工程化乙酸激酶变体酶的制作方法
发明领域本发明提供了工程化乙酸激酶(ack)、具有ack活性的多肽和编码这些酶的多核苷酸、以及载体和包含这些多核苷酸和多肽的宿主细胞。还提供了用于产生ack酶的方法。本发明还提供了包含ack酶的组合物,以及使用工程化ack酶的方法。本发明尤其可用于药物化合物的产生。对序列表、表格或计算机程序的引用序列表的正式副本作为ascii格式的文本文件经由efs-web与说明书同时提交,文件名为“cx2-205wo1_st25.txt”,创建日期为2022年3月31日,且大小为1.35兆字节。经由efs-web提交的序列表为本说明书的一部分并且通过引用以其整体并入本文。
背景技术:
0、发明背景
1、调节人体对外源dna的免疫应答的sting途径已经作为癌症疗法的重要靶标出现。特别地,已知激活sting的环状二核苷酸是激活或增强先天免疫应答的有吸引力的靶标。环状二核苷酸可以通过核苷三磷酸底物的环化酶促产生。已知cgamp(一种环状二核苷酸),作为第二信使,通过内质网传感器sting刺激先天免疫来起作用。sting的cgamp激活被显示通过诱导干扰素的产生和刺激树突状细胞在小鼠中具有抗肿瘤作用(li等人,sci.rep.6:19049[2016])。cgamp是由作为外来核酸的细胞传感器的环状gmp-amp合酶(cgas)响应于双链dna(dsdna)而产生的(gao等人,cell.153:1094–1107[2013])。cgas活性需要dsdna的结合,而单链dna(ssdna)或rna配体的结合分别仅产生弱活性或不产生活性。与dsdna的结合导致cgas的构象变化,以诱导活性酶状态(kranzusch等人,cell rep.3(5):1362–1368[2013])。
2、已经产生了若干种cgas晶体结构,包括鼠和人类cgas。这些晶体结构揭示了若干种保守结构域,包括核苷酸基转移酶核心、锌指结构域和c-末端结构域(gao等人,cell.153(5):1094-1107[2013];kranzusch等人,cell rep.3(5):1362–1368[2013])。除了结合的dsdna,cgas还需要二价金属阳离子(通常是mn2+或mg2+)来发挥活性。cgas从腺苷三磷酸(atp)和鸟苷三磷酸(gtp)合成cgamp。这些底物本身又分别由腺苷酸激酶(adk)和鸟苷酸激酶(gk)产生,其需要乙酸激酶(ack)进行最后的磷酸化步骤,并将核苷二磷酸再循环为被反应消耗的核苷三磷酸两者。
3、对于利用环状二核苷酸和非天然环状二核苷酸来刺激免疫的改进的癌症疗法存在需求。具体地,使用工业操作条件产生环状二核苷酸和非天然环状二核苷酸的改进的方法是必要的。一种方法是利用具有改进性质的工程化多肽来产生核苷三磷酸底物和非天然环状二核苷酸。
技术实现思路
0、发明概述
1、本发明提供了工程化乙酸激酶(ack)、具有ack活性的多肽和编码这些酶的多核苷酸、以及载体和包含这些多核苷酸和多肽的宿主细胞。还提供了用于产生ack酶的方法。本发明还提供了包含ack酶的组合物,以及使用工程化ack酶的方法。本发明尤其可用于药物化合物的产生。
2、本发明提供了工程化乙酸激酶或其功能片段,所述工程化乙酸激酶包含与seq idno:2和/或4具有至少85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更多序列同一性的多肽序列,其中所述工程化乙酸激酶包含在所述多肽序列中包含至少一个取代或取代集的多肽,并且其中所述多肽序列的氨基酸位置参考seq id no:2和/或4编号。在一些实施方案中,多肽序列与seq id no:2具有至少85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更多的序列同一性,并且其中工程化乙酸激酶的多肽在所述多肽序列中选自以下的一个或更多个位置处包含至少一个取代或取代集:4/142/242、12/76/164/284、12/76/232、15、23、39、41、47、51、52、54、57、76、76/164/232/262/386、76/164/262/284、76/232/262/284/386、76/232/364/386、76/262、76/262/273、76/262/364、76/273、76/284/299、76/364、130、135/284、135/392、145/400、191、232、232/386、275、285、288、290、292、294、297、298、298/377、298/405、343、372、373、374、376、391和392,其中所述多肽序列的氨基酸位置参考seq idno:2编号。在一些实施方案中,工程化乙酸激酶的多肽序列与seq id no:4具有至少85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更多的序列同一性,并且其中工程化乙酸激酶的多肽在所述多肽序列中的一个或更多个位置处包含选自以下的至少一个取代或取代集:4-/142v/242t、12k/76v/164m/284l、12k/76v/232s、15n、23h、23n、39a、41f、47a、47s、47w、51f、52w、54v、57r、76v、76v/164m/232s/262l/386k、76v/164m/262l/284l、76v/232s/262l/284l/386k、76v/232s/364i/386k、76v/262l、76v/262l/273v、76v/262l/364i、76v/273v、76v/284l/299d、76v/364i、130v、135t/284t、135t/392w、145e/400v、191i、232s、232s/386k、275h、275t、285t、288s、288t、290l、292p、294l、297n、298g、298g/377q、298l、298l/405e、298s、298t、298v、298w、343c、343s、372c、372l、372n、372r、372v、373p、374a、374d、374h、374l、374m、374p、374q、374s、374w、376s、376v、391g和392w,其中所述多肽序列的氨基酸位置参考seq id no:2编号。在一些实施方案中,工程化乙酸激酶的多肽序列与seq id no:2具有至少85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更多的序列同一性,并且其中工程化乙酸激酶的多肽在所述多肽序列中的一个或更多个位置处包含选自以下的至少一个取代或取代集:h4-/a142v/l242t、r12k/i76v/i164m/y284l、r12k/i76v/c232s、v15n、i23h、i23n、g39a、a41f、e47a、e47s、e47w、l51f、v52w、r54v、d57r、i76v、i76v/i164m/c232s/i262l/r386k、i76v/i164m/i262l/y284l、i76v/c232s/i262l/y284l/r386k、i76v/c232s/l364i/r386k、i76v/i262l、i76v/i262l/m273v、i76v/i262l/l364i、i76v/m273v、i76v/y284l/e299d、i76v/l364i、p130v、a135t/y284t、a135t/v392w、k145e/i400v、t191i、c232s、c232s/r386k、d275h、d275t、g285t、k288s、k288t、f290l、s292p、m294l、i297n、e298g、e298g/e377q、e298l、e298l/k405e、e298s、e298t、e298v、e298w、g343c、g343s、t372c、t372l、t372n、t372r、t372v、i373p、r374a、r374d、r374h、r374l、r374m、r374p、r374q、r374s、r374w、k376s、k376v、v391g和v392w,其中所述多肽序列的氨基酸位置参考seq id:2编号。在一些实施方案中,工程化乙酸激酶包含与seq id no:2具有至少85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更多的序列同一性的多肽序列。在一些实施方案中,工程化乙酸激酶包含与seq id no:2具有至少90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更多的序列同一性的多肽序列。在一些实施方案中,工程化乙酸激酶包含与seq id no:2具有至少95%、96%、97%、98%、99%或更多的序列同一性的多肽序列。
3、在一些实施方案中,多肽序列与seq id no:2具有至少85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更多的序列同一性,并且其中工程化乙酸激酶的多肽在所述多肽序列中选自以下的一个或更多个位置处包含至少一个取代或取代集:4/142/242、12/76/164、15、23、39、41、44、45、47、47/411、48、50、51、53、55、57/135、58、58/135、61、76、76/142/299/386、76/164、76/164/232/262/386、76/164/262、76/164/273、76/164/287/364、76/164/386、76/232、76/232/259/364、76/232/262、76/232/273/299/311/386、76/232/364/386、76/262、76/262/273、76/262/284/287/386、76/262/284/364、76/262/287、76/262/364、76/273、76/284/299、76/284/311/386、76/364、76/386、130、132、135/284、135/392、145/400、164/232/284/287、191、220、220/360、241、246、262/284/287、273/311/313/364、275、279、283、285、287、288、289、290、292、294、297、298、298/405、299、311、311/364/386、332、340、343、343/388、347、364、372、373、374、375、376、391、392和405,其中所述多肽序列的氨基酸位置参考seq id no:2编号。