一种用于辅助诊断甲状腺良恶性肿瘤的标志物及其应用的制作方法
本发明涉及医学领域,特别涉及一种用于辅助诊断甲状腺良恶性肿瘤的标志物及其应用。
背景技术:
1、甲状腺癌(thyroid cancer)是最常见的内分泌系统恶性肿瘤,其中乳头状癌(papillary thyroid cancer,ptc)最为常见,约占80-85%[huang f,wang l,jiah.research trends for papillary thyroid carcinoma from 2010to 2019:asystematic review and bibliometrics analysis.medicine.2021;100(21):e26100.]。目前临床上最常用的甲状腺结节诊断手段是细针穿刺活检,该方法根据穿刺物的细胞学形态对结节的良恶性进行评估[melany m,chen s.thyroid cancer:ultrasound imagingand fine-needle aspiration biopsy.endocrinol metab clin north am.2017;46(3):691-711.]。由于甲状腺良恶性肿瘤的细胞学特征经常发生重叠,因此约有10-30%的细针穿刺诊断为不明确的细胞学结果[cibas es,ali sz.the 2017bethesda system forreporting thyroid cytopathology.thyroid.2017;27(11):1341-6.]。不确定的穿刺结果导致约60%的患者遭受过度治疗或者漏诊[stewart r,leang yj,bhatt cr,grodski s,serpell j,lee jc.quantifying the differences in surgical management ofpatients with definitive and indeterminate thyroid nodule cytology.eur j surgoncol.2020;46(2):252-7.]。这不仅增加了患者经济和身心负担,还占据了大量的公共卫生资源,导致医疗保健系统的巨额财务成本[li m,dal maso l,vaccarella s.globaltrends in thyroid cancer incidence and the impact of overdiagnosis.lancetdiabetes endocrinol.2020;8(6):468-70.]。因此,鉴别甲状腺良恶性肿瘤有利于临床医师采取更精准的治疗方案,具有重要的临床和公共卫生意义。
2、表观遗传学是一种不涉及dna序列改变但可遗传的基因表达调控方式,并能够遗传给下一代[nicoglou a,merlin f.epigenetics:a way to bridge the gap betweenbiological fields.stud hist philos biol biomed sci.2017;66:73-82]。dna甲基化是表观遗传调控的重要方式之一,是指在dna甲基化转移酶的作用下,在基因组cpg二核苷酸的胞嘧啶5’碳位共价键结合一个甲基基团[bird a.perceptions ofepigenetics.nature.2007;447:396-398]。大量研究表明,dna甲基化能引起染色质结构、dna构象、dna稳定性及dna与蛋白质相互作用方式的改变,从而控制基因表达[moore ld,let,fan g.dna methylation and its basic function.neuropsychopharmacology.2013;38:23-38]。
