℃ 20min;4℃ forever共9个温度梯度。
[0071]
(3)将片段化产物按表3依次加入连接试剂进行二代建库,获得连接产物并纯化,qpcr扩增确定文库的浓度。
[0072]
(4)上机测序:使用 nextseq cn500(国械注准 20153400460)测序仪,根据制造商的说明进行上机测序。
[0073]
(5)分析测序数据:将测序数据与人类基因组参考序列进行比对,分析结果如表5所示:结果显示了各个反应温度下文库的浓度/uniq mapped reads/uniq mapped ratio/uniq gc ratio等信息,从各项数据结果可以知道,反应条件可为45℃~68℃,优选反应温度为50℃~62℃。
[0074]
表5:
实施例4:dna 起始含量对测序文库浓度的影响。
[0075]
根据上述实施例确定的实验条件(vvn稀释10倍投入8ul,taq dna polymerase投
入0.25ul,反应温度60℃)构建文库,用起始含量不同的 dna 样本制备测序文库,根据文库的浓度和体积计算所得文库的总量,结果如下表6所示。从表中可以看出,当 dna 起始含量为 3.5ng~1000ng 时,所得文库的总量均大于0.2 fmol,均可以满足测序需求。因此,用于制备文库的起始dna含量范围为 3.5~1000ng,但不限于本范围。
[0076]
实施例5:不同非整倍体样本的检测验证。
[0077]
根据上述实施例确定的实验条件(vvn稀释10倍投入8ul,taq dna polymerase投入0.25ul,反应温度60℃),采用不同非整倍体dna样本构建文库,用于染色体拷贝数变异的检测。将测序结果与人类基因组参考序列进行比对,不同非整倍体dna样本用该方法检测的结果如下表7和图5a-5k所示,染色体拷贝数变异均能正确检出。
[0078]
实施例6:vvn和两种类型聚合酶的混合酶实现dna的随机片段化。
[0079]
(1)按照表8依次加入反应试剂,其中vvn设置梯度分别加入稀释10倍(1ul)/稀释100倍(3/5/8ul),dna polymerase i的投入量是0.32ul,taq dna polymerase 的投入量是0.25ul。
[0080]
(2)pcr仪反应程序设定为37℃ 10min(5min);68℃ 10min;4℃ forever共2个温度梯度。
[0081]
(3)将片段化产物按表3依次加入连接试剂进行二代建库,获得连接产物并纯化,qpcr扩增确定文库的浓度。
[0082]
(4)上机测序:使用 nextseq cn500(国械注准 20153400460)测序仪,根据制造商的说明进行上机测序。
[0083]
(5)分析测序数据:将测序数据与人类基因组参考序列进行比对,分析结果如表9所示:结果显示了各个反应条件下文库的浓度/uniq mapped reads/uniq mapped ratio/uniq gc ratio等信息,从各项数据结果可以知道,vvn稀释100倍加入5.0ul或8ul均取得明显的有益技术效果,其中反应条件为37℃ 10min;68℃ 10min;4℃ forever是优选反应温度。
[0084]
表9:
实施例7:vvn和两种类型聚合酶的混合酶实现dna的随机片段化,进行染色体微缺失综合征的检测。
[0085]
根据实施例6确定的实验条件,采用三种染色体微缺失综合征dna样本构建文库,用于染色体微缺失dna拷贝数变异的检测。将测序结果与人类基因组参考序列进行比对,不同dna样本用该方法检测的结果如下表10和图6所示,对应区域的dna 拷贝数异常情况均能正确检出。
[0086]
实施例8:vvn核酸内切酶+taq dna polymerase实现对rna/dna杂合双链的随机片段化。
[0087]
(1)取总rna用oligo(dt)引物或随机引物合成rna/dna杂合双链。
[0088]
(2)根据上述实施例3确定的实验条件(vvn稀释10倍投入8ul,taq dna polymerase投入0.25ul,反应温度60℃)构建文库。
[0089]
(3)qpcr扩增确定文库的浓度,浓度结果如表11所示,从表中可以看出,用该发明方法对rna/dna杂合双链随机片段化建库后,所得文库的总量大于0.2 fmol,均可以满足测序需求,表明该方法可以实现对rna/dna杂合双链的随机片段化。
[0090]
表11:综上,本发明的用于构建高通量测序文库的方法,提供了一种新型有效的片段化技术和快速的建库方法,其可以更高效地构建检测染色体拷贝数变异的测序文库,取得了明显的有益技术效果。
[0091]
前述的示例仅是说明性的,用于解释本发明的特征的一些特征。所附的权利要求旨在要求可以设想的尽可能广的范围,且本文所呈现的实施例仅是根据所有可能的实施例的组合的选择的实施方式的说明。因此,申请人的用意是所附的权利要求并不被说明本技术的特征的示例的选择限制。如在权利要求中使用的,术语“包括”和其语意上的变体在逻辑上也包括不同和变化的用语,例如但不限于“基本组成为”或“组成为”。当需要时,提供了一些数值范围,而这些范围也包括了在其之间的子范围。这些范围中的变化也对于本领域技术人员也是自明的,且不应被认为被捐献给公众,而这些变化也应在可能的情况下被解释为被所附的权利要求覆盖。而且在科技上的进步将形成由于语言表达的不准确的原因而未被目前考虑的可能的等同物或子替换,且这些变化也应在可能的情况下被解释为被所附的权利要求覆盖。
[0092]
参考文献1. nord a, salipante sj, pritchard c. chapter 11
ꢀ–ꢀ
copy number variant detection using next-generation sequencing. clinical genomics, 2015 , 8 :165-187.
2. trask bj. fluoresence in situ hybridization: application in cytogenetics 15 and gene mapping. trends gnent. 1991, 7:149-154.3. manning m, and hudgins l. array-based technology and recommendations for utilization in medical genetics practice for detection of chromosomal abnormalities. genet. med. 2010, 12(11):742-745.4. xuan j, yu y, qing t, guo l, shi l. next-generation sequencing in 25 the clinic: promises and challenges. cancer lett. 2013, 340(2):284-295.
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1