在一些实施方案中,工程化乙酸激酶的多肽序列与seq id no:2具有至少85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更多的序列同一性,并且其中工程化乙酸激酶的多肽在所述多肽序列中的一个或更多个位置处包含选自以下的至少一个取代或取代集:4-/142v/242t、12k/76v/164m、15a、15n、15s、23h、23n、39a、39s、39t、41f、44v、45l、45w、47i、47m、47n、47p、47r、47s、47s/411f、48r、50q、51f、53i、55s、57s/135t、58n/135t、58s/135t、58w、61s、61t、76v、76v/142v/299d/386k、76v/164m、76v/164m/232s/262l/386k、76v/164m/262l、76v/164m/273v、76v/164m/287t/364i、76v/164m/386k、76v/232s、76v/232s/259v/364i、76v/232s/262l、76v/232s/273v/299d/311a/386k、76v/232s/364i/386k、76v/262l、76v/262l/273v、76v/262l/284l/287t/386k、76v/262l/284l/364i、76v/262l/287t、76v/262l/364i、76v/273v、76v/284l/299d、76v/284l/311a/386k、76v/364i、76v/386k、130v、132g、135t/284t、135t/392w、145e/400v、164m/232s/284l/287t、191i、191v、220g、220s/360v、241t、246q、246y、262l/284l/287t、273v/311a/313d/364i、275f、275h、275s、275t、275y、279r、283m、285s、285t、287g、287l、287n、287t、288h、288r、289s、290h、290i、290l、290r、290v、292p、292r、294f、294l、297n、298l、298l/405e、299q、299v、299w、311a、311a/364i/386k、332d、340g、343e、343t、343t/388i、347i、347q、347s、364i、372d、372g、372l、372n、372r、372v、373p、373s、374a、374d、374p、374s、374w、375p、376s、391g、392p和405e,其中所述多肽序列的氨基酸位置参考seq id no:2编号。在一些实施方案中,工程化乙酸激酶的多肽序列与seq id no:2具有至少85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更多的序列同一性,并且其中工程化乙酸激酶的多肽在所述多肽序列中的一个或更多个位置处包含选自以下的至少一个取代或取代集:h4-/a142v/l242t、r12k/i76v/i164m、v15a、v15n、v15s、i23h、i23n、g39a、g39s、g39t、a41f、i44v、g45l、g45w、e47i、e47m、e47n、e47p、e47r、e47s、e47s/i411f、g48r、r50q、l51f、h53i、v55s、d57s/a135t、e58n/a135t、e58s/a135t、e58w、v61s、v61t、i76v、i76v/a142v/e299d/r386k、i76v/i164m、i76v/i164m/c232s/i262l/r386k、i76v/i164m/i262l、i76v/i164m/m273v、i76v/i164m/s287t/l364i、i76v/i164m/r386k、i76v/c232s、i76v/c232s/p259v/l364i、i76v/c232s/i262l、i76v/c232s/m273v/e299d/v311a/r386k、i76v/c232s/l364i/r386k、i76v/i262l、i76v/i262l/m273v、i76v/i262l/y284l/s287t/r386k、i76v/i262l/y284l/l364i、i76v/i262l/s287t、i76v/i262l/l364i、i76v/m273v、i76v/y284l/e299d、i76v/y284l/v311a/r386k、i76v/l364i、i76v/r386k、p130v、h132g、a135t/y284t、a135t/v392w、k145e/i400v、i164m/c232s/y284l/s287t、t191i、t191v、n220g、n220s/l360v、p241t、v246q、v246y、i262l/y284l/s287t、m273v/v311a/e313d/l364i、d275f、d275h、d275s、d275t、d275y、k279r、v283m、g285s、g285t、s287g、s287l、s287n、s287t、k288h、k288r、g289s、f290h、f290i、f290l、f290r、f290v、s292p、s292r、m294f、m294l、i297n、e298l、e298l/k405e、e299q、e299v、e299w、v311a、v311a/l364i/r386k、g332d、a340g、g343e、g343t、g343t/k388i、p347i、p347q、p347s、l364i、t372d、t372g、t372l、t372n、t372r、t372v、i373p、i373s、r374a、r374d、r374p、r374s、r374w、g375p、k376s、v391g、v392p和k405e,其中所述多肽序列的氨基酸位置参考seq idno:2编号。在一些实施方案中,工程化乙酸激酶包含与seq id no:2具有至少85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更多的序列同一性的多肽序列。在一些实施方案中,工程化乙酸激酶包含与seq id no:2具有至少90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更多的序列同一性的多肽序列。在一些实施方案中,工程化乙酸激酶包含与seq id no:2具有至少95%、96%、97%、98%、99%或更多的序列同一性的多肽序列。
4、在一些实施方案中,多肽序列与seq id no:4具有至少85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更多的序列同一性,并且其中工程化乙酸激酶的多肽在所述多肽序列中选自以下的一个或更多个位置处包含至少一个取代或取代集:14、14/46、14/46/47、14/46/75/293/296/342、14/46/284/342/371、14/46/293、14/50/231/283/296、14/75、14/284/371、14/310/391、14/373、22/46/296/373、22/75/342、22/231/283/373、22/283/293/296、22/296、22/296/373、22/372/373、38/283/296/373、38/296/373、40/289/372/373、46、46/47/284/293、46/47/284/390/391、46/47/284/391、46/50/54/342/373、46/50/75/373、46/50/283/296/297/373、46/50/293/296、46/50/293/297、46/284/371、46/293、46/371/390/391、47/75/284/293/371、47/284/371/391、47/293/310/371、47/342/391、50/75/283/293/296、50/75/296、50/75/373、50/231/283/342、50/231/373、50/268/289/372/373、50/283/293/296、50/283/293/342/373、50/289/372/373、50/293/296、50/372、75/284/391、75/293/296/373、75/293/342、75/293/391、75/342/371、231/283/342、231/293/296/373、231/296/342、231/342/373、283/293/296、283/293/296/342、283/296、283/296/297/342、283/296/342/373、283/296/373、283/356、284/293/310/342/371、284/293/390、284/293/390/391、284/342/371、284/342/390、284/390、289、289/372/373、293、293/296、293/296/297、293/296/342/373、293/296/373、293/342/373、293/371、293/390、296/297、296/342、310/342/391、310/371/391、342、342/371/391、371、371/390、372/373、373和390/391,其中所述多肽序列的氨基酸位置参考seq id no:4编号。在一些实施方案中,工程化乙酸激酶的多肽序列与seq id no:4具有至少85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更多的序列同一性,并且其中工程化乙酸激酶的多肽在所述多肽序列中的一个或更多个位置处包含选自以下的至少一个取代或取代集:14n、14n/46a、14n/46a/75v/293l/296v/342c、14n/46a/293l、14n/46s/47r、14n/50f/231s/283l/296s、14n/75v、14n/284t/371d、14n/373d、14s/46s/284s/342t/371g、14s/310a/391p、22h/46a/296v/373d、22h/75v/342c、22h/231s/283l/373d、22h/283l/293l/296s、22h/296s/373d、22h/296v、22n/372p/373a、38a/283l/296v/373d、38a/296v/373d、40f/289r/372p/373p、46a/50f/54a/342c/373d、46a/50f/75v/373d、46a/50f/283l/296v/297g/373d、46a/50f/293l/296v、46a/50f/293l/297g、46a/293l、46r/47r/284s/390g/391p、46r/371d/390g/391p、46s、46s/47r/284s/293l、46s/47r/284s/391p、46s/284s/371d、47r/75v/284s/293l/371g、47r/284s/371g/391p、47r/293l/310a/371d、47r/342t/391p、50f/75v/283l/293l/296t、50f/75v/296v、50f/75v/373d、50f/231s/283l/342c、50f/231s/373d、50f/268g/289r/372s/373a、50f/283l/293l/296v、50f/283l/293l/342c/373d、50f/289r/372p/373a、50f/289v/372p/373a、50f/293l/296v、50f/372p、75v/284s/391p、75v/293l/296v/373d、75v/293l/342c、75v/293l/391p、75v/342t/371d、75v/342t/371g、231s/283l/342c、231s/293l/296v/373d、231s/296v/342c、231s/342c/373d、283l/293l/296v、283l/293l/296v/342c、283l/296s/342c/373d、283l/296v、283l/296v/297g/342c、283l/296v/373d、283l/356p、284s/293l/310a/342t/371g、284s/293l/390g/391p、284s/342t/371d、284s/390g、284t/293l/390g、284t/342t/371d、284t/342t/390g、289r/372p/373p、289v、289v/372s/373a、293l、293l/296s/373d、293l/296v、293l/296v/297g、293l/296v/342c/373d、293l/296v/373d、293l/342c/373d、293l/371d、293l/390g、296v/297g、296v/342c、310a/342t/391p、310a/371g/391p、342c、342t/371d/391p、371g、371g/390g、372s/373a、372s/373p、373d和390g/391p,其中所述多肽序列的氨基酸位置参考seq id no:4编号。