3、s100a10(s100 calcium binding protein a10)基因位于1q21.3,是s100钙结合蛋白家族中的一员。研究表明s100a10与anxa2形成的异四聚体定位于细胞膜表面,s100a10可结合纤溶酶激活剂和纤溶酶原,促进纤溶酶的生成,而后者进一步促进基质金属蛋白酶的产生。基质金属蛋白酶可降解和重塑细胞外基质,导致卵巢癌的侵袭和转移[noye tm,lokman na,oehler mk.s100a10 and cancer hallmarks:structure,functions,and itsemerging role in ovarian cancer.int j mol sci.2018;19(12).seo js,svenningssonp.modulation of ion channels and receptors by p11(s100a10).trends pharmacolsci.2020;41(7):487-97.]。此外,s100a10过表达可以通过多种通路促进胃癌细胞的迁移和侵袭[jiang l,hu lg.serpin peptidase inhibitor clade a member 1-overexpression in gastric cancer promotes tumor progression in vitro and isassociated with poor prognosis.oncol lett.2020;20(6):278.li y,li xy,lilx.s100a10 accelerates aerobic glycolysis and malignant growth by activatingmtor-signaling pathway in gastric cancer.front cell dev biol.2020;8:559486.]。目前关于s100a10基因dna甲基化与甲状腺癌的关系在动物与细胞研究中未见报道,组织s100a10基因甲基化与人群甲状腺癌的关系的研究还未见报道,组织s100a10基因甲基化与中国人群甲状腺良恶性肿瘤鉴别的研究亦未见报道。
技术实现思路
1、本发明的目的是提供一种用于甲状腺恶性肿瘤和甲状腺良性肿瘤鉴别诊断的甲基化标志物。
2、第一方面,本发明要求保护甲基化s100a10基因作为标志物在制备产品中的应用;所述产品的用途为如下中的至少一种:
3、(1)区分或辅助区分甲状腺良性肿瘤和甲状腺恶性肿瘤;
4、(2)区分或辅助区分甲状腺良性肿瘤和不同亚型的甲状腺恶性肿瘤;
5、(3)区分或辅助区分甲状腺良性肿瘤和不同分期的甲状腺恶性肿瘤;
6、(4)区分或辅助区分甲状腺恶性肿瘤不同亚型;
7、(5)区分或辅助区分甲状腺恶性肿瘤不同分期。
8、进一步地,(2)和(4)中所述不同亚型可为病理分型,如组织学分型。
9、进一步地,(3)和(5)中所述不同分期可为临床分期。
10、在本发明的具体实施方式中,(2)中所述区分或辅助区分甲状腺良性肿瘤和不同亚型的甲状腺恶性肿瘤具体可为如下任一种:区分或辅助区分甲状腺良性肿瘤和甲状腺乳头状癌、区分或辅助区分甲状腺良性肿瘤和甲状腺滤泡癌、区分或辅助区分甲状腺良性肿瘤和甲状腺髓样癌、区分或辅助区分甲状腺良性肿瘤和甲状腺未分化癌。
11、在本发明的具体实施方式中,(3)中所述区分或辅助区分甲状腺良性肿瘤和不同分期的甲状腺恶性肿瘤具体可为如下任一种:区分或辅助区分甲状腺良性肿瘤和ⅰ期甲状腺恶性肿瘤、区分或辅助区分甲状腺良性肿瘤和ⅱ期甲状腺恶性肿瘤、区分或辅助区分甲状腺良性肿瘤和ⅲ期甲状腺恶性肿瘤、区分或辅助区分甲状腺良性肿瘤和ⅳ期甲状腺恶性肿瘤。
