HNF1A基因突变的细胞模型及其构建方法和应用
hnf1a基因突变的细胞模型及其构建方法和应用
技术领域
1.本发明涉及生物技术技术领域,尤其是涉及一种hnf1a基因突变的hela细胞模型及其构建方法和应用。
背景技术:
2.糖尿病是一种受遗传和环境等因素影响的慢性代谢性疾病。
3.在糖尿病患者中,约1-4%的患者为单基因糖尿病,这类患者的糖尿病是由单个基因异常改变而引起胰岛β细胞功能失常所致,且单基因糖尿病的发生几乎不受环境的影响。单基因糖尿病主要包括新生儿糖尿病(ndm) 和青少年发病的成人型糖尿病(mody)。其中,青少年发病的成人型糖尿病是一组常染色体显性遗传病,mody家系中携带突变基因的健康成员的患病风险高达95%,且同一家系的患者临床表现高度相似。
4.在欧洲,mody占总糖尿病人群的1%2%。内分泌学界认为,至少有 6种不同基因中的一种突变导致了mody,包括编码葡萄糖激酶 (glucokinase,gck)的基因(mody2)和编码5个转录因子的基因:肝细胞核因子(hepatocyte nuclear factor,hnf-4a(mody1)、hnf-1a(mody3)、胰岛素启动因子1(insulin promoter factor,ipf-1)(mody4)、hnf-1b(mody5) 以及神经元性分化因子1(neuronal differentiation 1,neurod1)(mody6)。
5.其中,mody3由肝细胞核因子hnf1a基因突变引起,是最常见的单基因糖尿病,约占单基因糖尿病总数的50%。hnf1a广泛表达于胰岛β细胞、肝脏、肠道等器官,是胰岛发育及β细胞分化过程中重要的转录因子,该基因突变导致胰岛功能进行性下降,有较高的外显率,突变基因携带者多在25岁前发病。临床上以餐后血糖明显升高为主,可表现为“三多一少”,但较少发生酮症。同时,由于hnf1a是调节肾小管上皮钠葡萄糖共转运体 2(sglt2)表达的重要转录因子,hnf1a基因突变导致sglt2表达下降,葡萄糖重吸收减少,肾糖阈降低,故mody3患者在未发展成糖尿病之前即可出现尿糖阳性。
6.因此,对由hnf1a基因突变导致的单基因糖尿病的诊断和精确分型是实现个体化治疗,给予患者最优化治疗方案的基础,并且对于疾病进程、预后的判断及对家族遗传指导具有重要的意义。
7.本发明致力于提供一种可用于单基因糖尿病的诊断和精确分型的 hnf1a基因突变的hela细胞模型以及其构建方法和应用。
技术实现要素:
8.本发明的第一目的在于提供一种hnf1a基因突变的hela细胞模型的构建方法,该构建方法操作简单便捷,所得细胞模型稳定可靠;
9.本发明的第二目的在于提供一种hnf1a基因突变的hela细胞模型,可用于由hnf1a基因突变所致的单基因糖尿病的诊断和精确分型。
10.本发明提供一种hnf1a基因突变的hela细胞模型的构建方法,包括以下步骤:
11.s1、针对hnf1a基因需要突变的目的基因位点,设计grna靶点;
12.s2、根据grna靶点合成插入片段,并构建敲除质粒;
13.s3、将敲除质粒转染至hela细胞,得到hnf1a基因突变的hela细胞模型;
14.其中,所述grna靶点的序列如seq id no.1所示。
15.作为本技术方案优选地,步骤s2中,所述grna靶点对应的正向引物 hnf1a-g1-fp的序列如seq id no.2所示,所述grna靶点对应的反向引物hnf1a-g1-rp的序列如seq id no.3所示。
16.作为本技术方案优选地,步骤s2中,所述插入片段具体包括:利用正向引物hnf1a-g1-fp和反向引物hnf1a-g1-rp合成的引物合成引物二聚体。
17.作为本技术方案优选地,步骤s2中,所述构建敲除质粒具体包括:使用dna ligase将酶切好的pu6-grna-cas9质粒与引物二聚体连接起来,得到敲除质粒。