在一些实施方案中,工程化乙酸激酶的多肽序列与seq id no:4具有至少85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更多的序列同一性,并且其中工程化乙酸激酶的多肽在所述多肽序列中的一个或更多个位置处包含选自以下的至少一个取代或取代集:v14n、v14n/e46a、v14n/e46a/i75v/m293l/i296v/g342c、v14n/e46a/m293l、v14n/e46s/g47r、v14n/l50f/c231s/y283l/i296s、v14n/i75v、v14n/g284t/t371d、v14n/r373d、v14s/e46s/g284s/g342t/t371g、v14s/v310a/v391p、i22h/e46a/i296v/r373d、i22h/i75v/g342c、i22h/c231s/y283l/r373d、i22h/y283l/m293l/i296s、i22h/i296s/r373d、i22h/i296v、i22n/i372p/r373a、g38a/y283l/i296v/r373d、g38a/i296v/r373d、a40f/f289r/i372p/r373p、e46a/l50f/v54a/g342c/r373d、e46a/l50f/i75v/r373d、e46a/l50f/y283l/i296v/e297g/r373d、e46a/l50f/m293l/i296v、e46a/l50f/m293l/e297g、e46a/m293l、e46r/g47r/g284s/v390g/v391p、e46r/t371d/v390g/v391p、e46s、e46s/g47r/g284s/m293l、e46s/g47r/g284s/v391p、e46s/g284s/t371d、g47r/i75v/g284s/m293l/t371g、g47r/g284s/t371g/v391p、g47r/m293l/v310a/t371d、g47r/g342t/v391p、l50f/i75v/y283l/m293l/i296t、l50f/i75v/i296v、l50f/i75v/r373d、l50f/c231s/y283l/g342c、l50f/c231s/r373d、l50f/s268g/f289r/i372s/r373a、l50f/y283l/m293l/i296v、l50f/y283l/m293l/g342c/r373d、l50f/f289r/i372p/r373a、l50f/f289v/i372p/r373a、l50f/m293l/i296v、l50f/i372p、i75v/g284s/v391p、i75v/m293l/i296v/r373d、i75v/m293l/g342c、i75v/m293l/v391p、i75v/g342t/t371d、i75v/g342t/t371g、c231s/y283l/g342c、c231s/m293l/i296v/r373d、c231s/i296v/g342c、c231s/g342c/r373d、y283l/m293l/i296v、y283l/m293l/i296v/g342c、y283l/i296s/g342c/r373d、y283l/i296v、y283l/i296v/e297g/g342c、y283l/i296v/r373d、y283l/l356p、g284s/m293l/v310a/g342t/t371g、g284s/m293l/v390g/v391p、g284s/g342t/t371d、g284s/v390g、g284t/m293l/v390g、g284t/g342t/t371d、g284t/g342t/v390g、f289r/i372p/r373p、f289v、f289v/i372s/r373a、m293l、m293l/i296s/r373d、m293l/i296v、m293l/i296v/e297g、m293l/i296v/g342c/r373d、m293l/i296v/r373d、m293l/g342c/r373d、m293l/t371d、m293l/v390g、i296v/e297g、i296v/g342c、v310a/g342t/v391p、v310a/t371g/v391p、g342c、g342t/t371d/v391p、t371g、t371g/v390g、i372s/r373a、i372s/r373p、r373d和v390g/v391p,其中所述多肽序列的氨基酸位置参考seq id no:4编号。在一些实施方案中,工程化乙酸激酶包含与seq id no:4具有至少85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更多的序列同一性的多肽序列。在一些实施方案中,工程化乙酸激酶包含与seq id no:4具有至少90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更多的序列同一性的多肽序列。在一些实施方案中,工程化乙酸激酶包含与seq id no:4具有至少95%、96%、97%、98%、99%或更多的序列同一性的多肽序列。
5、在一些实施方案中,多肽序列与seq id no:4具有至少85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更多的序列同一性,并且其中工程化乙酸激酶的多肽在所述多肽序列中选自以下的一个或更多个位置处包含至少一个取代或取代集:14/38/50/75/293/296、14/342/391、38/46/50/75/373、46/293、47/342/391、50/75/283/293/296、50/75/296、50/103/296/342、50/231/373、50/268/289/372/373、50/283/293/296、50/283/293/342/373、50/293、50/293/296、50/372/373、75/283/296、75/293/296/297、75/293/391、75/342/371、75/390/391、283/296、289、289/372、289/372/373、293/342/373、293/342/391、293/371、296、296/342、310/342/391、342、372和372/373,其中所述多肽序列的氨基酸位置参考seq id no:4编号。在一些实施方案中,工程化乙酸激酶的多肽序列与seq id no:4具有至少85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更多的序列同一性,并且其中工程化乙酸激酶的多肽在所述多肽序列中的一个或更多个位置处包含选自以下的至少一个取代或取代集:14n/38a/50f/75v/293l/296s、14n/342t/391p、38a/46a/50f/75v/373d、46a/293l、47r/342t/391p、50f/75v/283l/293l/296t、50f/75v/296v、50f/103a/296t/342c、50f/231s/373d、50f/268g/289r/372s/373a、50f/283l/293l/296v、50f/283l/293l/342c/373d、50f/293l、50f/293l/296v、50f/372s/373a、75v/283l/296s、75v/293l/296s/297g、75v/293l/391p、75v/342t/371d、75v/390g/391p、283l/296v、289r/372p/373p、289r/372s、289v、289v/372s/373a、293l/342c/373d、293l/342t/391p、293l/371d、296v、296v/342c、310a/342t/391p、342c、342t、372p和372s/373a,其中所述多肽序列的氨基酸位置参考seq idno:4编号。在一些实施方案中,工程化乙酸激酶的多肽序列与seq id no:4具有至少85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更多的序列同一性,并且其中工程化乙酸激酶的多肽在所述多肽序列中的一个或更多个位置处包含选自以下的至少一个取代或取代集:v14n/g38a/l50f/i75v/m293l/i296s、v14n/g342t/v391p、g38a/e46a/l50f/i75v/r373d、e46a/m293l、g47r/g342t/v391p、l50f/i75v/y283l/m293l/i296t、l50f/i75v/i296v、l50f/g103a/i296t/g342c、l50f/c231s/r373d、l50f/s268g/f289r/i372s/r373a、l50f/y283l/m293l/i296v、l50f/y283l/m293l/g342c/r373d、l50f/m293l、l50f/m293l/i296v、l50f/i372s/r373a、i75v/y283l/i296s、i75v/m293l/i296s/e297g、i75v/m293l/v391p、i75v/g342t/t371d、i75v/v390g/v391p、y283l/i296v、f289r/i372p/r373p、f289r/i372s、f289v、f289v/i372s/r373a、m293l/g342c/r373d、m293l/g342t/v391p、m293l/t371d、i296v、i296v/g342c、v310a/g342t/v391p、g342c、g342t、i372p和i372s/r373a,其中所述多肽序列的氨基酸位置参考seq id no:4编号。在一些实施方案中,工程化乙酸激酶包含与seq id no:4具有至少85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更多的序列同一性的多肽序列。在一些实施方案中,工程化乙酸激酶包含与seq id no:4具有至少90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更多的序列同一性的多肽序列。在一些实施方案中,工程化乙酸激酶包含与seq id no:4具有至少95%、96%、97%、98%、99%或更多的序列同一性的多肽序列。