12、在本发明的具体实施方式中,(4)中所述区分或辅助区分甲状腺恶性肿瘤不同亚型具体可为如下任一种:区分或辅助区分甲状腺乳头状癌和甲状腺滤泡癌、区分或辅助区分甲状腺乳头状癌和甲状腺髓样癌、区分或辅助区分甲状腺乳头状癌和甲状腺未分化癌、区分或辅助区分甲状腺滤泡癌和甲状腺髓样癌、区分或辅助区分甲状腺滤泡癌和甲状腺未分化癌、区分或辅助区分甲状腺髓样癌和甲状腺未分化癌。
13、在本发明的具体实施方式中,(5)中所述区分或辅助区分甲状腺恶性肿瘤不同分期具体可为如下任一种:区分或辅助区分ⅰ期甲状腺恶性肿瘤和ⅱ期甲状腺恶性肿瘤、区分或辅助区分ⅰ期甲状腺恶性肿瘤和ⅲ期甲状腺恶性肿瘤、区分或辅助区分ⅰ期甲状腺恶性肿瘤和ⅳ期甲状腺恶性肿瘤、区分或辅助区分ⅱ期甲状腺恶性肿瘤和ⅲ期甲状腺恶性肿瘤、区分或辅助区分ⅱ期甲状腺恶性肿瘤和ⅳ期甲状腺恶性肿瘤、区分或辅助区分ⅲ期甲状腺恶性肿瘤和ⅳ期甲状腺恶性肿瘤。
14、第二方面,本发明要求保护用于检测s100a10基因甲基化水平的物质在制备产品中的应用;所述产品的用途为前文(1)-(5)中的至少一种。
15、第三方面,本发明要求保护用于检测s100a10基因甲基化水平的物质和记载有数学模型和/或数学模型使用方法的介质在制备产品中的应用;所述产品的用途为前文(1)-(5)中的至少一种。
16、所述数学模型按照包括如下步骤的方法获得:
17、(a1)分别检测n1个a类型样本和n2个b类型样本的s100a10基因甲基化水平(训练集);
18、(a2)取步骤(a1)获得的所有样本的s100a10基因甲基化水平数据,按照a类型和b类型的分类方式,通过二分类逻辑回归法建立数学模型,确定分类判定的阈值。
19、其中,n1和n2均可为10以上正整数。
20、所述数学模型的使用方法包括如下步骤:
21、(b1)检测待测样本的s100a10基因甲基化水平;
22、(b2)将步骤(b1)获得的所述待测样本的s100a10基因甲基化水平数据代入所述数学模型,得到检测指数;然后比较检测指数和阈值的大小,根据比较结果确定所述待测样本的类型是a类型还是b类型;
23、在本发明的具体实施方式中,所述阈值设为0.5。大于0.5归为一类,小于0.5归为另外一类,等于0.5作为不确定的灰区。其中a类型和b类型为相对应的两分类,二分类的分组,哪一组是a类型,哪一组是b类型,要根据具体的数学模型来确定,无需约定。
24、在实际应用中,所述阈值也可根据最大约登指数确定(具体可为最大约登指数对应的数值)。大于阈值归为一类,小于阈值归为另外一类,等于阈值作为不确定的灰区。其中a类型和b类型为相对应的两分类,二分类的分组,哪一组a类型,哪一组是b类型,要根据具体的数学模型来确定,无需约定。
25、所述a类型样本和所述b类型样本可为如下中的任一种:
26、(c1)甲状腺良性肿瘤和甲状腺恶性肿瘤;
27、(c2)甲状腺良性肿瘤和不同亚型的甲状腺恶性肿瘤;
28、(c3)甲状腺良性肿瘤和不同分期的甲状腺恶性肿瘤;
29、(c4)不同亚型的甲状腺恶性肿瘤;
30、(c5)不同分期的甲状腺恶性肿瘤。
31、进一步地,(c2)和(c4)中所述不同亚型可为病理分型,如组织学分型。
32、进一步地,(c3)和(c5)中所述不同分期可为临床分期。
33、在本发明的具体实施方式中,(c2)中所述甲状腺良性肿瘤和不同亚型的甲状腺恶性肿瘤具体可为如下任一种:甲状腺良性肿瘤和甲状腺乳头状癌、甲状腺良性肿瘤和甲状腺滤泡癌、甲状腺良性肿瘤和甲状腺髓样癌、甲状腺良性肿瘤和甲状腺未分化癌。
34、在本发明的具体实施方式中,(c3)中所述甲状腺良性肿瘤和不同分期的甲状腺恶性肿瘤具体可为如下任一种:甲状腺良性肿瘤和ⅰ期甲状腺恶性肿瘤、甲状腺良性肿瘤和ⅱ期甲状腺恶性肿瘤、甲状腺良性肿瘤和ⅲ期甲状腺恶性肿瘤、甲状腺良性肿瘤和ⅳ期甲状腺恶性肿瘤。
35、在本发明的具体实施方式中,(c4)中所述甲状腺恶性肿瘤不同亚型具体可为如下任一种:甲状腺乳头状癌和甲状腺滤泡癌、甲状腺乳头状癌和甲状腺髓样癌、甲状腺乳头状癌和甲状腺未分化癌、甲状腺滤泡癌和甲状腺髓样癌、甲状腺滤泡癌和甲状腺未分化癌、甲状腺髓样癌和甲状腺未分化癌。