18.作为本技术方案优选地,步骤s3之后还包括步骤s4:转染敲除质粒的hela细胞的活性检测和单克隆细胞的目的位点基因鉴定。
19.作为本技术方案优选地,所述活性检测时,提取转染敲除质粒hela细胞的基因组,以基因组dna为模板,采用正向引物hnf1a-f1和反向引物 hnf1a-r1进行扩增,回收产物后进行活性检测;
20.所述正向引物hnf1a-f1的序列如seq id no.4所示;
21.所述反向引物hnf1a-r1的序列如seq id no.5所示。
22.作为本技术方案优选地,所述目的位点基因鉴定时,使用所述正向引物hnf1a-f1和所述反向引物hnf1a-r1对单克隆细胞基因组dna进行 pcr扩增,回收产物后进行一代测序。
23.根据上述构建方法构建得到的hnf1a基因突变的hela细胞模型也理应属于本发明的保护范围。
24.本发明还公开了上述hnf1a基因突变的hela细胞模型在由hnf1a突变所致糖尿病的机理研究、药物筛选以及防治产品中的应用,其产品包括试剂、试剂盒、药物或保健品,但不限于此。
25.本发明hnf1a基因突变的hela细胞模型的构建方法,至少具有以下技术效果:
26.本发明首先根据由hnf1a基因需要突变的位点,设计了特异性的grna靶点,合成表达grna的质粒,然后在此基础上,根据grna靶点合成插入片段,并构建敲除质粒,建立hnf1a基因突变的hela细胞模型。经活性检测及测序鉴定得到的hnf1a基因突变的hela细胞模型,为一稳定可靠的模型,可用于由hnf1a基因突变所致的单基因糖尿病的诊断和精确分型,进而实现个体化治疗,给予患者最优化治疗方案的基础,对于疾病进程、预后的判断及对家族遗传指导具有重要的意义。
附图说明
27.为了更清楚地说明本发明具体实施方式或现有技术中的技术方案,下面将对具体实施方式或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图是本发明的一些实施方式,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
28.图1为本发明cas9/grna的突变率检测酶切结果;
29.图2为本发明g1的pcr产物测序结果;
30.图3为本发明nc的pcr产物测序结果;
31.图4为本发明细胞培养成长状态示意图;
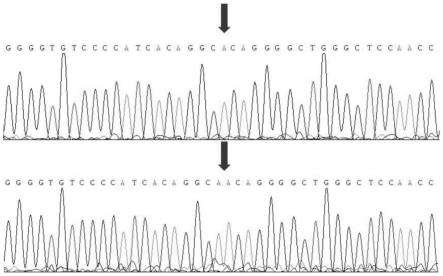
32.图5为本发明野生型及突变型测序结果。
具体实施方式
33.应该指出,以下详细说明都是例示性的,旨在对本技术提供进一步的说明。除非另有指明,本文使用的所有技术和科学术语具有与本技术所属技术领域的普通技术人员通常理解的相同含义。
34.需要注意的是,这里所使用的术语仅是为了描述具体实施方式,而非意图限制根据本技术的示例性实施方式。如在这里所使用的,除非上下文另外明确指出,否则单数形式也包括复数形式,此外,还应当理解的是,当在本说明中使用术语“包含”和/或“包括”时,其指明存在特征、步骤、操作、器件、组件和/或它们的组合。
35.下面将结合实施例对本发明的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
36.实施例
37.s1、针对hnf1a基因需要突变的目的基因位点,设计grna靶点,合成表达grna的质粒,表1为几种grna靶点序列;
38.表1 grna靶点序列
39.靶点名称序列信息hnf1a-g1tccccatcacaggcacagggghnf1a-g2cttcttctttgcgccggttgghnf1a-g3aagccttccggcacaagctgghnf1a-g4gcccgctgtacgtgtccatgghnf1a-g5gcccgctcacagctcccctgghnf1a-g6ctgccctctcccccagtaagg
40.s2、根据grna靶点合成插入片段,并构建敲除质粒;
41.插入片段的合成