6、在一些另外的实施方案中,本发明提供了工程化乙酸激酶,其中工程化乙酸激酶包含与表2-1、表3-1、表4-1和/或表5-1中列出的至少一种工程化乙酸激酶变体的序列至少85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更多相同的多肽序列。
7、在一些另外的实施方案中,本发明提供了工程化乙酸激酶,其中工程化乙酸激酶包含与seq id no:2和/或4至少85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更多相同的多肽序列。在一些实施方案中,工程化乙酸激酶包含seq id no:4中列出的变体工程化乙酸激酶。
8、本发明还提供了工程化乙酸激酶,其中工程化乙酸激酶包含与seq id no:4-550中偶数编号的序列中列出的至少一种工程化乙酸激酶变体的序列至少85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更多相同的多肽序列。
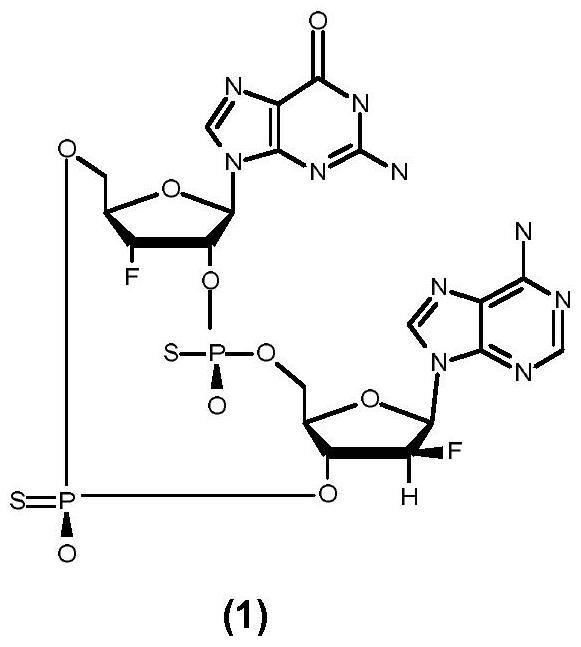
9、本发明还提供了工程化乙酸激酶,其中所述工程化乙酸激酶与野生型海栖热袍菌(thermotoga maritima)乙酸激酶相比包含至少一种改进的性质。在一些实施方案中,改进的性质包括改进的对底物的活性。在一些另外的实施方案中,底物包括sp-3’氟-3’-脱氧鸟苷-5’-(1-硫代)-二磷酸(f-thiogdp或化合物(7))和/或sp-2’f-ara-腺苷-5’-(1-硫代)-二磷酸(f-thioadp或化合物(5))。在一些另外的实施方案中,改进的性质包括改进的sp-3’氟-3’-脱氧鸟苷-5’-(1-硫代)-三磷酸(f-thiogtp或化合物(2))和/或sp-2’f-ara-腺苷-5’-(1-硫代)-三磷酸(f-thioatp或化合物(3))的产生。在又一些另外的实施方案中,工程化乙酸激酶是纯化的。本发明还提供了组合物,所述组合物包含本文提供的至少一种工程化乙酸激酶。
10、本发明还提供了多核苷酸序列,所述多核苷酸序列编码本文提供的至少一种工程化乙酸激酶。在一些实施方案中,编码至少一种工程化乙酸激酶的多核苷酸序列包括与seqid no:1和/或3具有至少85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更多的序列同一性的多核苷酸序列。在一些实施方案中,编码至少一种工程化乙酸激酶的多核苷酸序列包括与seq id no:1和/或3具有至少85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更多的序列同一性的多核苷酸序列,其中所述工程化乙酸激酶的多核苷酸序列在一个或更多个位置处包含至少一个取代。在一些另外的实施方案中,编码至少一种工程化乙酸激酶或其功能片段的多核苷酸序列包含与seq id no:1和/或3的至少85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更多的序列同一性。在又一些另外的实施方案中,多核苷酸序列可操作地连接至控制序列。在一些另外的实施方案中,多核苷酸序列是密码子优化的。在又一些另外的实施方案中,多核苷酸序列包括seq id no:3-549中奇数编号的序列中列出的多核苷酸序列。
11、本发明还提供了表达载体,所述表达载体包含至少一种本文提供的多核苷酸序列。本发明还提供了包含至少一种本文提供的表达载体的宿主细胞。在一些实施方案中,本发明提供了包含本文提供的至少一种多核苷酸序列的宿主细胞。
12、本发明还提供了在宿主细胞中产生工程化乙酸激酶的方法,所述方法包括在合适的条件下培养本文提供的宿主细胞,从而产生至少一种工程化乙酸激酶。在一些实施方案中,方法还包括从培养物和/或宿主细胞回收至少一种工程化乙酸激酶。在一些另外的实施方案中,方法还包括纯化所述至少一种工程化乙酸激酶的步骤。
13、发明描述
14、本发明提供了工程化乙酸激酶(ack)、具有ack活性的多肽和编码这些酶的多核苷酸、以及载体和包含这些多核苷酸和多肽的宿主细胞。还提供了用于产生ack酶的方法。本发明还提供了包含ack酶的组合物,以及使用工程化ack酶的方法。本发明尤其可用于药物化合物的产生。
15、除非另外定义,否则本文使用的所有技术和科学术语通常具有与本发明所属领域普通技术人员通常理解的相同的含义。通常,本文使用的命名法和下文描述的细胞培养、分子遗传学、微生物学、有机化学、分析化学和核酸化学中的实验程序是本领域熟知的并且普遍地采用的那些。这样的技术是熟知的,并且在本领域技术人员熟知的许多教科书和参考著作中进行了描述。对于化学合成和化学分析使用了标准技术或其修改形式。本文(上文和下文两者)提及的所有专利、专利申请、文章和出版物,特此通过引用明确并入本文。
16、尽管本发明的实践中可使用类似或等同于本文描述的那些的任何合适的方法和材料,本文描述了一些方法和材料。应理解本发明不限于所描述的特定方法、方案和试剂,因为这些可以根据本领域技术人员使用它们的情况而改变。因此,下文即将定义的术语通过参考本发明作为整体而被更充分地描述。
17、应理解,上文的一般描述和下文的详细描述仅是示例性的和说明性的,而不是限制本发明。本文使用的章节标题仅用于组织目的,并且不被解释为限制所描述的主题。数值范围包括限定该范围的数字。因此,本文公开的每个数值范围意图包括落在这样的较宽数值范围内的每一较窄数值范围,如同这样的较窄数值范围在本文被全部清楚地写出。还意图本文公开的每个最大的(或最小的)数值限制包含每个较低(或较高)的数值限制,如同此类较低(或较高)数值限制在本文被清楚地写出。
18、缩写和定义
19、用于遗传编码的氨基酸的缩写是常规的,并且如下:丙氨酸(ala或a)、精氨酸(arg或r)、天冬酰胺(asn或n)、天冬氨酸(asp或d)、半胱氨酸(cys或c)、谷氨酸(glu或e)、谷氨酰胺(gln或q)、组氨酸(his或h)、异亮氨酸(ile或i)、亮氨酸(leu或l)、赖氨酸(lys或k)、甲硫氨酸(met或m)、苯丙氨酸(phe或f)、脯氨酸(pro或p)、丝氨酸(ser或s)、苏氨酸(thr或t)、色氨酸(trp或w)、酪氨酸(tyr或y)和缬氨酸(val或v)。
20、当使用三字母缩写时,除非前面具体地有“l”或“d”,或者从使用缩写的上下文清楚看出,否则氨基酸可以是关于α-碳(cα)的l-构型或d-构型。例如,“ala”表示丙氨酸而不指定关于α-碳的构型,而“d-ala”和“l-ala”分别表示d-丙氨酸和l-丙氨酸。当使用单字母缩写时,大写字母表示关于α-碳的l-构型的氨基酸,并且小写字母表示关于α-碳的d-构型的氨基酸。例如,“a”表示l-丙氨酸并且“a”表示d-丙氨酸。当多肽序列以一串单字母或三字母缩写(或其混合)呈现时,根据常规惯例将序列呈现为氨基(n)至羧基(c)方向。
21、用于遗传编码核苷的缩写是常规的并且如下:腺苷(a);鸟苷(g);胞苷(c);胸苷(t);和尿苷(u)。除非具体描述,否则缩写的核苷可以是核糖核苷或2’-脱氧核糖核苷。核苷可以单独地或总体地指定为核糖核苷或2’-脱氧核糖核苷。当核酸序列以单字母缩写串呈现时,序列按照常规惯例呈现为5’至3’方向,并且不示出磷酸。
22、参考本发明,本文描述中使用的技术和科学术语将具有本领域普通技术人员通常理解的含义,除非另有具体定义。因此,以下术语旨在具有以下含义。
23、除非上下文另外清楚地指示,否则如本文使用的单数形式“一(a)”、“一(an)”和“该(the)”包括复数指代物。因此,例如对“多肽(a polypeptide)”的提及包括多于一种多肽。
24、类似地,“包括(comprise)”、“包括(comprises)”、“包括(comprising)”、“包括(include)”、“包括(includes)”和“包括(including)”是可互换的,而不意图是限制性的。因此,如本文使用的,术语“包含(comprising)”及其同根词以其包含性含义被使用(即,等同于术语“包括(including)”及其相应的同根词)。
25、还应当理解,在各种实施方案的描述中使用术语“包含(comprising)”的情况下,本领域技术人员将理解,在一些特定情况下,可以使用“基本上由...组成(consistingessentially of)”或“由...组成(consisting of)”的语言可选择地描述实施方案。
26、如本文使用的,术语“约”意指特定值的可接受误差。在一些情况下,“约”意指在给定值范围的0.05%、0.5%、1.0%或2.0%内。在一些情况下,“约”意指在给定值的1、2、3或4个标准偏差内。
27、如本文使用的,“ec”编号是指生物化学和分子生物学国际联合命名委员会(nomenclature committee of the international union of biochemistry andmolecular biology)(nc-iubmb)的酶命名法。该iubmb生化分类是基于酶催化的化学反应的酶数字分类系统。
28、如本文使用的,“atcc”是指美国典型培养物保藏中心(american type culturecollection),其生物保藏收集物包括基因和菌株。
29、如本文使用的,“ncbi”是指美国国家生物信息中心(national center forbiological information)和其中提供的序列数据库。
30、如本文使用的,“乙酸激酶(“ack”)酶(ec 2.7.2.1)是能够使用乙酰磷酸或另一种磷酰基基团供体催化核苷二磷酸(或其类似物)磷酸化为核苷三磷酸(或其类似物)的酶。乙酸激酶包括本公开内容的工程化多肽,其能够使用乙酰磷酸作为磷酸供体,分别催化f-thioadp(5)和f-thiogdp(7)转化为f-thioatp(3)和f-thiogtp(2)。如本领域已知的,乙酸激酶可以是天然存在的野生型酶,也可以是通过人类干预操纵或合成的工程化酶。乙酸激酶可以是或可以来源于主要在原核生物中发现的天然存在的野生型基本代谢酶,其在存在atp的情况下催化乙酸磷酸化为乙酰辅酶a。
31、“蛋白”、“多肽”和“肽”在本文中可互换地使用,来表示通过酰胺键共价连接的至少两个氨基酸的聚合物,而不论长度或翻译后修饰(例如糖基化或磷酸化)如何。该定义中包括d-氨基酸和l-氨基酸、以及d-氨基酸和l-氨基酸的混合物、以及包含d-氨基酸和l-氨基酸以及d-氨基酸和l-氨基酸的混合物的聚合物。
32、“氨基酸”通过其通常已知的三字母符号或通过iupac-iub生物化学命名委员会推荐的单字母符号在本文被提及。同样地,核苷酸可以通过其通常可接受的单字母代码被提及。