36、在本发明的具体实施方式中,(c5)中所述甲状腺恶性肿瘤不同分期具体可为如下任一种:ⅰ期甲状腺恶性肿瘤和ⅱ期甲状腺恶性肿瘤、ⅰ期甲状腺恶性肿瘤和ⅲ期甲状腺恶性肿瘤、ⅰ期甲状腺恶性肿瘤和ⅳ期甲状腺恶性肿瘤、ⅱ期甲状腺恶性肿瘤和ⅲ期甲状腺恶性肿瘤、ⅱ期甲状腺恶性肿瘤和ⅳ期甲状腺恶性肿瘤、ⅲ期甲状腺恶性肿瘤和ⅳ期甲状腺恶性肿瘤。
37、第四方面,本发明要求保护前文第三方面中所述的“记载有数学模型和/或数学模型使用方法的介质”在制备产品中的应用;所述产品的用途为前文(1)-(5)中的至少一种。
38、第五方面,本发明要求保护一种试剂盒。
39、本发明要求保护的试剂盒包括用于检测s100a10基因甲基化水平的物质。所述试剂盒的用途可为前文(1)-(5)中的至少一种。
40、进一步地,所述试剂盒中还含有前文第三方面或第四方面中所述的“记载有数学模型和/或数学模型使用方法的介质”。
41、第六方面,本发明要求保护一种系统。
42、本发明所要求保护的系统,包括:
43、(d1)用于检测s100a10基因甲基化水平的试剂和/或仪器;
44、(d2)装置,所述装置包括单元x和单元y。
45、所述单元x用于建立数学模型,包括数据采集模块、数据分析处理模块和模型输出模块。
46、所述数据采集模块被配置为采集(d1)检测得到的n1个a类型样本和n2个b类型样本的s100a10基因甲基化水平数据。
47、所述数据分析处理模块被配置为接收来自于所述数据采集模块的所述n1个a类型样本和n2个b类型样本的s100a10基因甲基化水平数据,按照a类型和b类型的分类方式,通过二分类逻辑回归法建立数学模型,确定分类判定的阈值。
48、所述模型输出模块被配置为接收来自于所述数据分析处理模块建立的所述数学模型,并进行输出。
49、所述单元y用于确定待测样本类型,包括数据输入模块、数据运算模块、数据比较模块和结论输出模块。
50、所述数据输入模块被配置为输入(d1)检测得到的待测者的s100a10基因甲基化水平数据。
51、所述数据运算模块被配置为接收来自于所述数据输入模块的所述待测者的s100a10基因甲基化水平数据,并将所述待测者的s100a10基因甲基化水平数据代入所述单元x中的所述数据分析处理模块建立的所述数学模型,计算得到检测指数。
52、所述数据比较模块被配置为接收来自于所述数据运算模块计算得到的检测指数,并将所述检测指数与所述单元x中的所述数据分析处理模块中确定的所述阈值进行比较。
53、所述结论输出模块被配置为接收来自于所述数据比较模块的比较结果,并根据所述比较结果输出所述待测样本的类型是a类型还是b类型的结论。
54、所述a类型样本和所述b类型样本可为前文(c1)-(c5)中的任一种。
55、其中,n1和n2均可为10以上正整数。
56、在本发明的具体实施方式中,所述阈值设为0.5。大于0.5归为一类,小于0.5归为另外一类,等于0.5作为不确定的灰区。其中a类型和b类型为相对应的两分类,二分类的分组,哪一组是a类型,哪一组是b类型,要根据具体的数学模型来确定,无需约定。
57、在实际应用中,所述阈值也可根据最大约登指数确定(具体可为最大约登指数对应的数值)。大于阈值归为一类,小于阈值归为另外一类,等于阈值作为不确定的灰区。其中a类型和b类型为相对应的两分类,二分类的分组,哪一组是a类型,哪一组是b类型,要根据具体的数学模型来确定,无需约定。
58、在前文的各个方面中,所述s100a10基因甲基化水平可为s100a10基因中如下(e1)-(e4)所示片段中全部或部分cpg位点的甲基化水平。所述甲基化s100a10基因可为s100a10基因中如下(e1)-(e4)所示片段中全部或部分cpg位点甲基化。
59、(e1)seq id no.1所示的dna片段或与其具有80%以上同一性的dna片段;