42.每个靶点设计对应的引物,引物序列如表2,正向引物和反向引物合成的oligo分别稀释成10μm,按表3比例混合,混匀后,跑pcr仪anneal 退火程序,程序如下:95℃5min,每30s降1℃,直至16℃。
43.表2引物序列
44.引物名称序列信息hnf1a-g1-fpaccgtccccatcacaggcacaghnf1a-g1-rpaaacctgtgcctgtgatggggahnf1a-g2-fpaccgcttcttctttgcgccggthnf1a-g2-rpaaacaccggcgcaaagaagaag
hnf1a-g3-fpaccgaagccttccggcacaagchnf1a-g3-rpaaacgcttgtgccggaaggctthnf1a-g4-fpaccggcccgctgtacgtgtccahnf1a-g4-rpaaactggacacgtacagcgggchnf1a-g5-fpaccggcccgctcacagctcccchnf1a-g5-rpaaacggggagctgtgagcgggchnf1a-g6-fpaccgctgccctctcccccagtahnf1a-g6-rpaaactactgggggagagggcag
45.表3反应体系
46.target-sense1μltarget-anti1μl10x退火buffer2μlh2o6μl最终体系10μl
47.敲除质粒的构建
48.使用bbsi酶(neb)对pu6-grna-cas9质粒进行酶切,酶切体系如表 4所示,50℃反应2小时,回收线性质粒;
49.表4酶切体系
50.组分用量10x neb buffer 3.15μlbbsi1μlpu6-grna-cas9质粒xμl(2μg)ddh2oup to 50μl
51.使用t4 dna ligase(neb)将酶切好的pu6-grna-cas9质粒与oligo二聚体连接起来,反应体系如表5所示,16℃连接反应2h,将混合物加入到刚解冻的50μl dh5a感受态细胞中,轻弹混匀,冰浴30min后,42℃热激90s,冰上静置2min,直接涂于氨苄抗性的平板,37℃倒置培养过夜。挑取克隆培养,取3个菌液送测,测序正确后,得到正确质粒,根据对应的靶点,质粒分别取名hnf1a-g1到g6。
52.表5反应体系
53.组分用量10
×ꢀ
t4 dna ligase buffer1μlt4 dna ligase0.5μloligo二聚体2μl线性pu6-grna-cas9质粒xμl(50ng)ddh2oup to 10μl
54.s3、将敲除质粒转染至hela细胞,得到hnf1a基因突变的hela细胞模型;
55.1、将hela细胞接种于6孔板中(1.5
×
106细胞/孔),采用含10%fbs 的dmem培养液于37℃5%co2培养24h;
56.2、完成步骤1后,取所述6孔板,吸去培养基,将转染复合物加入孔中,混匀,37℃5%co2培养5h。
57.3、转染复合物的制备
58.a.取50μl opti-mem低血清培养基(或者其他无血清培养基),加入 1ug pu6-grna-cas9质粒,1μl lipo2000试剂,轻轻混匀;
59.b.取4μl lipo2000试剂在50μl opti-mem培养基中稀释,混匀。
60.c.将前两步所稀释的dna和lipo2000试剂混合(使总体积为100μl),轻轻混匀,室温放置5分钟。
61.3、在每孔细胞中加入100μl转染液,轻轻摇匀,得到hnf1a基因突变的hela细胞模型。
62.s4、转染敲除质粒的hela细胞的活性检测和目的位点基因鉴定
63.活性检测方法
64.1、收集分别转染hnf1ag1、hnf1ag2、hnf1ag3、hnf1ag4、 hnf1ag5、hnf1ag6的细胞和未进行转染的hela细胞(nc),分别提取细胞的基因组dna,以基因组dna为模板,采用正向引物hnf1a-f1和反向引物hnf1a-r1进行pcr扩增,引物序列如表6所示;