33、如本文使用的,“亲水性氨基酸或残基”是指具有根据eisenberg等人的归一化共有疏水性量表(normalized consensus hydrophobicity scale)表现出小于零的疏水性的侧链的氨基酸或残基(eisenberg等人,j.mol.biol.,179:125-142[1984])。遗传编码的亲水性氨基酸包括l-thr(t)、l-ser(s)、l-his(h)、l-glu(e)、l-asn(n)、l-gln(q)、l-asp(d)、l-lys(k)和l-arg(r)。
34、如本文使用的,“酸性氨基酸或残基”是指当氨基酸被包含在肽或多肽中时,具有表现出小于约6的pka值的侧链的亲水氨基酸或残基。由于失去氢离子,酸性氨基酸在生理ph通常具有带负电荷的侧链。遗传编码的酸性氨基酸包括l-glu(e)和l-asp(d)。
35、如本文使用的,“碱性氨基酸或残基”是指当氨基酸被包含在肽或多肽中时,具有表现出大于约6的pka值的侧链的亲水氨基酸或残基。由于与水合氢离子的缔合,碱性氨基酸在生理ph通常具有带正电荷的侧链。遗传编码的碱性氨基酸包括l-arg(r)和l-lys(k)。
36、如本文使用的,“极性氨基酸或残基”是指具有在生理ph不带电荷但具有其中两个原子共同共有的电子对被其中一个原子更紧密地保持(held more closely)的至少一个键的侧链的亲水氨基酸或残基。遗传编码的极性氨基酸包括l-asn(n)、l-gln(q)、l-ser(s)和l-thr(t)。
37、如本文使用的,“疏水性氨基酸或残基”是指具有根据eisenberg等人的归一化共有疏水性量表表现出大于零的疏水性的侧链的氨基酸或残基(eisenberg等人,j.mol.biol.,179:125-142[1984])。遗传编码的疏水性氨基酸包括l-pro(p)、l-ile(i)、l-phe(f)、l-val(v)、l-leu(l)、l-trp(w)、l-met(m)、l-ala(a)和l-tyr(y)。
38、如本文使用的,“芳香族氨基酸或残基”是指具有包含至少一个芳香族环或杂芳香族环的侧链的亲水或疏水氨基酸或残基。遗传编码的芳香族氨基酸包括l-phe(f)、l-tyr(y)和l-trp(w)。尽管l-his(h)由于其杂芳族氮原子的pka有时被归类为碱性残基,或因为其侧链包括杂芳族环而被归类为芳族残基;但在本文中,组氨酸被归类为亲水残基或为“受限残基(constrained residue)”(参见下文)。
39、如本文使用的,“受限氨基酸或残基”是指具有受限几何形状的氨基酸或残基。本文中,受限残基包括l-pro(p)和l-his(h)。组氨酸具有受限的几何形状,因为它具有相对小的咪唑环。脯氨酸具有受限的几何形状,因为它也具有五元环。
40、如本文使用的,“非极性氨基酸或残基”是指具有在生理ph不带电荷并具有其中两个原子共同共有的电子对通常由两个原子各自同等地保持的键的侧链(即侧链不是极性的)的疏水氨基酸或残基。遗传编码的非极性氨基酸包括l-gly(g)、l-leu(l)、l-val(v)、l-ile(i)、l-met(m)和l-ala(a)。
41、如本文使用的,“脂肪族氨基酸或残基”是指具有脂肪族烃侧链的疏水氨基酸或残基。遗传编码的脂肪族氨基酸包括l-ala(a)、l-val(v)、l-leu(l)和l-ile(i)。应注意,半胱氨酸(或“l-cys”或“[c]”)之所以与众不同,是因为它可以与其他l-cys(c)氨基酸或其他含硫烷基(sulfanyl)或巯基(sulfhydryl)氨基酸形成二硫桥。“半胱氨酸样残基”包括半胱氨酸和含有可用于形成二硫桥的巯基部分的其他氨基酸。l-cys(c)(和具有含-sh侧链的其他氨基酸)以还原的游离-sh或氧化的二硫桥的形式存在于肽中的能力影响l-cys(c)是否向肽贡献净的疏水特征或亲水特征。虽然根据eisenberg的归一化共有标度(eisenberg等人,1984年,上文),l-cys(c)表现出0.29的疏水性,但是应当理解,为了本公开内容的目的,l-cys(c)被分类为其自身独特的组。
42、如本文使用的,“小氨基酸或残基”是指具有包括总计三个或更少的碳原子和/或杂原子(不包括α-碳和氢)的侧链的氨基酸或残基。根据上文的定义,小氨基酸或残基可以被进一步分类为脂肪族、非极性、极性或酸性小氨基酸或残基。遗传编码的小氨基酸包括l-ala(a)、l-val(v)、l-cys(c)、l-asn(n)、l-ser(s)、l-thr(t)和l-asp(d)。
43、如本文使用的,“含羟基的氨基酸或残基”是指含有羟基(-oh)部分的氨基酸。遗传编码的含羟基的氨基酸包括l-ser(s)、l-thr(t)和l-tyr(y)。
44、如本文使用的,“多核苷酸”和“核酸”是指共价连接在一起的两个或更多个核苷酸。多核苷酸可以完全包含核糖核苷酸(即rna)、完全包含2’脱氧核糖核苷酸(即dna)或包含核糖核苷酸和2’脱氧核糖核苷酸的混合物。虽然核苷通常将经由标准磷酸二酯键连接在一起,但多核苷酸可以包含一个或更多个非标准键。多核苷酸可以是单链或双链的,或者可以包含单链区域和双链区域二者。此外,虽然多核苷酸通常包含天然存在的编码核碱基(即腺嘌呤、鸟嘌呤、尿嘧啶、胸腺嘧啶和胞嘧啶),它可以包含一种或更多种经修饰的和/或合成的核碱基,诸如例如肌苷、黄嘌呤、次黄嘌呤等。在一些实施方案中,这样的经修饰的或合成的核碱基是编码氨基酸序列的核碱基。
45、如本文使用的,“核苷”是指包含核碱基(即含氮碱基)和5-碳糖(例如核糖或脱氧核糖)的糖基胺。核苷的非限制性实例包括胞苷、尿苷、腺苷、鸟苷、胸苷和肌苷。相比之下,术语“核苷酸”是指包含核碱基、5-碳糖和一个或更多个磷酸基团的糖基胺。在一些实施方案中,核苷可以被激酶磷酸化以产生核苷酸。
46、如本文使用的,“核苷二磷酸”是指包含核碱基(即含氮碱基)、5-碳糖(例如核糖或脱氧核糖)和二磷酸(即焦磷酸)部分的糖基胺。在本文的一些实施方案中,“核苷二磷酸”缩写为“ndp”。核苷二磷酸的非限制性实例包括胞苷二磷酸(cdp)、尿苷二磷酸(udp)、腺苷二磷酸(adp)、鸟苷二磷酸(gdp)、胸苷二磷酸(tdp)和肌苷二磷酸(idp)。在一些实施方案中,“核苷二磷酸”可以指非天然核苷二磷酸,诸如化合物(5)。在一些情形中,术语“核苷”和“核苷酸”可互换使用。
47、如本文使用的,“核苷三磷酸”是指包含核碱基(即含氮碱基)、5-碳糖(例如核糖或脱氧核糖)和三磷酸部分的糖基胺。在本文的一些实施方案中,“核苷三磷酸”缩写为“ntp”。核苷三磷酸的非限制性实例包括胞苷三磷酸(ctp)、尿苷三磷酸(utp)、腺苷三磷酸(atp)、鸟苷三磷酸(gtp)、胸苷三磷酸(ttp)和肌苷三磷酸(itp)。在一些实施方案中,“核苷三磷酸”可以指非天然核苷三磷酸,诸如化合物(2)和/或化合物(3)。在一些情形中,术语“核苷”和“核苷酸”可互换使用。
48、如本文使用的,“编码序列”是指核酸(例如基因)编码蛋白的氨基酸序列的部分。
49、如本文使用的,术语“生物催化(biocatalysis)”、“生物催化(biocatalytic)”、“生物转化”和“生物合成”是指使用酶来对有机化合物进行化学反应。
50、如本文使用的,“野生型”和“天然存在的”指在自然界中发现的形式。例如,野生型多肽或多核苷酸序列为生物体中存在的序列,其可从天然来源分离且未通过人为操作被有意识地修饰。
51、如本文使用的,当关于细胞、核酸或多肽使用时,“重组”、“工程化”、“变体”、“非天然”和“非天然存在的”是指已经以自然界原本不存在的方式修饰的材料或相应于该材料的天然或自然形式的材料。在一些实施方案中,该细胞、核酸或多肽与天然存在的细胞、核酸或多肽相同,但由合成材料和/或通过使用重组技术操纵产生或衍生。非限制性实例包括,除其他以外,表达自然(非重组)形式的细胞中未发现的基因或表达原本以不同水平表达的自然基因的重组细胞。
52、术语“序列同一性百分比(%)”在本文中用于指多核苷酸或多肽之间的比较,并通过比较比较窗中两条最佳对齐的序列确定,其中多核苷酸或多肽序列在比较窗中的部分与参考序列相比可以包含添加或缺失(即,空位),以用于两个序列的最佳对齐。百分比可以通过如下计算:确定两个序列中出现相同核酸碱基或氨基酸残基的位置的数目以产生匹配位置的数目,将匹配位置的数目除以比较窗中位置的总数目,并将结果乘以100以得到序列同一性的百分比。可选地,百分比可以通过如下计算:确定两个序列中出现相同的核酸碱基或氨基酸残基或者核酸碱基或氨基酸残基与空位对齐的位置的数目以产生匹配位置的数目,将匹配位置的数目除以比较窗中位置的总数目,并将结果乘以100以得到序列同一性的百分比。本领域技术人员理解,存在许多可用于比对两个序列的已建立的算法。用于比较的序列的最佳比对可以通过任何合适的方法进行,包括但不限于smith和waterman的局部同源性算法(smith和waterman,adv.appl.math.,2:482[1981]),通过needleman和wunsch的同源性比对算法(needleman和wunsch,j.mol.biol.,48:443[1970]),通过pearson和lipman的相似性搜索方法(pearson和lipman,proc.natl.acad.sci.usa85:2444[1988]),通过这些算法的计算机化实现(例如,gcg wisconsin软件包中的gap、bestfit、fasta和tfasta),或者通过目视检查,如本领域已知的。适用于确定序列同一性和序列相似性百分比的算法的实例包括但不限于blast和blast 2.0算法,由altschul等人描述(分别参见altschul等人,j.mol.biol.,215:403-410[1990];和altschul等人,nucl.acids res.,3389-3402[1977])。公众可通过美国国家生物技术信息中心网站获得用于进行blast分析的软件。该算法包括首先通过鉴定查询序列中长度w的短字来鉴定高评分序列对(hsp),所述短字在与数据库序列中相同长度的字比对时匹配或满足某一正值的阀值评分t。t被称为邻近字评分阈值(参见,altschul等人,上文)。这些最初的邻近字击中(word hit)充当启动搜索的种子以找到包含它们的更长hsp。然后字击中沿着每个序列的两个方向延伸直到累积比对评分不能增加的程度。对于核苷酸序列,累积评分使用参数m(用于匹配残基对的奖励评分;总是>0)和n(用于错配残基的惩罚评分;总是<0)计算。对于氨基酸序列,评分矩阵用于计算累积评分。在以下情况时,停止字击中在每一个方向的延伸:累积比对评分从其最大达到值下降了量x;由于累积了一个或更多个负评分残基比对,累积评分达到0或小于0;或到达任一序列末端。blast算法参数w、t和x决定比对的灵敏度和速度。blastn程序(对于核苷酸序列)使用以下作为默认值:字长(w)为11、期望值(e)为10、m=5、n=-4、以及两条链的比较。对于氨基酸序列,blastp程序使用以下作为默认值:字长(w)为3,期望(e)为10和blosum62评分矩阵(参见,henikoff和henikoff,proc.natl.acad.sci.usa89:10915[1989])。序列比对与%序列同一性的示例性确定可以使用gcg wisconsin软件包(accelrys,madison wi)中的bestfit或gap程序,使用提供的默认参数。