60、(e2)seq id no.2所示的dna片段或与其具有80%以上同一性的dna片段;
61、(e3)seq id no.3所示的dna片段或与其具有80%以上同一性的dna片段;
62、(e4)seq id no.4所示的dna片段或与其具有80%以上同一性的dna片段。
63、进一步地,所述“全部或部分cpg位点”可为s100a10基因中seq id no.1至seq idno.4所示4个dna片段中的任意一个或多个cpg位点。
64、或,所述“全部或部分cpg位点”可为s100a10基因中seq id no.1所示的dna片段中所有cpg位点、seq id no.2所示的dna片段中所有cpg位点、seq id no.3所示的dna片段中所有cpg位点和seq id no.4所示的dna片段中所有cpg位点。
65、或,所述“全部或部分cpg位点”可为s100a10基因中seq id no.1所示的dna片段中所有cpg位点、seq id no.2所示的dna片段中所有cpg位点和seq id no.3所示的dna片段中所有cpg位点。
66、或,所述“全部或部分cpg位点”可为s100a10基因中seq id no.1所示的dna片段中所有cpg位点、seq id no.2所示的dna片段中所有cpg位点和seq id no.4所示的dna片段中所有cpg位点。
67、或,所述“全部或部分cpg位点”可为s100a10基因中seq id no.1所示的dna片段中所有cpg位点、seq id no.3所示的dna片段中所有cpg位点和seq id no.4所示的dna片段中所有cpg位点。
68、或,所述“全部或部分cpg位点”可为s100a10基因中seq id no.2所示的dna片段中所有cpg位点、seq id no.3所示的dna片段中所有cpg位点和seq id no.4所示的dna片段中所有cpg位点。
69、或,所述“全部或部分cpg位点”可为s100a10基因中seq id no.1所示的dna片段中所有cpg位点和seq id no.2所示的dna片段中所有cpg位点。
70、或,所述“全部或部分cpg位点”可为s100a10基因中seq id no.1所示的dna片段中所有cpg位点和seq id no.3所示的dna片段中所有cpg位点。
71、或,所述“全部或部分cpg位点”可为s100a10基因中seq id no.1所示的dna片段中所有cpg位点和seq id no.4所示的dna片段中所有cpg位点。
72、或,所述“全部或部分cpg位点”可为s100a10基因中seq id no.2所示的dna片段中所有cpg位点和seq id no.3所示的dna片段中所有cpg位点。
73、或,所述“全部或部分cpg位点”可为s100a10基因中seq id no.2所示的dna片段中所有cpg位点和seq id no.4所示的dna片段中所有cpg位点。
74、或,所述“全部或部分cpg位点”可为s100a10基因中seq id no.3所示的dna片段中所有cpg位点和seq id no.4所示的dna片段中所有cpg位点;
75、或,所述“全部或部分cpg位点”为s100a10基因中所述seq id no.1所示的dna片段中如下5项所示cpg位点的全部或任意4项或任意3项或任意2项或任意1项:
76、(f1)seq id no.1所示的dna片段自5’端第27-28位所示cpg位点;
77、(f2)seq id no.1所示的dna片段自5’端第35-36位所示cpg位点;
78、(f3)seq id no.1所示的dna片段自5’端第63-64位所示cpg位点;
79、(f4)seq id no.1所示的dna片段自5’端第436-437位所示cpg位点;