65.表6正向引物hnf1a-f1和反向引物hnf1a-r1的序列
[0066][0067]
2、转染质粒的细胞为突变型细胞,未转染的细胞为野生型细胞,用引物扩增细胞基因组dna,分两组:突变型的细胞基因组dna和野生型细胞基因组dna,纯化pcr产物,定量;
[0068]
3、将相应对的突变型细胞基因组dna分别和野生型的基因组dna产物各取100ng,pcr产物加热95℃5分钟,自然冷却,退火杂交;
[0069]
4、将处理好的pcr产物混合物,用t7e1酶切(#e001s,唯尚立德),酶切体系如表7所示,使用pcr仪进行退火处理,设置程序如下:95℃5min,每30s降1℃,到16℃;
[0070]
5、退火结束后,加入0.5μl t7e1酶,37℃反应30min后,立刻加2μldna loading buffer,混匀后65℃煮10min,跑2%的琼脂糖凝胶电泳检测分析酶切结果。
[0071]
表7酶切体系
[0072]
组分用量突变体dna pcr产物50ng野生型dna pcr产物50ng10x t7e1 buffer1μlddh2oup to 10μl
[0073]
活性检测结果
[0074]
cas9/grna的突变率检测酶切结果如图1所示;
[0075]
如果g1有活性,将酶切出190bp+530bp左右的条带,从图中可以看到酶切目的条带,并且大小与预期相符,因此g1有内源活性;
[0076]
如果g2有活性,将酶切出240bp+480bp左右的条带,从图中可以看到酶切目的条带,并且大小与预期相符,因此g2可能有内源活性;
[0077]
如果g3有活性,将酶切出270bp+450bp左右的条带,从图中可以看到酶切目的条带,并且大小与预期相符,因此g3可能有内源活性;
[0078]
如果g4有活性,将酶切出270bp+450bp左右的条带,从图中可以看到酶切目的条带,并且大小与预期相符,因此g4可能有内源活性;
[0079]
如果g5有活性,将酶切出350bp+370bp左右的条带,从图中可以看到酶切目的条带,并且大小与预期相符,因此g5可能有内源活性;
[0080]
如果g6有活性,将酶切出370bp+350bp左右的条带,从图中可以看到酶切目的条带,并且大小与预期相符,因此g6可能有内源活性;
[0081]
因此g1有内源活性,g2、g3、g4、g5、g6没有内源活性。
[0082]
为了进一步确认g1的内源活性活性情况,我们将g1的pcr产物回收送测,其测序结果如图2所示。
[0083]
对比图2和图3可知,g1在靶点附近有底峰,因此g1有内源活性,可进行后续的细胞构建。
[0084]
目的位点基因鉴定
[0085]
1、细胞转染:将敲除质粒g1转染至hela细胞,48h后进行单克隆铺板;
[0086]
2、单克隆铺板:细胞消化,计数后加入培养基稀释,稀释成1细胞/100ul 培养基浓度,吸取100ul液体加入到96空细胞培养板中,进行单克隆细胞培养;
[0087]
3、细胞培养1周后,定期观察细胞成长状态,观察细胞单克隆是否形成,图4可见单克隆细胞簇形成;
[0088]
4、单克隆细胞生长至96孔板50%后,消化细胞,一半细胞提取基因组,对目的位点进行pcr,进行一代测序,另一半转移到48孔板继续培养;
[0089]
5、使用引物hnf1a-f1和引物hnf1a-r1对单克隆细胞基因组dna 进行pcr扩增,回收产物后进行一代测序,突变后的测序结果如图5所示。
[0090]
结果表明,成功构建了hnf1a基因突变的hela细胞模型。
[0091]
最后应说明的是:以上各实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述各实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分或者全部技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1