53、如本文使用的,“参考序列”是指用作序列和/或活性比较的基础的定义序列。参考序列可以是更大序列的子集,例如,全长基因或多肽序列的区段。通常,参考序列为至少20个核苷酸或氨基酸残基的长度、至少25个残基的长度、至少50个残基的长度、至少100个残基的长度或核酸或多肽的全长。因为两个多核苷酸或多肽可以各自(1)包含在两个序列之间相似的序列(即,完整序列的一部分),和(2)可以还包含在两个序列之间趋异的(divergent)序列,所以两个(或更多个)多核苷酸或多肽之间的序列比较通常通过比较两个多核苷酸或多肽在“比较窗”上的序列以鉴定和比较局部区域的序列相似性来进行。在一些实施方案中,“参考序列”可以基于一级氨基酸序列,其中参考序列是可以在一级序列中具有一个或更多个变化的序列。
54、如本文使用的,“比较窗”是指至少约20个连续核苷酸位置或氨基酸残基的概念性区段,其中序列可以与至少20个连续核苷酸或氨基酸的参考序列进行比较,并且其中序列在比较窗中的部分与参考序列(其不包含添加或缺失)相比,可以包含20%或更少的添加或缺失(即,空位)以用于两个序列的最佳比对。比较窗可以比20个连续残基更长,并任选地包括30、40、50、100或更长的窗。
55、如本文使用的,当在对给定氨基酸或多核苷酸序列进行编号的情况中使用时,“对应于”、“参考”和“相对于”是指当给定氨基酸或多核苷酸序列与参考序列相比较时对指定参考序列的残基进行编号。换言之,给定聚合物的残基编号或残基位置关于参考序列被指定,而不是通过给定氨基酸或多核苷酸序列内残基的实际数字位置被指定。例如,给定氨基酸序列,诸如工程化乙酸激酶的氨基酸序列可以通过引入空位以与参考序列对齐,来优化两个序列之间的残基匹配。在这些情况中,尽管存在空位,对给定氨基酸或多核苷酸序列中的残基关于与其比对的参考序列进行编号。
56、如本文使用的,“大体同一性”是指在至少20个残基位置的比较窗中、通常在至少30个-50个残基窗中,与参考序列相比,具有至少80%序列同一性、至少85%同一性、至少89%至95%之间序列同一性,或更通常至少99%序列同一性的多核苷酸或多肽序列,其中序列同一性的百分比通过在比较窗上比较参考序列和包含总计为参考序列的20%或更少的缺失或添加的序列来计算。在应用于多肽的一些具体实施方案中,术语“大体同一性”意指当诸如通过程序gap或bestfit使用默认空位权重进行最佳比对时,两个多肽序列共享至少80%的序列同一性,优选地至少89%的序列同一性、至少95%的序列同一性或更高(例如,99%的序列同一性)。在一些实施方案中,在所比较的序列中不相同的残基位置因保守氨基酸取代而不同。
57、如本文使用的,“氨基酸差异”、“残基差异”和“取代”是指在多肽序列的一个位置处氨基酸残基相对于参考序列中对应位置处的氨基酸残基的差异。本文中氨基酸差异的位置通常被称为“xn”,其中n是指残基差异所基于的参考序列中的对应位置。例如,“与seq idno:4相比位置x93处的残基差异”是指对应于seq id no:4的位置93的多肽位置处的氨基酸残基的差异。因此,如果参考多肽seq id no:4在位置93处具有丝氨酸,则“与seq id no:4相比位置x93处的残基差异”是指在对应于seq id no:4的位置93的多肽位置处的除了丝氨酸以外的任何残基的氨基酸取代。在本文的大多数实例中,在一个位置处的具体氨基酸残基差异指示为“xny”,其中“xn”指定如上文描述的对应位置,并且“y”是在工程化多肽中发现的氨基酸(即,与参考多肽中不同的残基)的单字母标识符。在一些情况下(例如,在实施例中呈现的表格中),本发明还提供由常规符号“anb”表示的具体氨基酸差异,其中a为参考序列中的残基的单字母标识符,“n”为参考序列中的残基位置的编号,并且b为工程化多肽的序列中残基取代的单字母标识符。在一些情况下,氨基酸残基差异或取代可以是缺失,并且可以用“-”表示(例如xn-或h4-表示位置4处的组氨酸的缺失。任何这样的缺失都会影响缺失后的残基相对于它们在序列表中的位置的编号。使用h4-的实例,x3处的残基仍将在位置3处被发现,但位置x5处的残基现在将在序列表的位置4处被发现)。在一些情况下,本发明的多肽可以相对于参考序列包含一个或更多个氨基酸残基差异,其由相对于参考序列存在残基差异的一列指定位置指示。在一些实施方案中,在多于一个氨基酸可以用于多肽的具体残基位置中时,可以使用的各种氨基酸残基由“/”分开(例如,x307h/x307p或x307h/p)。斜线也可用于指示给定变体内的多于一个取代(即,在给定序列中诸如在组合变体中存在多于一个取代)。在一些实施方案中,本发明包括含有一个或更多个氨基酸差异的工程化多肽序列,所述氨基酸差异包括保守氨基酸取代或非保守氨基酸取代。在一些另外的实施方案中,本发明提供了包含保守氨基酸取代和非保守氨基酸取代二者的工程化多肽序列。
58、如本文使用的,“保守氨基酸取代”是指用具有相似侧链的不同残基取代残基,并且因此通常包括用相同或相似的氨基酸定义类别中的氨基酸取代多肽中的氨基酸。例如但不限于,在一些实施方案中,具有脂肪族侧链的氨基酸被另一种脂肪族氨基酸(例如,丙氨酸、缬氨酸、亮氨酸和异亮氨酸)取代;具有羟基侧链的氨基酸被另一种具有羟基侧链的氨基酸(例如,丝氨酸和苏氨酸)取代;具有芳香族侧链的氨基酸被另一种具有芳香族侧链的氨基酸(例如,苯丙氨酸、酪氨酸、色氨酸和组氨酸)取代;具有碱性侧链的氨基酸被另一种具有碱性侧链的氨基酸(例如,赖氨酸和精氨酸)取代;具有酸性侧链的氨基酸被另一种具有酸性侧链的氨基酸(例如,天冬氨酸或谷氨酸)取代;和/或疏水氨基酸或亲水氨基酸分别被另一种疏水氨基酸或亲水氨基酸取代。
59、如本文使用的,“非保守取代”是指用具有显著不同的侧链性质的氨基酸取代多肽中的氨基酸。非保守取代可以使用定义的组之间而不是之内的氨基酸,并且影响(a)取代区域中的肽主链的结构(例如,脯氨酸取代甘氨酸),(b)电荷或疏水性,或(c)侧链体积。例如但不限于,示例性非保守取代可以是用碱性或脂肪族氨基酸取代酸性氨基酸;用小氨基酸取代芳香族氨基酸;和用疏水氨基酸取代亲水氨基酸。
60、如本文使用的,“缺失”是指通过从参考多肽去除一个或更多个氨基酸对多肽进行的修饰。缺失可以包括去除1个或更多个氨基酸、2个或更多个氨基酸、5个或更多个氨基酸、10个或更多个氨基酸、15个或更多个氨基酸或者20个或更多个氨基酸、多达组成参考酶的氨基酸总数的10%、或多达氨基酸总数的20%,同时保留酶活性和/或保留工程化乙酸激酶的改进的性质。缺失可以涉及多肽的内部部分和/或末端部分。在各种实施方案中,缺失可以包括连续的区段或可以是不连续的。氨基酸序列中的缺失通常用“-”表示。
61、如本文使用的,“插入”是指通过将一个或更多个氨基酸添加到参考多肽对多肽进行的修饰。插入可以处于多肽的内部部分或者可以是插入到羧基或氨基末端。如本文使用的插入包括如本领域已知的融合蛋白。插入可以是氨基酸的连续区段或由天然存在的多肽中的一个或更多个氨基酸隔开。
62、术语“氨基酸取代集”或“取代集”是指与参考序列相比,多肽序列中的一组氨基酸取代。取代集可以具有1个、2个、3个、4个、5个、6个、7个、8个、9个、10个、11个、12个、13个、14个、15个或更多个氨基酸取代。在一些实施方案中,取代集是指在实施例中提供的表格中列出的任何变体乙酸激酶中存在的氨基酸取代的集合。
63、“功能片段”和“生物活性片段”在本文可互换使用,指如下多肽:所述多肽具有氨基末端缺失和/或羧基末端缺失和/或内部缺失,但其中剩余的氨基酸序列与和它进行比较的序列(例如,本发明的全长工程化乙酸激酶)中的对应位置相同,并且保留全长多肽的基本上全部活性。
64、如本文使用的,“分离的多肽”是指与其天然伴随的其他污染物(例如蛋白质、脂质和多核苷酸)基本上分开的多肽。该术语包括已经从它们天然存在的环境或表达系统(例如,宿主细胞内或经由体外合成)中取出或纯化的多肽。重组乙酸激酶多肽可以存在于细胞内、存在于细胞培养基中,或以各种形式(诸如裂解物或分离的制品)制备。因此,在一些实施方案中,重组乙酸激酶多肽可以是分离的多肽。
65、如本文使用的,“基本上纯的多肽”或“纯化的蛋白”是指如下组合物,在所述组合物中多肽物质是存在的主要物质(即,在摩尔或重量基础上,它比该组合物中的任何其他单独的大分子物质更丰富),并且当目标物质构成存在的大分子物质的按摩尔或%重量计至少约50%时,通常是基本上纯化的组合物。然而,在一些实施方案中,包含乙酸激酶的组合物包含纯度低于50%(例如,约10%、约20%、约30%、约40%或约50%)的乙酸激酶。通常,基本上纯的乙酸激酶组合物构成该组合物中存在的所有大分子物质的按摩尔或%重量计约60%或更多、约70%或更多、约80%或更多、约90%或更多、约95%或更多以及约98%或更多。在一些实施方案中,将目标物质纯化至基本同质(即,通过常规检测方法不能在组合物中检测出污染物物质),其中该组合物基本上由单一大分子物质组成。溶剂物质、小分子(<500道尔顿)和元素离子物质不被认为是大分子物质。在一些实施方案中,分离的重组乙酸激酶多肽是基本上纯的多肽组合物。
66、如本文使用的,“改进的酶性质”是指酶的至少一种改进的性质。在一些实施方案中,本发明提供了与参考乙酸激酶多肽和/或野生型乙酸激酶多肽和/或另一种工程化乙酸激酶多肽相比显示出任何酶性质的改进的工程化乙酸激酶多肽。因此,“改进”的水平可以在各种乙酸激酶多肽、包括野生型以及工程化乙酸激酶之间进行确定和比较。改进的性质包括但不限于诸如以下的性质:增加的蛋白表达、增加的热活性(thermoactivity)、增加的热稳定性、增加的ph活性、增加的稳定性、增加的酶活性、增加的底物特异性或亲和力、增加的比活性、增加的对底物或终产物抑制的抗性、增加的化学稳定性、改进的化学选择性、改进的溶剂稳定性、增加的对酸性ph的耐受性、增加的对蛋白水解活性的耐受性(即,降低的对蛋白水解的敏感性)、降低的聚集、增加的溶解度和改变的温度谱(temperatureprofile)。在另外的实施方案中,该术语用于指乙酸激酶的至少一种改进的性质。在一些实施方案中,本发明提供了与参考乙酸激酶多肽和/或野生型乙酸激酶多肽和/或另一种工程化乙酸激酶多肽相比显示出任何酶性质的改进的乙酸激酶多肽。因此,“改进”的水平可以在各种乙酸激酶多肽、包括野生型以及工程化乙酸激酶之间进行确定和比较。
67、如本文使用的,“增加的酶活性”和“增强的催化活性”是指工程化多肽的改进的性质,可以被表示为与参考酶相比,比活性(例如产生的产物/时间/重量蛋白)的增加或将底物转化为产物的转化百分比(例如使用指定量的酶,在指定的时间段内将起始量的底物转化为产物的转化百分比)的增加。在一些实施方案中,这些术语指本文提供的工程化乙酸激酶多肽的改进的性质,其可以通过与参考乙酸激酶相比的比活性(例如,产生的产物/时间/重量蛋白)的增加或底物转化为产物的转化百分比(例如使用指定量的乙酸激酶,在指定时间段内起始量的底物转化为产物的转化百分比)的增加来表示。在一些实施方案中,这些术语用于指本文提供的改进的乙酸激酶。在实施例中提供了确定本发明的工程化乙酸激酶的酶活性的示例性方法。与酶活性相关的任何性质都可以被影响,包括典型的酶性质km、vmax或kcat,其变化可以导致酶活性的增加。例如,酶活性的改进可以是对应野生型酶的酶活性的约1.1倍到相比于天然存在的乙酸激酶或乙酸激酶多肽所源自的另一种工程化乙酸激酶的多达2倍、5倍、10倍、20倍、25倍、50倍、75倍、100倍、150倍、200倍或更大的酶活性。