80、(f5)seq id no.1所示的dna片段自5’端第458-459位所示cpg位点。
81、或,所述“全部或部分cpg位点”为s100a10基因中所述seq id no.2所示的dna片段中如下6项所示cpg位点的全部或任意5项或任意4项或任意3项或任意2项或任意1项:
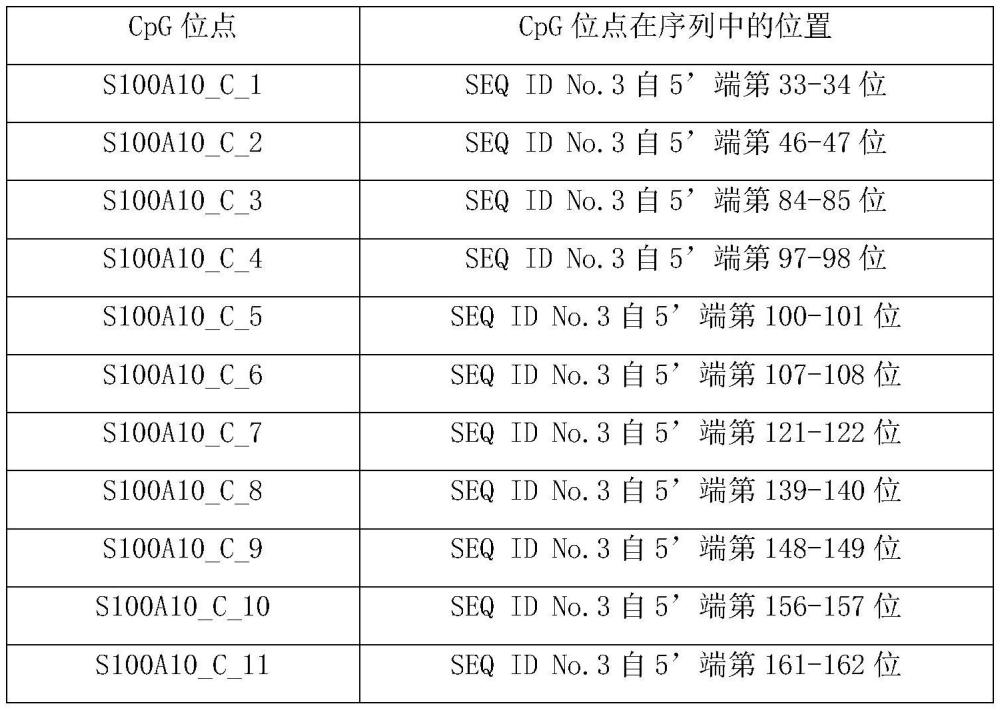
82、(g1)seq id no.2所示的dna片段自5’端第41-42位所示cpg位点;
83、(g2)seq id no.2所示的dna片段自5’端第105-106位所示cpg位点;
84、(g3)seq id no.2所示的dna片段自5’端第128-129和136-137位所示cpg位点;
85、(g4)seq id no.2所示的dna片段自5’端第153-154位所示cpg位点;
86、(g5)seq id no.2所示的dna片段自5’端第233-234位所示cpg位点;
87、(g6)seq id no.2所示的dna片段自5’端第249-250位所示cpg位点。
88、或,所述“全部或部分cpg位点”为s100a10基因中所述seq id no.3所示的dna片段中如下10项所示cpg位点的全部或任意9项或任意8项或任意7项或任意6项或任意5项或任意4项或任意3项或任意2项或任意1项:
89、(h1)seq id no.3所示的dna片段自5’端第33-34位所示cpg位点;
90、(h2)seq id no.3所示的dna片段自5’端第46-47位所示cpg位点;
91、(h3)seq id no.3所示的dna片段自5’端第84-85,97-98,100-101和107-108位所示cpg位点;
92、(h4)seq id no.3所示的dna片段自5’端第121-122位所示cpg位点;
93、(h5)seq id no.3所示的dna片段自5’端第139-140和148-149位所示cpg位点;
94、(h6)seq id no.3所示的dna片段自5’端第156-157,161-162和163-164位所示cpg位点;
95、(h7)seq id no.3所示的dna片段自5’端第171-172位所示cpg位点;
96、(h8)seq id no.3所示的dna片段自5’端第184-185位所示cpg位点;
97、(h9)seq id no.3所示的dna片段自5’端第210-211位所示cpg位点;
98、(h10)seq id no.3所示的dna片段自5’端第255-256位所示cpg位点。
99、或,所述“全部或部分cpg位点”为s100a10基因中所述seq id no.4所示的dna片段中如下5项所示cpg位点的全部或任意4项或任意3项或任意2项或任意1项:
100、(i1)seq id no.4所示的dna片段自5’端第95-96位所示cpg位点;
101、(i2)seq id no.4所示的dna片段自5’端第198-199位所示cpg位点;
102、(i3)seq id no.4所示的dna片段自5’端第228-229位所示cpg位点;
103、(i4)seq id no.4所示的dna片段自5’端第261-262位所示cpg位点;
104、(i5)seq id no.4所示的dna片段自5’端第390-391位所示cpg位点。
105、在本发明的具体实施方式中,有些相邻的甲基化位点在利用飞行时间质谱进行dna甲基化分析时由于几个cpg位点位于一个甲基化片段上,峰图无法区分(无法区分的位点在表6中有记载),因而在进行甲基化水平分析、以及构建和使用相关数学模型时将其按照一个甲基化位点进行处理。前文所述的(g3)、(h3)、(h5)和(h6)便是这种情况。