68、如本文使用的,“转化”是指将一种或多于一种底物酶促转化(或生物转化)为一种或多于一种对应的产物。“转化百分比”是指在指定条件下在一定时间段内转化为产物的底物的百分比。因此,乙酸激酶多肽的“酶活性”或“活性”可以表示为指定时间段内底物转化为产物的“转化百分比”。
69、具有“通用型性质(generalist properties)”的酶(或“通用型酶(generalistenzymes)”)是指与亲本序列相比,对宽范围的底物表现出改进的活性的酶。通用型酶不必对于每种可能的底物都表现出改进的活性。在一些实施方案中,本发明提供了具有通用型性质的乙酸激酶变体,因为相对于亲本基因,它们对宽范围的空间和电子不同的底物表现出相似或改进的活性。此外,本文提供的通用型酶被工程化为跨越宽范围的有差异的分子被改进以增加代谢物/产物的产生。
70、术语“严格杂交条件”在本文中用于指在该条件下核酸杂交体稳定的条件。如本领域技术人员已知的,杂交体的稳定性反映在杂交体的解链温度(tm)中。通常,杂交体的稳定性随着离子强度、温度、g/c含量和离液剂的存在而变化。多核苷酸的tm值可以使用用于预测解链温度的已知方法来计算(参见例如baldino等人,meth.enzymol.,168:761-777[1989];bolton等人,proc.natl.acad.sci.usa48:1390[1962];bresslauer等人,proc.natl.acad.sci.usa83:8893-8897[1986];freier等人,proc.natl.acad.sci.usa83:9373-9377[1986];kierzek等人,biochem.,25:7840-7846[1986];rychlik等人,nucl.acids res.,18:6409-6412[1990](勘误,nucl.acids res.,19:698[1991]);sambrook等人,上文);suggs等人,1981,于developmental biology using purifiedgenes中,brown等人.[eds.],pp.683-693,academic press,cambridge,ma[1981];以及wetmur,crit.rev.biochem.mol.biol.26:227-259[1991])。在一些实施方案中,多核苷酸编码本文公开的多肽,并且在限定的条件下,诸如中度严格或高度严格条件下,与编码本发明的工程化乙酸激酶的序列的互补序列杂交。
71、如本文使用的,“杂交严格性”是指核酸杂交中的杂交条件,诸如洗涤条件。通常,杂交反应在较低严格性的条件下进行,随后是不同的但较高严格性的洗涤。术语“中度严格杂交”是指允许靶dna结合与靶dna具有约60%同一性、优选地约75%同一性、约85%同一性以及与靶多核苷酸具有大于约90%同一性的互补核酸的条件。示例性中度严格性条件是等同于在50%甲酰胺、5×denhart溶液、5×sspe、0.2%sds中在42℃杂交,随后在0.2×sspe、0.2%sds中在42℃洗涤的条件。“高严格性杂交”通常是指与如对限定的多核苷酸序列在溶液条件下确定的热解链温度tm相差约10℃或更小的条件。在一些实施方案中,高严格性条件是指仅允许在0.018m nacl中在65℃形成稳定杂交体的那些核酸序列的杂交的条件(即,如果杂交体在0.018m nacl中在65℃是不稳定的,它在如本文设想的高严格性条件下将是不稳定的)。例如,高严格性条件可以通过在等同于50%甲酰胺、5×denhart溶液、5×sspe、0.2%sds在42℃的条件杂交,然后在0.1×sspe和0.1%sds中在65℃洗涤提供。另一种高严格性条件是在等同于在含有0.1%(w/v)sds的5x ssc中在65℃杂交的条件进行杂交和在含有0.1%sds的0.1×ssc中在65℃洗涤。其他高严格性杂交条件以及中度严格条件在上文引用的参考文献中描述。
72、如本文使用的,“密码子优化的”是指编码蛋白的多核苷酸的密码子改变为在特定生物体中优先使用的那些密码子,使得编码的蛋白在感兴趣的生物体中有效地表达。尽管遗传密码是简并的,即大多数氨基酸由被称为“同义”(“synonyms”)或“同义”(“synonymous”)密码子的若干密码子表示,但熟知的是,特定生物体的密码子使用是非随机的和对于特定的密码子三联体是有偏倚的。就给定基因、具有共同功能或祖先起源的基因、高表达的蛋白对比低拷贝数蛋白和生物体的基因组的聚集蛋白编码区而言,这种密码子使用偏倚可能更高。在一些实施方案中,可以对编码乙酸激酶的多核苷酸进行密码子优化,用于在选择用于表达的宿主生物体中的最佳产生。
73、如本文使用的,“优选的”、“最佳的”和“高密码子使用偏倚”密码子在单独或组合使用时,可以互换地指在蛋白编码区中以高于编码相同氨基酸的其他密码子的频率使用的密码子。优选的密码子可以根据单个基因、具有共同功能或起源的一组基因、高表达基因中的密码子使用、整个生物体的聚集蛋白编码区中的密码子频率、相关生物体的聚集蛋白编码区中的密码子频率,或它们的组合来确定。其频率随着基因表达的水平而增加的密码子通常是用于表达的最佳密码子。用于确定特定生物体中密码子频率(例如密码子使用、相对同义密码子使用)和密码子偏好和基因中使用的密码子的有效数目的各种方法是已知的,包括多变量分析,例如使用聚类分析或相关性分析(参见例如,gcg codonpreference,genetics computer group wisconsin package;codonw,peden,university ofnottingham;mcinerney,bioinform.,14:372-73[1998];stenico等人,nucl.acids res.,222437-46[1994];以及wright,gene 87:23-29[1990])。许多不同的生物体的密码子使用表是可用的(参见例如,wada等人,nucl.acids res.,20:2111-2118[1992];nakamura等人,nucl.acids res.,28:292[2000];duret等人,上文;henaut和danchin,于escherichiacoli and salmonella中,neidhardt等人.(eds.),asm press,washington d.c.,p.2047-2066[1996])。用于获得密码子使用的数据源可以依赖于能够编码蛋白的任何可获得的核苷酸序列。这些数据集包括实际已知编码表达的蛋白质的核酸序列(例如,完整的蛋白质编码序列-cds)、表达的序列标签(ests),或基因组序列的预测编码区(参见例如,mount,bioinformatics:sequence and genome analysis,第8章,cold spring harborlaboratory press,cold spring harbor,n.y.[2001];uberbacher,meth.enzymol.,266:259-281[1996];以及tiwari等人,comput.appl.biosci.,13:263-270[1997])。
74、如本文使用的,“控制序列”包括对本发明的多核苷酸和/或多肽的表达是必需或有利的所有组分。每一个控制序列对于编码多肽的核酸序列可以是天然的或外源的。这样的控制序列包括但不限于,前导序列、多腺苷酸化序列、前肽序列、启动子序列、信号肽序列、起始序列和转录终止子。在最小程度上,控制序列包括启动子和转录及翻译终止信号。控制序列可以与接头一起被提供,以用于导入促进控制序列与编码多肽的核酸序列的编码区的连接的特定限制性位点的目的。
75、“可操作地连接”在本文被定义为其中控制序列放置在相对于感兴趣的多核苷酸的适当位置(即,以功能关系)处,使得控制序列指导或调节感兴趣的多核苷酸和/或多肽的表达的配置。
76、“启动子序列”指被宿主细胞识别用于感兴趣的多核苷酸诸如编码序列的表达的核酸序列。启动子序列包括介导感兴趣的多核苷酸的表达的转录控制序列。启动子可以是在选择的宿主细胞中显示转录活性的任何核酸序列,包括突变、截短的和杂合启动子,并且可以从编码与宿主细胞同源或异源的细胞外或细胞内多肽的基因来获得。
77、短语“合适的反应条件”是指在酶促转化反应溶液中的那些条件(例如,酶载量(enzyme loading)、底物载量、温度、ph、缓冲剂、助溶剂等的范围),在所述条件下本发明的乙酸激酶多肽能够将底物转化为期望的产物化合物。一些示例性的“合适的反应条件”在本文中提供。
78、如本文使用的,“载量”,诸如在“化合物载量”或“酶载量”中,是指在反应起始时组分在反应混合物中的浓度或量。
79、如本文使用的,在酶促转化反应过程的情况下,“底物”是指由本文提供的工程化酶(例如工程化乙酸激酶多肽)作用的化合物或分子。
80、如本文使用的,当反应期间存在的特定组分(例如乙酸激酶)导致,与相同条件下用相同底物和其他取代物、但不存在感兴趣的组分的情况下进行的反应相比产生更多的产物时,发生反应产物(例如核苷三磷酸或类似物)的产率“增加”。
81、如果与参与催化反应的其他酶相比,特定酶的量少于约2%、约1%、或约0.1%(wt/wt),则该反应被称为“基本上不含”该酶。
82、如本文使用的,使液体(例如,培养肉汤)“分级分离”意指应用分离过程(例如,盐沉淀、柱色谱、尺寸排阻和过滤)或这些过程的组合以提供这样的溶液:其中期望的蛋白占溶液中的总蛋白的百分比比在初始液体产物中的更大。
83、如本文使用的,“起始组合物”是指包含至少一种底物的任何组合物。在一些实施方案中,起始组合物包含任何合适的底物。
84、如本文使用的,在酶促转化过程的上下文中的“产物”是指酶多肽对底物的作用所产生的化合物或分子。
85、如本文使用的,“平衡”如本文使用的是指在化学或酶促反应(例如,两种物质a和b的相互转化)中导致化学物质稳定状态浓度的过程,包括立体异构体的相互转化,如由化学或酶促反应的正向速率常数和反向速率常数确定的。
86、如本文使用的,“烷基(alkyl)”是指具有从1至18个碳原子(包括端点)的,直链的或支链的,更优选地从1个至8个碳原子(包括端点),并且最优选地1个至6个碳原子(包括端点)的饱和烃基团。具有指定数目的碳原子的烷基在括号中表示(例如(c1-c4)烷基是指1个至4个碳原子的烷基)。
87、如本文使用的,“烯基”是指具有从2个至12个碳原子(包括端点)的、直链或支链的、包含至少一个双键但任选地包含多于一个双键的基团。
88、如本文使用的,“炔基”是指具有从2个至12个碳原子(包括端点)的、直链或支链的、包含至少一个三键但任选地包含多于一个三键,并且另外任选地包含一个或更多个双键键合部分的基团。
89、如本文使用的,“杂烷基”、“杂烯基”和“杂炔基”是指其中一个或更多个碳原子各自独立地被相同或不同的杂原子或杂原子基团替代的如本文定义的烷基、烯基和炔基。可以替代碳原子的杂原子和/或杂原子基团包括但不限于-o-、-s-、-s-o-、-nrα-、-ph-、-s(o)-、-s(o)2-、-s(o)nrα-、-s(o)2nrα-等,包括其组合,其中每个rα独立地选自氢、烷基、杂烷基、环烷基、杂环烃基、芳基和杂芳基。
90、如本文使用的,“烷氧基”是指基团“-orβ”,其中rβ是如上文定义的烷基基团,包括也如本文定义的任选地被取代的烷基基团。
91、如本文使用的,“芳基”是指具有单环(例如,苯基)或多于一个稠环(例如,萘基或蒽基)的具有从6个至12个碳原子(包括端点)的不饱和芳族碳环基团。示例性芳基包括苯基、吡啶基、萘基等。