106、在上述各方面中,所述用于检测s100a10基因甲基化水平的物质可包含(或为)用于扩增s100a10基因全长或部分片段的引物组合。所述用于检测s100a10基因甲基化水平的试剂可包含(或为)用于扩增s100a10基因全长或部分片段的引物组合。所述用于检测s100a10基因甲基化水平的仪器可为飞行时间质谱检测仪。当然所述用于检测s100a10基因甲基化水平的试剂中还可包含进行飞行时间质谱所用的其他常规试剂。
107、进一步地,所述部分片段可为如下中至少一个片段:
108、(j1)seq id no.1所示的dna片段或其包含的dna片段;
109、(j2)seq id no.2所示的dna片段或其包含的dna片段;
110、(j3)seq id no.3所示的dna片段或其包含的dna片段;
111、(j4)seq id no.4所示的dna片段或其包含的dna片段;
112、(j5)与seq id no.1所示的dna片段或其包含的dna片段具有80%以上同一性的dna片段;
113、(j6)与seq id no.2所示的dna片段或其包含的dna片段具有80%以上同一性的dna片段;
114、(j7)与seq id no.3所示的dna片段或其包含的dna片段具有80%以上同一性的dna片段;
115、(j8)与seq id no.4所示的dna片段或其包含的dna片段具有80%以上同一性的dna片段。
116、更进一步地,所述引物组合可为引物对a和/或引物对b和/或引物对c和/或引物d。
117、所述引物对a为引物a1和引物a2组成的引物对;所述引物a1为seq id no.5或seqid no.5的第11-36位核苷酸所示的单链dna;所述引物a2为seq id no.6或seq id no.6的第32-56位核苷酸所示的单链dna。
118、所述引物对b为引物b1和引物b2组成的引物对;所述引物b1为seq id no.7或seqid no.7的第11-35位核苷酸所示的单链dna;所述引物b2为seq id no.8或seq id no.8的第32-56位核苷酸所示的单链dna。
119、所述引物对c为引物c1和引物c2组成的引物对;所述引物c1为seq id no.9或seqid no.9的第11-35位核苷酸所示的单链dna;所述引物c2为seq id no.10或seq idno.10的第32-60位核苷酸所示的单链dna。
120、所述引物对d为引物d1和引物d2组成的引物对;所述引物d1为seq id no.11或seqid no.11的第11-35位核苷酸所示的单链dna;所述引物d2为seq id no.12或seqidno.12的第32-56位核苷酸所示的单链dna。
121、另外,本发明还要求保护一种区分待测样本为a类型样本还是b类型样本的方法。该方法可包括如下步骤:
122、(a)可按照包括如下步骤的方法建立数学模型:
123、(a1)分别检测n1个a类型样本和n2个b类型样本的s100a10基因甲基化水平(训练集);
124、(a2)取步骤(a1)获得的所有样本的s100a10基因甲基化水平数据,按照a类型和b类型的分类方式,通过二分类逻辑回归法建立数学模型,确定分类判定的阈值。
125、其中,(a1)中的n1和n2均为10以上的正整数。
126、(b)可按照包括如下步骤的方法确定所述待测样本为a类型样本还是b类型样本:
127、(b1)检测所述待测样本的s100a10基因甲基化水平;
128、(b2)将步骤(b1)获得的所述待测样本的s100a10基因甲基化水平数据代入所述数学模型,得到检测指数;然后比较检测指数和阈值的大小,根据比较结果确定所述待测样本的类型是a类型还是b类型。
129、在本发明的具体实施方式中,所述阈值设为0.5。大于0.5归为一类,小于0.5归为另外一类,等于0.5作为不确定的灰区。其中a类型和b类型为相对应的两分类,二分类的分组,哪一组是a类型,哪一组是b类型,要根据具体的数学模型来确定,无需约定。