92、如本文使用的,“氨基”是指基团“-nh2”。被取代的氨基是指基团:-nhrδ、nrδrδ和nrδrδrδ,其中每个rδ独立选自被取代的或未被取代的烷基、环烷基、环杂烷基、烷氧基、芳基、杂芳基、杂芳基烷基、酰基、烷氧基羰基、硫烷基、亚磺酰基(sulfenyl)、磺酰基等。典型的氨基基团包括但不限于二甲基氨基、二乙基氨基、三甲基铵、三乙基铵、甲基磺酰基氨基、呋喃基-氧基-磺氨基等。
93、如本文使用的,“氧/氧代(oxo)”是指=o。
94、如本文使用的,“氧基”是指二价基团“-o-”,其可以具有各种取代基以形成不同的氧基基团,包括醚和酯。
95、如本文使用的,“羧基”是指-cooh。
96、如本文使用的,“羰基”是指-c(o)-,其可以具有各种取代基以形成不同的羰基基团,包括酸、酸性卤化物、醛、酰胺、酯和酮。
97、如本文使用的,“烷基氧基羰基”是指-c(o)orε,其中rε是如本文定义的烷基基团,其可以被任选地取代。
98、如本文使用的,“氨基羰基”是指-c(o)nh2。被取代的氨基羰基是指-c(o)nrδrδ,其中氨基基团nrδrδ是如本文定义的。
99、如本文使用的,“卤素(halogen)”和“卤代(halo)”是指氟、氯、溴和碘。
100、如本文使用的,“羟基”是指-oh。
101、如本文使用的,“氰基”是指-cn。
102、如本文使用的,“杂芳基”是指在环内具有1至10个碳原子(包括端点)和1至4个选自氧、氮和硫的杂原子(包括端点)的芳族杂环基团。这样的杂芳基基团可以具有单环(例如,吡啶基或呋喃基)或多于一个稠环(例如,吲嗪基(indolizinyl)或苯并噻吩基)。
103、如本文使用的,“杂芳基烷基”是指被杂芳基取代的烷基(即,“杂芳基-烷基-”基团),优选地在烷基部分中具有1个至6个碳原子(包括端点)并且在杂芳基部分中具有5个至12个环原子(包括端点)。这样的杂芳基烷基基团的实例是吡啶基甲基等。
104、如本文使用的,“杂芳基烯基”是指被杂芳基取代的烯基(即,“杂芳基-烯基-”基团),优选地在烯基部分中具有2个至6个碳原子(包括端点)并且在杂芳基部分中具有5个至12个环原子(包括端点)。
105、如本文使用的,“杂芳基炔基”是指被杂芳基取代的炔基(即,“杂芳基-炔基-”基团),优选地在炔基部分中具有2个至6个碳原子(包括端点)并且在杂芳基部分中具有5个至12个环原子(包括端点)。
106、如本文使用的,“杂环”、“杂环的”和可互换的“杂环烃基(heterocycloalkyl)”是指具有单环或多于一个稠环的、具有2个至10个碳环原子(包括端点)和1个至4个在环内的选自氮、硫或氧的杂环原子(包括端点)的饱和的或不饱和基团。这样的杂环基团可以具有单环(例如,哌啶基或四氢呋喃基)或多于一个稠环(例如,二氢吲哚基、二氢苯并呋喃或奎宁环基(quinuclidinyl))。杂环的实例包括但不限于呋喃、噻吩、噻唑、噁唑、吡咯、咪唑、吡唑、吡啶、吡嗪、嘧啶、哒嗪、吲嗪、异吲哚、吲哚、吲唑、嘌呤、喹嗪(quinolizine)、异喹啉、喹啉、酞嗪(phthalazine)、萘基吡啶、喹喔啉、喹唑啉、噌啉、蝶啶、咔唑(carbazole)、咔啉(carboline)、菲啶(phenanthridine)、吖啶、菲咯啉(phenanthroline)、异噻唑、吩嗪(phenazine)、异噁唑、吩噁嗪(phenoxazine)、吩噻嗪(phenothiazine)、四氢咪唑(imidazolidine)、咪唑啉(imidazoline)、哌啶、哌嗪、吡咯烷、二氢吲哚等。
107、如本文使用的,“元环”意图涵盖任何环状结构。术语“元”之前的数字表示构成环的主链原子的数目。因此,例如环己基、吡啶、吡喃和噻喃是6元环,并且环戊基、吡咯、呋喃和噻吩是5元环。
108、除非另有指定,否则在前述基团中被氢占据的位置可以用以下取代基进一步取代,所述取代基例如但不限于:羟基、氧代、硝基、甲氧基、乙氧基、烷氧基、被取代的烷氧基、三氟甲氧基、卤代烷氧基、氟、氯、溴、碘、卤代、甲基、乙基、丙基、丁基、烷基、烯基、炔基、被取代的烷基、三氟甲基、卤代烷基、羟基烷基、烷氧基烷基、硫基、烷硫基、酰基、羧基、烷氧基羰基、甲酰氨基、被取代的甲酰氨基、烷基磺酰基、烷基亚磺酰基、烷基磺酰基氨基、磺酰氨基、被取代的磺酰氨基、氰基、氨基、被取代的氨基、烷基氨基、二烷基氨基、氨基烷基、酰基氨基、脒基、脒肟基(amidoximo)、羟基甲酰基(hydroxamoyl)、苯基、芳基、被取代的芳基、芳氧基、芳基烷基、芳基烯基、芳基炔基、吡啶基、咪唑基、杂芳基、被取代的杂芳基、杂芳氧基、杂芳基烷基、杂芳基烯基、杂芳基炔基、环丙基、环丁基、环戊基、环己基、环烷基、环烯基、环烷基烷基、被取代的环烷基、环烷基氧基、吡咯烷基、哌啶基、吗啉代、杂环、(杂环)氧基和(杂环)烷基;并且优选的杂原子是氧、氮和硫。应理解,当在这些取代基上存在开放化合价时,它们可以进一步被烷基、环烷基、芳基、杂芳基和/或杂环基团取代,当碳上存在这些开放化合价时,它们可以进一步被卤素和被氧-、氮-或硫-键合的取代基取代,并且当存在多于一个这样的开放化合价时,这些基团可以通过直接形成键或通过与新的杂原子(优选地,氧、氮或硫)形成键而连接以形成环。还应理解,可以进行上文的取代,条件是用取代基替代氢不会对本发明的分子带来不可接受的不稳定性,并且在其他方面在化学上是合理的。
109、如本文使用的术语“培养”指微生物细胞群体在任何合适的条件(例如,使用液体、凝胶或固体培养基)下的生长。
110、在一些实施方案中,可使用“重组乙酸激酶多肽”(在本文中也称为“工程化乙酸激酶多肽”、“变体乙酸激酶”、“乙酸激酶变体”和“乙酸激酶组合变体”)。
111、如本文使用的,“载体”为用于将dna序列导入到细胞中的dna构建体。在一些实施方案中,载体为被可操作地连接至能够实现dna序列中编码的多肽在合适宿主中的表达的合适的控制序列的表达载体。在一些实施方案中,“表达载体”具有可操作地连接至dna序列(例如,转基因)以驱动在宿主细胞中表达的启动子序列,并且在一些实施方案中,还包含转录终止子序列。
112、如本文使用的,术语“表达”包括参与多肽产生的任何步骤,包括但不限于,转录、转录后修饰、翻译和翻译后修饰。在一些实施方案中,该术语还包括多肽从细胞的分泌。
113、如本文使用的,术语“产生”指蛋白和/或其他化合物由细胞的产生。意图是,该术语包括参与多肽产生的任何步骤,包括但不限于,转录、转录后修饰、翻译和翻译后修饰。在一些实施方案中,该术语还包括多肽从细胞的分泌。
114、如本文使用的,如果氨基酸或核苷酸序列(例如,启动子序列、信号肽、终止子序列等)与它被可操作地连接至其的另一个序列在自然界中未缔合,则这两个序列为异源的。例如“异源”多核苷酸是通过实验室技术被引入宿主细胞的任何多核苷酸,并且包括从宿主细胞中取出、进行实验室操作并且然后重新引入宿主细胞的多核苷酸。
115、如本文使用的,术语“宿主细胞”和“宿主菌株”是指包含本文提供的dna(例如,编码乙酸激酶变体的多核苷酸)的表达载体的合适的宿主。在一些实施方案中,宿主细胞是已经用使用如本领域已知的重组dna技术构建的载体转化或转染的原核细胞或真核细胞。
116、术语“类似物”意指与参考多肽具有多于70%序列同一性,但少于100%序列同一性(例如,多于75%、78%、80%、83%、85%、88%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%序列同一性)的多肽。在一些实施方案中,类似物意指包含一个或更多个非天然存在的氨基酸残基(包括但不限于高精氨酸、鸟氨酸和正缬氨酸)以及天然存在的氨基酸的多肽。在一些实施方案中,类似物还包括一个或更多个d-氨基酸残基以及两个或更多个氨基酸残基之间的非肽连接。当用于指化学结构或化合物时,术语“类似物”是指类似的化学结构或化合物,其中与参考化学结构或化合物相比,一个或更多个取代基或化学基团已被取代。
117、术语“有效量”意指足以产生期望的结果的量。本领域普通技术人员可以通过使用常规实验确定有效量。
118、术语“分离的”和“纯化的”用于指从与其天然缔合的至少一种其他组分分开的分子(例如,分离的核酸、多肽等)或其他组分。术语“纯化的”不要求绝对纯度,而是意图作为相对定义。
119、如本文使用的,“立体选择性”是指在化学或酶促反应中一种立体异构体相比另一种立体异构体优先形成。立体选择性可以是部分的,其中一种立体异构体的形成优于另一种,或者其可以是完全的,其中只形成一种立体异构体。当立体异构体是对映异构体时,立体选择性被称为对映选择性,即两种对映体的总和中一种对映体的分数(通常以百分比报告)。本领域通常可选地报告其为根据下式从中计算的对映体过量(“e.e.”)(通常为百分比):[主要对映异构体-次要对映异构体]/[主要对映异构体+次要对映异构体]。当立体异构体是非对映异构体时,立体选择性被称为非对映选择性,即两种非对映异构体的混合物中一种非对映异构体的分数(通常报告为百分比),通常可选地报告为非对映异构体过量(“d.e.”)。对映异构体过量和非对映体过量是立体异构过量的类型。
120、如本文使用的,“区域选择性”和“区域选择性反应”是指其中一个键形成或断裂方向优先于所有其他可能方向发生的反应。如果区分是完全的,则反应可以是完全(100%)区域选择性的;如果一个位点的反应产物相比其他位点的反应产物占主导地位,则是基本上区域选择性的(至少75%),或者部分区域选择性的(x%,其中百分比取决于感兴趣的反应设置)。
121、如本文使用的,“化学选择性”是指在化学或酶促反应中一种产物相比另一种产物优先形成。
122、如本文使用的,“ph稳定的”是指与未处理的酶相比,在暴露于高或低的ph(例如4.5-6或8至12)一段时间(例如0.5-24小时)后维持类似活性(例如多于60%至80%)的乙酸激酶多肽。
123、如本文使用的,“热稳定的”是指与暴露于升高的温度(例如40℃至80℃)的野生型酶相比,在暴露于相同的升高的温度持续一段时间(例如0.5h-24h)后,维持类似活性(例如多于60%至80%)的乙酸激酶多肽。
124、如本文使用的,“溶剂稳定的”是指与暴露于不同浓度(例如5%-99%)的溶剂(乙醇、异丙醇、二甲基亚砜[dmso]、四氢呋喃、2-甲基四氢呋喃、丙酮、甲苯、乙酸丁酯、甲基叔丁基醚等)的野生型酶相比,在暴露于相同浓度的相同溶剂持续一段时间(例如0.5h-24h)后,维持类似活性(多于例如60%至80%)的乙酸激酶多肽。
125、如本文使用的,“热稳定且溶剂稳定的”是指既热稳定又溶剂稳定的乙酸激酶多肽。
126、如本文使用的,“任选的”和“任选地”意指随后描述的事件或情形可以发生或可以不发生,并且意指该描述包括当该事件或情形发生的情况和其中该事件或情形不发生的情况。本领域普通技术人员将理解,对于被描述为含有一种或更多种任选的取代基的任何分子,仅意在包括空间上可实现的和/或合成上可行的化合物。
127、如本文使用的,“任选地被取代的”是指术语或化学基团系列中的所有后续修饰对象(modifier)。例如,在术语“任选地被取代的芳基烷基”中,分子的“烷基”部分和“芳基”部分可以被取代或可以不被取代,并且对于系列“任选地被取代的烷基、环烷基、芳基和杂芳基”,烷基、环烷基、芳基和杂芳基基团彼此独立地可以被取代或可以不被取代。
- 还没有人留言评论。精彩留言会获得点赞!