130、在实际应用中,所述阈值也可根据最大约登指数确定(具体可为最大约登指数对应的数值)。大于阈值归为一类,小于阈值归为另外一类,等于阈值作为不确定的灰区。其中a类型和b类型为相对应的两分类,二分类的分组,哪一组是a类型,哪一组是b类型,要根据具体的数学模型来确定,无需约定。
131、所述a类型样本和所述b类型样本可为前文(c1)-(c5)中的任一种。
132、以上任一所述数学模型在实际应用中可能会根据dna甲基化的检测方法以及拟合方式不同有所改变,要根据具体的数学模型来确定,无需约定。
133、在本发明的实施例中,所述模型具体为ln(y/(1-y))=b0+b1x1+b2x2+b3x3+…+bnxn,其中y为因变量即将待测样品的一个或者多个甲基化位点的甲基化值代入模型以后得出的检测指数,b0为常量,x1~xn为自变量即为该测试样品的一个或者多个甲基化位点的甲基化值(每一个值为0-1之间的数值),b1~bn为模型赋予每一个位点甲基化值的权重。
134、在本发明的实施例中,所述模型的建立还可酌情加入年龄、性别等已知参数来提高判别效率。本发明的实施例中建立的一个具体模型为用于区分或辅助区分甲状腺良性肿瘤和甲状腺恶性肿瘤的模型,所述模型具体为:ln(y/(1-y))=5.75-2.14*s100a10_b_1+1.89*s100a10_b_2-3.13*s100a10_b_3.4-1.22*s100a10_b_5-3.76*s100a10_b_6-2.84*s100a10_b_7-0.081*年龄(取整数值)+0.163*性别(男性赋值为1,女性赋值为2)。
135、所述s100a10_b_cpg_1为seq id no.2所示的dna片段自5’端第41-42位所示cpg位点的甲基化水平;所述s100a10_b_cpg_2为seq id no.2所示的dna片段自5’端第105-106位所示cpg位点的甲基化水平;所述s100a10_b_cpg_3.4为seq id no.2所示的dna片段自5’端第128-129和136-137位所示cpg位点的甲基化水平;所述s100a10_b_cpg_5为seq id no.2所示的dna片段自5’端第153-154位所示cpg位点的甲基化水平;所述s100a10_b_cpg_6为seq id no.2所示的dna片段自5’端第233-234位所示cpg位点的甲基化水平;所述s100a10_b_cpg_7为seq id no.2所示的dna片段自5’端第249-250位所示cpg位点的甲基化水平。所述模型的阈值为0.5。通过模型计算的检测指数大于0.5的患者候选为甲状腺恶性肿瘤患者,小于0.5的患者候选为甲状腺良性肿瘤患者。
136、在上述各方面中,所述检测s100a10基因甲基化水平为检测肿瘤组织样本中s100a10基因甲基化水平。
137、在本发明中,甲状腺恶性肿瘤组织中的s100a10基因中seq id no.1、2、3和4所示的dna片段上甲基化位点的甲基化水平明显低于甲状腺良性肿瘤。
138、在本发明中,随着甲状腺恶性肿瘤的分期的增加组织中的s100a10基因中seq idno.1、2、3和4所示的dna片段上甲基化位点的甲基化水平越来越低。
139、以上任一所述s100a10基因具体可参见genbank登录号:nc_000001.11。
140、本发明证明活检样本s100a10甲基化可作为甲状腺良性肿瘤和甲状腺恶性肿瘤、不同亚型或不同分期的甲状腺恶性肿瘤的鉴别诊断的潜在标志物。本发明对鉴别甲状腺良性肿瘤和甲状腺恶性肿瘤、不同亚型或不同分期的甲状腺恶性肿瘤,以及指导制定合理的临床治疗方案均有重要的科学意义和临床应用价值。
- 还没有人留言评论。精彩留言会获得点赞!